What is synergetic process
In short, a coroutine is an existence based on threads, but more lightweight than threads. For the system kernel, the co process has invisible characteristics. Therefore, this lightweight thread managed by programmers writing their own programs is called "user space thread".
Advantages of more threads
1. The control right of thread is in the operating system, and the control right of cooperative process is completely in the hands of users. Therefore, using cooperative process can reduce the context switching during program running and effectively improve the running efficiency of the program.
2. When creating a thread, the stack size allocated to the thread by default is 1M, while the coroutine is lighter, only close to 1k. Therefore, more coprocesses can be opened in the same memory.
3. Because the essence of the co process is not multithreading, but single thread. Therefore, there is no need for multi-threaded locking mechanism, because there is only one thread, and there is no conflict caused by writing variables at the same time. Controlling shared resources in the collaboration process does not need to be locked, but only needs to judge the status. Therefore, the execution efficiency of CO process is much higher than that of thread, and it also effectively avoids the competitive relationship in multi thread.
Advantages and disadvantages of collaborative process
Advantages: coprocessing is suitable for those scenarios that need to be blocked and have a large number of concurrency.
Disadvantages: a coroutine is not suitable for scenarios that require a lot of computation (because the essence of a coroutine is a single thread switching back and forth). Therefore, it is impossible to use a single thread for computation.
Understand synchronous, asynchronous, blocking and non blocking
IO operation
IO is divided into two stages (once the data is obtained, it becomes a data operation, not IO):
1. Data preparation stage
2. Copy data from kernel space to user process buffer (user space)
In the operating system, the program running space is divided into kernel space and user space. Applications run in user space, so the data they operate on is also in user space.
