background
In previous articles Analysis and solution of DataSourceScanExec NullPointerException caused by spark DPP , we directly skipped the step of dynamic code generation failure. This time, let's analyze that SQL is still in the article mentioned above.
analysis
After running the sql, we can see the following physical plan:
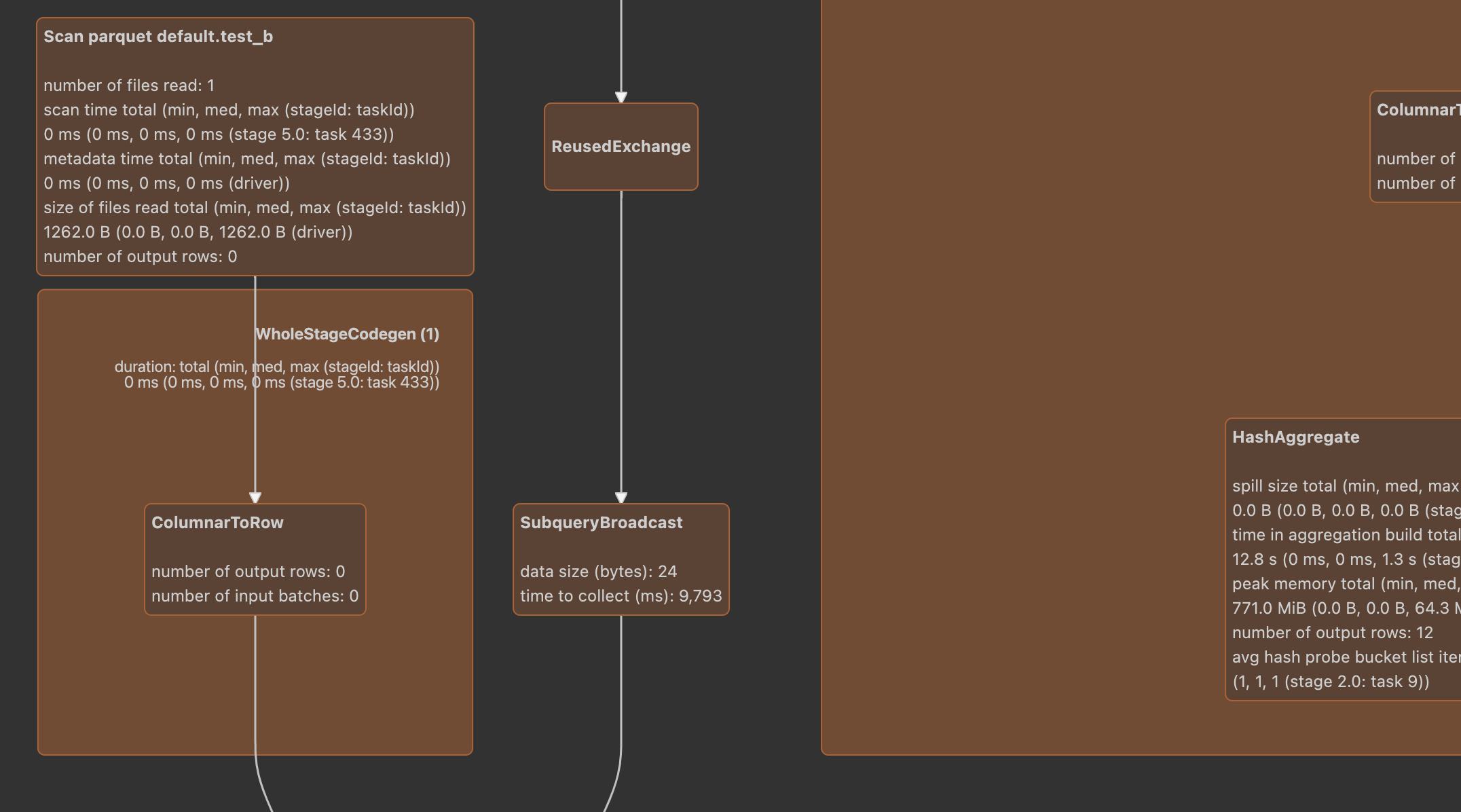
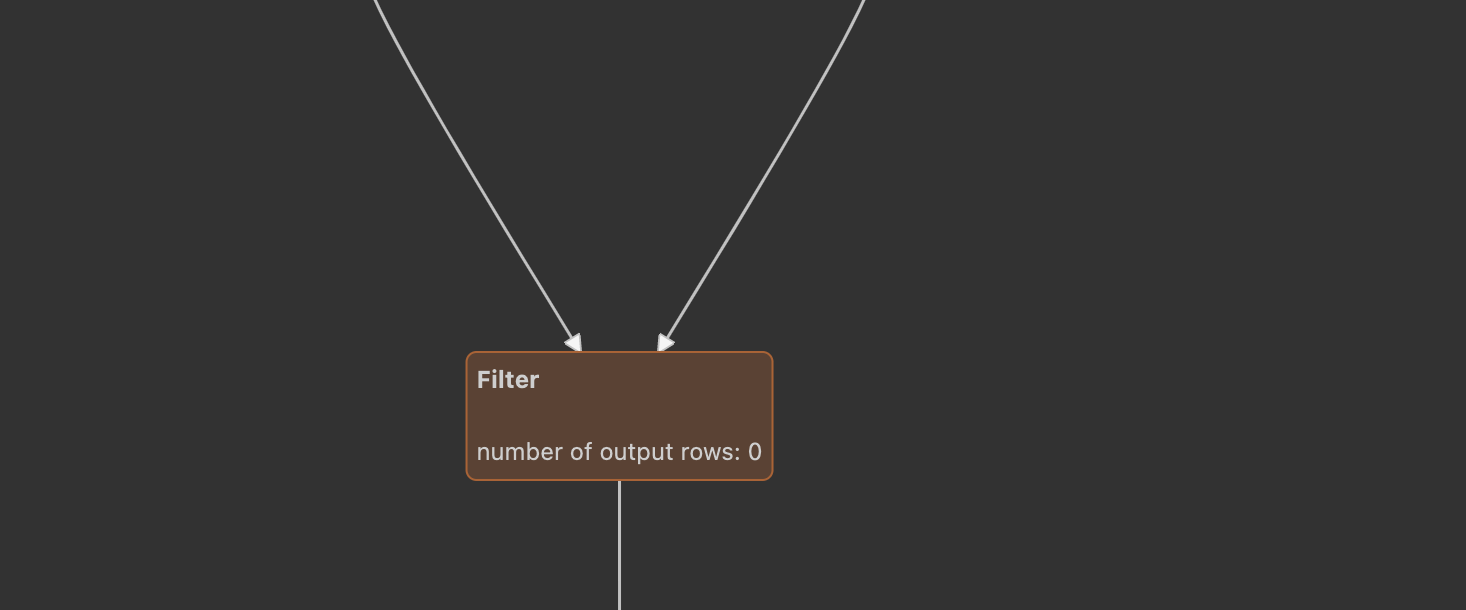
We can see that FilterExec and columnarrowexec are not in a wholestage CodeGen. Why?
This is because the exists method is inherited from codegenfallback trail.
We can track the physical rule CollapseCodegenStages. The corresponding codes are as follows:
private def insertWholeStageCodegen(plan: SparkPlan): SparkPlan = {
plan match {
// For operators that will output domain object, do not insert WholeStageCodegen for it as
// domain object can not be written into unsafe row.
case plan if plan.output.length == 1 && plan.output.head.dataType.isInstanceOf[ObjectType] =>
plan.withNewChildren(plan.children.map(insertWholeStageCodegen))
case plan: LocalTableScanExec =>
// Do not make LogicalTableScanExec the root of WholeStageCodegen
// to support the fast driver-local collect/take paths.
plan
case plan: CodegenSupport if supportCodegen(plan) =>
// The whole-stage-codegen framework is row-based. If a plan supports columnar execution,
// it can't support whole-stage-codegen at the same time.
assert(!plan.supportsColumnar)
WholeStageCodegenExec(insertInputAdapter(plan))(codegenStageCounter.incrementAndGet())
case other =>
other.withNewChildren(other.children.map(insertWholeStageCodegen))
}
When FilterExec judges supportCodegen, it will also scan whether there is a subclass of CodegenFallback in its expression. If so, FilterExec will not be generated in full code. Obviously, the conditions are not met here, and his child, that is, columnarrowexec, is qualified, so columnarrowexec can be generated in full code.
