How to use
As a distributed service framework, Zookeeper is mainly used to solve the consistency problem of application systems in distributed clusters. It can provide data storage based on directory node tree similar to file system. However, Zookeeper is not used to store data. Its function is mainly to maintain and monitor the state changes of your stored data. By monitoring the changes of these data states, data-based cluster management can be achieved. Later, some typical problems that Zookeeper can solve will be introduced in detail. Here, the operation interface and simple use examples of Zookeeper will be introduced first.
List of common interfaces
The client can connect to the Zookeeper server by creating org apache. Zookeeper. An instance object of Zookeeper, and then invoke the interface provided by this class to interact with the server.
As mentioned earlier, ZooKeeper is mainly used to maintain and monitor the state of the data stored in a directory node tree. All that we can operate ZooKeeper is roughly the same as operating a directory node tree, such as creating a directory node, setting data for a directory node, and obtaining all the subdirectory nodes of a directory node, Set permissions for a directory node and monitor the status changes of this directory node.
These interfaces are shown in the table below:
Table 1. Org apache. zookeeper. ZooKeeper
Method list # method name method function description
| String create(String path, byte[] data, List<ACL> acl,CreateMode createMode) | Create a given directory node path and set data for it, CreateMode There are four forms of directory nodes, namely PERSISTENT: PERSISTENT directory node. The data stored in this directory node will not be lost; PERSISTENT_SEQUENTIAL: a directory node automatically numbered in sequence. This directory node will automatically add 1 according to the number of existing nodes, and then return the name of the directory node successfully created by the client; EPHEMERAL: temporary directory node. Once the client and server ports of this node are created, that is, the session times out, this node will be automatically deleted; EPHEMERAL_SEQUENTIAL: temporary automatic numbering node |
| Stat exists(String path, boolean watch) | Judge whether a path exists and set whether to monitor this directory node. The watcher here is the watcher specified when creating the ZooKeeper instance, exists Method also has an overloaded method that can specify a specific watcher |
| Stat exists(String path,Watcher watcher) | Overload method. Here, a specific watcher is set for a directory node. Watcher is a core function in ZooKeeper. Watcher can monitor the data changes of directory nodes and the changes of subdirectories. Once these states change, the server will notify all watchers set on this directory node, Thus, each client will quickly know that the state of the directory node it is concerned about has changed and respond accordingly |
| void delete(String path, int version) | Delete the directory node corresponding to path. If the version is - 1, any version can be matched, and all data of this directory node will be deleted |
| List<String>getChildren(String path, boolean watch) | Get all subdirectory nodes under the specified path. Similarly getChildren Method also has an overloaded method that can set a specific watcher to monitor the status of child nodes |
| Stat setData(String path, byte[] data, int version) | Setting data for path can specify the version number of this data. If the version is - 1, how can it match any version |
| byte[] getData(String path, boolean watch, Stat stat) | Get the data stored in the directory node corresponding to this path, and the version of the data can be specified through stat. at the same time, you can also set whether to monitor the data status of this directory node |
| voidaddAuthInfo(String scheme, byte[] auth) | The client submits its authorization information to the server, and the server will verify the access rights of the client according to the authorization information. |
| Stat setACL(String path,List<ACL> acl, int version) | Reset the access permission of a directory node. It should be noted that the permission of the directory node in Zookeeper is not transferable, and the permission of the parent directory node cannot be transferred to the child directory node. The directory node ACL consists of two parts: perms and id. Perms includes ALL, READ, WRITE, CREATE, DELETE and ADMIN The id identifies the identity list of the access directory node. By default, there are two types: ANYONE_ID_UNSAFE = new Id("world", "anyone") and AUTH_IDS = new Id("auth", "") respectively indicates that anyone can access and the creator has access rights. |
| List<ACL>getACL(String path,Stat stat) | Get the access permission list of a directory node |
In addition to the above methods listed in the above table, there are also some overloaded methods, such as the overloaded methods that provide a callback class and the overloaded methods that can set a specific Watcher. For specific methods, please refer to org apache. zookeeper. API description of zookeeper class.