The difference between blocking IO and non blocking IO is whether the IO request initiated in the first step is blocked. If it is blocked until it is completed, it is a traditional blocking io. If it is not blocked, it is a non blocking io.
Blocking and non blocking are different methods adopted according to the ready state of IO operation when a process accesses data. In other words, they are the implementation of read or write operation methods. In blocking mode, the read or write function will always wait, while in non blocking mode, the read or write function will immediately return a status value.
Synchronous and asynchronous I/O
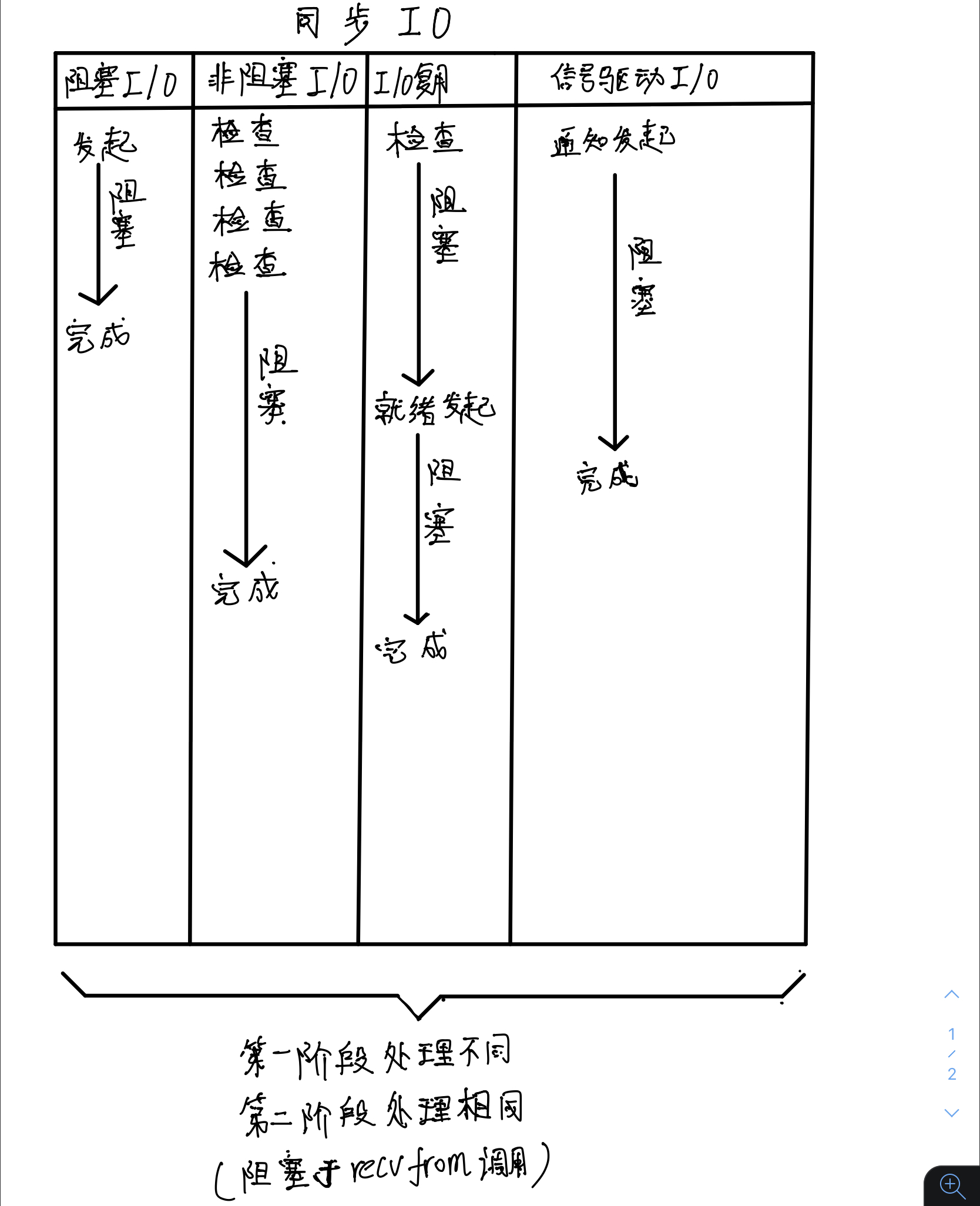
(hand drawn synchronous IO diagram) the content shown in the above figure is synchronous I/O diagram.
The difference between synchronous IO and asynchronous IO is whether the second step is blocked. If it is not blocked, but the operating system helps you complete the IO operation and return the result, it is asynchronous io.
