@TOC xpath crawls to university ranking 700 (python3)
Reptile thinking
There are no more than four steps for a crawler, [find data], [parse data], [extract data], [save data]
Find data
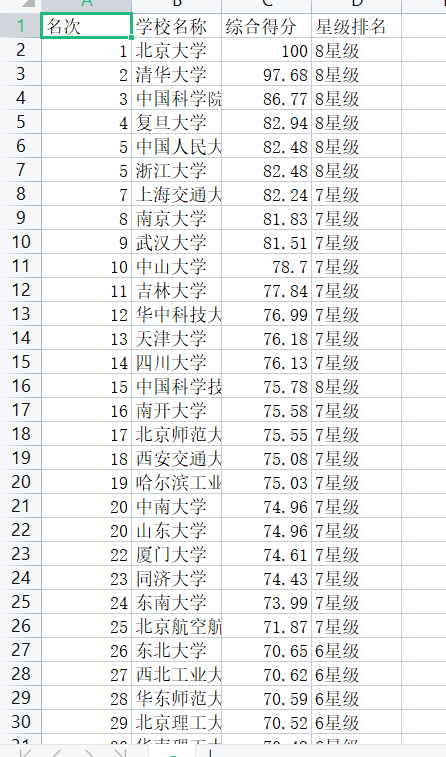
Data found. Find the website you want to crawl, the content you want to crawl, and the website of this article
: http://www.gaosan.com/gaokao/196075.html , crawling content: [ranking] [school name] [comprehensive score] [star ranking].
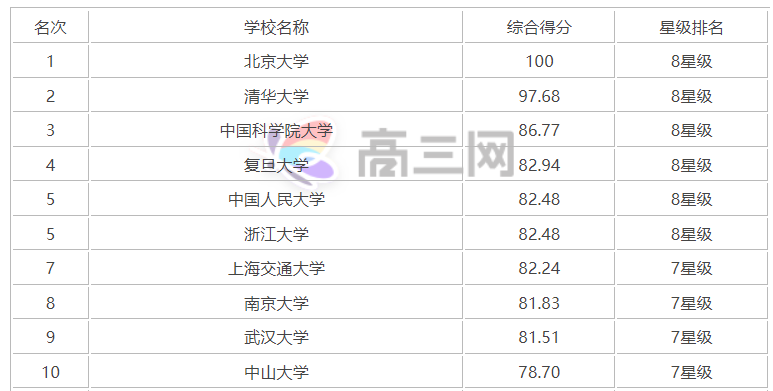
Right click to open [check] and you can see that the content we want to crawl is 196075 HTML, indicating that it is a static web page

Parse data
This article uses xpath to parse data. First, download the xpath plug-in. I use Google browser, open [extension program], search Google store and download the xpath plug-in. I have downloaded it.
Press shift+ctrl+x to start the xpath plug-in, * * Note: * * open the check first and then start the xpath plug-in. This is the case after startup.

Using xpath code
import requests
from lxml import etree
import csv
url = 'http://www.gaosan.com/gaokao/196075.html'
headers = {
'User-Agent': 'Own request header'
}
re = requests.get(url=url,headers = headers)
#Create xpath
re1=re.content.decode('utf-8')
html=etree.HTML(re1)
Extract data
First, let's take a look at the ranking, which is under div id="data196075".
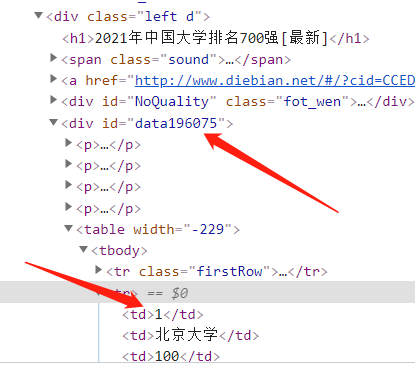
Select td 1 / td and right-click to find copy → select copy xpath

We found the [rank] of 1, but we need to find all the [rank] and change it a little

