Do you want to accurately find the MySQL articles you want to read? Here → MySQL column directory | click here
I have to say that how to create an index is one of the skills that our developers must master. When designing a system data table, you may add a common index or a unique index to a corresponding table field according to specific business requirements; It is also possible to knead multiple columns into a joint index according to the leftmost prefix principle, index push down feature and overlay index. when my colleagues asked me about my experience in creating indexes, as a veteran programmer, I suggested maximizing the use of indexes for where, group by and order by conditions in each SQL. Of course, the usage is different in different scenarios of writing more and reading less and reading more and writing less. While ensuring the efficiency of SQL execution, we should also pay attention to the maintenance cost of database index files, and calmly deal with those common and annoying scenarios, such as fuzzy query, large text retrieval, large paging, etc.
today I want to talk to you about what we need to pay attention to when creating the index, so as to avoid playing a good hand badly.
Special ticket
- 1, Identify the advantages and disadvantages of indexing
- 2, What should we pay attention to when creating an index in development (experience)
- summary
1, Identify the advantages and disadvantages of indexing
know yourself and your enemy, and you will be invincible in a hundred battles. If we want to use the index correctly, we must first know the characteristics of the index and its advantages and disadvantages.
1-1. Advantages
- Indexing greatly reduces the amount of data (data pages) that the server needs to scan
- Indexes can help the server avoid sorting and temporary tables
- Indexes can turn random I/O into sequential I/O
1-2. Disadvantages
- Although the index greatly improves the query speed, it will reduce the speed of updating the table, such as INSERT, UPDATE and DELETE. When updating tables, MySQL saves not only data but also index files.
- Index files that take up disk space when indexing. Generally, this problem is not serious, but if you create multiple composite indexes on a large table and insert a large amount of data, the index file size will expand rapidly.
- If a data column contains many duplicate contents, indexing it will not have much practical effect.
- For very small tables, simple full table scanning is more efficient in most cases;
- Only the most frequently queried and sorted data columns need to be indexed. (the maximum number of indexes in the same data table in MySQL is 16)
the purpose of index is to improve the query efficiency, just as we borrow books in the Library: first locate the classification area → bookshelf → book → chapter → page number. The library can be regarded as a database. If you misplace all the data, I believe you can't find the sunflower treasure book you want one day. In fact, the server is also very tired. Be nice to it~
in fact, the essence of indexing is to filter out the final desired results by constantly narrowing the range of data to be obtained, and turn random events into sequential events. In other words, with this indexing mechanism, we can not only efficiently lock certain data, but also quickly locate the range and sort work.
the read-write ratio in general application systems will be 10:1 ~ 15:1 or even higher, while insert operations and update delete operations (we call them DML operations) rarely have performance problems, mostly in transaction processing. In the production environment, we encounter more performance problems in some complex SQL queries. Therefore, the index optimization of query statements is obviously the top priority.
when it comes to indexing, we must understand its data structure and its storage and query methods. Take MysQL for example. InnoDB, MyISAM and Memory are different from each other.
Binary sort tree → binary balanced tree → B-Tree → B+Tree
for the InnoDB engine most commonly used in MySQL, the data structure is B+Tree. The selection of B+Tree has undergone a long evolution (as above). Students who want to know the detailed process can refer to it Once, I thought I knew MySQL index very well , I won't repeat it here.
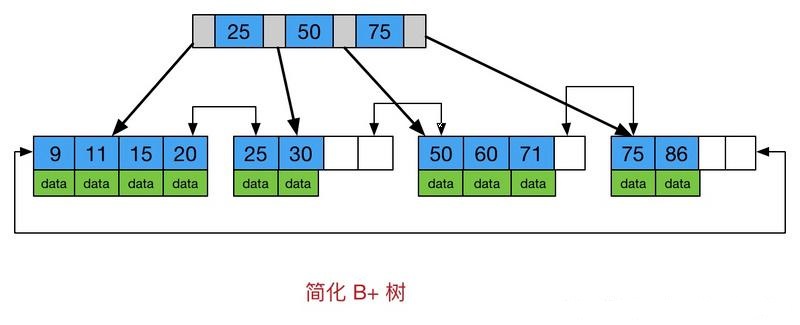
it should be noted that the characteristic of B+Tree is N-ary tree + ordered storage. Chain pointers are established between leaf nodes of B+Tree in order to strengthen interval accessibility. Therefore, B+Tree has natural advantages in index, range query and sorting.
