About Zeppelin

Zeppelin is a Web-based notebook that supports data-driven, interactive data analysis and collaboration using SQL, Scala, Python, R, and so on.
Zeppelin supports multiple language backends, and the Apache Zeppelin interpreter allows any language/data processing backend to be inserted into Zeppelin. Currently, Apache Zeppelin supports many interpreters, including Apache Spark, Apache Flink, Python, R, JDBC, Markdown, and Shell.
Simply put, it lets you use the Web UI to implement many functions that would otherwise require logging on to the server and using the terminal.
(For Flink and Hudi introductions, refer to other articles on this blog, or search by yourself)
The topic for today follows.
This article covers components and their versions
| Component Name | version number |
|---|---|
| hadoop | 3.2.0 |
| hudi | 0.10.0-SNAPSHOT |
| zeppelin | 0.10.0 |
| flink | 1.13.1 |
Import data into hudi before doing the following. If you have not already done so, you can refer to:
Restore hudi jobs from savepoint using FLINK SQL (flink 1.13)
Related blog posts import data into hudi
zeppelin installation package download
mkdir /data && cd /data wget https://dlcdn.apache.org/zeppelin/zeppelin-0.10.0/zeppelin-0.10.0-bin-all.tgz tar zxvf zeppelin-0.10.0-bin-all.tgz ln -s /data/zeppelin-0.10.0-bin-all /data/zeppelin
zeppelin Profile Modification
