Hello everyone, Lebyte's Xiaole is coming again. Where is less Xiaole shared by Java technology? Last time we said that. Extensible Markup Language XML II: XML Language Format Specification, Document Composition This article will focus on XML parsing.
There are two basic ways of parsing: SAX and DOM.
SAX(Simple API for XML) is based on event stream parsing and DOM(Document Object Model) is based on XML document tree structure parsing.
SAX: High efficiency, small amount of data, only one acquisition.
DOM: The whole tree is loaded into memory, which consumes memory and can be retrieved many times.
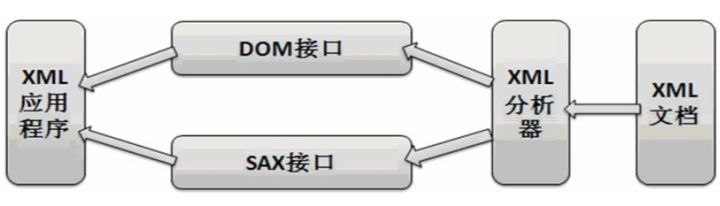
DOM parsing
Similar to js, JAXP (Java API for XML Parsing) is used, that is, Java API for XML parsing.
DOM(Document Object Model, Document Object Model), in applications, based on DOM XML
The parser transforms an XML document into a set of object models (usually called DOM trees). It is through the operation of the object model that the application realizes the operation of the XML document data.
XML itself appears in the form of a tree, so DOM operations will also be transformed in the form of a chapter tree. In the entire DOM tree species, the largest point is the Document, which represents a document in which there is a root node.
Note: When using DOM operations, each text area is also a node, called a text node.
1. Core Operating Interface
There are four core operation interfaces in DOM parsing:
Document: This interface represents the entire XML document, representing the root of the entire DOM tree, providing access to data in the document and operation of the entry, through the Document node can access all elements in the XML file content.
Node: This interface plays a decisive role in the whole DOM tree species. A large part of the core interfaces of DOM operation are inherited from Node interface. For example: Document, Element and other interfaces, in the DOM tree species, each Node interface represents a node of the DOM tree species.
NodeList: This interface represents a collection of nodes and is generally used to represent a set of nodes in a sequential relationship.
For example, a child node of a node directly affects the NodeList collection when the document changes.
NamedNodeMap: This interface represents a one-to-one correspondence between a set of nodes and their unique names.
Interfaces are mainly used for the representation of attribute nodes.
2. DOM Analytical Process
If a program needs DOM parsing read operation, it also needs to follow the following steps:
Establishment of Document Builder Factory: Document Builder Factory=
DocumentBuilderFactory.newInstance();
(2) Establish Document Builder: Document Builder builder = factory. new Document Builder ();
Establish Document: Document doc = builder. parse ("file path to parse");
(4) Establish NodeList: NodeList NL = doc. getElements ByTagName ("Read Node");
Reading XML Information
In addition to parsing, DOM operations can also generate documents.
If you want to generate an XML file, you should use the newDocument() method when creating the document
If you want to output DOM documents, it's troublesome in itself. Write multiple copies at a time
public static void createXml() throws Exception{
//Get parser factory
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
//Get the parser
DocumentBuilder builder=factory.newDocumentBuilder();
//create documents
Document doc=builder.newDocument();
//Create elements, set relationships
Element root=doc.createElement("people");
Element person=doc.createElement("person");
Element name=doc.createElement("name");
Element age=doc.createElement("age");
name.appendChild(doc.createTextNode("shsxt"));
age.appendChild(doc.createTextNode("10"));
doc.appendChild(root);
root.appendChild(person);
person.appendChild(name);
person.appendChild(age);
//Write it out
// Obtain Transformer Factory
TransformerFactory tsf=TransformerFactory.newInstance();
Transformer ts=tsf.newTransformer();
//Setting Code
ts.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
//Create a new input source with DOM nodes to act as the holder of the transformation Source tree
DOMSource source=new DOMSource(doc);
//Act as the holder of the conversion result
File file=new File("src/output.xml");
StreamResult result=new StreamResult(file);
ts.transform(source, result);
}
2. SAX parsing
SAX(Simple API for XML) parsing is done step by step in the order of xml files. SAX does not have an official standard body, it does not belong to any standard prevention or group, nor to any company or individual, but provides a computer technology for anyone to use.
SAX(Simple API for XML, a simple interface for manipulating XML), unlike DOM, SAX uses a sequential mode to access, which is a fast way to read XML data. When using SAX parser to operate, a series of things will be triggered. When the document is scanned to start and end, the relevant processing methods will be invoked at the beginning and end of the element, and the corresponding operations will be made by these methods until the whole document is scanned.
