Recently, a friend is preparing for an interview. We will discuss some interview questions in the group. Every time I will be hit hard, and I can't answer many questions. In normal development, Google and third parties use it very smoothly, which seems to solve the problem. In retrospect, there is no progress in technology. For example, I know that pictures use three-level cache and Lru algorithm, but if I don't use glide and write a picture cache tool class, I find my thinking is not clear. Taking the write memory cache as an example, I will think of using strong reference cache and soft reference cache to realize it. What classes are the best for strong reference and soft reference to realize cache? I have to check this and know that LruCache and LinkedHashMap can be used to cache data. Why does LruCache choose LinkedHashMap instead of other storage classes? Ask more why, and you'll find that you don't know anything. I also understand why many companies pay attention to the underlying implementation principles and algorithms during the interview. Only by understanding the implementation principle, can we learn the essence, appreciate the loading framework written by experts, and apply the medicine to the case when encountering problems, instead of trying every online answer like a headless fly, and we still don't know why.
In order to understand the above series of problems, I have read the relevant contents about HashMap, LinkedHashMap, Lru and the implementation of memory cache. Now I will organize these into articles.
What I said earlier
Before reading the articles on the underlying principles of HashMap and LinkedHashMap, it's best to review the basic knowledge of array, single linked list, double linked list, hash table, hash function and hash algorithm, which is very helpful to understand HashMap and LinkedHashMap. This article only talks about the implementation of HashMap, LinkedHashMap and cache, and does not fully explain these knowledge points. After reading it, you will know why LinkedHashMap is used in LruCache.
HashMap
HashMap implements hash table based on array, and the backbone is array. Add or find an element in the array. Through the array index (that is, the index), the operation can be completed at one time.
Array is equivalent to internal storage space, and the index of array is just like the address of memory. Each record of HashMap is an Entry < K, V > object. Each Entry contains a key value pair. These objects are stored in the array. Now let's see how to calculate the memory address of each storage object.
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}Hash value = (hashcode) ^ (hashcode > > > 16). Hashcode gives hashcode an exclusive or operation that shifts 16 bits to the right, and uses the hashcode of key to calculate the hash value. The next step is to calculate the subscript using the hash value.
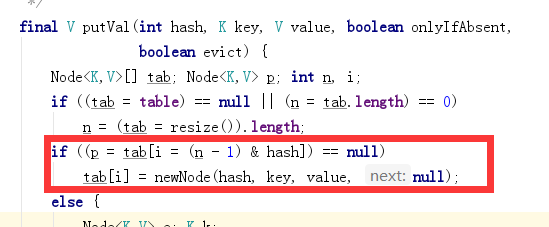
The above code is the source code of the put key value pair. The code in the red part is the code to get the subscript. It seems a little difficult to understand. Rewrite it
i = (n - 1) & hash;//Hash is the hash value calculated in the previous step. n is the length of the underlying array. Use the & operator to calculate the value of i
p = tab[i];//Use the calculated value of i as a subscript to extract elements from the array
if(p == null){//If this element is null, use key and value to construct a Node object and put it into the position with index i in the array
tab[i] = newNode(hash, key, value, null);
}
I is the subscript calculated by the hash value, that is, the storage location. We saw the if statement of the source code above. When tab[i] is null, it directly stores the object. What if it is not null? The relevant source code is as follows
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
......
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// If the array elements are found, and the hash es are equal and the key s are equal, they will be overwritten directly
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// The array element forms the object of red black tree structure after the length of the linked list is > 8
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// The array elements have equal hash es and different key s, and the length of the linked list is less than 8 Traverse to find elements, overwrite if any, and create new if none
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// New data element in linked list
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// The linked list length > = 8 structure is transformed into a red black tree
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
Copy codeIgnore the conversion of red black tree and summarize the above code:
1. Judge whether there are elements with the same hashcode and key in the currently determined index position. If there are elements with the same hashcode and key, the new value overwrites the original old value and returns the old value.
2. If the same hashcode exists, the index positions they determine will be the same. At this time, judge whether their key s are the same. If not, there will be a hash conflict.
3. In case of hash conflict, the single linked list is introduced. Traverse to find elements, overwrite if there is one, and create if there is no one.
The above is the storage entry, and the process is complex. Obtaining data is relatively simple. The basic process is as follows:
1. Get the array subscript through the hashCode and addressing algorithm of the key. If the key and hash in the array element are equal, it will be returned directly.
