Environmental preparation
System centos 7
java 1.8
hadoop 2.7
ES 7.15.2 (for installation of ES stand-alone version, refer to: https://blog.csdn.net/weixin_36340771/article/details/121389741 )
Prepare hadoop local running environment
Get Hadoop files
Link: https://pan.baidu.com/s/1MGriraZ8ekvzsJyWdPssrw
Extraction code: u4uc
Configure HADOOP_HOME
Extract the above files and configure HADOOP_HOME, pay attention to changing the address.
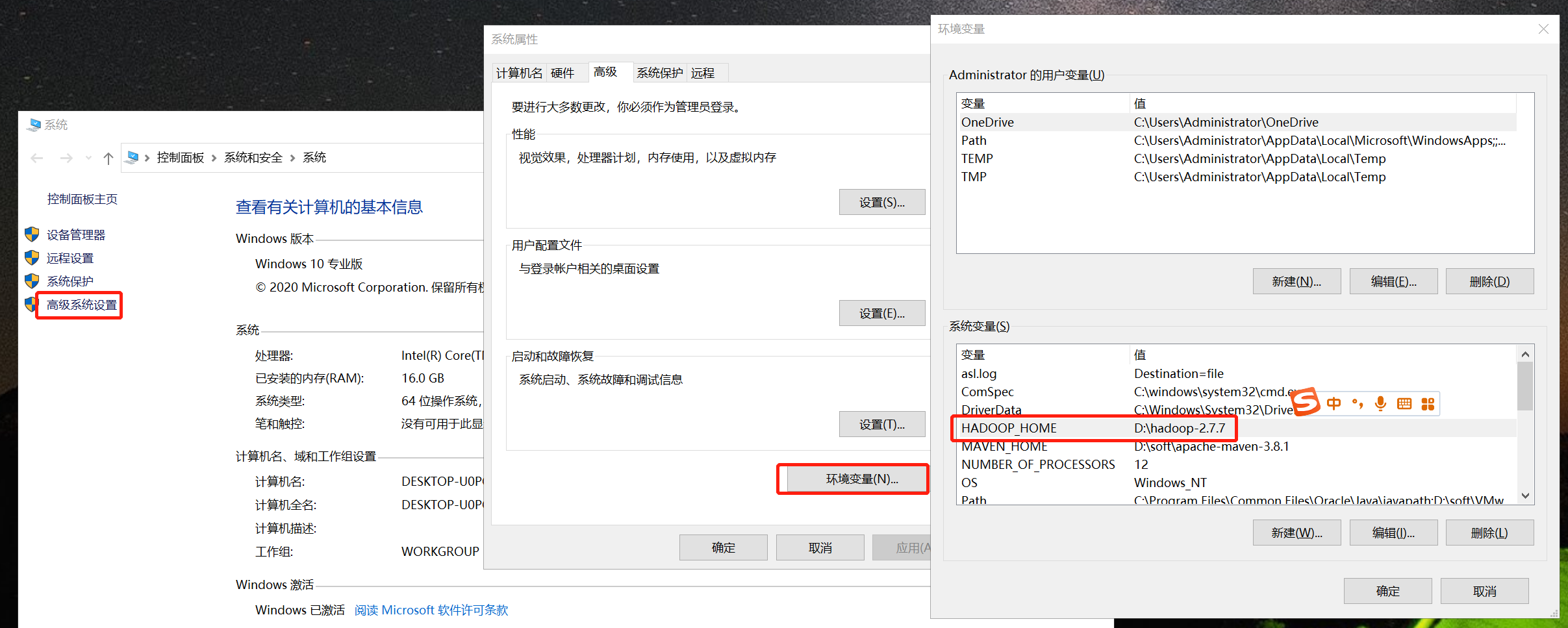
Get engineering code
https://github.com/BaoPiao/elasticsearch_demo
Read HDFS write ES
Read HDFS data through FileInputFormat, then convert the data to MapWritable data type through Mapper, and finally write the data to ES through EsOutputFormat.
