We programmers usually open many Terminal windows in parallel in the development process, especially in the process of program debugging. However, over time, you may forget what each Terminal is used for. Therefore, how to keep the interface fresh without reducing work efficiency has become the biggest pain point for many developers.
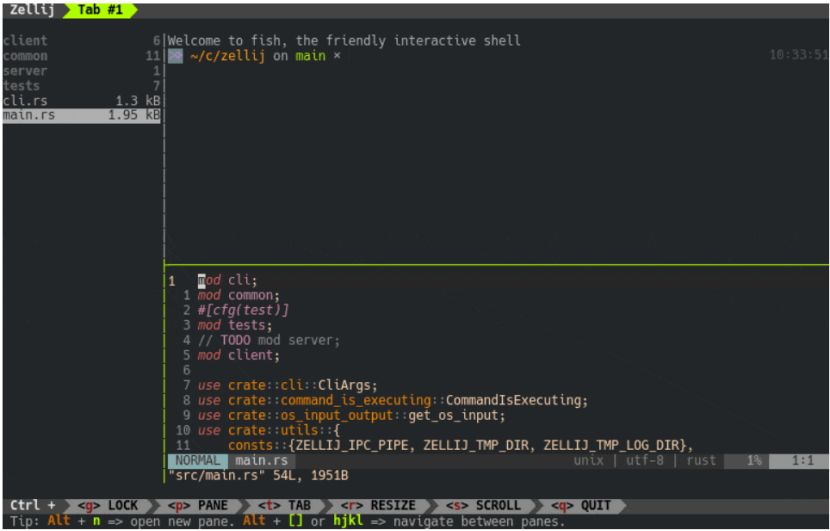
Zellij It is an excellent terminal workspace and multiplexer (similar to tmux and screen). It is developed with Rust language, so it is similar to Zellij Compatible with WebAssembly native. As a powerful and easy-to-use terminal reuse tool, it decouples session and window, so that users can run multiple virtual terminals in a single window, really keep the interface fresh and improve work efficiency.
The author notes that in the past few months, Zellij Our development team has been Zellij For optimization and pit drainage, they published some meaningful technical blogs to record the whole optimization process. The blog shows some issues worthy of summary and attention. We can see through their sharing, Zellij Developers have come up with many creative solutions. Through two main technical improvement points, they have greatly tuned Zellij Performance in a large number of display refresh scenarios. Now I will interpret the related technology blog for you.
Zellij seems simple, but in fact, the amount of code is huge. If you dig into all the technical} details, you may completely confuse the readers. Therefore, the code examples used in this article are simplified versions and are only used to discuss problems.
One problem is the impact of huge traffic
Zellij is a terminal multiplexer. As we just showed in the screenshot, it allows users to create multiple "tabs" and "windows". Zellij will maintain the state for each terminal window. The state information includes text, style, light mark position in the window and other elements. This design can facilitate users to ensure the consistency of user experience every time they connect to an existing session, and support users to switch freely between internal tabs. However, when the state displays a large amount of data in the zellij window in previous versions, the performance problem will be very obvious. For example, when cat inputs a very large file, zellij will be much slower than the bare terminal emulator, and even slower than the multiplexer with other terminals. Next, the author will take you to study this problem in depth.
Zellij uses multithreading architecture, PTY threads and Screen rendering threads to perform specific tasks and pass through MPSC channel Communicate with each other. PTY thread query PTY That is, input and output on the user's Screen, and send the original data to the Screen thread. The thread parses the data and establishes the internal state of the terminal window. The PTY thread will present the state of the terminal to the user Screen and send a rendering request to the Screen thread.
One is the round robin mechanism: the PTY thread continuously polls PTY to see if it has new data in the while loop of asynchronous data reception. If no data is received, sleep for a fixed period of time.
The other is the POLL mechanism: let the data flow drive the update. This design is generally considered to be more efficient. If PTY has a large influx of data streams, users will see the updates of these data on the screen in real time.
Let's look at the code:
task::spawn({
async move {
// Terminalbytes is the asynchronous data stream let mut terminal_bytes = TerminalBytes::new(pid);
let mut last_render = Instant::now();
let mut pending_render = false;
let max_render_pause = Duration::from_millis(30);
while let Some(bytes) = terminal_bytes.next().await {
let receiving_data = !bytes.is_emPTY();
if receiving_data {
send_data_to_screen(bytes);
pending_render = true;
}
if pending_render && last_render.elapsed() > max_render_pause {
send_render_to_screen();
last_render = Instant::now();
pending_render = false;
}
if !receiving_data {
task::sleep(max_render_pause).await;
}
}
}
})Solution to traffic impact
In order to test the performance of this large-scale display process, developers cat a 2000000 line bigfile file and use it hyperfine Benchmark tool, and use the -- show output parameter to test the standard output scenario tmux Compare.
hyperfine --show-output "cat /tmp/bigfile"stay tmux Results of internal operation: (window size: 59 rows, 104 columns) Time (mean ± σ): 5.593 s ± 0.055 s [User: 1.3 ms, System: 2260.6 ms] Range (min ... max): 5.526 s ... 5.678 s 10 runs hyperfine --show-output "cat /tmp/bigfile"stay Zellij Results of internal operation: (window size: 59 rows, 104 columns) Time (mean ± σ): 19.175 s ± 0.347 s [User: 4.5 ms, System: 2754.7 ms] Range (min ... max): 18.647 s ... 19.803 s 10 runs
You can see that the performance of tmux before optimization is almost eight times that of Zellij.