2. If they are not equal and there are linked list elements at the same time, traverse the linked list elements for matching and return.
HashMap does not have hash conflicts and does not form a single linked list. HashMap finds elements quickly, and the get() method can directly locate elements. After a single linked list appears, instead of an Entry, an Entry chain is stored in the located single bucket. The system can only traverse each Entry in order until the Entry to be searched is found. If the Entry to be searched is located at the end of the Entry chain (the Entry is first placed in the bucket), the system must cycle to the end to find the element. In order to solve the performance problems caused by the long linked list, jdk1 8 at jdk1 On the basis of 7, red black tree is added for optimization. When the linked list exceeds 8, the linked list will be converted into a red black tree. The performance of HashMap will be improved by using the characteristics of rapid addition, deletion, modification and query of red black tree, in which the insertion, deletion, search and other algorithms of red black tree will be used.
Put a structure diagram of HashMap and the diagram found on the Internet
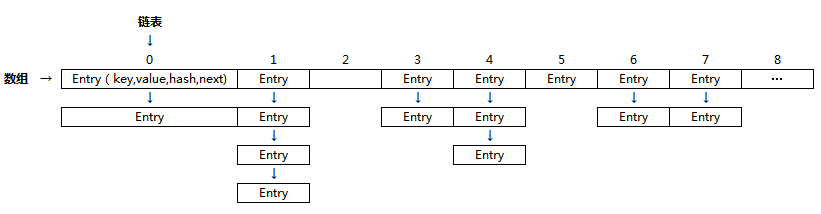
We can locate the position of each index in the array and see that there are buckets. The bucket may contain an Entry or an Entry chain.
To summarize the HashMap feature
1.HashMap stores key value pairs to achieve fast access and allow null s.
2. The key value cannot be repeated.
3. The bottom layer is a hash table, which does not guarantee order (such as the order of insertion)
LinkedHashMap
As mentioned above, HashMap can achieve fast access, but it is out of order. The order of elements obtained by traversing HashMap is not the order in which they were originally placed in HashMap. In our practical application, we need to achieve fast access and orderly. At this time, LinkedHashMap is a good choice. LinkedHashMap is a subclass of HashMap. It has high efficiency in order (insertion order or access order), element addition, modification and deletion.
The storage structure of LinkedHashMap is a double linked list. The data operation is the same as HashMap. The big difference is the Entry. Let's take a look at the properties in the Entry of LinkedHashMap
1,K key
2,V value
3,Entry<K, V> next
4,int hash
5,Entry<K, V> before
6,Entry<K, V> after
In the first four, the red part inherits HashMap Entry; The latter two are unique to LinkedHashMap. next is used to maintain the order of entries connected at the table specified by HashMap, and before and after are used to maintain the order of entry insertion. The structure diagram of LinkedHashMap is as follows:
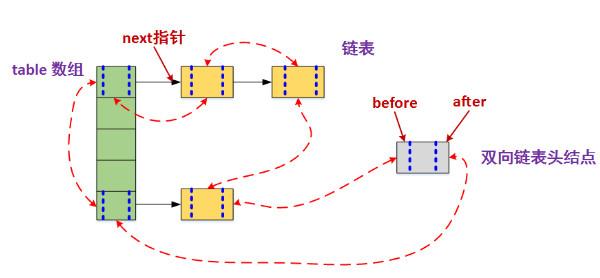
There is no method to operate the data structure in LinkedHashMap, that is, LinkedHashMap operates the data structure (such as put ting a data), which is exactly the same as the method of HashMap operating the data, but there are some differences in details. I won't make a detailed description here. You can look at the source code by yourself. If this part is not very clear, it is suggested to look at some knowledge of the double linked list first. LinkedHashMap is the implementation method of HashMap+LinkedList. HashMap maintains the data structure and LinkList maintains the data insertion order.
Picture cache
The above content introduces HashMap mainly to understand LinkedHashMap and summarize the advantages of LinkedHashMap in simple words, that is, the efficiency of element addition, modification and deletion is relatively high, and the order can be insertion order or access order. LinkedHashMap is used in LruCache class. The internal implementation principle of LruCache is based on LinkedHashMap, and the core is Lru algorithm. Soft reference caching can also use LinkedHashMap to access data. Talk about the simple idea of image caching, and you will understand the advantages of LinkedHashMap.
