redis-benchmark -t set,lpush -n 100000 -q SET: 38550.50 requests per second //Processing 38000 set requests per second LPUSH: 37821.48 requests per second //Process 37000 lpush requests per second ### Script execution times redis-benchmark -n 100000 -q script load"redis.call('set','foo','bar')" script loadredis.call('set','foo','bar'): 37050.76 requests per second
Horizontal axis: number of connections; vertical axis: QPS
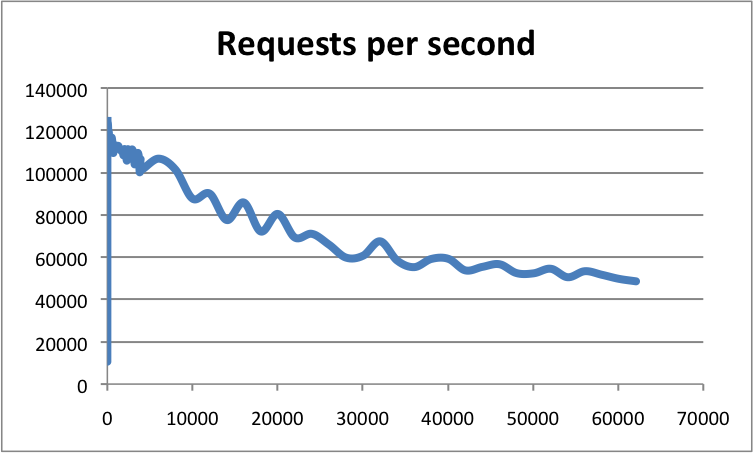
According to official data, Redis's QPS can reach about 100000 (requests per second).
Why is Redis so fast?
- Pure memory structure
- Single thread
- Multiplexing
Memory
KV structure memory database, time complexity O(1).
Single thread
What are the benefits of a single thread?
- No consumption caused by thread creation or thread destruction
- Avoid the CPU consumption caused by context switching
- It avoids the competition problems between threads, such as adding locks, releasing locks, deadlocks, etc
Asynchronous non blocking
Asynchronous non blocking I/O, multiplexing processing concurrent connections
Why is Redis single threaded?
Isn't it a waste of CPU resources to use a single thread?
https://redis.io/topics/faq
Because single thread is enough, CPU is not the bottleneck of redis. The most likely bottleneck of redis is machine memory or network bandwidth. Since single thread is easy to implement and CPU will not be the bottleneck, it is natural to adopt the single thread solution.
Why is single thread so fast?
Because Redis is a memory based operation, let's start with memory.
Virtual memory (virtual memory)
Main memory: memory; auxiliary memory: disk (hard disk)
The main memory of a computer can be regarded as an array of M consecutive byte sized units. Each byte has a unique address, which is called the physical address (PA). In early computers, if the CPU needed memory, physical addressing was used to directly access the main memory.
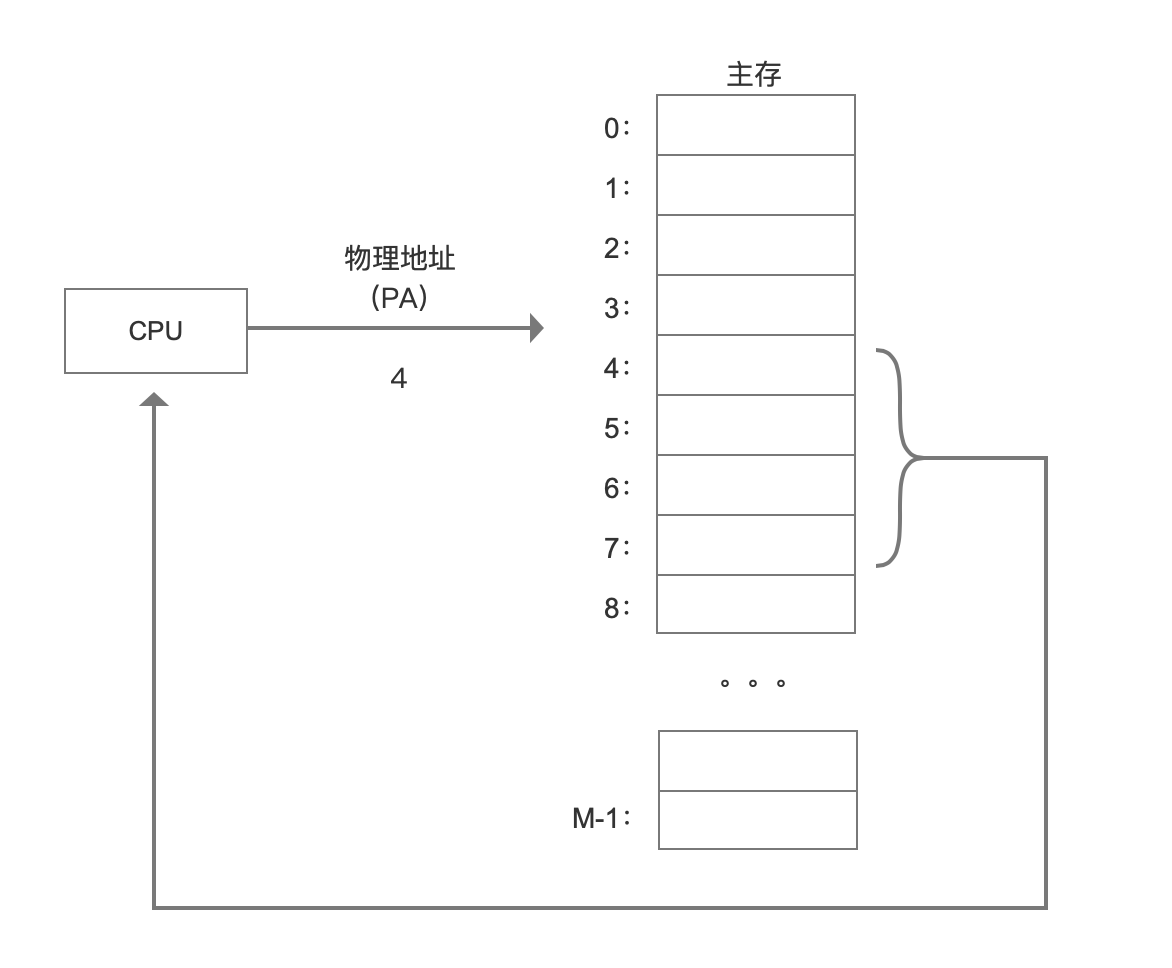
There are several drawbacks to this approach:
1. In a multi-user and multi task operating system, all processes share main memory. If each process occupies a piece of physical address space, main memory will soon be used up. We hope that at different times, different processes can share the same physical address space.
2. If all processes directly access the physical memory, then one process can modify the memory data of other processes, causing the physical address space to be damaged, and the program will run abnormally.
In order to solve these problems, we have a way to add a middle layer between CPU and main memory. CPU no longer uses physical address to access, but accesses a virtual address. This middle layer converts the address into a physical address, and finally obtains the data. This middle tier is called virtual memory.
