preface
Students who have read the Alibaba Java development manual should notice that there is a mandatory specification in the MySQL index specification:

This article will analyze why the index on varchar must specify the index length?
index structure
To understand the reason, we must first have a certain understanding of the index structure. Generally, we will use the InnoDB storage engine, and its corresponding index structure is B+TREE.
The biggest difference between B+TREE and other binary trees is that the degree of nodes can be set greatly. MySQL defines 16KB as one page, and one page is a node of the tree.
In the following figure, in the root node of the tree, 7 and 13 correspond to the saved index field values.
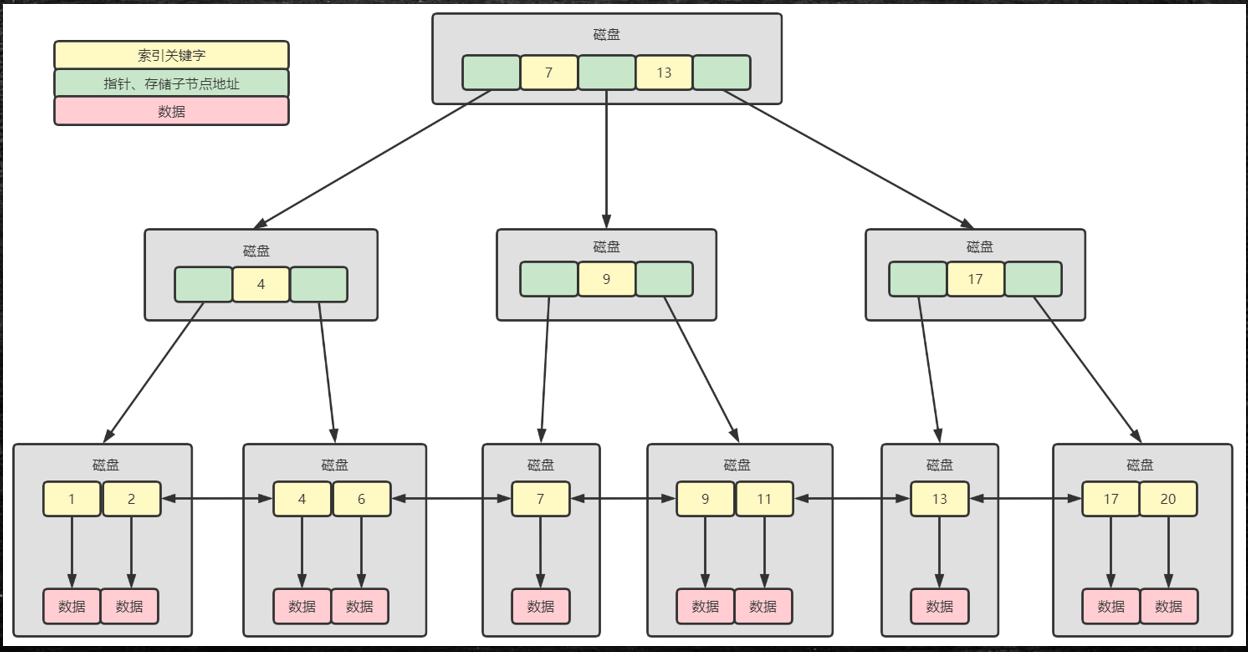
Then, since the size of a page is a constant 16KB, it means that the smaller the space occupied by the index field value, the more a page can be saved, which is finally reflected in reducing the number of disk IO.
Here we might as well give an example:
Assuming that our index field is of type int and the single row data size is 1KB, if the height of the tree is 3 layers, the data rows can be stored. The calculation method is as follows:
int type Occupation: 4byte
Index pointer Occupation: 6byte
Leaf nodes of the third layer: 16kb/1kb = 16
Layer 1 and layer 2 nodes, each node can save: 16kb/(4byte+6byte) ≈ 1600
1600 * 1600 * 16 ≈ 40 million pieces
If the index field is now changed to bigint type, the approximate amount of data that can be stored is:
1170 * 1170 * 16 ≈ 20 million pieces
It can be seen that assuming that the height of the tree remains unchanged, the size of the space occupied by the index field will directly affect the amount of data storage.
If the index length is determined
According to the above analysis, the smaller the length of the index field, the better? Of course not!
Another example:
Suppose there are two pieces of data, the field value of A is 20200101000000, and the field value of B is 2020010100001
As like as two peas, the first 12 of the two data are the same. If only the top 12 data is introduced, it will be indexed to two identical data, and finally, it is not allowed to filter from the two data.
It should be noted that if the data does not match and the feature of overwriting the index cannot be used, it must be filtered back to the clustered index.
The index will not be overwritten after the index length is specified. Case demonstration:
drop table t_demo;
CREATE TABLE t_demo (
id INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 'Self increasing id',
name VARCHAR(20) DEFAULT NULL COMMENT 'full name',
phone char(11) DEFAULT NULL COMMENT 'cell-phone number',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
alter table t_demo add index idx_phone(phone(3));
INSERT into t_demo (name,phone) VALUES ('zz','''13900000000');
INSERT into t_demo (name,phone) VALUES ('ls','13700000000');
INSERT into t_demo (name,phone) VALUES ('ls2','13800000000');
INSERT into t_demo (name,phone) VALUES ('zz','''13900000001');
INSERT into t_demo (name,phone) VALUES ('ls','13700000002');
INSERT into t_demo (name,phone) VALUES ('ls2','13800000003');
explain select phone from t_demo where phone = '13900000001';
Overwrite index not used