Synchronization and asynchrony refer to the interaction between the application and the kernel. Synchronization refers to the user process triggering the IO operation and waiting or polling to see whether the IO operation is ready; Asynchronous means that the user process starts to do its own things after triggering the IO operation, and will be notified of the completion of the IO operation when the IO operation has been completed.
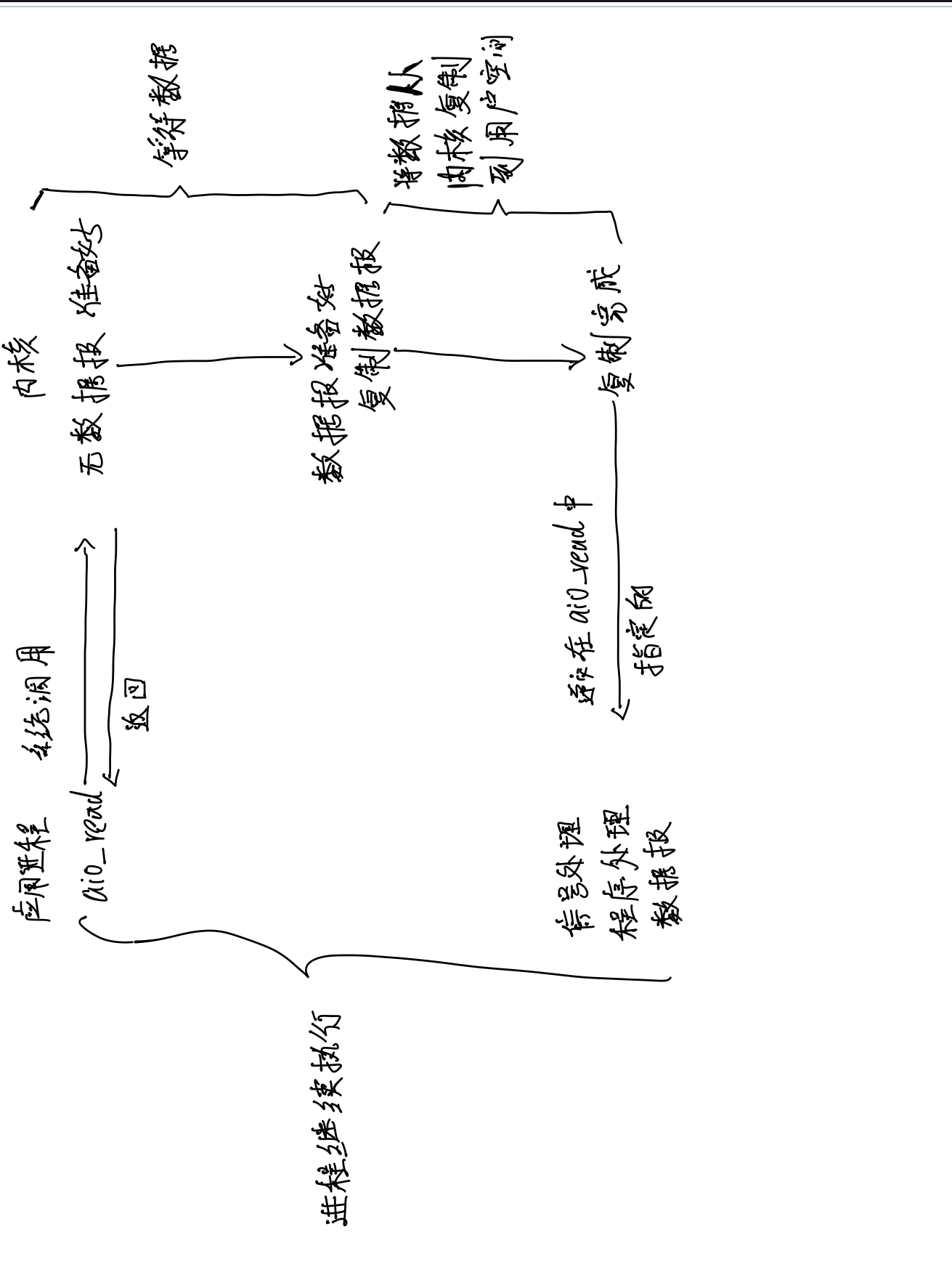
The figure above shows the model diagram of asynchronous IO.
Blocking IO and non blocking IO
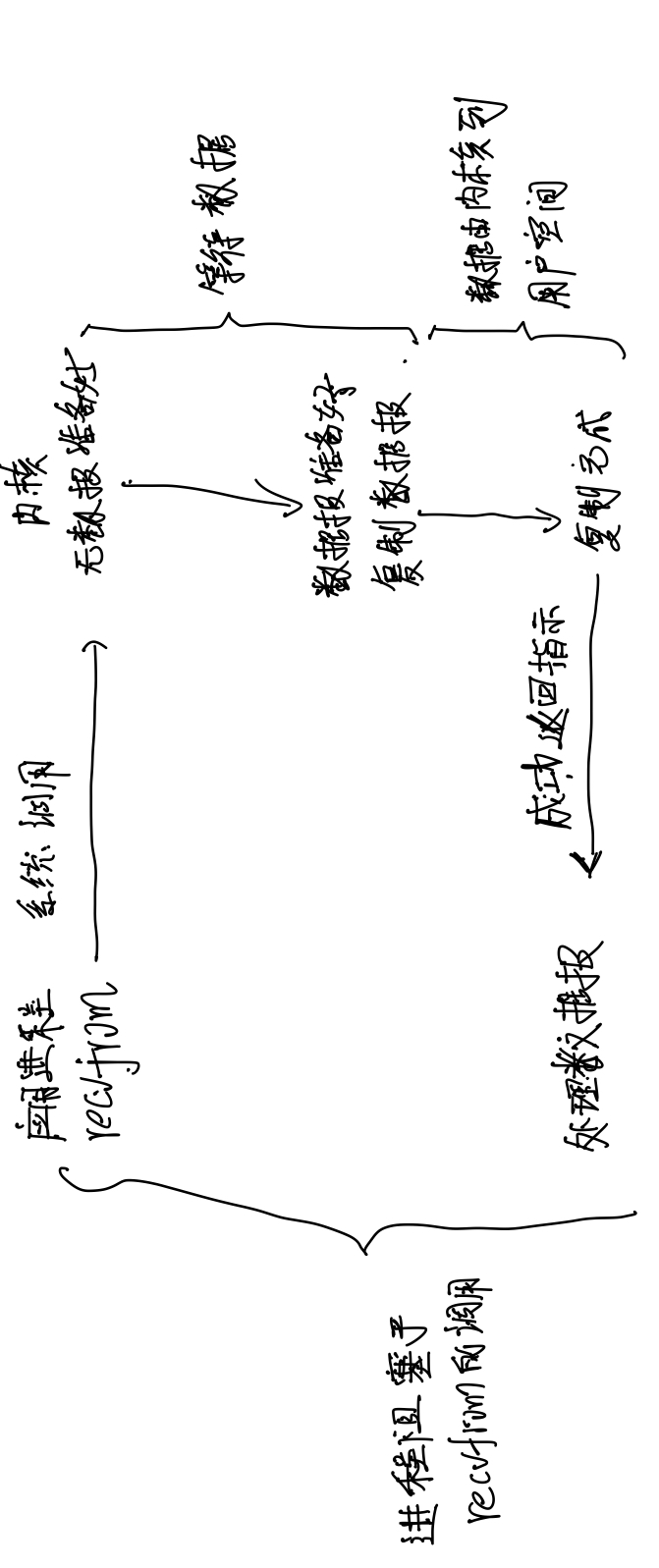
Blocking means that I/O operations need to be completely completed before they can return to user space. The blocking IO model is shown in the following figure:
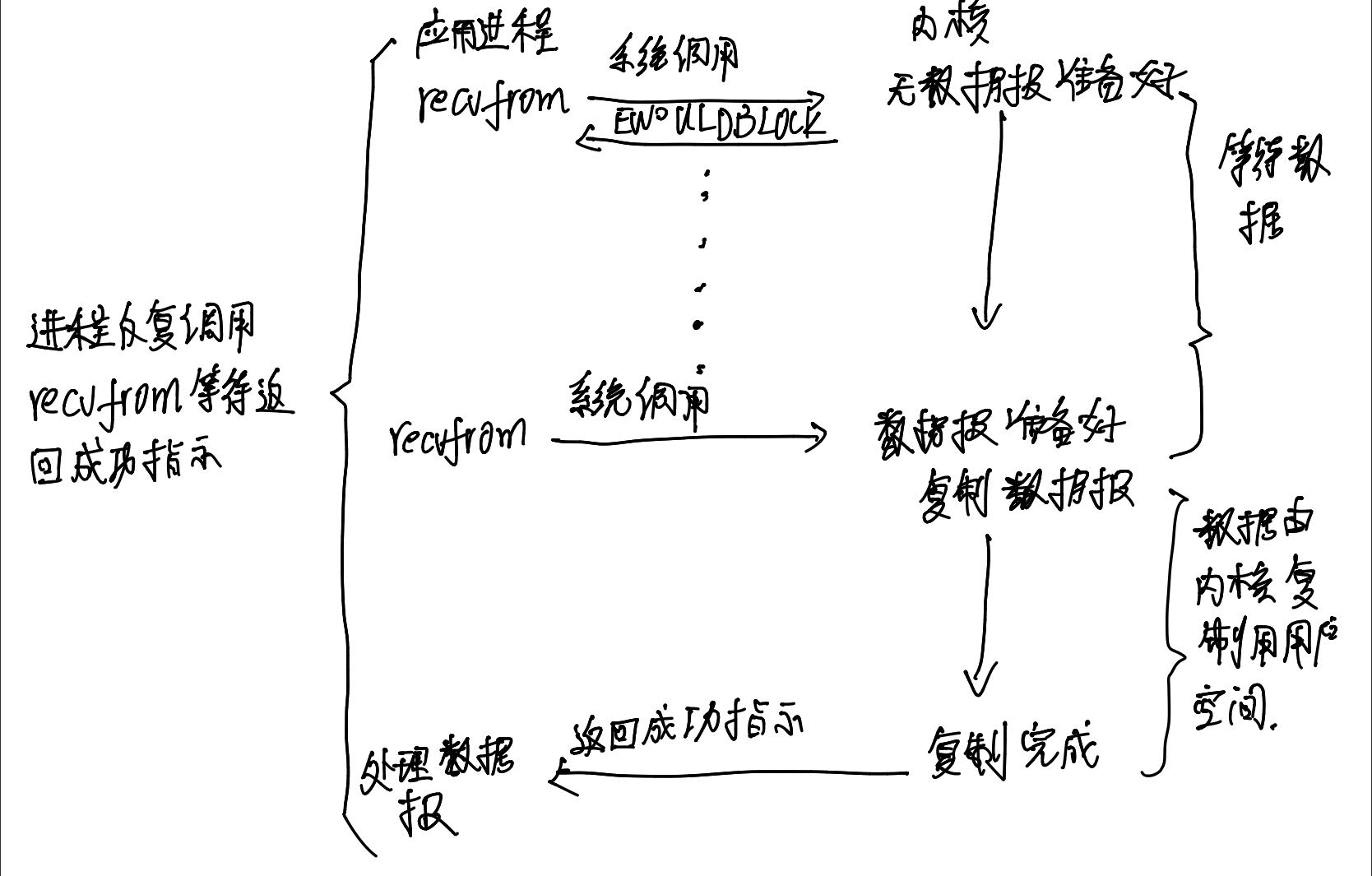
Non blocking IO operation means that a value is returned immediately after being called without waiting for the I/O operation to complete completely. Non blocking I/O model, as shown in the figure below:
Synchronous and asynchronous (call between threads)
Synchronous and asynchronous for the caller and callee, they are the relationship between threads. The two threads are either synchronous or asynchronous.