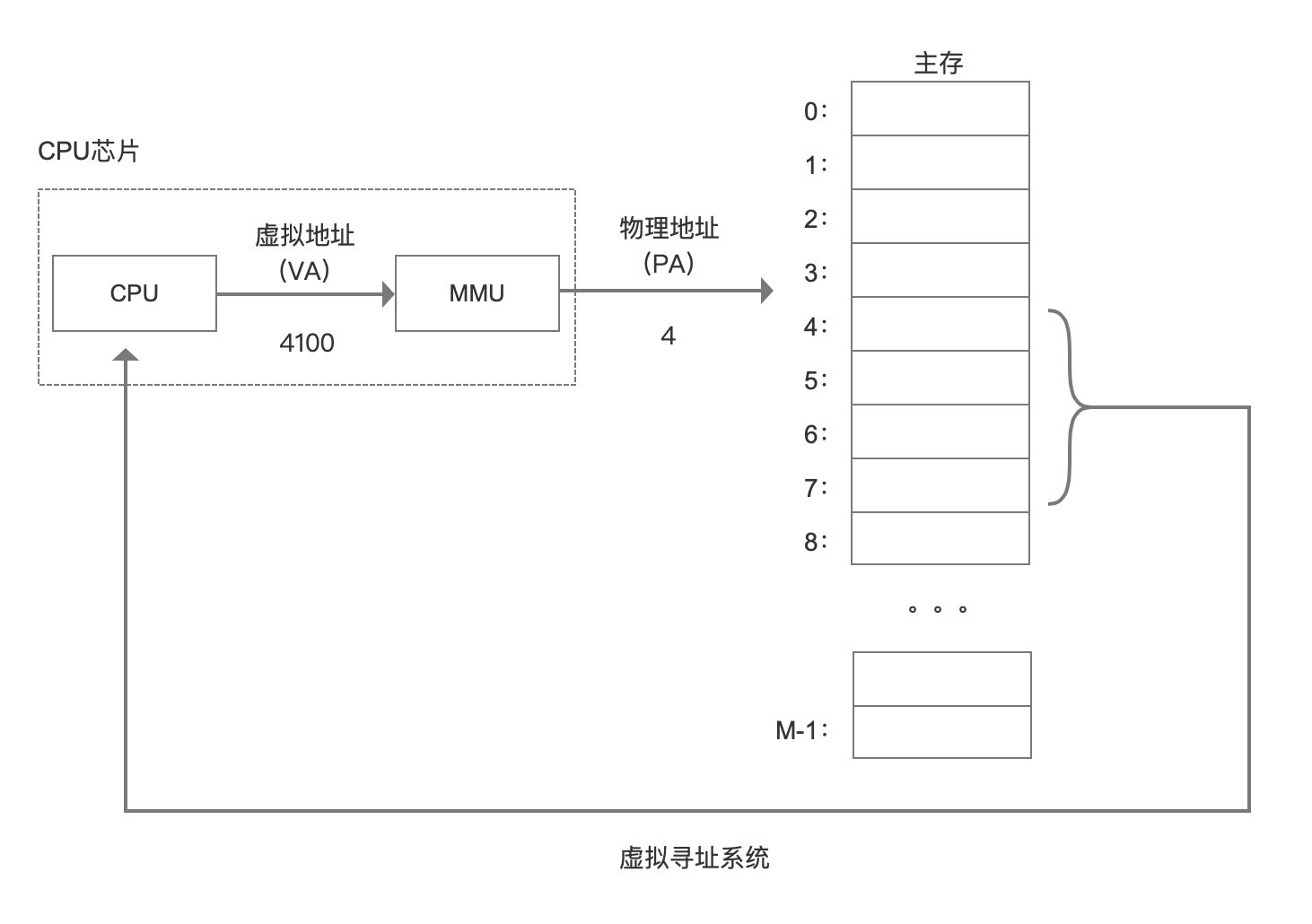
When each process starts to create, it will assign a virtual address, and then obtain the real data through the mapping of virtual address and physical address, so that the process will not directly contact the physical address, or even know which physical address data it calls.
At present, most operating systems use virtual memory, such as the virtual memory of windows system, the swap space of Linux system and so on. Windows virtual memory (pagefile.sys) is part of disk space.
On a 32-bit system, the virtual address space size is 2^32bit=4G. What is the maximum virtual address space size on a 64 bit system? Is it 2^64bit=1024*1014TB=1024PB=16EB? In fact, 64 bit is not used, because it does not use such a large space, and it will cause a lot of system overhead. Linux generally uses the lower 48 bits to represent the virtual address space, that is, 2^48bit=256T.
cat /proc/cpuinfo
addresssizes:40bitsphysical,48bitsvirtual
The actual physical memory may be much smaller than the size of the virtual memory.
Conclusion: the introduction of virtual memory can provide a larger address space, and the address space is continuous, making programming and linking easier. In addition, physical memory can be isolated, and different process operations do not affect each other. Memory sharing can also be realized by mapping the same block of physical memory to different virtual address spaces.
User space and kernel space
In order to avoid the user process directly operating the kernel and ensure the kernel security, the operating system divides the virtual memory into two parts, one is kernel space / ˈ k ɜ nl / and the other is user space.
