After microservices, many originally simple problems have become complex, such as global ID!
Brother song just used this content in his recent work, so he investigated several common global ID generation strategies on the market and made a comparison for his partners' reference.
After the database is divided into databases and tables, the original primary key self increment is inconvenient to continue to use. It is necessary to find a new and appropriate scheme. SongGe's demand is put forward under such circumstances.
Next, let's touch it together.
1. Two ideas
On the whole, there are two different ideas on this issue:
- Let the database handle it by itself
- Java code to process the primary key, and then directly insert it into the database.
These two ideas correspond to different schemes. Let's look at them one by one.
2. Do it yourself
The database does it by itself, that is, when I insert data, I still don't consider the problem of primary key. I hope to continue to use the primary key auto increment of the database, but obviously, the original default primary key auto increment can't be used now. We must have a new scheme.
2.1 modifying database configuration
The structure after the database is divided into databases and tables is shown in the following figure (assuming that MyCat is used for Database Middleware):
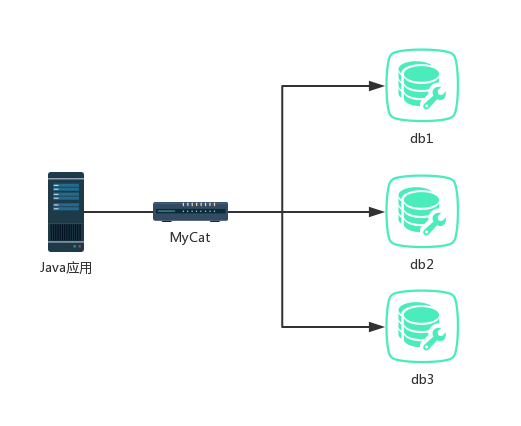
At this time, if the original primary keys of db1, db2 and db3 continue to increase automatically, the primary keys for MyCat are not increased automatically, the primary keys will be repeated, and there will be problems with the data primary keys queried by users from MyCat.
Find the cause of the problem, and the rest will be solved.
We can directly modify the starting value and step size of self increment of MySQL database primary key.
First, we can view the values of the two related variables through the following SQL:
SHOW VARIABLES LIKE 'auto_increment%'
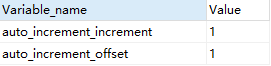
You can see that the starting value and step size of the self increment of the primary key are 1.
The starting value is easy to change. It can be set when defining the table. The step size can be achieved by modifying this configuration:
set @@auto_increment_increment=9;
After modification, check the corresponding variable value and find that it has changed:
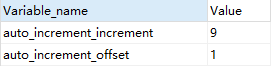
At this time, we insert data again. The primary key auto increment is not 1 each time, but 9 each time.
As for the self increment starting value, it is actually very easy to set. It can be set when creating a table.
create table test01(id integer PRIMARY KEY auto_increment,username varchar(255)) auto_increment=8;
Since MySQL can modify the starting value of self increment and the step size of each increment, now assuming that I have db1, db2 and db3, I can set the starting values of self increment of tables in these three databases to 1, 2 and 3 respectively, and then the self increment step size is 3, so that self increment can be realized.
But obviously, this method is not elegant enough, and it is troublesome to handle, and it is inconvenient to expand in the future, so it is not recommended.
2.2 MySQL+MyCat+ZooKeeper
If you happen to use MyCat in the database and table splitting tool, you can also well realize the global self increment of the primary key in combination with Zookeeper.
As a distributed database, MyCat shields the operation of the database cluster. Let's operate the database cluster like a stand-alone database. It has its own scheme for the self increment of the primary key:
- Through local files
- Realized through database
- Implemented by local timestamp
- Implemented by distributed ZK ID generator
- Realized by ZK increment
Here we mainly look at scheme 4.