During synchronization, the caller needs to wait for the result returned by the callee before proceeding to the next step.
During asynchronous operation, the caller does not need to wait for the callee to return the call, and can carry out the next operation. The callee usually relies on event, callback and other mechanisms to notify the caller of the result.
Blocking and non blocking (intra thread calls)
Blocking and non blocking are for the same thread. At a certain time, the thread is either blocked or non blocked.
Blocking and non blocking focus on the state of the program waiting for the call result (message and return value).
Blocking call means that the current thread will be suspended before the returned call result is obtained. The calling thread does not continue until the result is obtained.
A non blocking call means that the call will not block the current thread until the return result of the call is obtained.
httpx based on http framework
The http requests implemented in requests are synchronous requests, but based on the IO blocking characteristics of http requests, it is very suitable for collaborative processes to implement "asynchronous" http requests.
Httpx is a library that inherits all requests features and supports asynchronous http requests. You can think of httpx as an enhanced version of requests.
Installation method
pip install httpx
practice
We can use the synchronous and asynchronous methods of httpx to initiate batch requests for URLs, and then compare the time-consuming.
The specific code of the synchronization http request is as follows:
import httpx
import threading
import time
def sync_main(url, sign):
response = httpx.get(url).status_code
print(f'sync_main: {threading.current_thread()}: {sign} : {response}')
sync_start = time.time()
[sync_main(url='https://www.baidu.com', sign=i) for i in range(200)]
sync_end = time.time()
print(sync_end-sync_start)
The operation results are as follows:
sync_main: <_MainThread(MainThread, started 12368)>: 195 + 200 sync_main: <_MainThread(MainThread, started 12368)>: 196 + 200 sync_main: <_MainThread(MainThread, started 12368)>: 197 + 200 sync_main: <_MainThread(MainThread, started 12368)>: 198 + 200 sync_main: <_MainThread(MainThread, started 12368)>: 199 + 200 12.657010078430176
It takes about 12 seconds.
The specific code of asynchronous http request is as follows:
import asyncio
import httpx
import threading
import time
client = httpx.AsyncClient()
async def async_main(url, sign):
response = httpx.get(url).status_code
print(f'async_main: {threading.current_thread()}: {sign}: {response}')
loop = asyncio.get_event_loop()
task = [async_main('http://www.baidu.com', sign=i) for i in range(200)]
async_start = time.time()
loop.run_until_complete(asyncio.wait(task))
async_end = time.time()
loop.close()
print(async_end-async_start)
The operation results are as follows:
async_main: <_MainThread(MainThread, started 10948)>: 82: 200 async_main: <_MainThread(MainThread, started 10948)>: 144: 200 async_main: <_MainThread(MainThread, started 10948)>: 21: 200 async_main: <_MainThread(MainThread, started 10948)>: 83: 200 async_main: <_MainThread(MainThread, started 10948)>: 145: 200 10.82936143875122
It takes about 10 seconds.
It also sends 200 requests to Baidu. Asynchronous http is about 2 seconds faster than synchronous http, and the efficiency has been improved.
Summary
The order of sending requests using a coroutine must be chaotic, because the program keeps switching between coroutines, but the main thread does not switch. The essence of a coroutine is a single thread.
The main content of this article is to understand the concepts of synchronization, asynchrony, blocking and non blocking. In later articles, I will combine with crawlers.
Every word of the article is typed out by my heart. I just hope it can be worthy of everyone who pays attention to me.
Click and see again. Let me know that my article is really rewarding for you!