When capturing the relevant data of each other's websites and APP applications, we often encounter a series of methods to prevent crawlers.

The reasons why website apps do this are to ensure the quality of service and reduce the server load, and to protect data from being obtained. The struggle between reptiles and anti reptiles has lasted for a long time,
Here we summarize the common anti crawler methods when crawling data.
1. User-Agent
In network requests, user agent is a way to indicate identity. Websites can judge what browser users use to access through user agent. Different browsers have different user agents
For example, our Chrome browser on windows, its user agent is:
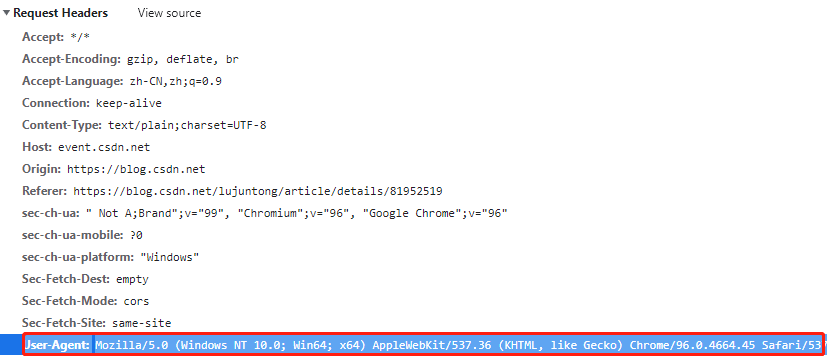
However, if we use Python Requests to directly access the website and provide no other information except the website address, the user agent received by the website is empty.
At this time, the website knows that we don't use the browser to access, so it can refuse our access.
from fake_useragent import UserAgent
for i in range(1,11):
ua = UserAgent().random
print(f'The first{i}Secondary ua yes', ua)
'''
For the first time ua yes Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.62 Safari/537.36
For the second time ua yes Mozilla/5.0 (Windows NT 6.1; rv:21.0) Gecko/20130401 Firefox/21.0
For the third time ua yes Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_6; es-es) AppleWebKit/533.20.25 (KHTML, like Gecko) Version/5.0.4 Safari/533.20.27
For the fourth time ua yes Mozilla/5.0 (X11; CrOS i686 4319.74.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.57 Safari/537.36
For the fifth time ua yes Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_6; fr-ch) AppleWebKit/533.19.4 (KHTML, like Gecko) Version/5.0.3 Safari/533.19.4
For the 6th time ua yes Mozilla/5.0 (X11; OpenBSD i386) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.125 Safari/537.36
For the 7th time ua yes Mozilla/5.0 (X11; NetBSD) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36
For the 8th time ua yes Mozilla/5.0 (X11; Linux i586; rv:31.0) Gecko/20100101 Firefox/31.0
For the 9th time ua yes Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; Zune 3.0)
For the 10th time ua yes Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.16 Safari/537.36
'''2. Referer
HTTP Referer is a part of the header. When the browser sends a request to the web server, it usually brings a Referer to indicate where the web page jumps from. It is a way of web page anti-theft chain
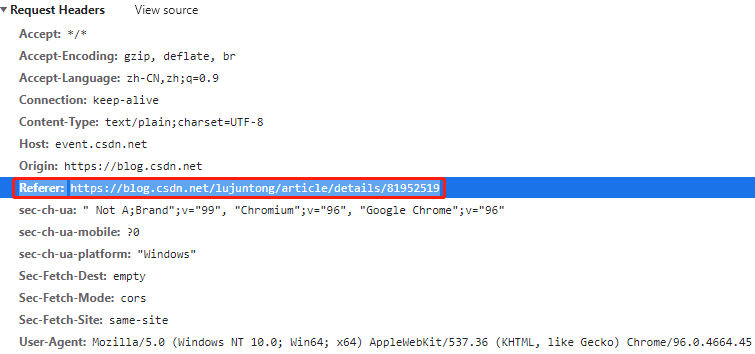
Sometimes it is also used for anti reptiles. If the website will check the Referer, please ensure that your Referer is always correct (jump to the page URL before this page).