The configuration steps are as follows:
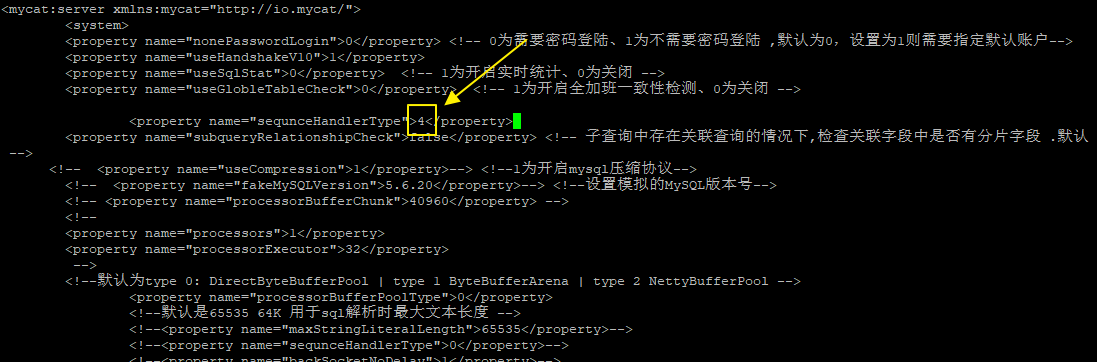
- First, modify the primary key auto increment method to 4. 4 means to use zookeeper to realize primary key auto increment.
server.xml
- Configure the self increment of the table and set the primary key
schema.xml
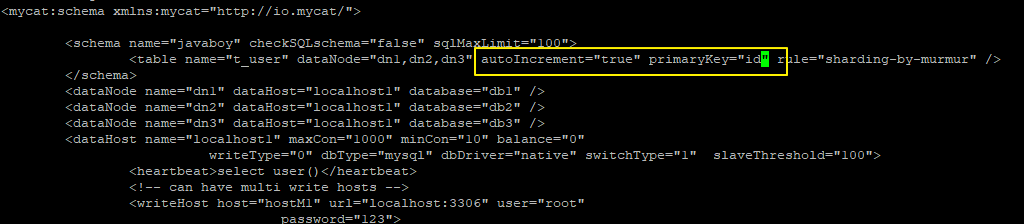
Set the primary key auto increment and set the primary key to id.
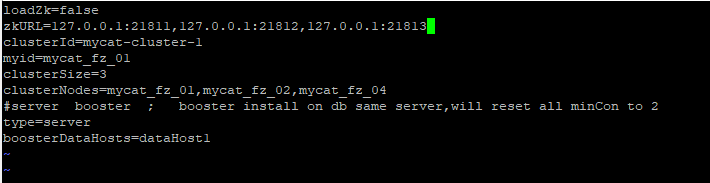
- Information for configuring zookeeper
In myid Configure zookeeper information in properties:
- Configure tables to auto increment
sequence_conf.properties
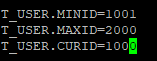
Note that the name of the table here should be capitalized.
- TABLE.MINID is the minimum value in the current interval of a thread
- TABLE. Max the maximum value of a thread in the current interval
- TABLE.CURID current value in the current interval of a thread
- The maximum and MINID of the file configuration determine the interval obtained each time, which is valid for each thread or process
- These three attribute configurations in the file are only valid for the first thread of the first process, and other threads and processes will dynamically read ZK
- Restart the MyCat test
Finally, restart MyCat, delete the previously created table, and then create a new table for testing.
This method is easier and more scalable. If you choose MyCat as the database and table tool, this is the best scheme.
The two methods mentioned above deal with the self increment of primary key at the database or database middleware level. Our Java code does not need additional work.
Next, let's look at several schemes that need to be processed in Java code.
3. Java code processing
3.1 UUID
The easiest thing to think of is UUID (universal unique identifier),
The standard type of UUID contains 32 hexadecimal digits, which are divided into five segments by hyphen and 36 characters in the form of 8-4-4-4-12. This comes with Java and is easy to use. The biggest advantage is that it is generated locally and has no network consumption. However, all partners who develop in the company know that this thing is not used much in the company's projects. The reasons are as follows:
- The string is too long, which is not conducive to indexing for MySQL.