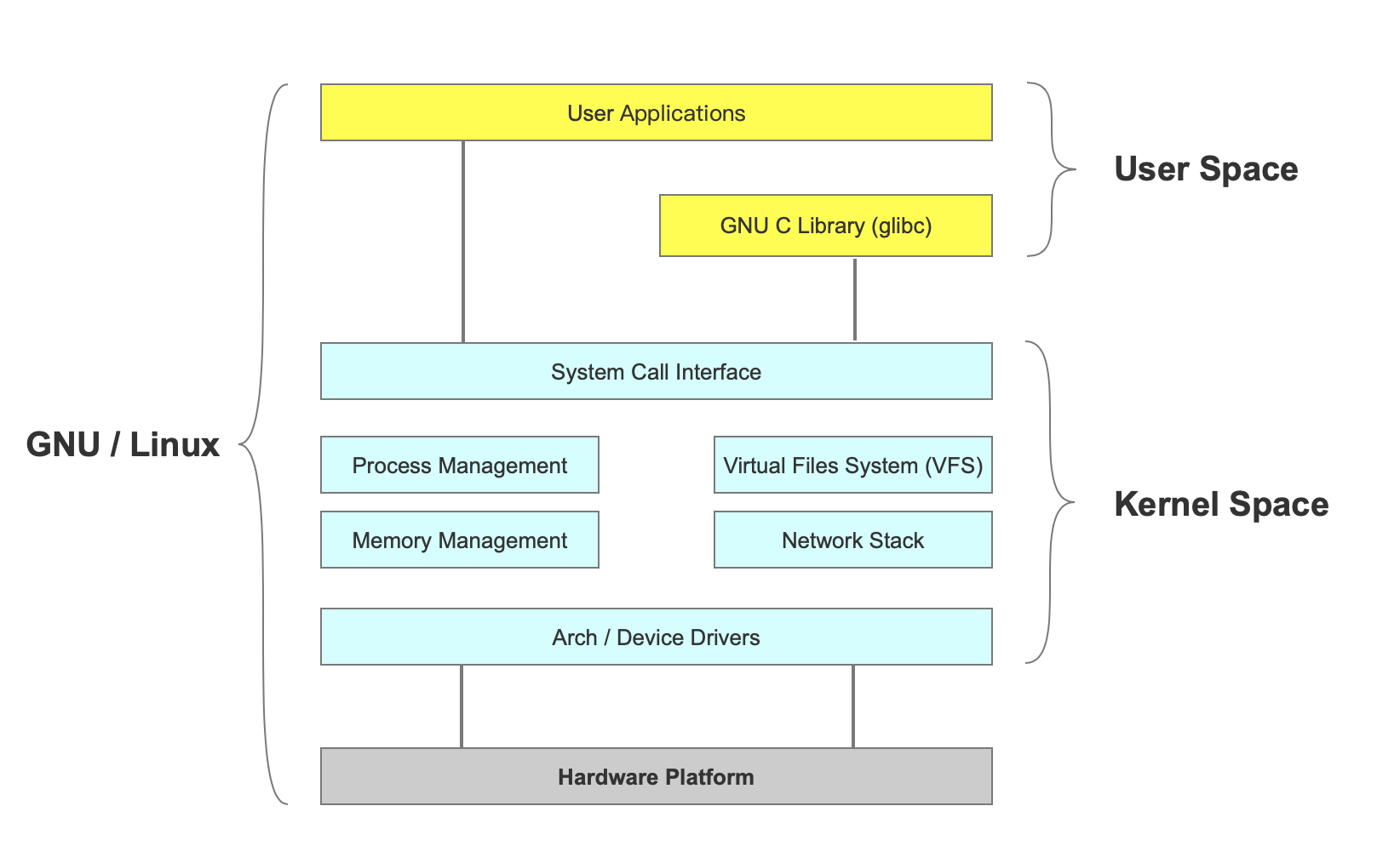
The kernel is the core of the operating system. It is independent of the ordinary application program, and can access the protected memory space as well as the underlying hardware devices.
The kernel space stores the kernel code and data, while the process user space stores the user program code and data. Whether it is kernel space or user space, they are all in virtual space, and they are all the mapping of physical address.
When a process is running in kernel space, it is in kernel state, while when a process is running in user space, it is in user state.
The process can execute arbitrary commands in kernel space and call all resources of the system; in user space, it can only perform simple operations, not directly call system resources, and only through system interface (also called systemcall) can it send instructions to the kernel.
top command:

User represents the percentage of CPU time consumed in User space; sys represents the percentage of CPU time consumed in Kernel space;
Process switching (context switching)
How does multitask operating system realize the number of tasks running far more than the number of CPUs? Of course, these tasks are not really running at the same time, but because the system allocates the CPU to them in turn in a short time through the time slicing algorithm, resulting in the illusion of multitasking running at the same time.
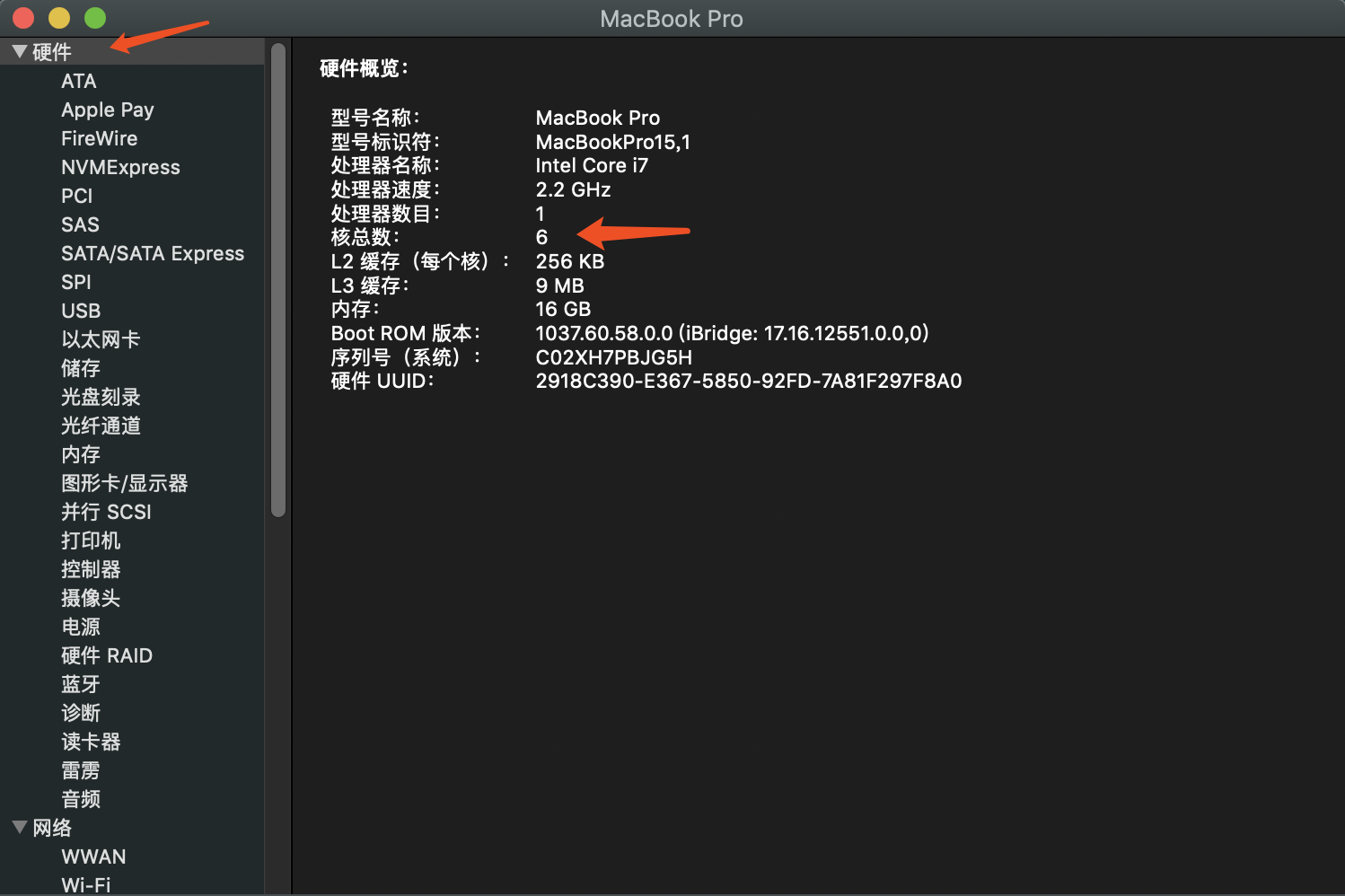
In order to control the execution of a process, the kernel must have the ability to suspend a process running on the CPU and resume the execution of a previously suspended process. This behavior is called process switching.
What is context?
Before each task runs, the CPU needs to know where the task loads and starts running. That is to say, the system needs to help it set the CPU register and program counter in advance, which is called the CPU context.