If you want to implement this SAX parsing, you must first build a SAX parser.
// 1. Creating parser factories
SAXParserFactory factory = SAXParserFactory.newInstance();
// 2. Obtaining parsers
SAXParser parser = factory.newSAXParser();
// SAX parser, inheriting DefaultHandler
String path = new File("resource/demo01.xml").getAbsolutePath();
// analysis
parser.parse(path, new MySaxHandler());
3. DOM4j parsing
dom4j is a simple open source library for dealing with XML, XPath and XSLT. It is based on the Java platform and uses Java's collection framework to fully integrate DOM, SAX and JAXP. Download path:
http://www.dom4j.org/dom4j-1.6.1/
http://sourceforge.net/projects/dom4j
DOM4J can be used to read and write XML files.
DOM4J, like JDOM, belongs to a free open source XML component. However, due to the use of this technology in current development frameworks, such as Hibernate, Spring and so on, DOM4J is used as a function. As an introduction, you can have an understanding of this component. There is no good or bad, the general framework uses DOM4J more, and we usually use JDOM more common. It can be found that DOM4J has many new features, such as the output format can be well parsed.
File file = new File("resource/outputdom4j.xml");
SAXReader reader = new SAXReader();
// Read files as documents
Document doc = reader.read(file);
// Get the root element of the document
Element root = doc.getRootElement();
// Find all child nodes based on the following element
Iterator<Element> iter = root.elementIterator();
while(iter.hasNext()){
Element name = iter.next();
System.out.println("value = " + name.getText());
}
//Establish
// Use Document Helper to create Document objects
Document document = DocumentHelper.createDocument();
// Create elements and set relationships
Element person = document.addElement("person");
Element name = person.addElement("name");
Element age = person.addElement("age");
// Setting text
name.setText("shsxt");
age.setText("10");
// Create a formatted output
OutputFormat of = OutputFormat.createPrettyPrint();
of.setEncoding("utf-8");
// output to a file
File file = new File("resource/outputdom4j.xml");
XMLWriter writer = new XMLWriter(new FileOutputStream(new
File(file.getAbsolutePath())),of);
// Write out
writer.write(document);
writer.flush();
writer.close();
JDOM parsing
Download path: http://www.jdom.org/downloads/index.html
JDOM is a unique Java toolkit using XML for rapid development of XML applications. JDOM is an open source project, which is based on tree structure and uses pure Java technology to parse, generate, serialize and operate XML documents.
JDOM parsing
Master the Use and Generation Principle of JDOM Development Tools
JDOM can be used for read or write operations
The XML operating standards, DOM and SAX provided by W3C itself, but from a development perspective, DOM and SAX
It has its own characteristics. DOM can be modified, but it is not suitable for reading large files. SAX can read large files.
But it cannot modify the so-called JDOM = DOM modifiable + SAX read large files.
JDOM itself is a free open source organization, downloaded directly from www.jdom.org, decompressed after downloading, and copied the jdom.jar package to the lib of Tomcat directory (project).
Classes of JDOM main operations:
We find that JDOM's output operations are much more convenient and intuitive than traditional DOM's, including output.
Time is easy.
What is observed at this point is JDOM's support for DOM parsing, but also that JDOM itself supports SAX's
Features; therefore, SAX can be used for parsing operations.
analysis
// Get the SAX parser
SAXBuilder builder = new SAXBuilder();
File file = new File("resource/demo01.xml");
// Getting Documents
Document doc = builder.build(new File(file.getAbsolutePath()));
// Get the root node
Element root = doc.getRootElement();
System.out.println(root.getName());
// Gets all the child nodes under the root node, or the specified direct point according to the label name
List<Element> list = root.getChildren();
System.out.println(list.size());
for(int x = 0; x<list.size(); x++){
Element e = list.get(x);
// Gets the name of the element and the text inside it
String name = e.getName();
System.out.println(name + "=" + e.getText());
System.out.println("==================");
}
Establish
// Create Nodes
Element person = new Element("person");
Element name = new Element("name");
Element age = new Element("age");
// Create properties
Attribute id = new Attribute("id","1");
// Setting text
name.setText("shsxt");
age.setText("10");
// set relationship
Document doc = new Document(person);
person.addContent(name);
name.setAttribute(id);
person.addContent(age);
XMLOutputter out = new XMLOutputter();
File file = new File("resource/outputjdom.xml");
out.output(doc, new FileOutputStream(file.getAbsoluteFile(
)
)
);
Let's start with XML parsing. Keep an eye on Lebytes. Follow-up Java Super Dry Goods will be served. Learn Java happily.