3 Ajax
This shouldn't be anti climbing? When the website uses ajax to asynchronously obtain data, we cannot directly obtain the desired data from the web page source code. At this time, we should use the Network toolbar to analyze the API request, and then use Python to simulate and call the API to obtain data directly from the API. (most of them are POST requests and a small number of GET requests)
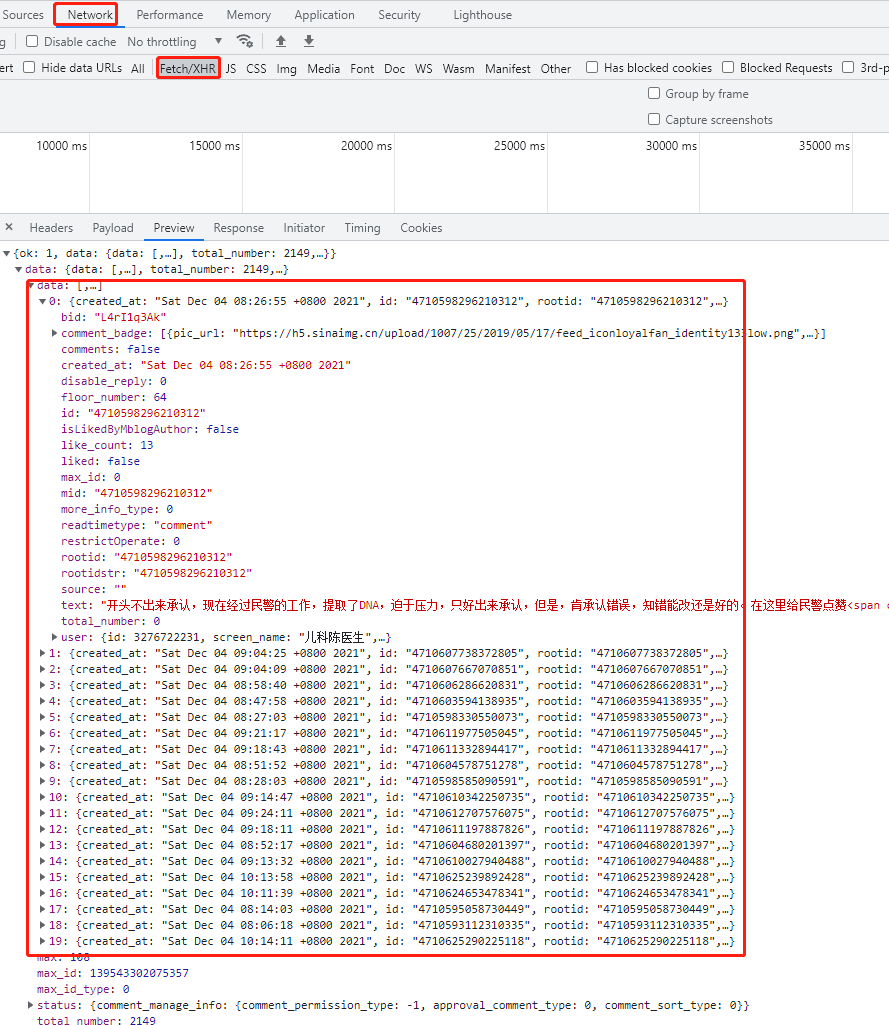
Of course, you can also use Selenium and other automated testing tools to directly render web pages, and then parse data from the rendered web page source code.
4 Cookie
In Web sites, http requests are usually stateless (after the first connection and login with the server, the server knows which user it is, but when the second request is made to the server, the server still does not know which user it is currently requesting). Cookies are used to solve this problem.
After logging in to the server for the first time, the server will return the data (i.e. cookies) related to the user to the browser. The browser will save the cookies locally. When the user requests the server for the second time, it will automatically carry the last stored cookie to the server. The server will know which user is currently through this cookie.
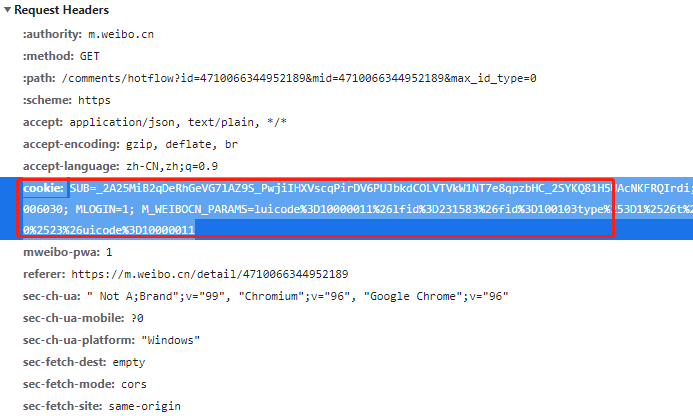
In some crawlers, we need to log in before entering a page, such as Renren. If we want to browse the home page in Renren, we need to register and log in first, and then browse. Then, when we keep logging in, we need to add cookie s in the request header.
cookies refer to the data stored in the local terminal by the website in order to identify the user's identity and track the session. cookies are generally stored in the form of text in the file in the computer. cookies are actually composed of key value pairs, as shown in the following figure:
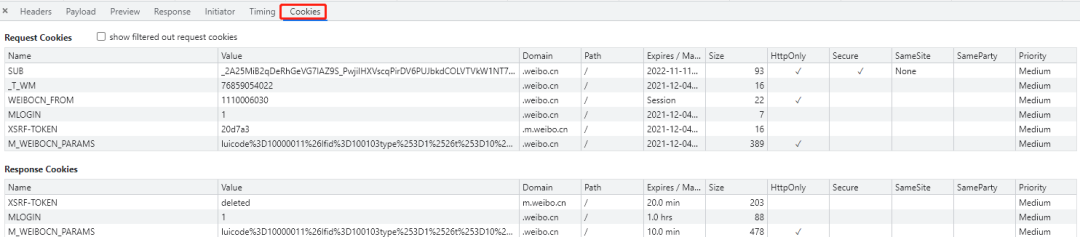
five Verification Code
There are many kinds of verification codes. Let's talk about three common ones: letter verification code, puzzle verification code and click verification code.