These saved contexts are stored in the system kernel and loaded again when the task is rescheduled. In this way, the original state of the task will not be affected, and the task will appear to be running continuously.
When switching context, we need to complete a series of work, which is a very resource consuming operation.
Process blocking
Due to the system service request (such as I/O operation) made by the running process, but for some reason, it did not get the immediate response from the operating system, so the process can only turn itself into a blocking state and wait for the corresponding event to appear before it is awakened. The process does not consume CPU resources in the blocked state.
File descriptor FD
Linux system treats all devices as files, and Linux uses file descriptors to identify each file object.
The file descriptor is an index created by the kernel to efficiently manage the opened files. It is used to point to the opened files. All system calls to perform I/O operations pass through the file descriptor. The file descriptor is a simple non negative integer to indicate each file opened by the process.
There are three standard file descriptors in Linux system.
0: standard input (keyboard); 1: standard output (display); 2: standard error output (display).
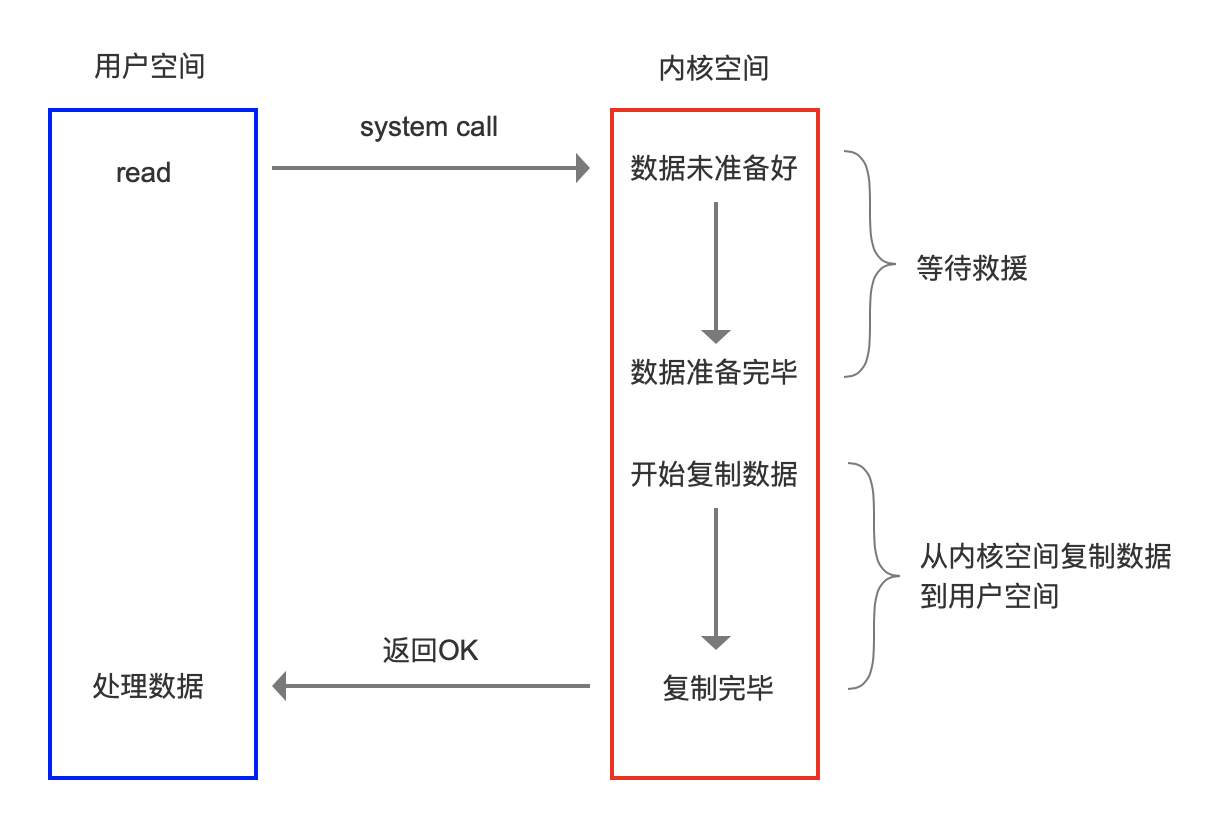
Traditional I/O data copy
When the application program executes the read system call to read the file descriptor (FD), if the data already exists in the page memory of the user process, it will read the data directly from the memory. If the data does not exist, load the data from the disk into the kernel buffer, and then copy the data from the kernel buffer to the page memory of the user process. (two copies, two context switches between user and kernel).
Blocking I/O (where is the blocking of I/O?)
When read or write is used to read or write a file descriptor, if the current FD is not readable, the system will not respond to other operations. Copying data from the device to the kernel buffer is blocked. Copying data from the kernel buffer to the user space is also blocked. Until copycomplete and the kernel returns the result, the user process will not release the block.
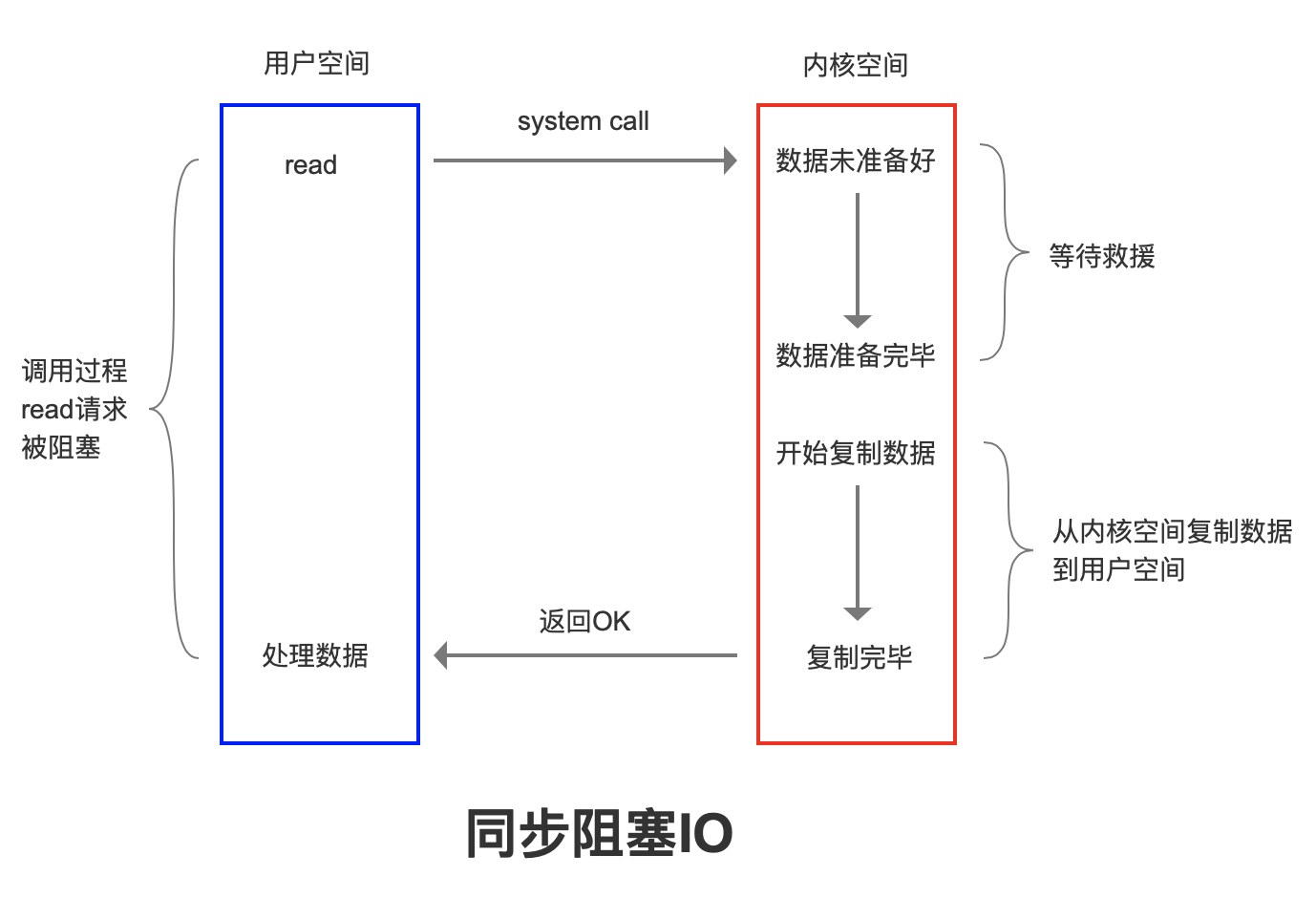
In order to solve the problem of blocking, we have several ideas.