basic operation
The following is the sample code for the basic operation of ZooKeeper, so that you can have an intuitive understanding of ZooKeeper. The following list includes creating a connection to the ZooKeeper server and the most basic data operations:
Basic operation examples of ZooKeeper
package com.dxz.zktest;
import java.io.IOException;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.ZooKeeper;
import com.dxz.zktest.utils.ClientBase;
import com.dxz.zktest.utils.Constants;
public class Test {
public static void main(String[] args) throws IOException, KeeperException,
InterruptedException {
// TODO Auto-generated method stub
// Create a connection to the server
ZooKeeper zk = new ZooKeeper("localhost:" + Constants.CLIENT_PORT,
ClientBase.CONNECTION_TIMEOUT, new Watcher() {
// Monitor all triggered events
public void process(WatchedEvent event) {
System.out.println("It's triggered" + event.getType() + "event!");
}
});
// Create a directory node
zk.create("/testRootPath", "testRootData".getBytes(),
Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
// Create a subdirectory node
zk.create("/testRootPath/testChildPathOne",
"testChildDataOne".getBytes(), Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
System.out
.println(new String(zk.getData("/testRootPath", false, null)));
// Take out the subdirectory node list
System.out.println(zk.getChildren("/testRootPath", true));
// Modify subdirectory node data
zk.setData("/testRootPath/testChildPathOne",
"modifyChildDataOne".getBytes(), -1);
System.out.println("Directory node status:[" + zk.exists("/testRootPath", true) + "]");
// Create another subdirectory node
zk.create("/testRootPath/testChildPathTwo",
"testChildDataTwo".getBytes(), Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
System.out.println(new String(zk.getData(
"/testRootPath/testChildPathTwo", true, null)));
// Delete subdirectory node
zk.delete("/testRootPath/testChildPathTwo", -1);
zk.delete("/testRootPath/testChildPathOne", -1);
// Delete parent directory node
zk.delete("/testRootPath", -1);
// Close connection
zk.close();
}
}The output results are as follows:
It's triggered None event! testRootData [testChildPathOne] Directory node status:[5,5,1281804532336,1281804532336,0,1,0,0,12,1,6] It's triggered NodeChildrenChanged event! testChildDataTwo It's triggered NodeDeleted event! It's triggered NodeDeleted event!
When the monitoring status of the directory node is turned on, once the status of the directory node changes, the process method of the Watcher object will be called.
Typical application scenarios of ZooKeeper
From the perspective of design pattern, Zookeeper is a distributed service management framework designed based on observer pattern. It is responsible for storing and managing data that everyone cares about, and then accepting the registration of observers. Once the status of these data changes, Zookeeper will be responsible for notifying those observers who have registered on Zookeeper to respond accordingly, So as to realize the similar Master/Slave management mode in the cluster. You can read the source code of Zookeeper for the detailed architecture and other internal details of Zookeeper
The following describes in detail these typical application scenarios, that is, what problems can Zookeeper help us solve? The answer is given below.
Unified Name Service
In distributed applications, it is usually necessary to have a complete set of naming rules, which can not only produce unique names, but also facilitate people to recognize and remember. Usually, the tree name structure is an ideal choice. The tree name structure is a hierarchical directory structure, which is friendly to people and will not be repeated. At this point, you may think of JNDI. Yes, Zookeeper's Name Service can perform the same functions as JNDI. They both associate a hierarchical directory structure with a certain resource, but Zookeeper's Name Service is more related in a broad sense. Maybe you don't need to associate the name with a specific resource, You may only need a non duplicate name, just like generating a unique digital primary key in the database.
Name Service is already a built-in function of Zookeeper. You can implement it by calling Zookeeper's API. If you call the create interface, you can easily create a directory node.
