order
It took me so long to help the teacher with a new topic, but fortunately, the bug that could not be detected before yolov3 has been repaired. After 3-4 days of discontinuous debug ging and thinking, I feel that I have a deeper understanding of yolov3's detection framework, including the format of pytorch data, the transmission of data in darknet network, the implementation of detection frame, etc, After more than 15 days to reproduce yolov3, I feel I have gained something. I can write a simple article to record it later when I am free.
bug fix
Last time, it was traced to the darknet module, that is, the forward propagation result prediction obtained was wrong
with torch.no_grad(): prediction = model(batch, CUDA) # Results obtained by forward propagation
After further follow-up, in the forward propagation method of darknet, the results can be obtained by performing conv convolution block for the first time, but the second time, all results will become nan, including the value of weight weight weight;
The problem must arise at this time_ In the weight method, because the second convolution is followed by the first result, there is no interference of other method variables, except the weights loaded at the beginning
After repeatedly comparing the results, I finally found that I wrote the code for loading conv weights into the paranoia of loading conv, which eventually led to wrong results. I still have to be careful.
if module_type == "convolutional": model = self.module_list[i] try: batch_normalize = int(self.blocks[i + 1]["batch_normalize"]) except: batch_normalize = 0 conv = model[0] if batch_normalize: # existence bn Situation bn = model[1] # bn Number of layer weights num_bn_biases = bn.bias.numel() # load bn weight bn_biases = torch.from_numpy(weights[ptr:ptr+num_bn_biases]) ptr+=num_bn_biases bn_weights = torch.from_numpy(weights[ptr: ptr + num_bn_biases]) ptr += num_bn_biases bn_running_mean = torch.from_numpy(weights[ptr: ptr + num_bn_biases]) ptr += num_bn_biases bn_running_var = torch.from_numpy(weights[ptr: ptr + num_bn_biases]) ptr += num_bn_biases # Set weights to the same dims bn_biases = bn_biases.view_as(bn.bias.data) bn_weights = bn_weights.view_as(bn.weight.data) bn_running_mean = bn_running_mean.view_as(bn.running_mean) bn_running_var = bn_running_var.view_as(bn.running_var) # copy Data to model bn.bias.data.copy_(bn_biases) bn.weight.data.copy_(bn_weights) bn.running_mean.copy_(bn_running_mean) bn.running_var.copy_(bn_running_var) else: # Convolution layer paranoia num_biases = conv.bias.numel() conv_biases = torch.from_numpy(weights[ptr:ptr+num_biases]) ptr+=num_biases conv_biases = conv_biases.view_as(conv.bias.data) # Corresponding dimension conv.bias.data.copy_(conv_biases) # Load convolution layer weights num_weights = conv.weight.numel() conv_weights = torch.from_numpy(weights[ptr:ptr + num_weights]) ptr = ptr + num_weights conv_weights = conv_weights.view_as(conv.weight.data) conv.weight.data.copy_(conv_weights)
After eliminating this bug, the remaining big bug is located in write_ In the result method, there was an error in converting the prediction result into the 80 categories of coco.
The problem caused by the bug here is that only one type can be detected at a time, and the range drawn by the detection box is incorrect and biased.
To solve this problem, considering that the prediction result is correct:
1) Then it may be that in the process of multiple detection results cat into a large tensor, the latter tensor covers the former and does not form a correct cat;
2) Or the detection process is ended in advance, resulting in data loss
This can also explain the position deviation of the detection frame. Finally, through step-by-step debug ging, it is found that there is a problem in the code for selecting the best bounding box in NMS. It is simple and hidden. In short, it makes the error in (1), but it also produces the consequences in (2)
detection result
After completing the code, how is it appropriate not to run a few pictures? So I got some pictures from the Internet and tested them




This is probably the performance
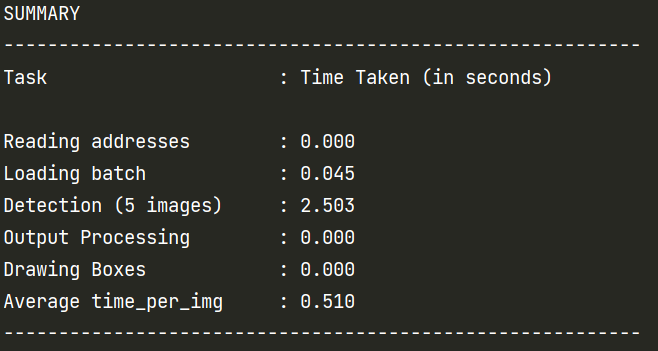
Very interesting. It is said that yolov3 is on the 810 platform? It can reach the speed of 30 frames / s, and it should be faster to use c + +, so it can also be applied to video detection. That is, in addition to the time-consuming detection of the first picture, the subsequent pictures are very fast, which is worthy of being a competitive framework in the industry,
I suspect that the temperature detection at the supermarket entrance next to the school is done by this framework.
Of course, there are also aspects about video detection in the tutorial. I haven't reproduced it yet. I'll make it up later, and the training part hasn't been written yet.
As an in-depth learning project realized for the first time, I think yolov3 is a very good introductory course. I hope I can read the paper independently and reproduce yolov4 in winter vacation. Good.