- The randomness of UUID is very unfriendly to I/O-Intensive applications! It will make the insertion of cluster index completely random, so that the data has no clustering characteristics.
- Information insecurity: the algorithm of generating UUID based on MAC address may cause MAC address disclosure. This vulnerability has been used to find the producer location of Melissa virus.
Therefore, UUID is not the best solution.
3.2 SNOWFLAKE
Snowflake algorithm is a distributed primary key generation algorithm published by Twitter. It can ensure the non repetition of primary keys of different processes and the order of primary keys of the same process. In the same process, it first guarantees non repetition through time bits. If the time is the same, it is guaranteed through sequence bits.
At the same time, because the time bits are monotonically increasing, and if each server roughly synchronizes the time, the generated primary keys can be considered to be generally orderly in the distributed environment, which ensures the efficiency of inserting index fields.
For example, the primary key of MySQL's Innodb storage engine. The binary representation of the primary key generated by the snowflake algorithm consists of four parts. From high to low, it is divided into 1 bit symbol bit, 41 bit timestamp bit, 10 bit work process bit and 12 bit serial number bit.
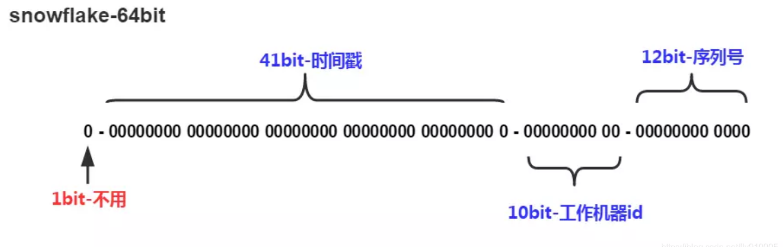
- Symbol bit (1bit)
Reserved symbol bit, constant to zero.
- Timestamp bit (41bit)
The number of milliseconds that can be accommodated by the 41 bit timestamp is the 41st power of 2. The number of milliseconds used in a year is 365 * 24 * 60 * 60 * 1000. The calculation shows that: math pow(2, 41) / (365 * 24 * 60 * 60 * 1000L); The result is about 69.73 years.
The era of ShardingSphere's snowflake algorithm starts from 0:00 on November 1, 2016 and can be used until 2086. I believe it can meet the requirements of most systems.
- Work progress bit (10bit)
This flag is unique within the Java process. In case of distributed application deployment, ensure that the id of each working process is different. The default value is 0, which can be set through the property.
- Serial number bit (12bit)
This sequence is used to generate different ID S in the same millisecond. If the number generated in this millisecond exceeds 4096 (the 12th power of 2), the generator will wait until the next millisecond to continue the generation.
Note: there is a clock callback problem in this algorithm. The server clock callback will lead to repeated sequences. Therefore, the default distributed primary key generator provides a maximum allowable number of clock callback milliseconds. If the clock callback time exceeds the maximum allowable threshold of milliseconds, the program will report an error; If within the tolerable range, the default distributed primary key generator will wait until the clock is synchronized to the time of the last primary key generation. The default value of the maximum allowable number of clock callback milliseconds is 0, which can be set through the property.