cd /data/zeppelin/conf cp zeppelin-site.xml.template zeppelin-site.xml
Modify the zeppelin.server.addr configuration item to 0.0.0.0
The default port for Zeppelin is 8080. If it conflicts with your local port, you can change it to a different port. This document changes the port to 8008, which is to change the zeppelin.server.port configuration item to 8008.
cp zeppelin-env.sh.template zeppelin-env.sh
Fill in the following variables:
export JAVA_HOME=/data/jdk export HADOOP_CONF_DIR=/data/hadoop/etc/hadoop export FLINK_HOME=/data/flink
Variables should be set according to your environment.
This article then starts Flink using the default local mode.
Start zeppelin
bin/zeppelin-daemon.sh start
If you do not create the logs and run folders at this point, they will be automatically created in the zeppelin directory, as follows:
[root@hadoop zeppelin]# bin/zeppelin-daemon.sh start Log dir doesn't exist, create /data/zeppelin/logs Pid dir doesn't exist, create /data/zeppelin/run Zeppelin start [ OK ]
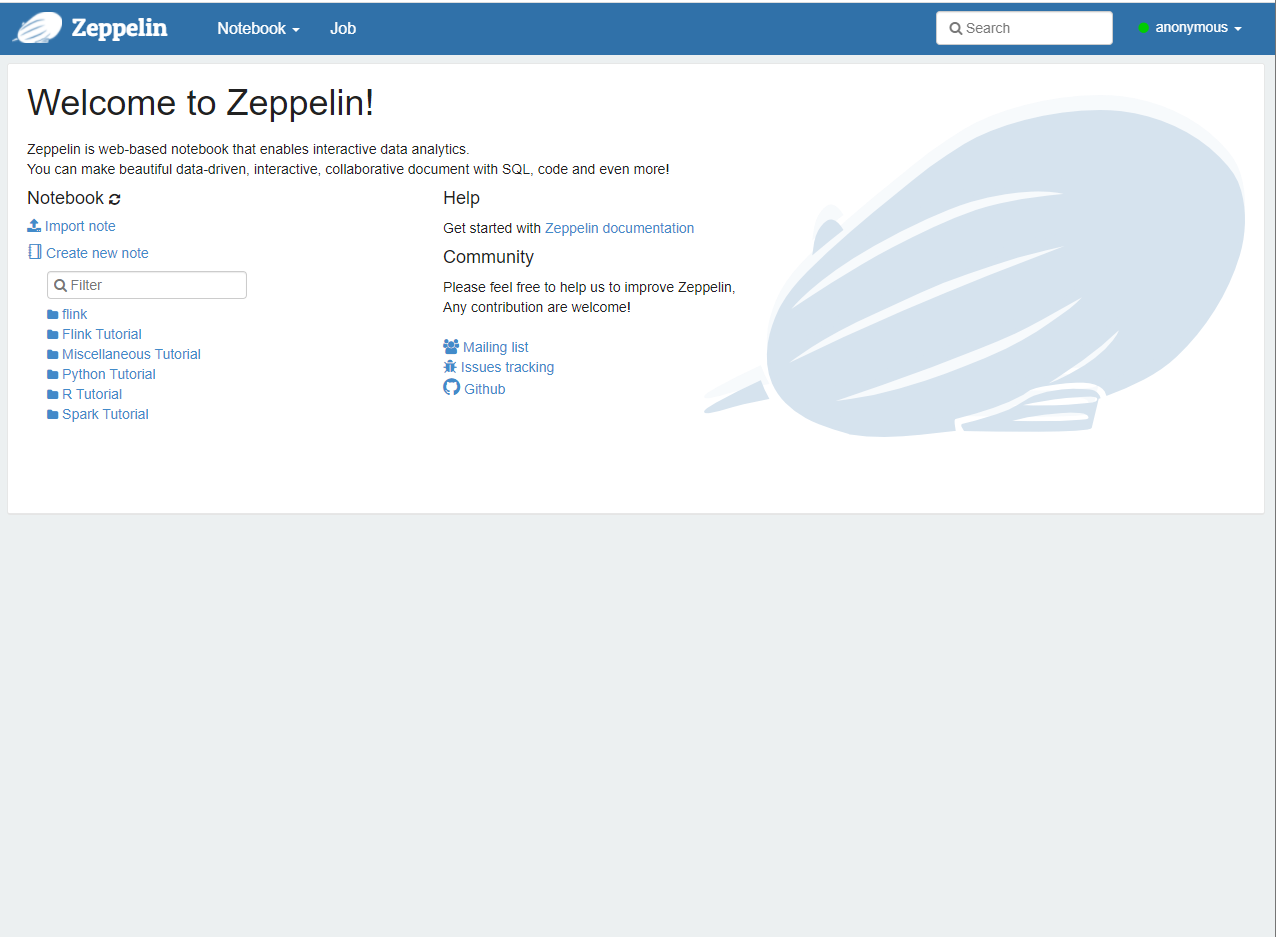
The browser enters the following page by typing zeppelin server ip:8008 or hostname:8008:
Basic Use
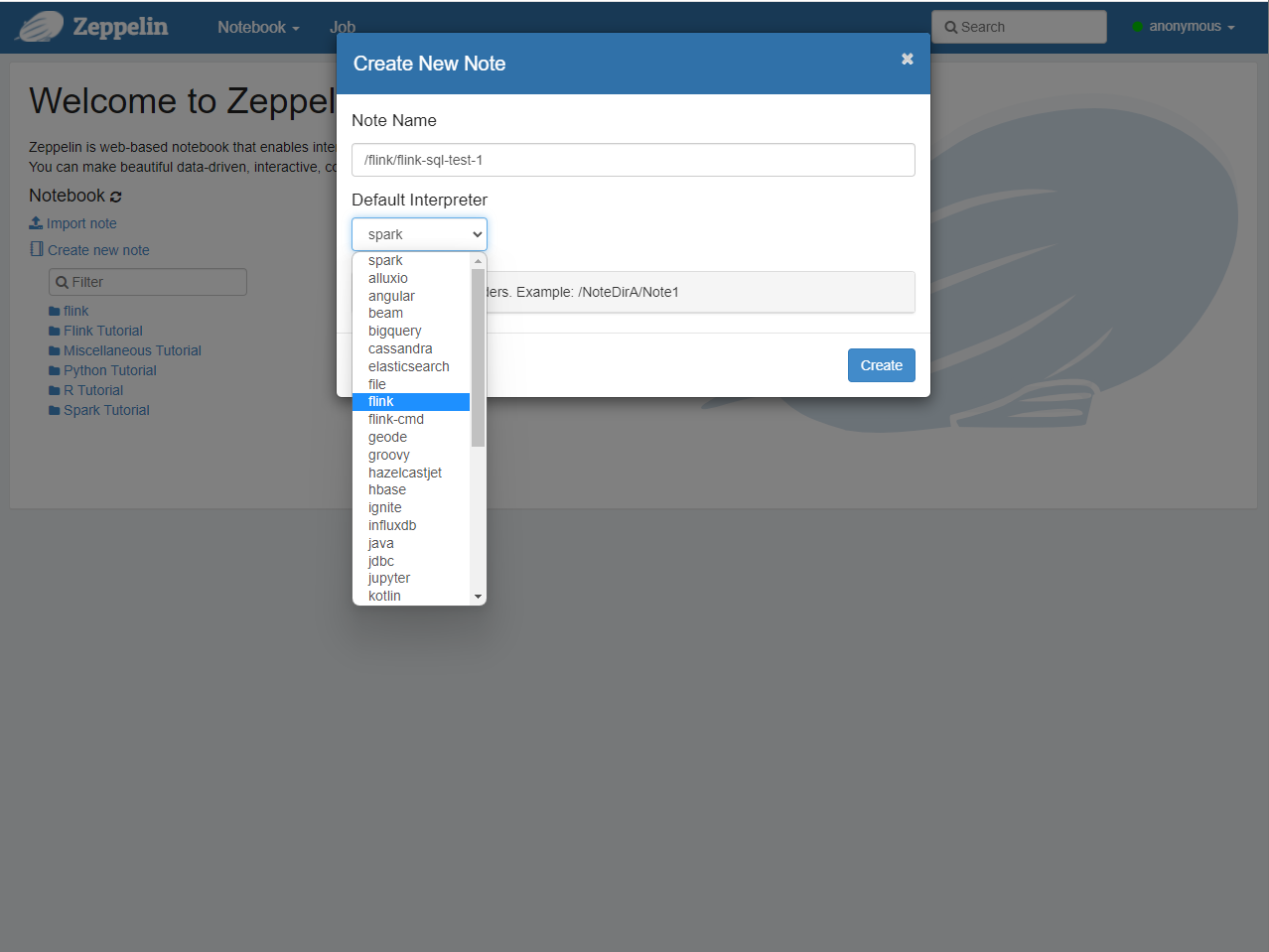
Click Notebook, click Create new note, fill in the text name and select flink interpreter as follows:
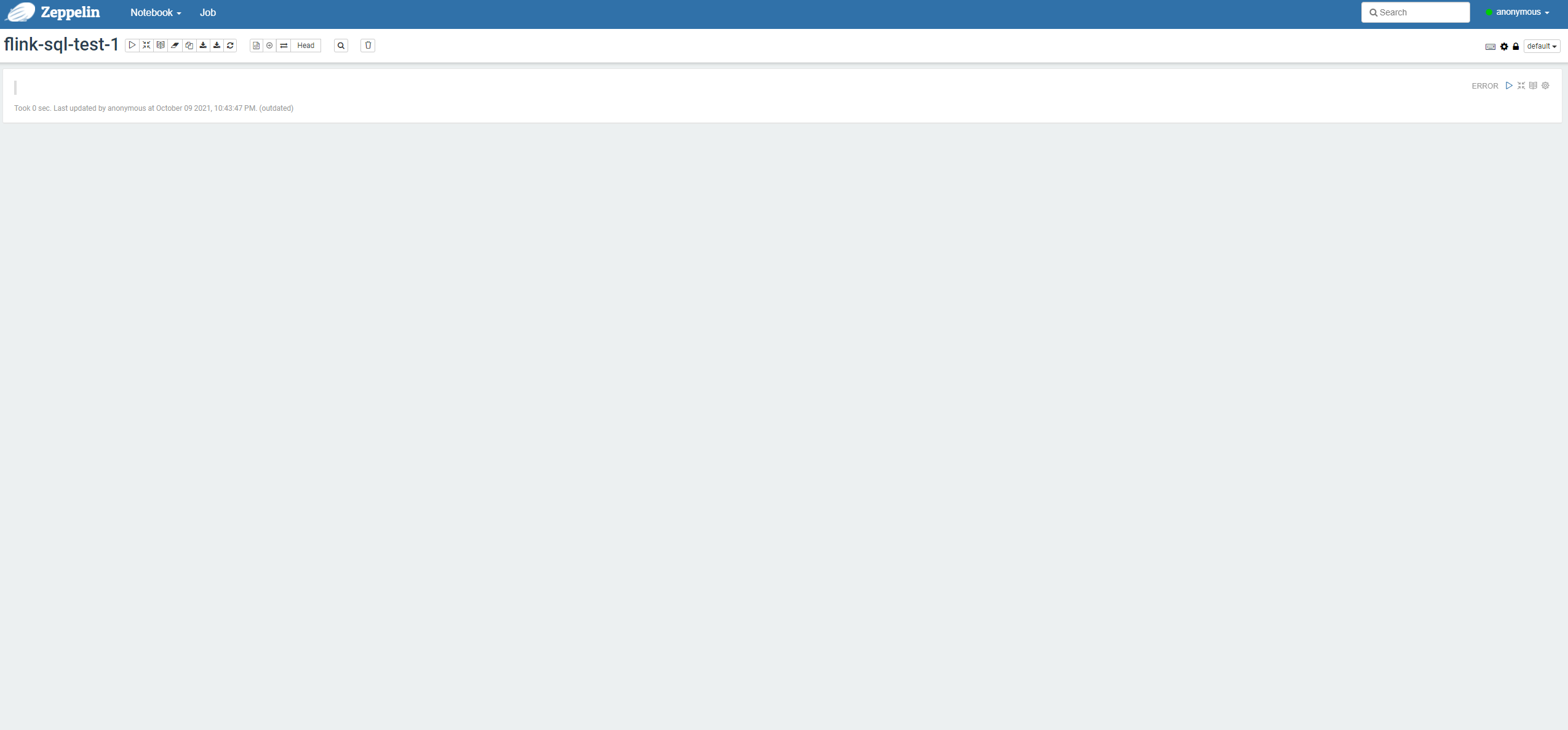
After you create the new page, go to the following page:
As mentioned earlier, we have passed the article
Restore hudi jobs from savepoint using FLINK SQL (flink 1.13)
Importing data into hudi as described, then we can query:
We choose
%flink.ssql
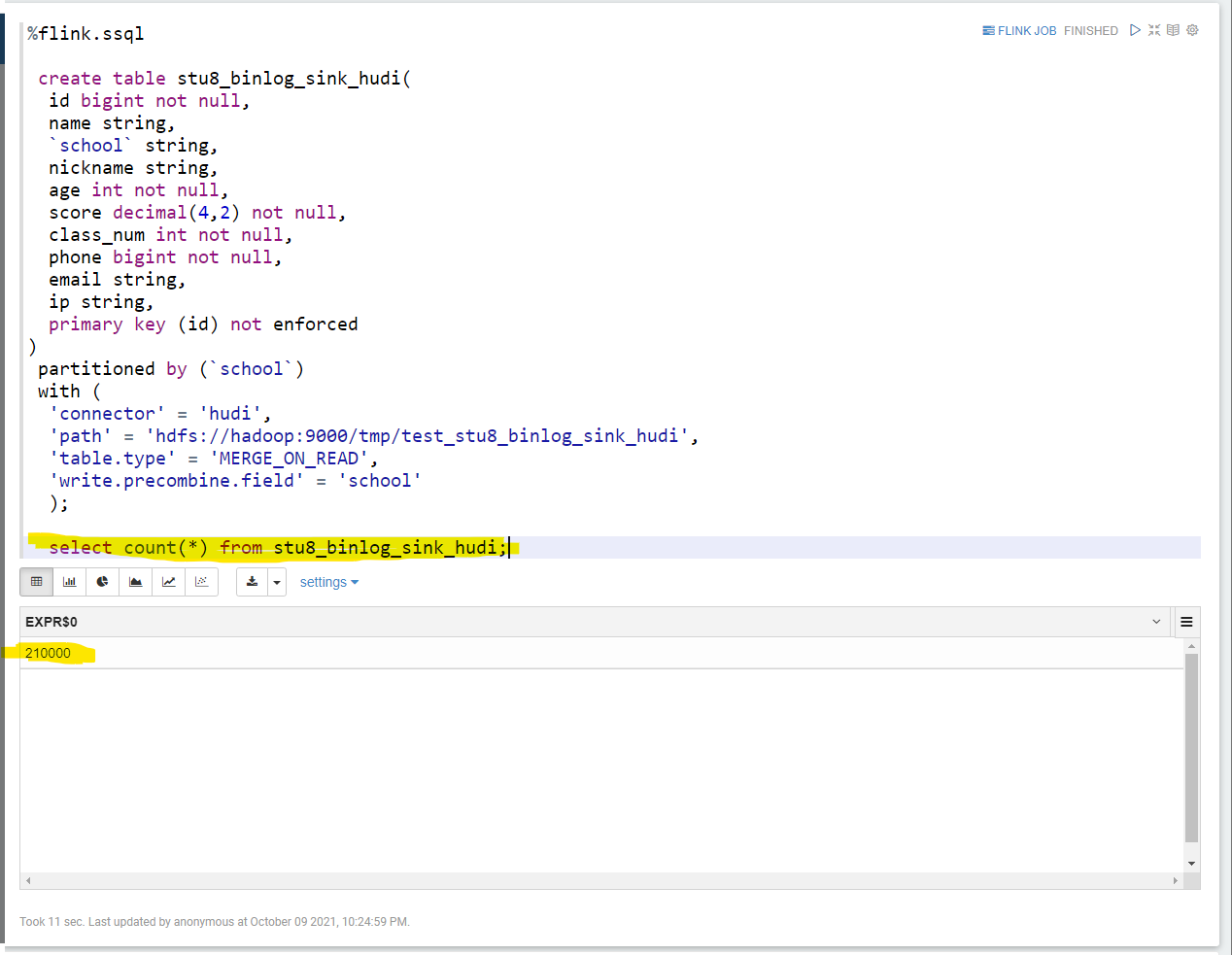
First define the hudi table:
create table stu8_binlog_sink_hudi( id bigint not null, name string, `school` string, nickname string, age int not null, score decimal(4,2) not null, class_num int not null, phone bigint not null, email string, ip string, primary key (id) not enforced ) partitioned by (`school`) with ( 'connector' = 'hudi', 'path' = 'hdfs://hadoop:9000/tmp/test_stu8_binlog_sink_hudi', 'table.type' = 'MERGE_ON_READ', 'write.precombine.field' = 'school' );
