Recommended reading:
This code takes c as an example
First, take a look at a classic code and count its execution time:
// test_predict.cc
#include <algorithm>
#include <ctime>
#include <iostream>
int main() {
const unsigned ARRAY_SIZE = 50000;
int data[ARRAY_SIZE];
const unsigned DATA_STRIDE = 256;
for (unsigned c = 0; c < ARRAY_SIZE; ++c) data[c] = std::rand() % DATA_STRIDE;
std::sort(data, data + ARRAY_SIZE);
{ // Test part
clock_t start = clock();
long long sum = 0;
for (unsigned i = 0; i < 100000; ++i) {
for (unsigned c = 0; c < ARRAY_SIZE; ++c) {
if (data[c] >= 128) sum += data[c];
}
}
double elapsedTime = static_cast<double>(clock() - start) / CLOCKS_PER_SEC;
std::cout << elapsedTime << "\n";
std::cout << "sum = " << sum << "\n";
}
return 0;
}
~/test$ g++ test_predict.cc ;./a.out
7.95312
sum = 480124300000
The execution time of this program is 7.9 seconds. If you comment out the sorted line of code, that is
// std::sort(data, data + ARRAY_SIZE);
The result is:
~/test$ g++ test_predict.cc ;./a.out 24.2188 sum = 480124300000
The execution time of the modified program is changed to 24 seconds.
In fact, only one line of code has been changed, but the execution time of the program is three times. It seems that whether the array is sorted or not has nothing to do with the execution speed of the program. In fact, it involves the knowledge points of CPU branch prediction.
When it comes to branch prediction, we first introduce a concept: pipeline.
Take barber for example. Small barber shops usually work by one person. One person washes, cuts and blows on one shoulder, while large barber shops have a clear division of labor. There are specific employees for washing, cutting and blowing. When the first person cuts his hair, the second person can wash his hair. When the first person cuts and blows his hair, the second person can cut his hair and the third person can wash his hair, It greatly improves the efficiency.
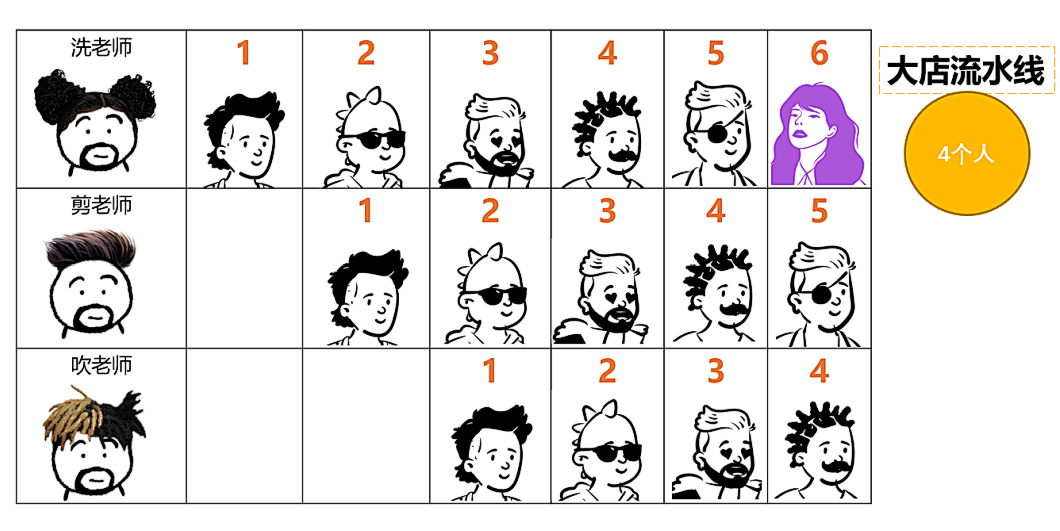
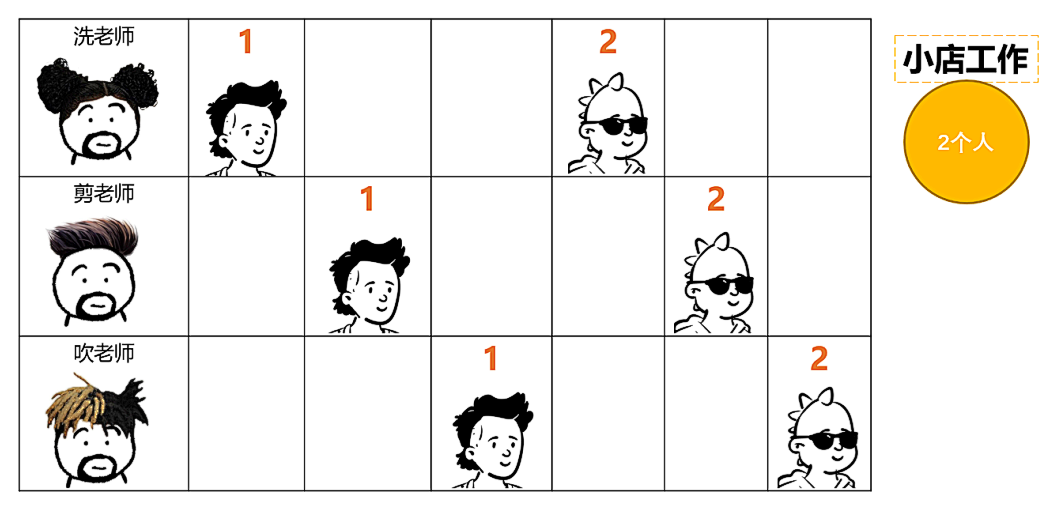
The washing, cutting and blowing here is equivalent to a three-stage pipeline. There is also the concept of pipeline in the CPU architecture, as shown in the figure:
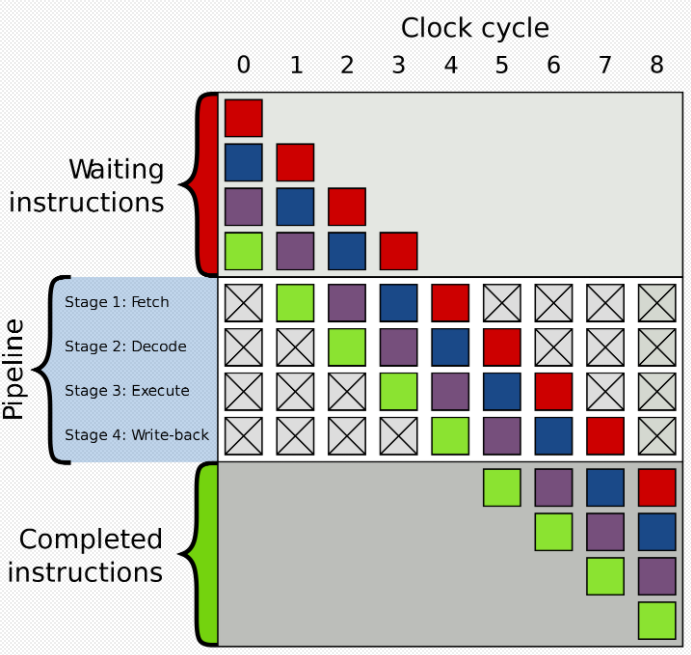
When executing instructions, there are generally the following processes:
-
Finger: Fetch
-
Decode
-
execute: execute
-
Write back: write back