Problem point location 1: MPSC channel overflow
The first performance problem is the overflow of MPSC channel. Because there is no synchronization control between PTY thread and screen thread, PTY process sends data much faster than screen thread processes data. The imbalance between PTY and screen will affect performance in the following aspects:
The channel buffer space is growing, occupying more and more memory
The number of screen threads rendering is much higher than reasonable because screen threads need more and more time to process messages in the queue.
Solution: convert MPSC to bounded channel
The solution to this pressing problem is to limit the buffer size of the channel, thereby creating a synchronization relationship between the two threads. Therefore, developers abandoned MPSC and chose bounded synchronization channel crossbeam,crossbeam Provides a very useful macro select!. In addition, developers also removed the custom asynchronous flow implementation of background polling and used async instead_ std File For asynchronous i/o.
Let's look at the changes in the code:
task::spawn({
async move {
let render_pause = Duration::from_millis(30);
let mut render_deadline = None;
let mut buf = [0u8; 65536];
let mut async_reader = AsyncFileReader::new(pid); // Using async_std implements asynchronous IO
//The following is the special processing of asynchronous implementation in deadline
loop {
match deadline_read(&mut async_reader, render_deadline, &mut buf).await {
ReadResult::Ok(0) | ReadResult::Err(_) => break, // EOF or error ReadResult::Timeout => {
async_send_render_to_screen(bytes).await;
render_deadline = None;
}
ReadResult::Ok(n_bytes) => {
let bytes = &buf[..n_bytes];
async_send_data_to_screen(bytes).await;
render_deadline.get_or_insert(Instant::now() + render_pause);
}
}
}
}
})The improved performance test is as follows:.
hyperfine --show-output "cat /tmp/bigfile"(Pane size: 59 rows, 104 columns): # Zellij before this fix Time (mean ± σ): 19.175 s ± 0.347 s [User: 4.5 ms, System: 2754.7 ms] Range (min ... max): 18.647 s ... 19.803 s 10 runs # Zellij after this fix Time (mean ± σ): 9.658 s ± 0.095 s [User: 2.2 ms, System: 2426.2 ms] Range (min ... max): 9.433 s ... 9.761 s 10 runs # Tmux Time (mean ± σ): 5.593 s ± 0.055 s [User: 1.3 ms, System: 2260.6 ms] Range (min ... max): 5.526 s ... 5.678 s 10 runs
Although the performance has been nearly doubled, from the data of Tmux, Zellij can still do better.
Second, the performance of rendering and data parsing
Next, developers bind the pipeline to the screen thread. If the performance of two related jobs in the screen thread is improved, the whole process can run faster: parsing data and rendering it to the user terminal. The data parsing part of screen thread is used to convert ANSI/VT and other control instructions (such as carriage return or line feed) into data structures that Zellij can control.
The following are relevant parts of these data structures:
struct Grid {
viewport: Vec<Row>,
cursor: Cursor,
width: usize,
height: usize,
}struct Row {
columns: Vec<TerminalCharacter>,
}struct Cursor {
x: usize,
y: usize
}#[derive(Clone, Copy)]struct TerminalCharacter {
character: char,
styles: CharacterStyles
}Solution to problem 2 - memory pre allocation
The most frequent operation performed by the parser is to add displayed characters to a line of text. Especially add characters at the end of the line. This action mainly involves pushing those terminal characters into the column vector. Each push involves allocating a section of memory space from the heap. This memory allocation operation is very time-consuming. This is described in the previous blog "a line of useless enumeration code improves Rust performance by 10%". Therefore, the performance can be improved by pre allocating memory every time a Row is created or the terminal window is resized. So developers start by changing the constructor of the Row class:
impl Row {
pub fn new() -> Self {
Row {
columns: Vec::new(),
}
}}
}
In this regard:
impl Row {
pub fn new(width: usize) -> Self {
Row {
columns: Vec::with_capacity(width),//Pre allocate a section of memory by specifying capacity
}
}}
}Cache character width
We know that some special characters, such as Chinese full angle characters, will occupy more space than ordinary English characters. In this regard, Zellij introduced unicode-width crate to calculate the width of each character.