2, What should we pay attention to when creating an index in development (experience)
In the example of this article, we construct a simple LOL hero information table as follows:
mysql> select * from t_lol; +----+--------------+--------------+-------+ | id | hero_title | hero_name | price | +----+--------------+--------------+-------+ | 1 | Blade shadow | Talon | 6300 | | 2 | Swift Scouts | Timo | 6300 | | 3 | Shining girl | Lacs | 1350 | | 4 | Clockwork demon | Oliana | 6300 | | 5 | Supreme fist | Li Qing | 6300 | | 6 | Limitless swordsman | easy | 450 | | 7 | Gale swordsman | Asso | 6300 | | 8 | Female gun | good luck | 1350 | +----+--------------+--------------+-------+ 8 rows in set (0.00 sec)
2-1. Try to construct coverage index
for example, you created hero_ Index idx of name and price_ name_ Price (hero_name, price), which is used when querying data:
SELECT * from t_lol where hero_name = 'Asso' and price = 6300;
because only hero is stored in the index_ What about the other fields of select * after the name, price and primary key columns hit the index? The database must also go back to the clustered index to find other column data through the primary key. This is the back table, which is the reason you recite: use select * less, which will make SQL miss the use of overlay index.
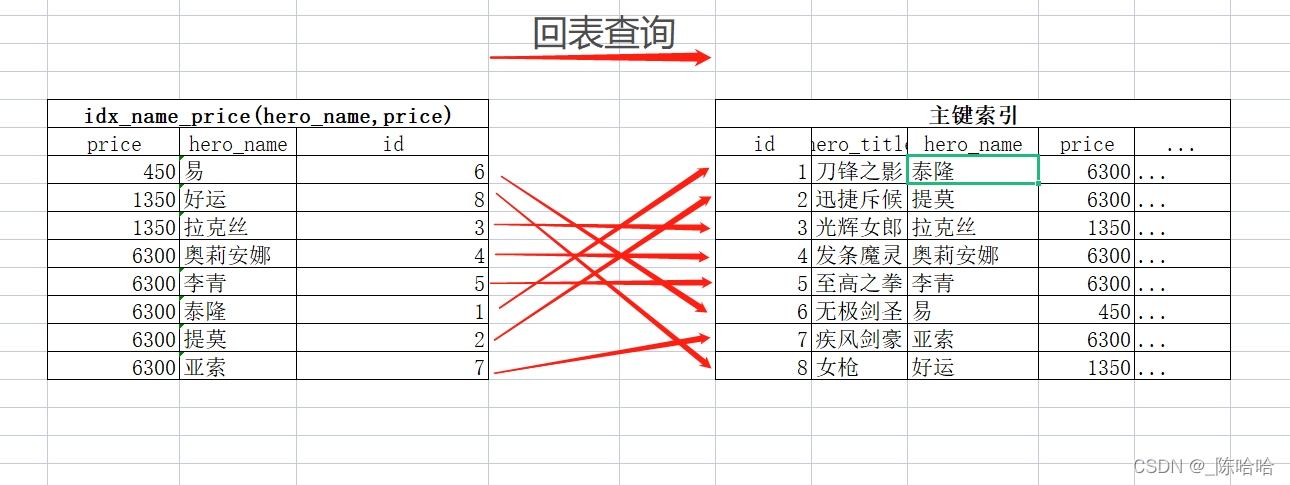
we checked the SQL execution through EXPLAIN and found that although the index was used, the index was not overwritten, and the table was returned. When the amount of data is large, the time spent on returning to the table may be more than ten times that of overwriting the index.