Pipeline architecture can better squeeze the four employees on the pipeline, let them work continuously, and make the instruction execution more efficient.
Let's talk about branch prediction again. Take a classic example:
When the train runs at a high speed, there is a fork in the road ahead. Assuming there is no means of communication in the train, the train needs to stop in front of the fork, get off and ask others which way to go. After finding out the route, restart the train to continue driving. The high-speed train stops slowly, restarts and accelerates. You can imagine how much time this process wastes.
There is a way that the train can guess a route before it meets a fork in the road. When it reaches the intersection, it can directly choose this road. If it passes through multiple forks, it can choose the right intersection every time it makes a choice. In this way, the train does not need to slow down all the way, and the speed is naturally very fast. However, if the train turns over and finds that it has gone the wrong way, it needs to reverse to the fork of the road and choose the right intersection to continue driving, and the speed will naturally decrease a lot. Therefore, the success rate of prediction is very important, because the cost of prediction failure is high, and prediction success is plain sailing.
Computer branch prediction is like a fork in the road when a train is running. If the prediction is successful, the execution efficiency of the program will be greatly improved, and if the prediction fails, the execution efficiency of the program will be greatly reduced.

CPUs operate in a multi-level pipeline architecture. If the branch prediction is successful and many instructions enter the pipeline process in advance, the instructions in the pipeline run very smoothly. If the branch prediction fails, you need to empty the predicted instructions in the pipeline and reload the correct instructions to the pipeline for execution. However, the pipeline level of modern CPUs is very long, Branch prediction failure will lose about 10-20 clock cycles. Therefore, for complex pipelines, good branch prediction methods are very important.
The prediction methods are mainly divided into static branch prediction and dynamic branch prediction:
**Static branch prediction: * * you can tell from the name that this strategy does not depend on the execution environment, and the compiler has predicted each branch when compiling.