When Zellij adds a character to a line, the terminal emulator needs to know the current width of the line in order to decide whether the character should be wrapped to the next line. Therefore, it needs to constantly view and accumulate the width of the previous character in the line. Because you need to find a way to calculate the character width.
The code is as follows:
#[derive(Clone, Copy)]struct TerminalCharacter {
character: char,
styles: CharacterStyles
}impl Row {
pub fn width(&self) -> usize {
let mut width = 0;
for terminal_character in self.columns.iter() {
width += terminal_character.character.width();
}
width
}
}Faster after adding cache:
#[derive(Clone, Copy)]struct TerminalCharacter {
character: char,
styles: CharacterStyles,
width: usize,
}impl Row {
pub fn width(&self) -> usize {
let mut width = 0;
for terminal_character in self.columns.iter() {
width += terminal_character.width;
}
width
}
}Rendering speed increased
The rendering part of the Screen thread essentially performs the opposite operation to the data parsing part. It obtains each window state represented by the above data structure and converts it into ANSI/VT control instructions to send to the terminal emulator of the operating system itself and interpret and execute it. That is, ordinary characters are displayed and rendered. If it is a control character, it is sent to the system shell for execution.
fn render(&mut self) -> String {
let mut vte_output = String::new();
let mut character_styles = CharacterStyles::new();
let x = self.get_x();
let y = self.get_y();
for (line_index, line) in grid.viewport.iter().enumerate() {
vte_output.push_str(
// goto row/col and reset styles &format!("\u{1b}[{};{}H\u{1b}[m", y + line_index + 1, x + 1)
);
for (col, t_character) in line.iter().enumerate() {
let styles_diff = character_styles
.update_and_return_diff(&t_character.styles);
if let Some(new_styles) = styles_diff {
vte_output.push_str(&new_styles); // If it is not a type of character, it will be replaced here
}
vte_output.push(t_character.character);
}
character_styles.clear();
}
vte_output
}We know that STDOUT writing is a very performance-consuming operation. Therefore, developers send the artifact of buffer again. The buffer mainly tracks the differences between the latest and the next new rendering requests. Finally, only these different differences in the buffer are rendered.
The code is as follows:
#[derive(Debug)]pub struct CharacterChunk {
pub terminal_characters: Vec<TerminalCharacter>,
pub x: usize,
pub y: usize,
}#[derive(Clone, Debug)]pub struct OutputBuffer {
changed_lines: Vec<usize>, // line index should_update_all_lines: bool,
}impl OutputBuffer {
pub fn update_line(&mut self, line_index: usize) {
self.changed_lines.push(line_index);
}
pub fn clear(&mut self) {
self.changed_lines.clear();
}
pub fn changed_chunks_in_viewport(
&self,
viewport: &[Row],
) -> Vec<CharacterChunk> {
let mut line_changes = self.changed_lines.to_vec();
line_changes.sort_unstable();
line_changes.dedup();
let mut changed_chunks = Vec::with_capacity(line_changes.len());
for line_index in line_changes {
let mut terminal_characters: Vec<TerminalCharacter> = viewport
.get(line_index).unwrap().columns
.iter()
.copied()
.collect();
changed_chunks.push(CharacterChunk {
x: 0,
y: line_index,
terminal_characters,
});
}
changed_chunks
}
}}We can see that the minimum modification unit of this implementation is the line, and there is a further optimization scheme to modify only some changed characters in the line. Although this scheme greatly increases the complexity, it also brings a very significant performance improvement.
The following are the improved comparison test results:
hyperfine --show-output "cat /tmp/bigfile"Run results after repair: (pane size: 59 rows, 104 columns) # Zellij before all fixes Time (mean ± σ): 19.175 s ± 0.347 s [User: 4.5 ms, System: 2754.7 ms] Range (min ... max): 18.647 s ... 19.803 s 10 runs # Zellij after the first fix Time (mean ± σ): 9.658 s ± 0.095 s [User: 2.2 ms, System: 2426.2 ms] Range (min ... max): 9.433 s ... 9.761 s 10 runs # Zellij after the second fix (includes both fixes) Time (mean ± σ): 5.270 s ± 0.027 s [User: 2.6 ms, System: 2388.7 ms] Range (min ... max): 5.220 s ... 5.299 s 10 runs # Tmux Time (mean ± σ): 5.593 s ± 0.055 s [User: 1.3 ms, System: 2260.6 ms] Range (min ... max): 5.526 s ... 5.678 s 10 runs
After this series of improvements, Zellij's performance in cat a large file can be comparable to that of Tmux.
conclusion
To sum up, Zellij has greatly improved the performance of Zellij multiplexer by optimizing the unbalanced relationship between data processing on both sides of the channel, adding buffer and optimizing rendering granularity. Many optimization ideas are very worthy of reference for developers.