mysql> EXPLAIN SELECT * from t_lol where hero_name = 'Asso' and price = 6300; +----+-------------+-------+------------+------+--------------------------+----------------+---------+-------------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+--------------------------+----------------+---------+-------------+------+----------+-------+ | 1 | SIMPLE | t_lol | NULL | ref | idx_price,idx_name_price | idx_name_price | 136 | const,const | 1 | 100.00 | NULL | +----+-------------+-------+------------+------+--------------------------+----------------+---------+-------------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec)
and if only select hero is checked_ The name and price columns, or the primary key id column, can be used to overwrite the index without going back to the table. key=idx_name_price;Extra=Using index;
mysql> EXPLAIN SELECT hero_name,price from t_lol where hero_name = 'Asso' and price = 6300; +----+-------------+-------+------------+------+--------------------------+----------------+---------+-------------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+--------------------------+----------------+---------+-------------+------+----------+-------------+ | 1 | SIMPLE | t_lol | NULL | ref | idx_price,idx_name_price | idx_name_price | 136 | const,const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+--------------------------+----------------+---------+-------------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)
2-2. Create highly reusable indexes
or this t_lol table. If we add a high-frequency interface and query hero_title through price, we will create IDX_ name_ Can the price (hero_name, price) index still be used?
mysql> explain select * from t_lol where price =6300; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | t_lol | NULL | ALL | idx_price | NULL | NULL | NULL | 8 | 62.50 | Using where | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)
key=NULL;Extra=Using where; Obviously, the index idx is not used_ name_ Price (hero_name, price), because the index in MySQL implements the leftmost prefix principle. The leftmost prefix can be the leftmost X fields of the union index or the leftmost Y characters of the string index.
- Leftmost prefix principle
the node storage index order of B + tree is stored from left to right (to explain, this left to right is only a logical one-way order, not left and right. Don't be stubborn). When matching, it is also necessary to meet the matching from left to right;
usually when we create a joint index, that is, we create an index for multiple fields. I believe students who have created an index will find that Oracle or MySQL will let us choose the order of the index. For example, if we want to create a joint index on three fields a, b and c, we can choose the priority we want, a,b,c, or b, a c or c, a, b, etc. Why does the database let us choose the order of fields? Aren't they all joint indexes of three fields? This leads to the leftmost prefix principle of database index.
in our development, we often encounter the problem that the joint index is established for this field, but the index will not be used when SQL queries this field. For example, index abc_index:(a,b,c) is the joint index of a, B and C. The following SQL cannot hit the index ABC during execution_ Index;
select * from table where c = '1'; select * from table where b ='1' and c ='2';
The index will be used in the following three cases:
select * from table where a = '1'; select * from table where a = '1' and b = '2'; select * from table where a = '1' and b = '2' and c='3';
From the above two examples, can you see the point?
yes, index abc_index:(a,b,c) can only be used in three types of queries (a), (a,b), (a,b,c). In fact, there is a bit of ambiguity here. In fact, (a,c) will also go, but only the a field index will go, not the C field.
in addition, there is another special case that the following types of indexes will only have a and b, and c will not.
select * from table where a = '1' and b > '2' and c='3';
For sql statements of the above type, after a and b complete the index, c is out of order, so c cannot go to the index. The optimizer will think that it is not as fast as scanning the c field of the whole table.