**Dynamic branch prediction: * * that is, run-time prediction. The CPU will predict according to the history of branch selection. If this intersection has been taken many times recently, the CPU will give priority to this intersection when making prediction.
**tips:** here is a brief introduction to branch prediction method, more branch prediction method data, we can pay attention to official account number recovery branch prediction keyword collection.
After understanding the concept of branch prediction, we return to the initial question: why is the execution speed of sorting and non sorting in the same program so different.
Because there is an if condition judgment in the program, for programs that are not sorted, the data is scattered, and it is difficult for the CPU to predict the branches. The prediction failure frequency is high. Each failure will waste 10-20 clock cycles, affecting the efficiency of program operation. For the sorted data, the CPU can better judge which branch to take according to the historical records. About the first half of the data will not enter the if branch, and the second half of the data will enter the if branch. The predicted success rate is very high, so the program runs very fast.
How to solve this problem? The general idea must be to minimize the judgment of branches in the program, and the method must be the specific analysis of specific problems. For the example program, here are two ideas to reduce if branches.
**Method 1: * * use bit operation:
int t = (data[c] - 128) >> 31; sum += ~t & data[c];
**Method 2: * * use table structure:
#include <algorithm>
#include <ctime>
#include <iostream>
int main() {
const unsigned ARRAY_SIZE = 50000;
int data[ARRAY_SIZE];
const unsigned DATA_STRIDE = 256;
for (unsigned c = 0; c < ARRAY_SIZE; ++c) data[c] = std::rand() % DATA_STRIDE;
int lookup[DATA_STRIDE];
for (unsigned c = 0; c < DATA_STRIDE; ++c) {
lookup[c] = (c >= 128) ? c : 0;
}
std::sort(data, data + ARRAY_SIZE);
{ // Test part
clock_t start = clock();
long long sum = 0;
for (unsigned i = 0; i < 100000; ++i) {
for (unsigned c = 0; c < ARRAY_SIZE; ++c) {
// if (data[c] >= 128) sum += data[c];
sum += lookup[data[c]];
}
}
double elapsedTime = static_cast<double>(clock() - start) / CLOCKS_PER_SEC;
std::cout << elapsedTime << "\n";
std::cout << "sum = " << sum << "\n";
}
return 0;
}
In fact, there are some tools in Linux that can detect the number of successful branch predictions, including valgrind and perf, as shown in the figure:
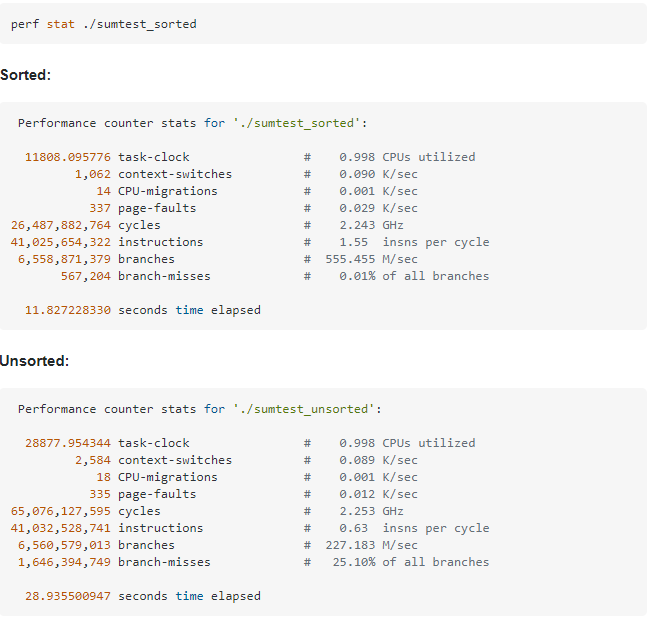
The use of conditional branches will affect the efficiency of program execution. We should try our best to reduce the use of too many branches in the program at will in the process of development, and avoid them if we can avoid them.
Author program meow
Analysis of Java high frequency interview topic collection:

Of course, there are more summarized advanced java learning notes and interview questions not shown here, which are also shared for free to those friends in need, including Dubbo, Redis, Netty, zookeeper, Spring cloud, distributed, high concurrency and other architecture materials and a complete advanced Java architecture learning guide!
These materials have been sorted into PDF documents, which can be used if necessary Free download here Yes!
More advanced materials on Java architecture
/doc/DSmxTbFJ1cmN1R2dB)**
[external chain picture transferring... (img-kYVOqLFp-1623619392896)]
More advanced materials on Java architecture
[external chain picture transferring... (img-w3WPpLNg-1623619392897)]
[external chain picture transferring... (img-iPlt42C2-1623619392898)]