Zero basics pytoch #2 | loading data sets with pytoch
Ⅰ. Note target
This blog post takes notes on learning the specific practice of pytoch. It is suitable for friends who have a certain theoretical basis for machine learning and in-depth learning but have weak practical ability. This article also focuses on the code practice process, not on the explanation of concepts.
Courseware and reference materials are from: Video of the teacher "Liu Er adult" at station B
*This account is the same owner as error13. This blog is a supplement and update to error13 blog (add source code and detailed explanation).
Ⅱ. Code practice
In general, we need to use the advantages of batch and mini batch to calculate the weight of the matrix, but we can use all the time points to update the weight, although it is relatively good in terms of time; Mini batch can be trained quickly by selecting the appropriate batch size through super parameter debugging.
In the future, each time you write a training cycle, you need to write a double cycle. Run iteration times outside and batch size times inside.

Next, we will focus on the concepts of Epoch and batch size. We know that a complete training process of the model is:
Forward propagation calculation result - > back propagation calculation loss - > Update weight
Then we calculate all the data in the data set by the model. The above process is called the model running through an Epoch.
Because of machine performance or training effect. We rarely forward propagate all data sets, and only update the weight once after back propagation calculation. We usually calculate all data through the model through many iterations.
If we only pass in one image for each Iteration, forward propagation, back propagation and update, then batch size is 1;
If we import N pictures in every Iteration and accumulate the loss after forward propagation and reverse broadcasting of each picture, and then update the weight with the accumulated loss after N pictures are calculated, then batch size is N.
Next, use pictures to visualize the process of dataloader.
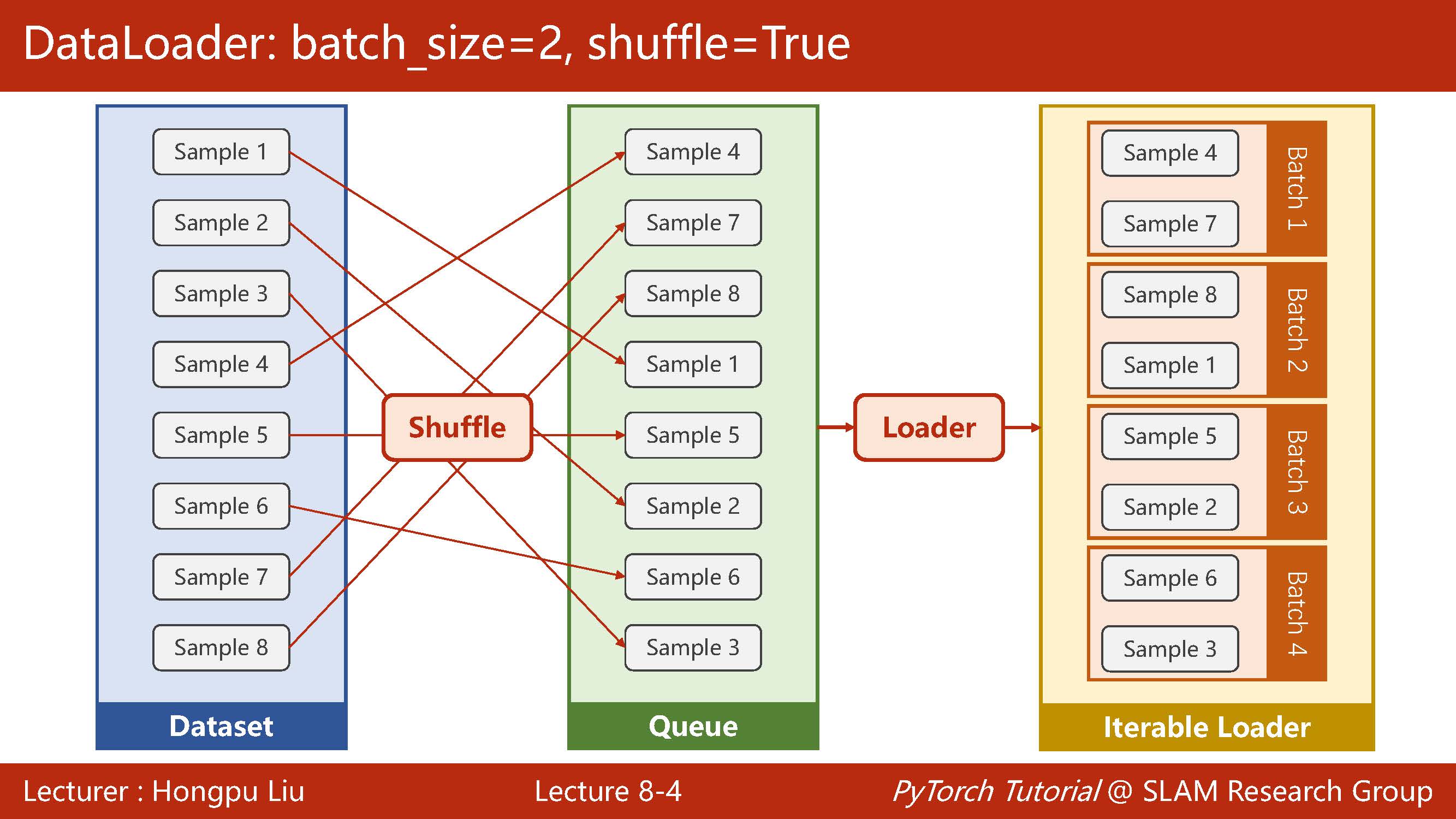
Therefore, the whole process is to inherit classes from dataset and write your own dataset, in which getitem and len need to be rewritten, and then instantiate them and send them to dataloader.
The following explains in detail how to implement it in python. dataset is an abstract class that cannot be instantiated and can only be inherited.
After defining a training model, we can directly inherit it from the dataset. The most important ones are getitem and len. The former is to retrieve data directly by subscript index, and the latter is to calculate the data length.
After the class is defined, it can be instantiated directly. dataloader generally uses only four parameters, including num_workers is the number of threads.

class OurDataset(Dataset):
def __init__(self, filepath) -> None:
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index) -> T_co:
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = OurDataset("file.csv.gz")
data_loader = DataLoader(
dataset = dataset,
batch_size = 32,
shuffle = True,
num_workers = 2
)
In the window, you should pay special attention to the error, and you need to add a line of red code.


The rest is similar to the logistic regression problem, but here we no longer load the whole data set, but load the training with the size of batch size and update the parameters once.


model = Model()
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01)
for epoch in range(200):
for i, data in enumerate(data_loader, start=0):
input, labels = data
output = model(input)
loss = criterion(output,labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()

Ⅲ. Code overview
import torch
import numpy as np
from torch.utils.data import DataLoader, Dataset
class OurDataset(Dataset):
def __init__(self, filepath) -> None:
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index) -> T_co:
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = OurDataset("file.csv.gz")
data_loader = DataLoader(
dataset = dataset,
batch_size = 32,
shuffle = True,
num_workers = 2
)
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear1 = torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,2)
self.linear4 = torch.nn.Linear(2,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
x = self.sigmoid(self.linear4(x))
return x
model = Model()
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01)
for epoch in range(200):
for i, data in enumerate(data_loader, start=0):
input, labels = data
output = model(input)
loss = criterion(output,labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()