preface
In short, the Internet is a large network composed of sites and network devices. We visit sites through the browser, and the site returns HTML, JS and CSS codes to the browser. These codes are parsed and rendered by the browser to present colorful web pages in front of us;
1, What is a reptile?
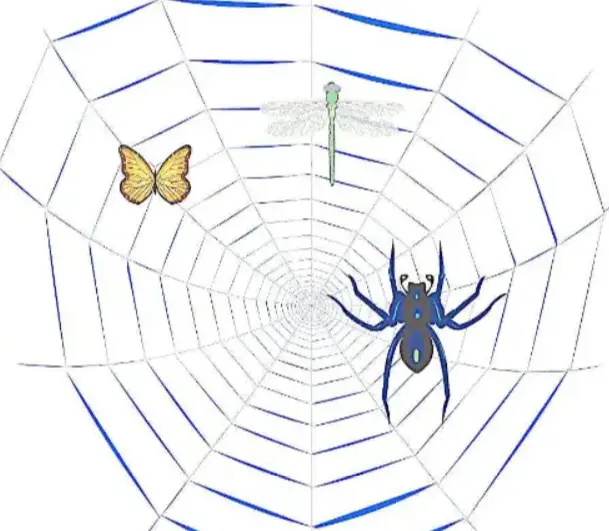
If we compare the Internet to a large spider web, the data is stored in each node of the spider web, and the crawler is a small spider,
Crawling their prey (data) along the network refers to the program that sends a request to the website, obtains resources, analyzes and extracts useful data;
From the technical level, it is to simulate the behavior of the browser requesting the site through the program, climb the HTML code / JSON data / binary data (pictures and videos) returned by the site to the local, and then extract the data you need and store it for use;
2, Basic process of crawler:
How users obtain network data:
Method 1: the browser submits the request - > downloads the web page code - > parses it into a page
Method 2: simulate the browser to send a request (get the web page code) - > extract useful data - > store it in the database or file
All reptiles have to do is mode 2;

1. Initiate request
Send a Request to the target site by using the http library
Request includes: request header, request body, etc
Request module defect: unable to execute JS and CSS code
2. Get response content
If the server can respond normally, you will get a Response
The Response includes: html, json, pictures, videos, etc
3. Parsing content
Parsing html data: regular expression (RE module), third-party parsing libraries, such as beautiful soup, pyquery, etc
Parsing json data: json module
Parsing binary data: writing files in wb mode
4. Save data
Database (MySQL, Mongdb, Redis)
file
3, http protocol request and response

Request: users send their own information to the server (socket server) through the browser (socket client)
Response: the server receives the request, analyzes the request information sent by the user, and then returns the data (the returned data may contain other links, such as pictures, js, css, etc.)
ps: after receiving the Response, the browser will parse its content to display to the user, while the crawler program will extract useful data after simulating the browser to send a request and then receive the Response.
4, request
1. Request method:
Common request methods: GET / POST
2. Requested URL
url global uniform resource locator is used to define a unique resource on the Internet. For example, a picture, a file and a video can be uniquely determined by url
url encoding
www.baidu.com/s?wd = picture
The picture will be encoded (see the sample code)
The loading process of the web page is:
When loading a web page, you usually load the document first,
When parsing a document, if a link is encountered, a request to download a picture is initiated for the hyperlink
3. Request header
User agent: if there is no user agent client configuration in the request header, the server may treat you as an illegal user host;
cookies: cookie s are used to save login information
Note: generally, crawlers will add the request header
Parameters to note in the request header:
(1) Referrer: where does the access source come from (for some large websites, the anti-theft chain strategy will be made through referrer; all crawlers should also pay attention to simulation)
(2) User agent: Browser accessed (to be added, otherwise it will be regarded as a crawler)
(3) cookie: the request header should be carried carefully
4. Request body
Request body
In the get mode, the request body has no content (the request body of the get request is placed in the parameter after the url, which can be seen directly)
In case of post mode, the request body is format data
ps: 1,Login window, file upload, etc. information will be attached to the request body 2,Log in, enter the wrong user name and password, and then submit, you can see post,After logging in correctly, the page usually jumps and cannot be captured post
Copy code
5, Response response
1. Response status code
200: success
301: represents jump
404: file does not exist
403: no access
502: server error
2,respone header
Parameters needing attention in response header:
(1)Set-Cookie:BDSVRTM=0; path = /: there may be more than one to tell the browser to save the cookie
(2) Content Location: the server response header contains Location. After returning to the browser, the browser will revisit another page
3. preview is the web page source code
JSO data
Such as web pages, html, pictures
Binary data, etc
6, Summary
1. Summarize the crawler process:
Crawl - > parse - > store
2. Tools required for crawler:
Request Library: requests,selenium (it can drive the browser to parse and render CSS and JS, but it has performance disadvantages (useful and useless web pages will be loaded);)
Parsing library: regular, beautiful soup, pyquery
Repository: file, MySQL, Mongodb, Redis
3. Climb the school flower net
Finally, let's give you some benefits
Basic version:
import re