Configuration Management
Configuration management is very common in distributed application environment. For example, the same application system requires multiple PC servers to run, but some configuration items of the application system they run are the same. If you want to modify these same configuration items, you must modify each PC Server running the application system at the same time, which is very troublesome and error prone.
The configuration information like this can be managed by Zookeeper. Save the configuration information in a directory node of Zookeeper, and then monitor the status of the configuration information of all application machines that need to be modified. Once the configuration information changes, each application machine will receive a notification from Zookeeper, Then obtain new configuration information from Zookeeper and apply it to the system.
Figure 2 Configuration management structure diagram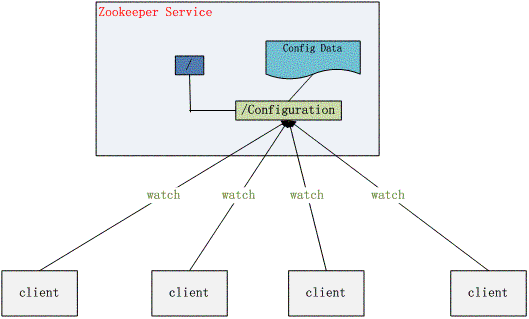
Group Membership
Zookeeper can easily realize the function of cluster management. If multiple servers form a service cluster, a "manager" must know the service status of each machine in the current cluster. Once a machine cannot provide services, other clusters in the cluster must know, so as to adjust and reassign the service strategy. Similarly, when the service capacity of the cluster is increased, one or more servers will be added, which must also be known to the "manager".
Zookeeper can not only help you maintain the service status of the machines in the current cluster, but also help you select a "manager" to manage the cluster. This is another function of zookeeper, leader selection.
They are implemented by creating an EPHEMERAL type directory node on Zookeeper, and then each Server calls it on the parent directory node where they create the directory node getChildren(String path, boolean (watch) method and set watch to true. As it is an EPHEMERAL directory node, when the Server that created it dies, the directory node will be deleted, so Children will change. At this time getChildren The Watch on will be called, so other servers will know that a Server has died. The same principle applies to the new Server.
How Zookeeper implements leader selection, that is, selecting a Master Server. As before, each Server creates an EPHEMERAL directory node. The difference is that it is also a SEQUENTIAL directory node, so it is an EPHEMERAL directory node_ Serial directory node. The reason why it is EPHEMERAL_ The SEQUENTIAL directory node is because we can number each Server. We can select the Server with the lowest number as the Master. If the Server with the lowest number dies, because it is an EPHEMERAL node, the node corresponding to the dead Server is also deleted, so another node with the lowest number appears in the current node list, We choose this node as the current Master. In this way, the dynamic selection of Master is realized, and the problem of single point of failure of single Master in the traditional sense is avoided.
Figure 3 Cluster management structure diagram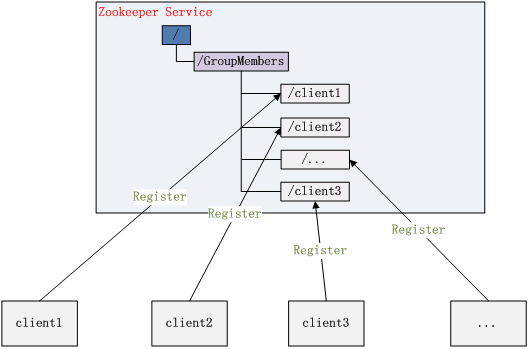
The sample code of this part is as follows. See the attachment for the complete code:
Leader Election key code
void findLeader() throws InterruptedException {
byte[] leader = null;
try {
leader = zk.getData(root + "/leader", true, null);
} catch (Exception e) {
logger.error(e);
}
if (leader != null) {
following();
} else {
String newLeader = null;
try {
byte[] localhost = InetAddress.getLocalHost().getAddress();
newLeader = zk.create(root + "/leader", localhost,
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
} catch (Exception e) {
logger.error(e);
}
if (newLeader != null) {
leading();
} else {
mutex.wait();
}
}
}Shared Locks
Shared locks are easy to implement in the same process, but not across processes or between different servers. Zookeeper is easy to implement this function. The implementation method is to create an ephemeral for the Server that needs to obtain the lock_ SEQUENTIAL directory node, then call getChildren Method to obtain whether the smallest directory node in the current directory node list is the directory node created by itself. If it is created by itself, it will obtain the lock. If not, it will call exists(String path, boolean (watch) method and monitor the changes in the list of directory nodes on Zookeeper until the node you create is the directory node with the smallest number in the list, so as to obtain the lock. Releasing the lock is very simple. Just delete the directory node you created earlier.