Letter verification code is to give you a picture with several letters or numbers, so that you can identify the content and enter it in the text box. Like this:

This is the simplest verification code. Generally, it can be solved by writing in-depth learning model training or directly using the coding platform.
Puzzle verification code, given a picture and a sliding component. When you drag the sliding component, a gap will appear in the picture. Drag the sliding component to fill the gap. Than something like this:
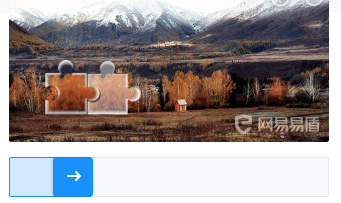
A common method is to calculate the position of the puzzle gap through the comparison between pictures, and then drag the slider with a specific track to complete the verification.
You have two methods to submit verification: one is to use Selenium to call the browser, the other is to directly crack JS and use POST to simulate submission.
The click verification code will give a small picture (some are pictures, some are not. Different verification code platforms are different), and several Chinese characters are displayed in sequence. Then give a big picture, which also has these Chinese characters, but the distribution of Chinese characters is random. You are required to click the Chinese characters in the large picture in the order of the Chinese characters in the small picture. Similar to this:


The most common method is to calculate the relative coordinates with the help of the coding platform, and then click in sequence with automatic tools such as Selenium. Of course, the self training model is also feasible, but it is more troublesome.
For the verification code, you can identify the picture through OCR. There are many codes shared by great gods on Github. You can go and have a look.
Simple OCR identification verification code:
from PIL import Image
import tesserocr
#Two methods of recognizing pictures by tesserocr
img = Image.open("code.jpg")
verify_code1 = tesserocr.image_to_text(img)
#print(verify_code1)
verify_code2 = tesserocr.file_to_text("code.jpg")six Proxy IP pool
If you frequently use the same IP to visit a website, it may be considered a malicious attack by the website, and then ban your IP. At this time, using proxy IP pool is a good solution.
In some website services, in addition to detecting the identity information of user agent
It also limits the ip address of the client,
If the same client accesses this web server too many times, it will be recognized as a crawler,
Therefore, the access of its client ip is restricted. This restriction brings trouble to our crawler, so it is very necessary to use proxy ip in crawler.
Here I provide you with two websites for reference
66 Agent: http://www.66ip.cn/6.html Express agent: https://www.kuaidaili.com/free/
7 request interval
It is best to set a certain interval between two requests. The reasons are as follows.
-
Requests are too frequent, far beyond the manual frequency, and are easy to be identified. Please do not put too much pressure on the other server
And the interval time should not be fixed. Fluctuation within a certain range is a more appropriate choice. Too long a mechanical interval may also make the website think you are a crawler.
import time
import random
for i in range(1,11):
time = random.random()*5
print(f'The first{i}Sleep for the first time:', time, 's')
'''
Sleep for the first time: 0.6327309035891232 s
Sleep for the second time: 0.037961811128097045 s
Sleep for the third time: 0.7443093721610153 s
Sleep for the fourth time: 0.564336149517787 s
Sleep for the fifth time: 0.39922345839757245 s
Sleep for the 6th time: 0.13724989845026703 s
Sleep for the 7th time: 0.7877693301824763 s
Sleep for the 8th time: 0.5641490602064826 s
Sleep for the 9th time: 0.05517343036931721 s
Sleep for the 10th time: 0.3992618299505627 s
'''8 font reverse crawl
There is another special case. You have seen the data you want on the browser page, but when you view the source code, you can't find the relevant data or the data is inconsistent with what you see. You suspect that the data is loaded asynchronously through the interface, but you check the request, and there is no asynchronous request data interface in the process. What's going on?
You may have encountered font backcrawl. That is, the target website completes the hiding of specific data by means of CSS style and font mapping. You can't directly extract relevant data from the source code, but it won't affect the display effect of the web page. So, how to solve it?
There are two methods. The first is to crack the font mapping relationship, extract the wrong data from the source code, and translate it into the correct data through the specific mapping relationship. The second method is to be lazy. Use Selenium and other automated test tools to render the page, intercept the data content picture, and identify the image content through OCR program.