Below, SongGe gives a tool class of snowflake algorithm, which you can refer to:
public class IdWorker {
// The time starting mark point is used as the benchmark, and the latest time of the system is generally taken (once it is determined, it cannot be changed)
private final static long twepoch = 1288834974657L;
// Machine identification digit
private final static long workerIdBits = 5L;
// Number of data center identifiers
private final static long datacenterIdBits = 5L;
// Machine ID Max
private final static long maxWorkerId = -1L ^ (-1L << workerIdBits);
// Maximum data center ID
private final static long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
// Self increment in milliseconds
private final static long sequenceBits = 12L;
// The machine ID shifts 12 bits to the left
private final static long workerIdShift = sequenceBits;
// Data center ID shifts 17 bits left
private final static long datacenterIdShift = sequenceBits + workerIdBits;
// Shift left 22 bits in milliseconds
private final static long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private final static long sequenceMask = -1L ^ (-1L << sequenceBits);
/* Last production id timestamp */
private static long lastTimestamp = -1L;
// 0, concurrency control
private long sequence = 0L;
private final long workerId;
// Data identification id part
private final long datacenterId;
public IdWorker(){
this.datacenterId = getDatacenterId(maxDatacenterId);
this.workerId = getMaxWorkerId(datacenterId, maxWorkerId);
}
/**
* @param workerId
* Work machine ID
* @param datacenterId
* serial number
*/
public IdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* Get next ID
*
* @return
*/
public synchronized long nextId() {
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
if (lastTimestamp == timestamp) {
// Within the current millisecond, + 1
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
// If the current millisecond count is full, wait for the next second
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
// The ID offset combination generates the final ID and returns the ID
long nextId = ((timestamp - twepoch) << timestampLeftShift)
| (datacenterId << datacenterIdShift)
| (workerId << workerIdShift) | sequence;
return nextId;
}
private long tilNextMillis(final long lastTimestamp) {
long timestamp = this.timeGen();
while (timestamp <= lastTimestamp) {
timestamp = this.timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
/**
* <p>
* Get maxWorkerId
* </p>
*/
protected static long getMaxWorkerId(long datacenterId, long maxWorkerId) {
StringBuffer mpid = new StringBuffer();
mpid.append(datacenterId);
String name = ManagementFactory.getRuntimeMXBean().getName();
if (!name.isEmpty()) {
/*
* GET jvmPid
*/
mpid.append(name.split("@")[0]);
}
/*
* MAC + PID The hashcode of gets 16 low bits
*/
return (mpid.toString().hashCode() & 0xffff) % (maxWorkerId + 1);
}
/**
* <p>
* Data identification id part
* </p>
*/
protected static long getDatacenterId(long maxDatacenterId) {
long id = 0L;
try {
InetAddress ip = InetAddress.getLocalHost();
NetworkInterface network = NetworkInterface.getByInetAddress(ip);
if (network == null) {
id = 1L;
} else {
byte[] mac = network.getHardwareAddress();
id = ((0x000000FF & (long) mac[mac.length - 1])
| (0x0000FF00 & (((long) mac[mac.length - 2]) << 8))) >> 6;
id = id % (maxDatacenterId + 1);
}
} catch (Exception e) {
System.out.println(" getDatacenterId: " + e.getMessage());
}
return id;
}
}
The usage is as follows:
IdWorker idWorker = new IdWorker(0, 0);
for (int i = 0; i < 1000; i++) {
System.out.println(idWorker.nextId());
}
3.3 LEAF
Leaf is an open source distributed ID generation system of meituan. The earliest requirement is the order ID generation requirement of each business line. In the early days of meituan, some businesses directly generated IDS through DB self increment, some businesses generated IDS through Redis cache, and some businesses directly generated IDS through UUID. The above methods have their own problems. Therefore, meituan has decided to implement a set of distributed ID generation services to meet the needs. At present, leaf covers many business lines of meituan review company, such as internal finance, catering, takeout, hotel tourism, cat's eye film and so on. On the basis of 4C8G VM, the QPS pressure measurement result is nearly 5w/s and TP999 1ms (TP=Top Percentile, Top percentage, is a statistical term, which is similar to the average and median. TP50, TP90, TP99 and other indicators are commonly used in the system performance monitoring field, which refers to the situation higher than the percentile of 50%, 90%, 99%).
At present, there are two different ideas for the use of LEAF, segment mode and SNOWFLAKE mode. You can enable both modes at the same time or specify a certain mode (the two modes are closed by default).