import requests
respose\=requests.get('http://www.xiaohuar.com/v/')
# print(respose.status\_code)# Response status code
# print(respose.content) #Return byte information
# print(respose.text) #Return text content
urls=re.findall(r'class="items".\*?href="(.\*?)"',respose.text,re.S) #re.S converts text information into 1 line matching
url=urls\[5\]
result\=requests.get(url)
mp4\_url\=re.findall(r'id="media".\*?src="(.\*?)"',result.text,re.S)\[0\]
video\=requests.get(mp4\_url)
with open('D:\\\\a.mp4','wb') as f:
f.write(video.content)
Copy code
View Code
Function encapsulated version
import re
import requests
import hashlib
import time
# respose=requests.get('http://www.xiaohuar.com/v/')
# # print(respose.status\_code)# Response status code
# # print(respose.content) #Return byte information
# # print(respose.text) #Return text content
# urls=re.findall(r'class="items".\*?href="(.\*?)"',respose.text,re.S) #re.S converts text information into 1 line matching
# url=urls\[5\]
# result=requests.get(url)
# mp4\_url=re.findall(r'id="media".\*?src="(.\*?)"',result.text,re.S)\[0\]
#
# video=requests.get(mp4\_url)
#
# with open('D:\\\\a.mp4','wb') as f:
# f.write(video.content)
#
def get\_index(url):
respose \= requests.get(url)
if respose.status\_code==200:
return respose.text
def parse\_index(res):
urls \= re.findall(r'class="items".\*?href="(.\*?)"', res,re.S) # re.S converts text information into 1 line matching
return urls
def get\_detail(urls):
for url in urls:
if not url.startswith('http'):
url\='http://www.xiaohuar.com%s' %url
result \= requests.get(url)
if result.status\_code==200 :
mp4\_url\_list \= re.findall(r'id="media".\*?src="(.\*?)"', result.text, re.S)
if mp4\_url\_list:
mp4\_url\=mp4\_url\_list\[0\]
print(mp4\_url)
# save(mp4\_url)
def save(url):
video \= requests.get(url)
if video.status\_code==200:
m\=hashlib.md5()
m.updata(url.encode('utf-8'))
m.updata(str(time.time()).encode('utf-8'))
filename\=r'%s.mp4'% m.hexdigest()
filepath\=r'D:\\\\%s'%filename
with open(filepath, 'wb') as f:
f.write(video.content)
def main():
for i in range(5):
res1 \= get\_index('http://www.xiaohuar.com/list-3-%s.html'% i )
res2 \= parse\_index(res1)
get\_detail(res2)
if \_\_name\_\_ == '\_\_main\_\_':
main()
Copy code
View Code
Concurrent Version (if you need to climb 30 videos and open 30 threads to do it, the time spent is the time spent on the slowest one)
import re
import requests
import hashlib
import time
from concurrent.futures import ThreadPoolExecutor
p\=ThreadPoolExecutor(30) #Create a process pool with 30 threads;
def get\_index(url):
respose \= requests.get(url)
if respose.status\_code==200:
return respose.text
def parse\_index(res):
res\=res.result() #After the process is executed, 1 object is obtained
urls = re.findall(r'class="items".\*?href="(.\*?)"', res,re.S) # re.S converts text information into 1 line matching
for url in urls:
p.submit(get\_detail(url)) #Get details page submit to thread pool
def get\_detail(url): #Download only 1 Video
if not url.startswith('http'):
url\='http://www.xiaohuar.com%s' %url
result \= requests.get(url)
if result.status\_code==200 :
mp4\_url\_list \= re.findall(r'id="media".\*?src="(.\*?)"', result.text, re.S)
if mp4\_url\_list:
mp4\_url\=mp4\_url\_list\[0\]
print(mp4\_url)
# save(mp4\_url)
def save(url):
video \= requests.get(url)
if video.status\_code==200:
m\=hashlib.md5()
m.updata(url.encode('utf-8'))
m.updata(str(time.time()).encode('utf-8'))
filename\=r'%s.mp4'% m.hexdigest()
filepath\=r'D:\\\\%s'%filename
with open(filepath, 'wb') as f:
f.write(video.content)
def main():
for i in range(5):
p.submit(get\_index,'http://www.xiaohuar.com/list-3-%s.html'% i ).add\_done\_callback(parse\_index)
#1. First, asynchronously submit the get \ _indextask to the thread pool
#2,get\_ After the index task is executed, it will add through the callback letter\_ done\_ The number of callbacks () notifies the main thread that the task is completed;
#2. get\_index execution result (note that the thread execution result is an object, and the real execution result can be obtained only by calling the result = result. Result() method), which is passed to parse as a parameter\_ index
#3,parse\_ After completing the task,
#4. Through the loop, get the details page again\_ The detail () task is submitted to the thread pool for execution
if \_\_name\_\_ == '\_\_main\_\_':
main()
Copy code
View Code
Knowledge involved: multithreading and multiprocessing
Computing intensive tasks: use multi-process, because Python has GIL, and multi-process can take advantage of multi-core CPU;
IO intensive tasks: use multithreading and do IO switching to save task execution time (concurrency)
Thread pool
last
If you think this article is a little helpful to you, give it a compliment. Or you can join my development exchange group: 1025263163 learn from each other, and we will have professional technical Q & A to solve doubts
If you think this article is useful to you, please click star: https://gitee.com/ZhongBangKeJi esteem it a favor!
PHP learning manual: https://doc.crmeb.com
Technical exchange forum: https://q.crmeb.com