1. When the strong reference cache is full, transfer the recently unused pictures into the soft reference cache according to the LRU algorithm
2. When the number of soft references is greater than 20 (the number is determined by yourself), the oldest soft references will be removed from the linked hash table
Because LinkedHashMap is ordered, and the order can be the insertion order and access order, it is very simple to find the pictures that have not been used recently. You only need to access and find the pictures in strong references every time and move them to the front of LinkedHashMap. In this way, the more front, the more recently used. When the memory is full, Take the picture from the last side of LinkedHashMap, which is the picture that has not been used recently. Similarly, LinkedHashMap is used to store soft references. It can easily remove old soft references from the linked hash table. The internal implementation of LruCache uses LinkedHashMap, which ensures the consistency of the order of the data when inserting and when taking out, and has good efficiency.
Now there are powerful third parties to help us solve the image cache, but I still want to paste the memory cache code written by Ren Yugang. Personally, I think it is necessary to learn.
public class ImageMemoryCache {
private static final String TAG = "ImageMemoryCache";
private static LruCache<String, Bitmap> mLruCache;//Strong reference cache
private static LinkedHashMap<String , SoftReference<Bitmap>> mSoftCache; //Soft reference cache
private static final int LRU_CACHE_SIZE = 4 * 1024 * 1024;//Strong reference cache
private static final int SOFT_CACHE_NUM = 20;//Number of soft reference caches
//Here, the strong reference cache and weak reference cache are initialized respectively
public ImageMemoryCache(){
mLruCache = new LruCache<String ,Bitmap>(LRU_CACHE_SIZE){
@Override
protected int sizeOf(String key, Bitmap value) {
if (value != null){
return value.getRowBytes() * value.getHeight();
}
return 0;
}
@Override
protected void entryRemoved(boolean evicted, String key, Bitmap oldValue, Bitmap newValue) {
super.entryRemoved(evicted, key, oldValue, newValue);
if (oldValue != null){
//When the strong reference cache is full, the pictures that have not been used recently will be transferred to this soft reference cache according to the LRU algorithm
Log.d(TAG,"LruCache is full,move to SoftReferenceCache");
mSoftCache.put(key,new SoftReference<Bitmap>(oldValue));
}
}
};
mSoftCache = new LinkedHashMap<String, SoftReference<Bitmap>>(SOFT_CACHE_NUM, 0.7f,true){
private static final long serialVersionUID = 1L;
//When the number of soft references is greater than 20, the oldest soft reference will be removed from the linked hash table
@Override
protected boolean removeEldestEntry(Entry<String, SoftReference<Bitmap>> eldest) {
if (size() > SOFT_CACHE_NUM){
Log.d(TAG,"shoudle remove the eldest from SoftReference");
return true;
}
return false;
}
};
}
//Get pictures from cache
public Bitmap getBitmapFromMemory(String url){
Bitmap bitmap;
//Get from strong reference first
synchronized (mLruCache){
bitmap = mLruCache.get(url);
if (bitmap != null){
//If found, move the element to the front of the LinkedHashMap to ensure that it is deleted last in the LRU algorithm
mLruCache.remove(url);
mLruCache.put(url,bitmap);
Log.d(TAG,"get bmp from LruCache,url =" +url);
return bitmap;
}
}
//If it cannot be found in the strong reference cache, find it in the soft reference cache, and move it from the soft reference to the strong reference after finding it
synchronized (mSoftCache){
SoftReference<Bitmap> bitmapReference = mSoftCache.get(url);
if (bitmapReference != null){
bitmap = bitmapReference.get();
if (bitmap != null){
//Move picture back to LruCache
mLruCache.put(url,bitmap);
mSoftCache.remove(url);
Log.d(TAG,"get bmp from SoftRefrenceCache, url = "+url);
return bitmap;
}else {
mSoftCache.remove(url);
}
}
}
return null;
}
//Add picture to cache
public void addBitmapToMemory(String url,Bitmap bitmap){
if (bitmap != null){
synchronized (mLruCache){
mLruCache.put(url,bitmap);
}
}
}
public void clearCache(){
mSoftCache.clear();
}
}
Copy codesummary
Android has a lot of knowledge, such as HashMap and LinkedHashMap. They will repeatedly look at the underlying implementation, but forget it after a period of time. If they are understood in combination with practical examples, it will be easier to understand its advantages. Many third parties have provided us with great help. We should not only be able to use it, but also understand how it is implemented. Why do we choose this way to implement it? Think more about why and understand. Maybe you can talk freely during the interview.
Author: honey Cake
Link: https://juejin.cn/post/6844904120462245901