1, Training environment
darknet compiled under Windows 10
Compilation process: https://blog.csdn.net/weixin_54603153/article/details/119980266?spm=1001.2014.3001.5501)
Source address: https://github.com/AlexeyAB/darknet
2, Make your own dataset
1. First, create a folder for the dataset under the Darknet master folder

Annotations tag xml file,
JPEGImages puts photos,
Just don't create anything in Main. The script will be automatically generated in a moment
labels don't need to be created. The script will be generated automatically later
2. Run the script make1 to divide the pictures into training set, test volume and verification set
import os
import random
trainval_percent = 1 #You can modify it yourself
train_percent = 0.9 #You can modify it yourself
xmlfilepath = 'VOCdevkit/VOC2007/Annotations'
txtsavepath = 'VOCdevkit/VOC2007/ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('VOCdevkit/VOC2007/ImageSets/Main/trainval.txt', 'w')
ftest = open('VOCdevkit/VOC2007/ImageSets/Main/test.txt', 'w')
ftrain = open('VOCdevkit/VOC2007/ImageSets/Main/train.txt', 'w')
fval = open('VOCdevkit/VOC2007/ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
Then we get
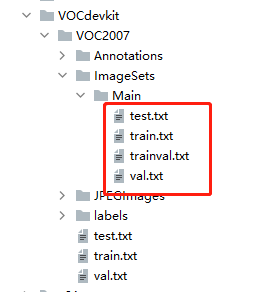
3. Convert xml to txt format and run make2
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["yes_mask", "no_mask"] #Change to the label of your own dataset
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOC%s/labels/'%(year)): #Attention path
os.makedirs('VOC%s/labels/'%(year))
image_ids = open('VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()Generate the following files, generate labels and three txt files, which is to convert our label file xml into TXT format
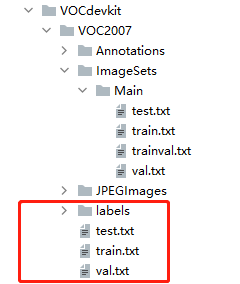
We have made all the data sets above
3, Prepare files and pre training weights for training
1. Download the pre training weight from the source website
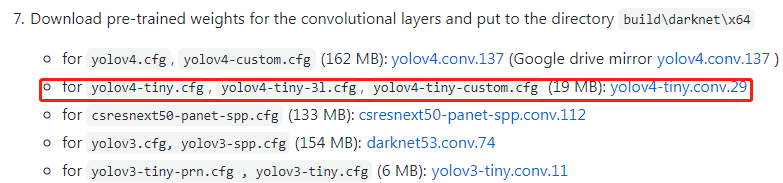
Just download it and put it directly in the Darknet master folder
2. Create and modify cfg files
CFG is a model structure file, which is located in Darknet master / CFG and needs to be modified according to its own data, operating environment and training mode. Take yolov4 tiny CFG as an example, select Copy and change it to yolov4 tiny new cfg
Modify yolov4 tiny new Several places of CFG
These parameters are modified according to their own needs
[net] batch=96 # The number of pictures entered during each iteration training subdivisions=48 # Divide the batch quantity of each time into the number of copies corresponding to the number of subdivision s. After running one by one, they are packaged together and counted as completing an iteration width=512 # Multiple of size 32 momentum=0.9 # Momentum, which affects the gradient to the optimal velocity, generally defaults to 0.9 decay=0.0005 # The weight attenuates the regularization coefficient to prevent over fitting angle=0 # Rotate the angle to generate more training samples saturation=1.5 # Adjust saturation exposure=1.5 # Adjust exposure hue=.1 # Adjust hue learning_rate=0.001 burn_in=1000 # The parameters of learning rate control are greater than burn in the number of iterations_ In, the policy update method is adopted: 0.001 * pow(iterations/1000, 4) max_batches=500200 # Maximum number of iterations policy=steps steps=400000,450000 # The learning rate change Steps, Steps and scales correspond to each other. These two parameters set the change of learning rate according to batch_num adjust learning rate scales=.1,.1 # Learning rate change factor, when the iteration reaches 400000 times, the learning rate x0 1; At 450000 iterations, the learning rate will be x0.5% higher than the previous learning rate one
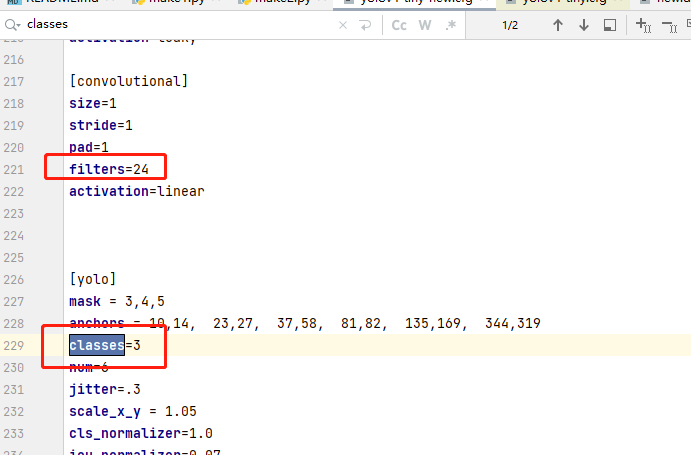
Then download to modify the classes of all yolo layers and the filters of the previous convolution layer of yolo layer (the calculation method is filters=(classes + 5)x3)
I'm used to directly ctrl+f search for classes. I can find two, and then modify the classes to the number of our categories, and then find the nearest filters on this class to (classes+5) * 3. There are two groups in total
3. Create ok folders and names files
I put the files needed for our training together for the convenience of management. The folders are as follows:
ok, create it in the Darknet master file
train.txt and val.txt are copied from vocdevkit / voc207. These two files are generated when we create the dataset and run make2. Here, I put them under ok for the convenience of management.
new. The content of data is as follows: (this new.data is equivalent to a headquarters, which places the path of files we need during training)

classes is the category. train writes the address of the training set we put into the ok folder, valid writes the address of the verification set we put into the ok folder, names is the text address of the names we created, and backup is the address of the folder where the training results are placed
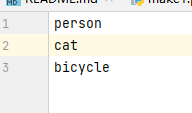
new.names is to fill in the training category:
4, Training
1. Open cmd in the Darknet master file directory and enter

Where OK / new Data is the location of the headquarters where we write many paths,
cfg/yolov4-tiny-new.cfg is the location of the cfg file we modified earlier,
yolov4-tiny.conv.29 is the location of the pre training weight we downloaded. It is directly placed in the source folder of Darknet master, so there is no need to write the name in the sub file in front
2. If the middle training breaks, we will continue training
Open cmd in the Darknet master file directory and enter
darknet.exe detector train ok/new.data cfg/yolov4-tiny-new.cfg ok/runs/yolov4-tiny-new_last.weights
The previous training is the same as the initial training, but the pre training weight is replaced by the weight obtained from the last training in ok/runs
The above is the training process