1. Create multiple threads or use thread pool on the server side, but in the case of high concurrency, there will be many threads needed, which the system cannot bear, and the creation and release of threads need to consume resources.
2. The requester polls regularly, and then copies the data from the kernel cache buffer to user space (non blocking I/O) after the data is prepared. There will be some delay in this way.
I/O multiplexing
I/O refers to network I/O.
Multiplexing: refers to multiple TCP connections (Socket or Channel).
Reuse: refers to reusing one or more threads.
Its basic principle is that instead of monitoring the connection by the application itself, the kernel monitors the file descriptor for the application.
When the client operates, it will generate socket s with different event types. On the server side, I/O multiplexing program (I/O multiplexing module) will put messages into the queue, and then forward them to different event processors through file event dispatcher.
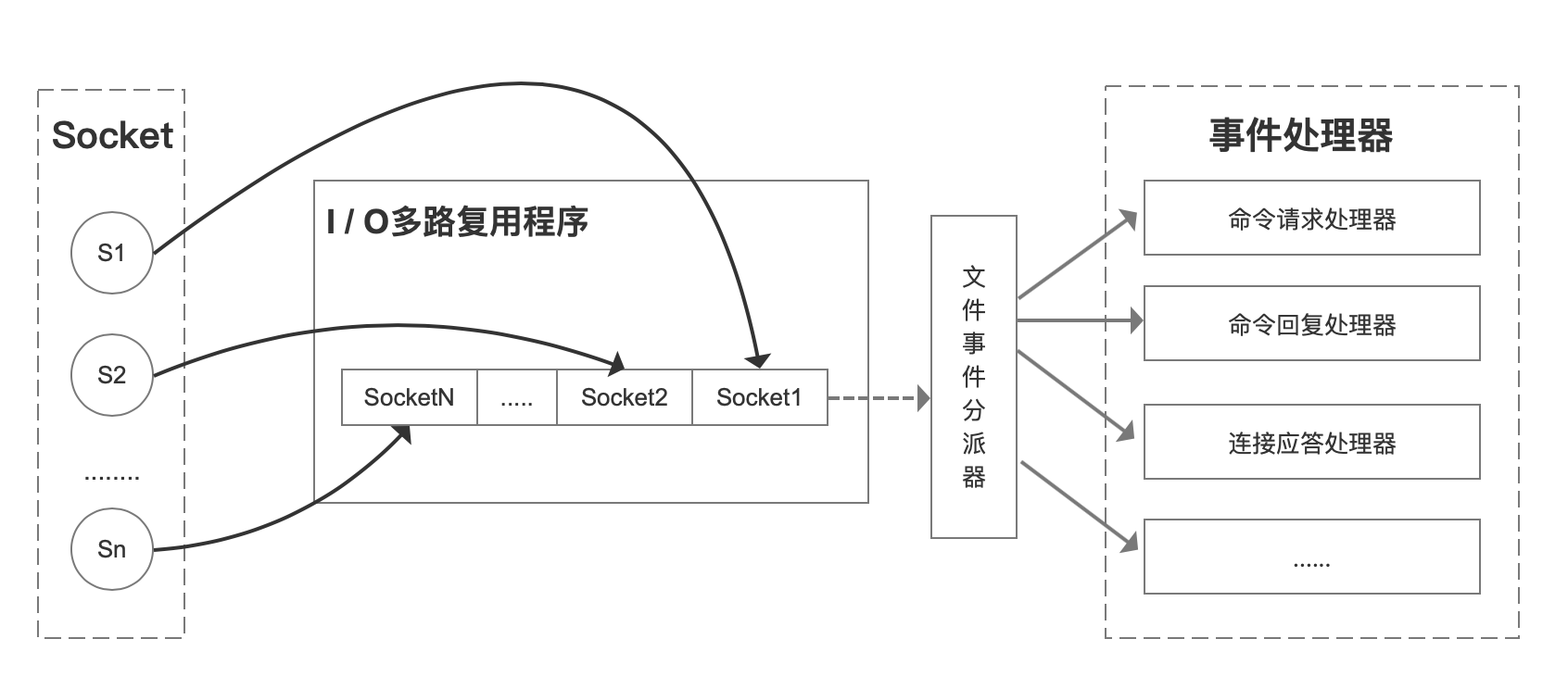
There are many implementations of multiplexing. Take select for example, when a user process calls the multiplexer, the process will be blocked. The kernel will monitor all the sockets that the multiplexer is responsible for. When the data of any socket is ready, the multiplexer will return. At this time, the user process calls the read operation to copy the data from the kernel buffer to the user space.