9 regular expression
Of course, the most powerful for page parsing is regular expression, which is different for different users of different websites. There is no need to explain too much. Two better websites are attached:
Getting started with regular expressions:
http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
Regular expression online test:
http://tool.oschina.net/regex/
The second is the parsing library. Two commonly used websites are lxml and BeautifulSoup. For the use of these two websites, two better websites are introduced:
lxml: http://my.oschina.net/jhao104/blog/639448
BeautifulSoup: http://cuiqingcai.com/1319.html
My evaluation of these two libraries is that they are both HTML/XML processing libraries, which are implemented in pure python with low efficiency but practical functions,
For example, you can get the source code of an HTML node through result search; lxml C language coding, efficient, support Xpath.
10 pprint
This is checked in pycharm to see the effect
print() print. I don't know how you feel. I'm confused
import requests url = 'https://www.douyu.com/gapi/rknc/directory/yzRec/1' resp = requests.get(url).json() print(resp)
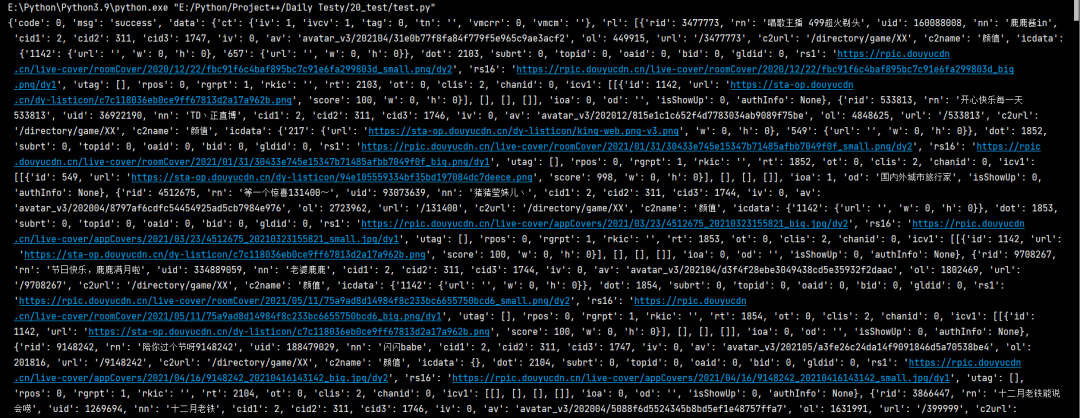

What does this structure look like when pprint() prints?
from pprint import pprint import requests url = 'https://www.douyu.com/gapi/rknc/directory/yzRec/1' resp = requests.get(url).json() pprint(resp)

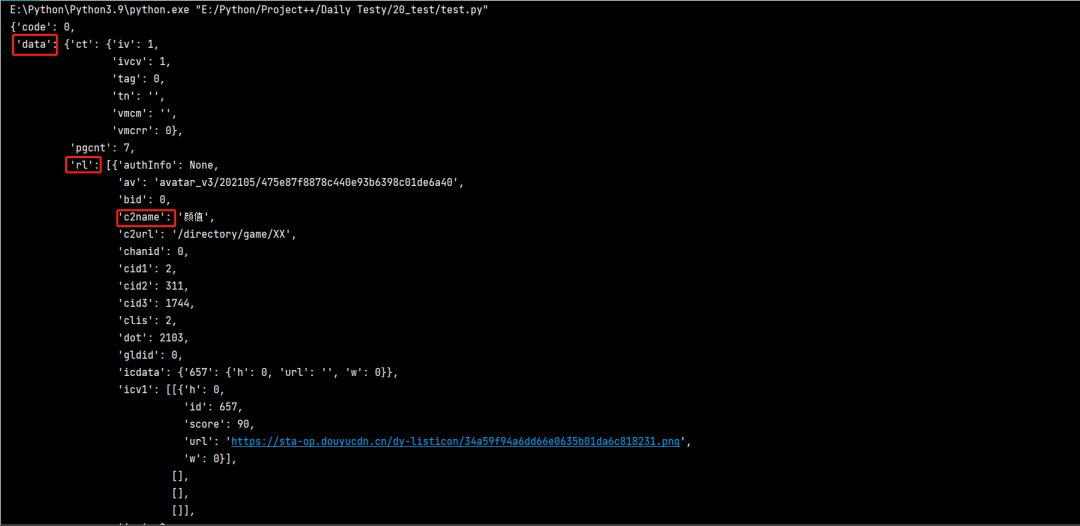
Now in addition to using pprint, ice cream is also a good choice
For details, please refer to:
Promise me not to print again in the future. Here comes the ice cream!
I've sorted out the above ten kinds. If there is any supplement, I'll wait for you in the comment area~~