After we Clone LEAF from GitHub, its configuration file is leaf server / SRC / main / resources / leaf In properties, the meaning of each configuration is as follows:
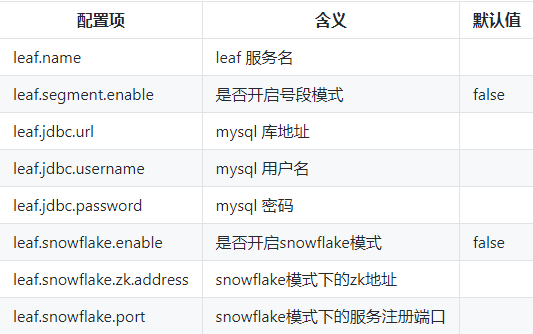 .
.
It can be seen that if the segment mode is used, database support is required; Zookeeper support is required if SNOWFLAKE mode is used.
3.3. Mode of section 1
The segment mode is still based on the database, but there are some changes in the idea, as follows:
- The proxy server is used to obtain IDS in batches from the database. Each time it obtains the value of a segment (step determines its size), and then go to the database to obtain a new segment after it is used up, which can greatly reduce the pressure of the database.
- Biz is used for different issuing requirements of each business_ Tag field. The ID acquisition of each biz tag is isolated from each other and does not affect each other.
- If a new business needs to expand the area ID, you only need to add a table record.
If the segment mode is used, we first need to create a data table. The script is as follows:
CREATE DATABASE leaf
CREATE TABLE `leaf_alloc` (
`biz_tag` varchar(128) NOT NULL DEFAULT '',
`max_id` bigint(20) NOT NULL DEFAULT '1',
`step` int(11) NOT NULL,
`description` varchar(256) DEFAULT NULL,
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB;
insert into leaf_alloc(biz_tag, max_id, step, description) values('leaf-segment-test', 1, 2000, 'Test leaf Segment Mode Get Id')
The meanings of the fields in this table are as follows:
- biz_tag: business tag (different business can have different number segment sequences)
- max_id: the maximum id under the current segment
- Step: the step size of each segment
- Description: description information
- update_time: update time
After configuration, start the project and access http://localhost:8080/api/segment/get/leaf -Segment test path (leaf segment test at the end of the path is the business tag), you can get the ID.
The monitoring page of segment mode can be accessed through the following address http://localhost:8080/cache .
Advantages and disadvantages of section mode:
advantage
- The Leaf service can be easily linearly expanded, and its performance can fully support most business scenarios.
- The ID number is a 64 bit number of 8byte with increasing trend, which meets the requirements of the primary key stored in the above database.
- High disaster tolerance: the Leaf service has an internal number segment cache. Even if the DB goes down, the Leaf can still provide external services normally in a short time.
- You can customize max_ The size of ID is very convenient for business migration from the original ID method.
shortcoming
- The ID number is not random enough. It can disclose the information of the number of numbers, which is not very safe.
- DB downtime causes unavailability of the whole system.
3.3.2 SNOWFLAKE mode
The SNOWFLAKE mode needs to work with Zookeeper, but the dependency of SNOWFLAKE on Zookeeper is weak. After starting Zookeeper, we can configure Zookeeper information in SNOWFLAKE, as follows:
leaf.snowflake.enable=true leaf.snowflake.zk.address=192.168.91.130 leaf.snowflake.port=2183
Then restart the project. After successful startup, you can access the ID through the following address:
http://localhost:8080/api/snowflake/get/test
3.4 Redis generation
This is mainly implemented by using the incrby of Redis. I don't think there's anything to say about this.
3.5 Zookeeper treatment
zookeeper can also do it, but it's troublesome. It's not recommended.
4. Summary
To sum up, if MyCat happens to be used in the project, MyCat+Zookeeper can be used. Otherwise, LEAF is recommended. Both modes can be used.