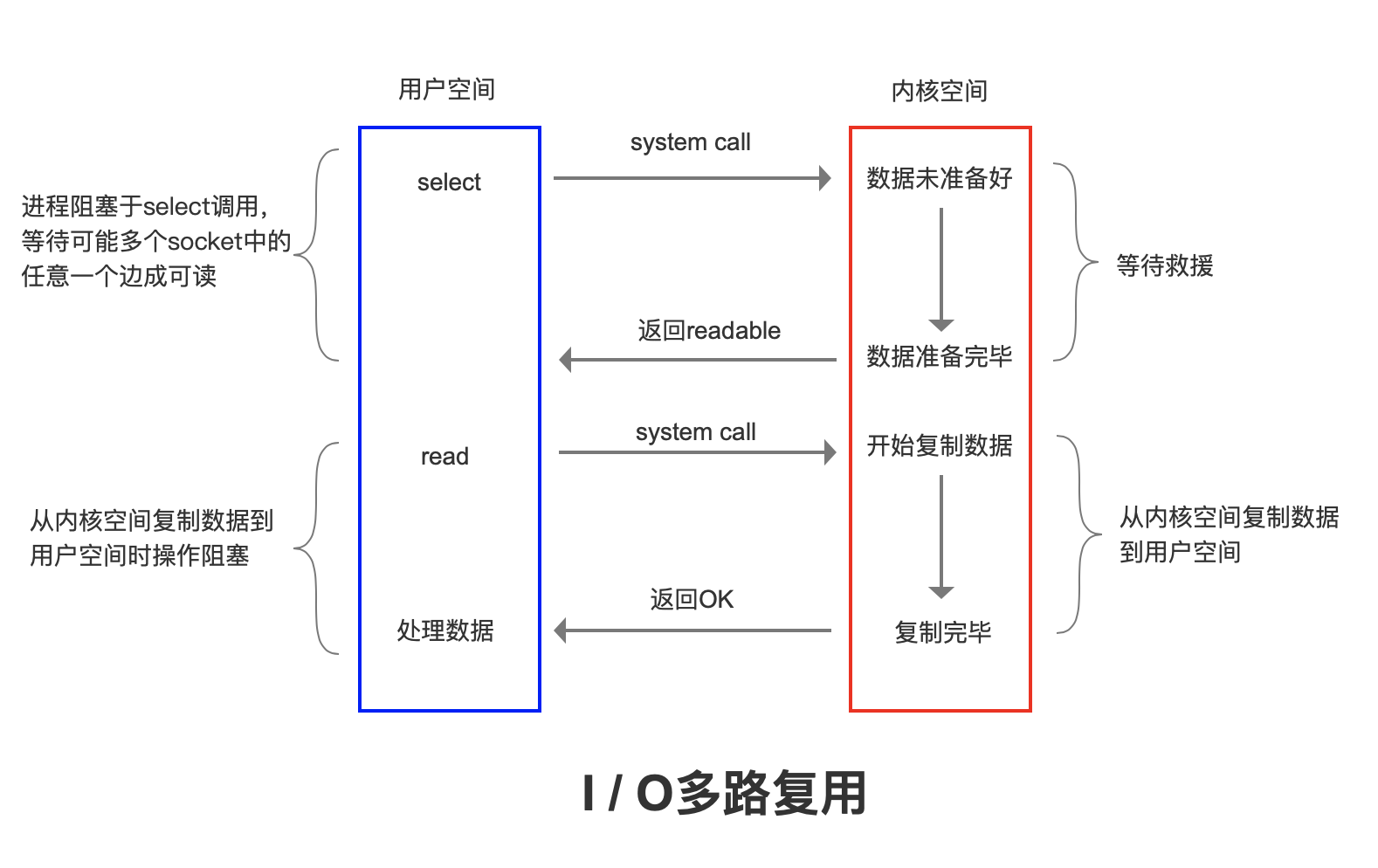
Therefore, the feature of I/O multiplexing is that a process can wait for multiple file descriptors at the same time through a mechanism, and any one of these file descriptors (socket descriptors) enters the readable state, and the select() function can return.
Redis's multiplexing provides several options, such as select, epoll, evport, and kqueue. You can choose one when compiling. Source code ae.c
/* Include the best multiplexing layer supported by this system. * The following should be ordered by performances, descending. */ #ifdef HAVE_EVPORT #include "ae_evport.c" #else #ifdef HAVE_EPOLL #include "ae_epoll.c" #else #ifdef HAVE_KQUEUE #include "ae_kqueue.c" #else #include "ae_select.c" #endif #endif #endif
- evport is supported by the kernel of Solaris System;
- epoll is supported by LINUX kernel;
- kqueue is supported by Mac system;
- select is provided by POSIX, and general operating systems have support (minimum guarantee scheme);
Source code: ae_epll. C, ae_select.c, ae_kqueue.c, ae_evport.c
Memory recovery
All the data of Reids is stored in memory. In some cases, the occupied memory space needs to be recycled. There are two main types of memory recovery: one is key expiration, and the other is memory usage reaching the maximum limit (max? Memory) to trigger memory obsolescence.
Expiration Policies
To achieve key expiration, we have several ideas.
- Timed expiration (active elimination)
Each key setting expiration time needs to create a timer, which will be cleared immediately after expiration time. This strategy can immediately clear the expired data, which is very memory friendly; however, it will consume a lot of CPU resources to process the expired data, thus affecting the response time and throughput of the cache.
- Inertia expiration (passive elimination)
Only when a key is accessed will it be judged whether the key has expired. If it expires, it will be cleared. This strategy can save CPU resources as much as possible, but it is not very memory friendly. In extreme cases, a large number of expired keys may not be accessed again, so they will not be cleared and occupy a large amount of memory.
For example, String will call expireifneed in getCommand
db.c expireIfNeeded(redisDb *db,robj *key)
/* This function is called when we are going to perform some operation * in a given key, but such key may be already logically expired even if * it still exists in the database. The main way this function is called * is via lookupKey*() family of functions. * * The behavior of the function depends on the replication role of the * instance, because slave instances do not expire keys, they wait * for DELs from the master for consistency matters. However even * slaves will try to have a coherent return value for the function, * so that read commands executed in the slave side will be able to * behave like if the key is expired even if still present (because the * master has yet to propagate the DEL). * * In masters as a side effect of finding a key which is expired, such * key will be evicted from the database. Also this may trigger the * propagation of a DEL/UNLINK command in AOF / replication stream. * * The return value of the function is 0 if the key is still valid, * otherwise the function returns 1 if the key is expired. */ int expireIfNeeded(redisDb *db, robj *key) { if (!keyIsExpired(db,key)) return 0; /* If we are running in the context of a slave, instead of * evicting the expired key from the database, we return ASAP: * the slave key expiration is controlled by the master that will * send us synthesized DEL operations for expired keys. * * Still we try to return the right information to the caller, * that is, 0 if we think the key should be still valid, 1 if * we think the key is expired at this time. */ if (server.masterhost != NULL) return 1; /* Delete the key */ server.stat_expiredkeys++; propagateExpire(db,key,server.lazyfree_lazy_expire); notifyKeyspaceEvent(NOTIFY_EXPIRED, "expired",key,db->id); return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) : dbSyncDelete(db,key); }
In the second case, each time a key is written, it is found that there is not enough memory. Call activeexpircycle to release some memory.