Leftmost prefix: as the name suggests, it is the leftmost priority. In the above example, we created a_b_c multi column index, which is equivalent to creating (a) single column index, (a,b) combined index and (a,b,c) combined index.
therefore, when creating a multi column index, the most frequently used column in the where clause should be placed on the left according to business requirements.
after understanding the leftmost prefix principle, we found that it is impossible to maximize the use of indexes for each request. Can't we add an index to one interface?
mysql> select * from t_lol; +----+--------------+--------------+-------+ | id | hero_title | hero_name | price | +----+--------------+--------------+-------+ | 1 | Blade shadow | Talon | 6300 | | 2 | Swift Scouts | Timo | 6300 | | 3 | Shining girl | Lacs | 1350 | | 4 | Clockwork demon | Oliana | 6300 | | 5 | Supreme fist | Li Qing | 6300 | | 6 | Limitless swordsman | easy | 450 | 7 | Gale swordsman | Asso | 6300 | | 8 | Female gun | good luck | 1350 | +----+--------------+--------------+-------+ 8 rows in set (0.00 sec)
back to the question we mentioned above, if there is a high-frequency interface: query hero_title through price, don't I want to create a separate index(price)?
in fact, this leads to a problem: how to arrange the order of fields in the index when creating a joint index? That is, the reusability of the index.
because it can support the leftmost prefix, when there is already IDX_ name_ After the price (hero_name, price) joint index, it is generally not necessary to separate it in hero_ Indexed on name. However, the joint index cannot be used when the price is queried separately. If the index is used, it can also meet the requirements of querying through the price column. What should I do? As you might think, change the index column order.
therefore, the first principle is that if one index can be maintained at least by adjusting the order, this order often needs to be given priority.
so you should know that in the question at the beginning of this paragraph, we need to create the joint index (price,hero_name) for high-frequency requests, and use this index to support querying hero according to price_ Demand for title. Then we just need to change the joint index order to idx_name_price(price,hero_name) is enough.
2-3. The more indexes, the better
Obviously, we explained the shortcomings of the index mentioned earlier in the article. Index is a double-edged sword. While improving query efficiency, we also need to use a lot of resources in the database to maintain it. Larger and larger index files and slower DML operations are the consequences to be considered.
therefore, when creating an index, we need to decide whether to read more and write less or read less and write more according to the needs of the actual scenario? The need to create an index for data volume? Hard injury to the index? Wait.
a classmate asked me when there was a small amount of data (dozens?) How much is the difference in query efficiency and maintenance cost between creating an index and not creating an index?
I don't know how to answer for the moment.. As an old programmer, I suggest you take a long-term view and don't spend too much time on this kind of problem. It can only be said that if any business will use it, it is recommended to create it according to the index creation specification during our development, which will always be used in the future. With less data, the cost of index maintenance can also be ignored. Just don't leave a hole.
2-4. Some warm suggestions for using the index
1. The index will not contain columns with null values
as long as the column contains null value, it will not be included in the index. As long as a column in the composite index contains null value, this column is invalid for this composite index. Therefore, we recommend not to let the default value of the field be null when designing the database.
2. Use short index index the serial column, and specify a prefix length if possible. For example, if you have a char(255) column, if multiple values are unique within the first 10 or 20 characters, do not index the entire column. Short index can not only improve query speed, but also save disk space and I/O operation.
3. Index column sorting the query only uses one index, so if the index has been used in the where clause, the column in order by will not use the index. Therefore, if the default sorting of the database can meet the requirements, do not use the sorting operation; Try not to include the sorting of multiple columns. If necessary, it is best to create a composite index for these columns.
4. like statement operation generally, the like operation is not recommended. If it must be used, how to use it is also a problem. Like% Chen% does not use indexes, but like Chen% can use indexes.
5. Do not operate on columns
this will cause index invalidation and full table scanning, such as
SELECT * FROM table_name WHERE YEAR(column_name)<2017;
6. Non set operations such as not in and < > are not used
this is not a supported range query condition, and the index will not be used.
summary
before we actually operate the index, it is recommended to design the index type and structure of each table according to the actual needs and in combination with the index characteristics of the search engine, and try to avoid changing while writing. It is troublesome to modify the index after the data volume increases sharply. It takes a long time to modify, and the table will be locked during modification. By the way, don't modify the index of online library at will. Don't ask me why. One word: pain~~
it's almost the new year. You have to have a new year's attitude. If you have anything to do, let's talk about it next year~~