Parameter description
Basic parameters
Network parameters
Es cluster information of es.nodes connection
es.port the port number of the es cluster. The default is 9200
The prefix information of es.nodes.path.prefix connection is empty by default (for example, if you want to write to es.node:9200/custom/path/prefix every time, it can be written as / custom/path/prefix here)
Write parameters
es.resource specifies the es index
es.resource = twitter/tweet #The index is called twitter and the type is tweet
es.resource.write the default value is es.resource
Support writing to different types according to data (media_type is a field)
es.resource.write = my-collection/{media_type}
According to the data, it is written into different indexes. In addition, it also supports date types for rolling generation of log indexes. For details, see reference 2.
es.resource.write = my-collection_{media_type}
Document related parameters
es.input.json is false by default, and the input file format is JSON
es.write.operation is index by default
index(default) will be replaced if it already exists
If create already exists, an exception will be reported
update updates the existing. If there is no exception, an exception is reported
If upsert does not exist, it is inserted. If it exists, it is updated
es.output.json is false by default. Is the output file format JSON
es.ingest.pipeline is none by default and specifies the processing pipeline
es.mapping.id specifies the document ID. the field name is filled in here. It is blank by default
es.mapping.parent specifies the parent document. Fill in the field name or a constant here
es.mapping.version specifies the version number. Fill in the field name or a constant here
es.mapping.include specifies which fields are written to ES
es.mapping.exclude specifies which fields are not written to ES
Code reference
Only the driver code is posted here. For the rest, please refer to GitHub: https://github.com/BaoPiao/elasticsearch_demo
public class ElasticsearchHadoop {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
conf.setBoolean("mapred.map.tasks.speculative.execution", false);
conf.setBoolean("mapred.reduce.tasks.speculative.execution", false);
conf.set("es.nodes", "192.168.10.108:9200");
conf.set("es.resource", "/artists_2");
conf.set("es.write.operation", "upsert");
conf.set("es.mapping.include", "id");
conf.set("es.mapping.id", "id");
Job job = Job.getInstance(conf);
job.setJarByClass(ElasticsearchHadoop.class);
job.setOutputFormatClass(EsOutputFormat.class);
job.setMapperClass(EsMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(MapWritable.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.10.108:9000/test"));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
Read ES write HDFS
Read ES data through esinpformat, and the returned data is < Text, MapWritable >, where Text is the key, and MapWritable contains field and field value information. Finally, write your own Reduce to HDFS.
Parameter description
Metadata information
es.read.metadata is false by default. Whether to return original data information, such as document id, version number, etc
es.read.metadata.field is by default_ Metadata field. If and only if es.read.metadata is set to true, metadata information is returned, and the data is encapsulated by map
es.read.metadata.version is false by default. If and only if es.read.metadata is set to true, the value will take effect and the version number will be returned.
Query parameters
es.resource specifies the es index
es.resource = twitter/tweet #The index is called twitter and the type is tweet
es.query is empty by default
- uri query method
- dsl query method (recommended)
- Read file mode
# uri (or parameter) query
es.query = ?q=costinl
# query dsl
es.query = { "query" : { "term" : { "user" : "costinl" } } }
# external resource
es.query = org/mypackage/myquery.json
es.resource.read the default value is es.resource
es.resource.read the default value is es.resource
Code reference
Only the driver part is posted here. For details, please refer to GitHub: https://github.com/BaoPiao/elasticsearch_demo
public class ReadElasticsearch {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
conf.set("es.nodes", "192.168.10.108:9200");
conf.set("es.resource", "artists_2");
conf.set("es.read.metadata", "true");
conf.set("es.read.metadata.field", "_metadata");
conf.set("es.query", "{\n" +
" \"query\":{\n" +
" \"match_all\":{}\n" +
" }\n" +
"}");
org.apache.hadoop.mapreduce.Job job = Job.getInstance(conf);
job.setInputFormatClass(EsInputFormat.class);
job.setReducerClass(EsReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(MapWritable.class);
FileOutputFormat.setOutputPath(job, new Path("D:\\hadoop\\outputES"));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
last
Many parameters are not listed in detail, such as write batch size, write retry times, timeout, etc; Read scroll settings, etc. for details, see resources
reference material
https://www.elastic.co/guide/en/elasticsearch/hadoop/current/mapreduce.html
https://www.elastic.co/guide/en/elasticsearch/hadoop/current/configuration.html#_essential_settings