expire.c activeExpireCycle(inttype)
/* Try to expire a few timed out keys. The algorithm used is adaptive and * will use few CPU cycles if there are few expiring keys, otherwise * it will get more aggressive to avoid that too much memory is used by * keys that can be removed from the keyspace. * * No more than CRON_DBS_PER_CALL databases are tested at every * iteration. * * This kind of call is used when Redis detects that timelimit_exit is * true, so there is more work to do, and we do it more incrementally from * the beforeSleep() function of the event loop. * * Expire cycle type: * * If type is ACTIVE_EXPIRE_CYCLE_FAST the function will try to run a * "fast" expire cycle that takes no longer than EXPIRE_FAST_CYCLE_DURATION * microseconds, and is not repeated again before the same amount of time. * * If type is ACTIVE_EXPIRE_CYCLE_SLOW, that normal expire cycle is * executed, where the time limit is a percentage of the REDIS_HZ period * as specified by the ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC define. */ void activeExpireCycle(int type) { /* This function has some global state in order to continue the work * incrementally across calls. */ static unsigned int current_db = 0; /* Last DB tested. */ static int timelimit_exit = 0; /* Time limit hit in previous call? */ static long long last_fast_cycle = 0; /* When last fast cycle ran. */ int j, iteration = 0; int dbs_per_call = CRON_DBS_PER_CALL; long long start = ustime(), timelimit, elapsed; /* When clients are paused the dataset should be static not just from the * POV of clients not being able to write, but also from the POV of * expires and evictions of keys not being performed. */ if (clientsArePaused()) return; if (type == ACTIVE_EXPIRE_CYCLE_FAST) { /* Don't start a fast cycle if the previous cycle did not exit * for time limit. Also don't repeat a fast cycle for the same period * as the fast cycle total duration itself. */ if (!timelimit_exit) return; if (start < last_fast_cycle + ACTIVE_EXPIRE_CYCLE_FAST_DURATION*2) return; last_fast_cycle = start; } /* We usually should test CRON_DBS_PER_CALL per iteration, with * two exceptions: * * 1) Don't test more DBs than we have. * 2) If last time we hit the time limit, we want to scan all DBs * in this iteration, as there is work to do in some DB and we don't want * expired keys to use memory for too much time. */ if (dbs_per_call > server.dbnum || timelimit_exit) dbs_per_call = server.dbnum; /* We can use at max ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC percentage of CPU time * per iteration. Since this function gets called with a frequency of * server.hz times per second, the following is the max amount of * microseconds we can spend in this function. */ timelimit = 1000000*ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC/server.hz/100; timelimit_exit = 0; if (timelimit <= 0) timelimit = 1; if (type == ACTIVE_EXPIRE_CYCLE_FAST) timelimit = ACTIVE_EXPIRE_CYCLE_FAST_DURATION; /* in microseconds. */ /* Accumulate some global stats as we expire keys, to have some idea * about the number of keys that are already logically expired, but still * existing inside the database. */ long total_sampled = 0; long total_expired = 0; for (j = 0; j < dbs_per_call && timelimit_exit == 0; j++) { int expired; redisDb *db = server.db+(current_db % server.dbnum); /* Increment the DB now so we are sure if we run out of time * in the current DB we'll restart from the next. This allows to * distribute the time evenly across DBs. */ current_db++; /* Continue to expire if at the end of the cycle more than 25% * of the keys were expired. */ do { unsigned long num, slots; long long now, ttl_sum; int ttl_samples; iteration++; /* If there is nothing to expire try next DB ASAP. */ if ((num = dictSize(db->expires)) == 0) { db->avg_ttl = 0; break; } slots = dictSlots(db->expires); now = mstime(); /* When there are less than 1% filled slots getting random * keys is expensive, so stop here waiting for better times... * The dictionary will be resized asap. */ if (num && slots > DICT_HT_INITIAL_SIZE && (num*100/slots < 1)) break; /* The main collection cycle. Sample random keys among keys * with an expire set, checking for expired ones. */ expired = 0; ttl_sum = 0; ttl_samples = 0; if (num > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP) num = ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP; while (num--) { dictEntry *de; long long ttl; if ((de = dictGetRandomKey(db->expires)) == NULL) break; ttl = dictGetSignedIntegerVal(de)-now; if (activeExpireCycleTryExpire(db,de,now)) expired++; if (ttl > 0) { /* We want the average TTL of keys yet not expired. */ ttl_sum += ttl; ttl_samples++; } total_sampled++; } total_expired += expired; /* Update the average TTL stats for this database. */ if (ttl_samples) { long long avg_ttl = ttl_sum/ttl_samples; /* Do a simple running average with a few samples. * We just use the current estimate with a weight of 2% * and the previous estimate with a weight of 98%. */ if (db->avg_ttl == 0) db->avg_ttl = avg_ttl; db->avg_ttl = (db->avg_ttl/50)*49 + (avg_ttl/50); } /* We can't block forever here even if there are many keys to * expire. So after a given amount of milliseconds return to the * caller waiting for the other active expire cycle. */ if ((iteration & 0xf) == 0) { /* check once every 16 iterations. */ elapsed = ustime()-start; if (elapsed > timelimit) { timelimit_exit = 1; server.stat_expired_time_cap_reached_count++; break; } } /* We don't repeat the cycle if there are less than 25% of keys * found expired in the current DB. */ } while (expired > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP/4); } elapsed = ustime()-start; latencyAddSampleIfNeeded("expire-cycle",elapsed/1000); /* Update our estimate of keys existing but yet to be expired. * Running average with this sample accounting for 5%. */ double current_perc; if (total_sampled) { current_perc = (double)total_expired/total_sampled; } else current_perc = 0; server.stat_expired_stale_perc = (current_perc*0.05)+ (server.stat_expired_stale_perc*0.95); }
- Expired regularly Source code: server.h
/* Redis database representation. There are multiple databases identified * by integers from 0 (the default database) up to the max configured * database. The database number is the 'id' field in the structure. */ typedef struct redisDb { dict *dict; /* All health values are right */ dict *expires; /* Key value pair with expiration time set */ dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/ dict *ready_keys; /* Blocked keys that received a PUSH */ dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */ int id; /* Database ID */ long long avg_ttl; /* Average TTL, just for stats */ list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */ } redisDb;
At regular intervals, a certain number of keys in the expires Dictionary of a certain number of databases will be scanned and the expired keys will be cleared. This strategy is a compromise between the first two. By adjusting the time interval and the limited time of each scan, the CPU and memory resources can achieve the optimal balance effect under different circumstances.
In Redis, two expiration policies, lazy expiration and periodic expiration, are used at the same time.
If it doesn't expire, what if Redis is full of memory?
Write prompt OOM error information without affecting reading.
Elimination strategy
Redis's memory elimination strategy refers to that when the memory usage reaches the maximum memory limit, the elimination algorithm needs to be used to decide which data is cleaned up to ensure the storage of new data.
redis.conf
#maxmemory-policy noeviction
#volatile-lru -> EvictusingapproximatedLRUamongthekeyswithanexpireset. #allkeys-lru -> EvictanykeyusingapproximatedLRU. #volatile-lfu -> EvictusingapproximatedLFUamongthekeyswithanexpireset. #allkeys-lfu -> EvictanykeyusingapproximatedLFU. #volatile-random -> Removearandomkeyamongtheoneswithanexpireset. #allkeys-random -> Removearandomkey,anykey. #volatile-ttl -> Removethekeywiththenearestexpiretime(minorTTL) #noeviction -> Don'tevictanything,justreturnanerroronwriteoperations.
LRU, least recently used. Judge the time that has been used recently, and the farthest data at present will be eliminated preferentially.