Statistics of hudi tables:
select * from stu8_binlog_sink_hudi;
The results are as follows:
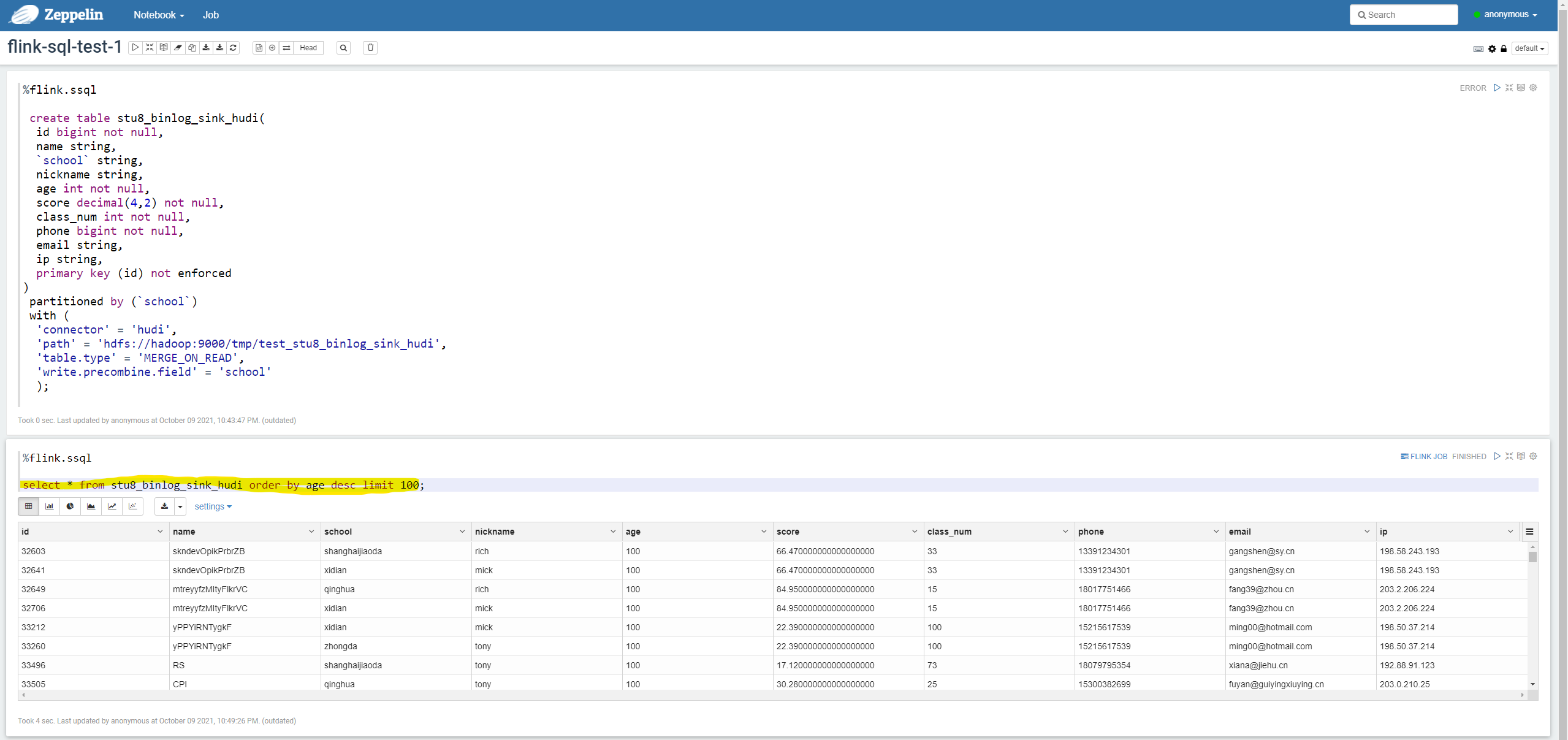
Next, order by query
select * from stu8_binlog_sink_hudi order by age desc limit 100;
summary
This article uses zeppelin in combination with the flink engine to query and count the given hudi data, but what we can do in Flink SQL Client before can be done in zeppelin, and we can completely replace the Flink SQL Client described in the previous article.
Learn more
The practice of hudi in this article is an example of the hudi theme, and more can be found in the following:
https://lrting.top/hudi.html