Explain that the data we are looking for is under table, and there are many table tags under div id="data196075", so removing the brackets after table [] means extracting all tables. Similarly, the tr label is the same. Look at the code.
rank = html.xpath('//div[@id="data196075"]/table/tbody/tr/td[1]/text()')
#Similarly, we need to extract [school name] and so on
name = html.xpath('//div[@id="data196075"]/table/tbody/tr/td[2]/text()')
score =html.xpath('//div[@id="data196075"]/table/tbody/tr/td[3]/text()')
star = html.xpath('//div[@id="data196075"]/table/tbody/tr/td[4]/text()')
Here's a problem: I want to remove tr class="firstRow", because I want to store it in csv format later. You can see that this web page is in batches. Each batch has class="firstRow", that is, when I store it in csv, there will be several more lines, such as ranking, school name, comprehensive score and star ranking. So I wrote xpath like this

Strangely, what is returned in the program is an empty list
rank=html.xpath('//div[@id="data196075"]/table/tbody/tr[@class!="firstRow"]/td[1]')
#Output []
There are big guys passing by to ask for answers.
rank = html.xpath('//div[@id="data196075"]/table/tbody/tr/td[1]/text()')
In my method, the list contains information such as' ranking '. How can I solve it? Right! Delete the element in the list! That's it! Direct code
length=len(rank)
x=0
while x < length:
if rank[x] == 'Ranking':
del rank[x]
x -= 1
length -= 1
x+=1
length=len(name)
x=0
while x < length:
if name[x] == 'School name':
del name[x]
x -= 1
length -= 1
x+=1
length=len(score)
x=0
while x < length:
if score[x] == 'Comprehensive score':
del score[x]
x -= 1
length -= 1
x+=1
length=len(star)
x=0
while x < length:
if star[x] == 'Star ranking':
del star[x]
x -= 1
length -= 1
x+=1
Here, using the for loop will lead to index confusion. You can search the Internet for details.
Based on the above, we get four lists, [ranking], [school name], [comprehensive score] and [school ranking]. But what I want is
In this form, what should we do? I think of the * * zip() * * function
zip_list = zip(rank,name,score,star)
Store data
Stored in csv format, I won't say much here, but directly code.
with open('a.csv','w',newline='',encoding='utf-8') as f:
write = csv.writer(f)
write.writerow(['Ranking','School name','Comprehensive score','Star ranking'])
for i in zip_list:
write.writerow(list(i))
f.close()
Complete code
import requests
from lxml import etree
import csv
url = 'http://www.gaosan.com/gaokao/196075.html'
headers = {
'User-Agent': 'Own request header'
}
re = requests.get(url=url,headers = headers)
re1=re.content.decode('utf-8')
html=etree.HTML(re1)
rank = html.xpath('//div[@id="data196075"]/table/tbody/tr[@class!="firstRow"]/td[1]')
name = html.xpath('//div[@id="data196075"]/table/tbody/tr/td[2]/text()')
score = html.xpath('//div[@id="data196075"]/table/tbody/tr/td[3]/text()')
star = html.xpath('//div[@id="data196075"]/table/tbody/tr/td[4]/text()')
print(rank)
length=len(rank)
x=0
while x < length:
if rank[x] == 'Ranking':
del rank[x]
x -= 1
length -= 1
x+=1
length=len(name)
x=0
while x < length:
if name[x] == 'School name':
del name[x]
x -= 1
length -= 1
x+=1
length=len(score)
x=0
while x < length:
if score[x] == 'Comprehensive score':
del score[x]
x -= 1
length -= 1
x+=1
length=len(star)
x=0
while x < length:
if star[x] == 'Star ranking':
del star[x]
x -= 1
length -= 1
x+=1
zip_list = zip(rank,name,score,star)
with open('a.csv','w',newline='',encoding='utf-8') as f:
write = csv.writer(f)
write.writerow(['Ranking','School name','Comprehensive score','Star ranking'])
for i in zip_list:
write.writerow(list(i))
f.close()
Result display