drop table t_demo;
CREATE TABLE t_demo (
id INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 'Self increasing id',
name VARCHAR(20) DEFAULT NULL COMMENT 'full name',
phone char(11) DEFAULT NULL COMMENT 'cell-phone number',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- Index full field value
alter table t_demo add index idx_phone(phone(11));
INSERT into t_demo (name,phone) VALUES ('zz','''13900000000');
INSERT into t_demo (name,phone) VALUES ('ls','13700000000');
INSERT into t_demo (name,phone) VALUES ('ls2','13800000000');
INSERT into t_demo (name,phone) VALUES ('zz','''13900000001');
INSERT into t_demo (name,phone) VALUES ('ls','13700000002');
INSERT into t_demo (name,phone) VALUES ('ls2','13800000003');
explain select phone from t_demo where phone = '13900000001';
Use overlay index

Therefore, it is not that the smaller the index field is, the better. Instead, it should be evaluated according to the calculation of index discrimination.
Query index field discrimination method:
SELECT count(DISTINCT LEFT(order_no, 20)) / count(*) AS '20', count(DISTINCT LEFT(order_no, 22)) / count(*) AS '22', count(DISTINCT LEFT(order_no, 24)) / count(*) AS '24', count(DISTINCT LEFT(order_no, 26)) / count(*) AS '26', count(DISTINCT LEFT(order_no, 28)) / count(*) AS '28', count(DISTINCT LEFT(order_no, 30)) / count(*) AS '30', count(DISTINCT LEFT(order_no, 32)) / count(*) AS '32' FROM test;

order_ The length of no field is 32. It can be seen that the discrimination has been close to 1 since the acquisition length is 26, and the cost performance is not high when the length is increased.
Index for order_ It is appropriate to set the index length to 26 in the no field.
Discrimination tips
The characteristic of some fields is that most of the front parts are the same, but the last few bits are different. For such fields, we can't keep the first few bits as index fields. In fact, they can be stored in reverse order.
In addition to storing in reverse order, you can also use the Hash method, but pay attention to the problem of Hash conflict
summary
In Ali's Java development manual, it is mandatory to specify the index length when establishing an index on the varchar field. However, through our analysis, we can see that not all the indexed fields are applicable, such as those with low discrimination or those that can be implemented by extensive use of overlay index. I think the development manual emphasizes the universal scenario, How to use it should be determined by ourselves after we understand the principle.