LFU, least frequently used, added in version 4.0.
| strategy | Meaning |
|---|---|
| volatile-lru | According to the LRU algorithm, delete the key with the timeout attribute set until enough memory is freed up. If there is no key object to delete, fallback to the noeviction policy. |
| allkeys-lru | According to the LRU algorithm, delete the key, no matter whether the data has set the timeout attribute or not, until enough memory is freed up. |
| volatile-lfu | Select the least commonly used key with expiration time. |
| allkeys-lfu | Select the least commonly used of all the keys, regardless of whether the timeout attribute is set for the data. |
| volatile-random | Select randomly in the key with expiration time. |
| allkeys-random | Randomly delete all keys until enough memory is freed up. |
| volatile-ttl | According to the ttl property of the key value object, delete the data that will expire recently. If not, go back to the noeviction policy. |
| noeviction | By default, no data will be deleted, all write operations will be rejected and client error information (error) oomcmandnot allowed when used memory will be returned. At this time, Redis only responds to read operations. |
If no key that meets the preconditions is eliminated, then volatile LRU, volatile random, and volatile TTL are equivalent to no eviction.
It is recommended to use volatile LRU to remove the least recently used key in the case of normal service.
What are the problems if RedisLRU is implemented based on traditional LRU algorithm?
Additional data structure storage is required, which consumes memory.
RedisLRU improves the traditional LRU algorithm and adjusts the accuracy of the algorithm by random sampling.
If the elimination strategy is LRU, then randomly select m keys from the database according to the configured sampling value maxmemory "samples (the default is 5), and eliminate the cache data corresponding to the key with the lowest heat. Therefore, the larger the value of the sampling parameter m is, the more accurate the cache data to be eliminated can be found, but it also consumes more CPU calculation and reduces the execution efficiency.
How to find the lowest heat data?
All object structures in Redis have an lru field, which uses the lower 24 bits of unsigned to record the heat of the object. lru values are recorded when the object is created. lru values are also updated when accessed. But instead of getting the current timestamp of the system, it is set to the value of the global variable server.lruclock.
Source code: server.h
typedef struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or * LFU data (least significant 8 bits frequency * and most significant 16 bits access time). */ int refcount; void *ptr; } robj;
How does the value of server.lruclock come from?
Redis has a function serverCron for timing processing. By default, the function updateCachedTime is called every 100ms to update the value of server.lruclock of the global variable. It records the current unix timestamp.
Source code: server.c
/* We take a cached value of the unix time in the global state because with * virtual memory and aging there is to store the current time in objects at * every object access, and accuracy is not needed. To access a global var is * a lot faster than calling time(NULL) */ void updateCachedTime(void) { time_t unixtime = time(NULL); atomicSet(server.unixtime,unixtime); server.mstime = mstime(); /* To get information about daylight saving time, we need to call localtime_r * and cache the result. However calling localtime_r in this context is safe * since we will never fork() while here, in the main thread. The logging * function will call a thread safe version of localtime that has no locks. */ struct tm tm; localtime_r(&server.unixtime,&tm); server.daylight_active = tm.tm_isdst; }
Why not get the exact time and put it in the global variable? Will there be no delay?
In this way, when the lru heat value of the data is updated in the function lookupKey, the system function time is not called every time, and the execution efficiency can be improved.
OK, when there is LRU field value in the object, you can evaluate the heat of the object.
The function estimateObjectIdleTime evaluates the lru heat of the specified object. The idea is that the larger the difference between the lru value of the object and the global server.lruclock (the longer it is not updated), the lower the heat of the object.
Source evict.c
/* Given an object returns the min number of milliseconds the object was never * requested, using an approximated LRU algorithm. */ unsigned long long estimateObjectIdleTime(robj *o) { unsigned long long lruclock = LRU_CLOCK(); if (lruclock >= o->lru) { return (lruclock - o->lru) * LRU_CLOCK_RESOLUTION; } else { return (lruclock + (LRU_CLOCK_MAX - o->lru)) * LRU_CLOCK_RESOLUTION; } }
server.lruclock has only 24 bits, which can be stored for 194 days in seconds. When it exceeds the maximum time that 24bit can express, it will start from scratch.
server.h
#define LRU_CLOCK_MAX ((1<<LRU_BITS)-1) /* Max value of obj->lru */
In this case, the lru of the object may be larger than that of server.lruclock. If this happens, two keys will be added rather than subtracted to find the longest key.
Why not use the conventional hash table + two-way linked list? Need additional data structure, consume resources. The RedisLRU algorithm can already approach the traditional LRU algorithm when the sample is 10.

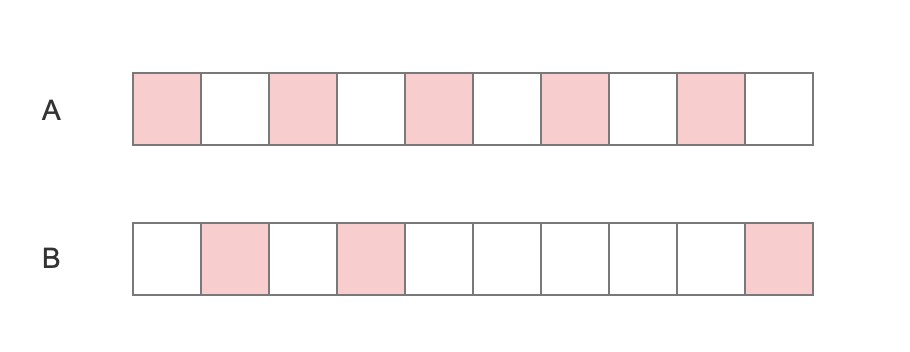
In addition to consuming resources, what are the problems with traditional LRU s?
As shown in the figure, suppose A is visited five times in 10 seconds, and B is visited three times in 10 seconds. Because B was last visited later than A, in the same case, A was recycled first.
LFU
server.h
typedef struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or * LFU data (least significant 8 bits frequency * and most significant 16 bits access time). */ int refcount; void *ptr; } robj;
When these 24bits are used as LFU, they are divided into two parts:
- The upper 16 bits are used to record the access time (in minutes, ldt, lastdecrementtime)
- The lower 8 bits are used to record the access frequency, which is called counter (log C, logistic counter for short)
Counter is implemented with probability based logarithm counter, 8 bits can represent millions of access frequency.
When the object is read and written, the lfu value is updated. db.c——lookupKey
/* Update LFU when an object is accessed. * Firstly, decrement the counter if the decrement time is reached. * Then logarithmically increment the counter, and update the access time. */ void updateLFU(robj *val) { unsigned long counter = LFUDecrAndReturn(val); counter = LFULogIncr(counter); val->lru = (LFUGetTimeInMinutes()<<8) | counter; }
The growth rate is determined by the larger the LFU log factor is, the slower the counter grows
redis.conf configuration file #lfu-log-factor10
If the counter only increases, it will not decrease, and it will not reflect the heat of the object. How does the counter decrement when it is not accessed?
The reduced value is controlled by the attenuation factor LFU deck time (minutes). If the value is 1, N minutes will be reduced if there is no access.
#lfu-decay-time 1