Therefore, when generating RDD on the driver side, FilterExec will still use its own doExecute method, that is, it will first run the code part of createCodeGeneratedObject, and finally call the method of subexpressionElimination to report an error.
In fact, we can modify the corresponding sql to generate the whole code and remove the filter condition of exists
FROM test_b where scenes='gogo' and exists(array(date1),x-> x =='2021-03-04') -> FROM test_b where scenes='gogo'
In this way, we can get the following physical plan:
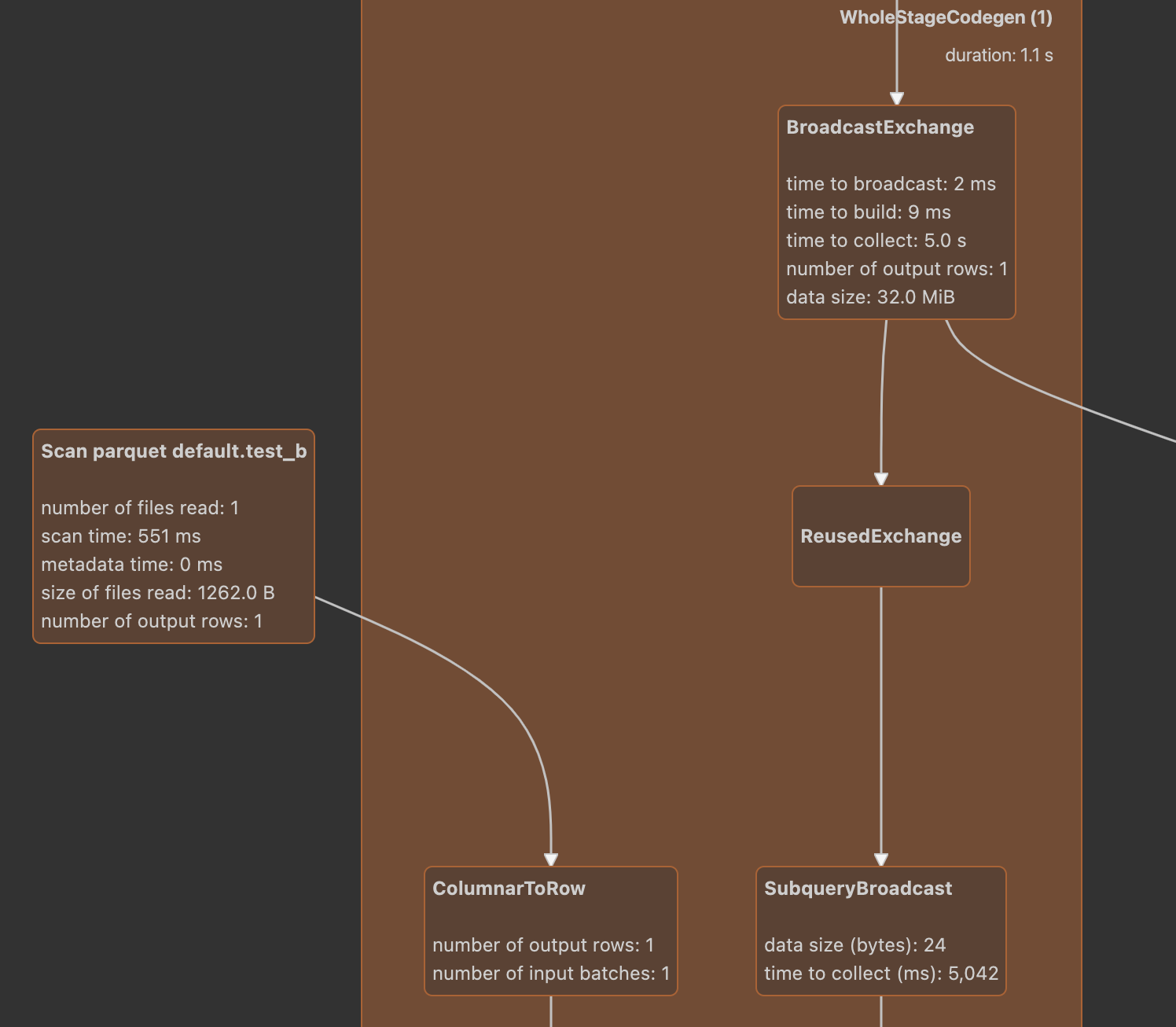
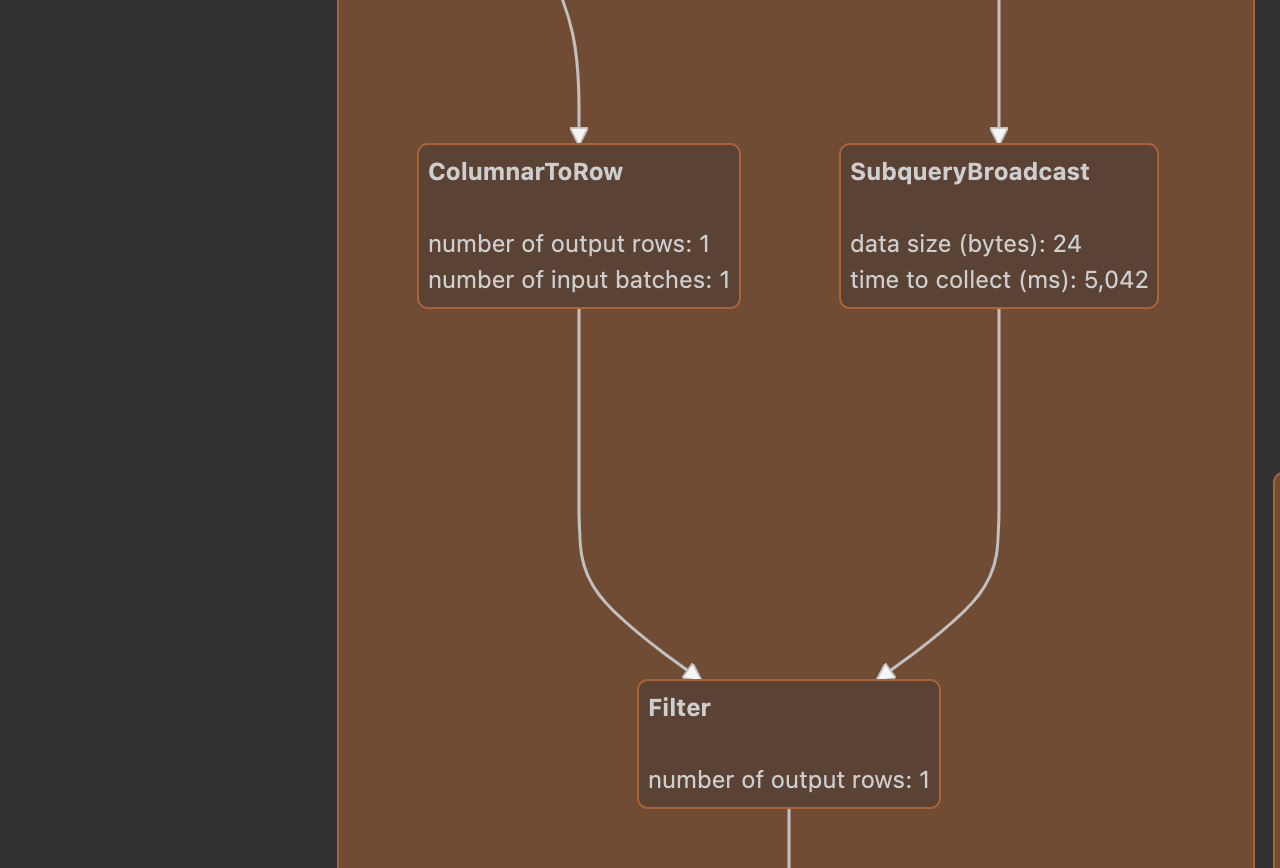
You can see that FilterExec and ColumnerExec are in a WholeStageCodegen. From the code level, they will generate data structures similar to the following:
WholeStageCodegenExec(FilterExec(ColumnarToRowExec(InputAdapter(FileSourceScanExec))))
When generating the corresponding RDD on the driver side, you will go to the doExecute method of WholeStageCodegenExec, as follows:
override def doExecute(): RDD[InternalRow] = {
val (ctx, cleanedSource) = doCodeGen()
// try to compile and fallback if it failed
val (_, compiledCodeStats) = try {
CodeGenerator.compile(cleanedSource)
} catch {
case NonFatal(_) if !Utils.isTesting && sqlContext.conf.codegenFallback =>
// We should already saw the error message
logWarning(s"Whole-stage codegen disabled for plan (id=$codegenStageId):\n $treeString")
return child.execute()
}
...
