0-Preface
What does HDFS Secondary NameNode do?
- This is a classic basic interview question, and the interviewer has asked the interviewer many times (and of course many times). From the impression, about half of the interviewees can't answer correctly, and even give the answer "is not NameNode's hobby". In order to save space, this article simply chats about relevant knowledge, and refers to Secondary NameNode as SNN, NameNode as NN.
1-NN and fsimage, edit log files
- NN is responsible for managing all metadata in HDFS, including but not limited to file/directory structure, file permissions, block ID/size/number, replica policies, etc. Clients obtain metadata from NN before performing read-write operations. When NN is running, metadata is stored in memory to ensure response time.
Obviously, it is unreliable to keep metadata in memory only, so it needs to be persisted to disk as well. There are two types of files inside the NN that are used to persist metadata:
- The fsimage file, prefixed with fsimage_is an overall snapshot of the serialized stored metadata;
- The edit log file, prefixed with edits_is a log of incremental modifications to metadata stored sequentially (that is, client write transactions).
Both types of files are stored under the ${dfs.namenode.name.dir}/current/path to view their contents:
[root@bigdata-test-hadoop10 current]# ll Total dosage 412944 -rw-r--r-- 1 hdfs hdfs 46134049 6 February 2916:57 edits_0000000001876931538-0000000001877134881 -rw-r--r-- 1 hdfs hdfs 29205984 6 February 2917:57 edits_0000000001877134882-0000000001877229652 -rw-r--r-- 1 hdfs hdfs 28306206 6 February 2918:57 edits_0000000001877229653-0000000001877318515 -rw-r--r-- 1 hdfs hdfs 49660366 6 29/19/2:57 edits_0000000001877318516-0000000001877544080 -rw-r--r-- 1 hdfs hdfs 50708454 6 February 2920:57 edits_0000000001877544081-0000000001877776582 -rw-r--r-- 1 hdfs hdfs 51308280 6 February 2921:57 edits_0000000001877776583-0000000001878012751 -rw-r--r-- 1 hdfs hdfs 28408745 6 29/22:57 edits_0000000001878012752-0000000001878101834 -rw-r--r-- 1 hdfs hdfs 1048576 6 29/22:58 edits_inprogress_0000000001878101835 -rw-r--r-- 1 hdfs hdfs 68590654 6 February 2921:57 fsimage_0000000001878012751 -rw-r--r-- 1 hdfs hdfs 62 6 February 2921:57 fsimage_0000000001878012751.md5 -rw-r--r-- 1 hdfs hdfs 69451619 6 29/22:57 fsimage_0000000001878101834 -rw-r--r-- 1 hdfs hdfs 62 6 29/22:57 fsimage_0000000001878101834.md5 -rw-r--r-- 1 hdfs hdfs 11 6 29/22:57 seen_txid -rw-r--r-- 1 hdfs hdfs 175 8 February 27, 2019 VERSION [root@bigdata-test-hadoop10 current]# cat seen_txid 1878101835
- Visible, both fsimage and edit log files are segmented according to the transaction ID. The name of the edit log file being written will be marked with "inprogress", while the see_txid file will hold the starting transaction ID of the edit log file being written.
- At any time, the contents of the most recent fsimage and edit log files add up to the full amount of metadata. When NN starts, it loads the most recent fsimage file into memory and replays the edit log file recorded after it to restore the metadata to the field.
2-SNN and checkpoint processes
To avoid large edit log files and shorten the time it takes to recover metadata at NN startup, we need to periodically merge edit log files into fsimage files, which are called checkpoint s (the word is really rotten).
Hadoop has introduced SNN s to take care of this since the burden of NNs is so heavy that it is not scientific to allow it to perform I/O-intensive file merge operations.
That is, the SNN is the role that assists the NN in checkpoint operations.
The trigger of checkpoint is controlled by two parameters in hdfs-site.xml.
- dfs.namenode.checkpoint.period: The length of the cycle that triggers the checkpoint, defaulting to 1 hour.
- dfs.namenode.checkpoint.txns: The maximum number of transactions allowed between two checkpoints (that is, incremental number of edit log s), defaulting to 1 million.
Whenever one of these two parameters is satisfied, the checkpoint process is triggered, as described below:
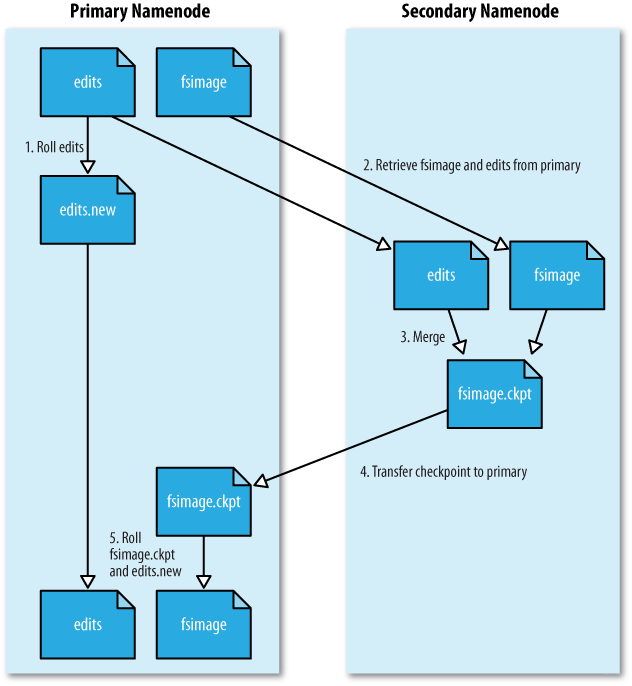
- NN generates a new edits_inprogress file in which subsequent transaction logs will be written, and the edit log file being written before is in the state to be merged.
- Copy the edit log file to be merged and the fsimage file to the SNN locally.
- SNN loads fsimage files into memory as NN starts, and replays edit log files for merge. The merge results in fsimage.chkpoint files.
- SNN copies fsimage.chkpoint back to NN and renames it as the official fsimage file name.
The official Hadoop diagram is shown below. Although the file names are different, the ideas are the same.
In addition, to avoid taking up too much disk space for fsimage files, the dfs.namenode.num.checkpoints.retained parameter allows you to specify how many fsimage files to keep, with a default value of 2.