val rdds = child.asInstanceOf[CodegenSupport].inputRDDs()
assert(rdds.size <= 2, "Up to two input RDDs can be supported")
if (rdds.length == 1) {
rdds.head.mapPartitionsWithIndex { (index, iter) =>
val (clazz, _) = CodeGenerator.compile(cleanedSource)
val buffer = clazz.generate(references).asInstanceOf[BufferedRowIterator]
buffer.init(index, Array(iter)
...
The doCodeGen method still organizes the code between various physical plans according to the calling method of produce - > doproduce - > consume doconsume >.
In the end, the doConsume code of FilterExec will be called, and the expression code of DPP involved in this is generated through the code:
override def doConsume(ctx: CodegenContext, input: Seq[ExprCode], row: ExprCode): String = {
val numOutput = metricTerm(ctx, "numOutputRows")
/**
* Generates code for `c`, using `in` for input attributes and `attrs` for nullability.
*/
def genPredicate(c: Expression, in: Seq[ExprCode], attrs: Seq[Attribute]): String = {
val bound = BindReferences.bindReference(c, attrs)
val evaluated = evaluateRequiredVariables(child.output, in, c.references)
// Generate the code for the predicate.
val ev = ExpressionCanonicalizer.execute(bound).genCode(ctx)
val nullCheck = if (bound.nullable) {
s"${ev.isNull} || "
} else {
...
Call the doGenCode method of expression through the genCode method.
The expression corresponding to our sql is dynamic pruningexpression (insubqueryexec (value, broadcastvalues, exprid))
The method of dynamic pruningexpression is to call the genCode method of child, that is, it will eventually call the doGenCode method of InSubqueryExec:
override def doGenCode(ctx: CodegenContext, ev: ExprCode): ExprCode = {
prepareResult()
inSet.doGenCode(ctx, ev)
}
...
private def prepareResult(): Unit = {
require(resultBroadcast != null, s"$this has not finished")
if (result == null) {
result = resultBroadcast.value
}
}
The prepareResult method is to prepare the value of broadcast.
The inSet method only calculates a row normally.
After the whole code is generated, compile the code as follows:
val rdds = child.asInstanceOf[CodegenSupport].inputRDDs()
assert(rdds.size <= 2, "Up to two input RDDs can be supported")
if (rdds.length == 1) {
rdds.head.mapPartitionsWithIndex { (index, iter) =>
val (clazz, _) = CodeGenerator.compile(cleanedSource)
val buffer = clazz.generate(references).asInstanceOf[BufferedRowIterator]
buffer.init(index, Array(iter))
The rdds here will call the inputRDDs method, which recursively calls the inputRDDs method of child, and eventually calls the inputRDDs method of ColumnarToRowExec,
Thus, the executeColumnar method of InputAdapter will be called, and finally the doExecuteColumnar method of FileSourceScanExec will be called to generate the corresponding RDD.
The generated RDD will be compiled again on the executor side for operation.
Note: the value of resultBroadcast is completed in the method execute of WholeStageCodegenExec:
final def execute(): RDD[InternalRow] = executeQuery {
if (isCanonicalizedPlan) {
throw new IllegalStateException("A canonicalized plan is not supposed to be executed.")
}
doExecute()
}
The executeQuery method is as follows:
protected final def executeQuery[T](query: => T): T = {
RDDOperationScope.withScope(sparkContext, nodeName, false, true) {
prepare()
waitForSubqueries()
query
}
}
...
final def prepare(): Unit = {
// doPrepare() may depend on it's children, we should call prepare() on all the children first.
children.foreach(_.prepare())
synchronized {
if (!prepared) {
prepareSubqueries()
doPrepare()
prepared = true
}
}
}
The prepare and prepareSubqueries methods are called recursively, so that the child nodes can make preparations, such as the broadcast on the driver side, so that the corresponding broadcast variables can be obtained on the executor side.
At this point, the analysis is completed.