Figure 4 Flow chart of zookeeper implementing Locks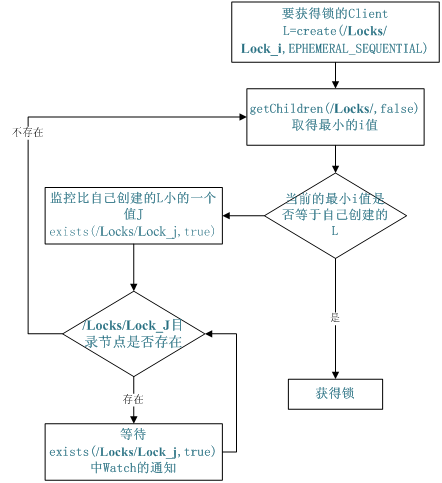
The implementation code of synchronization lock is as follows. See the attachment for the complete code:
Key ideas of synchronous lock
Locking: ZooKeeper The locking operation will be realized as follows: 1 ) ZooKeeper call create ()Method to create a path in the format“ _locknode_/lock- "Node of type sequence ((continuous) and ephemeral (Temporary). That is, the created nodes are temporary nodes, and all nodes are numbered consecutively, i.e“ lock-i "Format. 2 )Called on the created lock node getChildren ()Method to obtain the minimum number node under the lock directory without setting watch . 3 )If the node obtained in step 2 happens to be the node created by the client in step 1, the client obtains this type of lock and then exits the operation. 4 )The client calls on the lock directory exists ()Method, and set watch To monitor the status of a continuous temporary node smaller than itself in the lock directory. 5 )If the status of the monitoring node changes, skip to step 2 and continue the subsequent operations until the lock competition is exited. Unlock: ZooKeeper The unlocking operation is very simple. The client only needs to delete the temporary node created in step 1 of the locking operation.
Key code of synchronization lock
void getLock() throws KeeperException, InterruptedException{
List<String> list = zk.getChildren(root, false);
String[] nodes = list.toArray(new String[list.size()]);
Arrays.sort(nodes);
if(myZnode.equals(root+"/"+nodes[0])){
doAction();
}
else{
waitForLock(nodes[0]);
}
}
void waitForLock(String lower) throws InterruptedException, KeeperException {
Stat stat = zk.exists(root + "/" + lower,true);
if(stat != null){
mutex.wait();
}
else{
getLock();
}
}queue management
Zookeeper can handle two types of queues:
- When the members of a queue are gathered, the queue is available. Otherwise, it waits for all members to arrive. This is a synchronous queue.
- The queue performs queue in and queue out operations in FIFO mode, such as implementing producer and consumer models.
The implementation idea of synchronous queue realized by Zookeeper is as follows:
Create a parent directory / synchronizing. Each member monitors whether the flag bit directory / synchronizing/start exists. Then each member joins the queue by creating / synchronizing/member_i, and then each member obtains all directory nodes of / synchronizing directory, that is, member_i. Judge whether the value of I is already the number of members. If it is less than the number of members, wait for / synchronizing/start. If it is equal, create / synchronizing/start.
It is easier to understand with the following flow chart:
Figure 5 Synchronization queue flowchart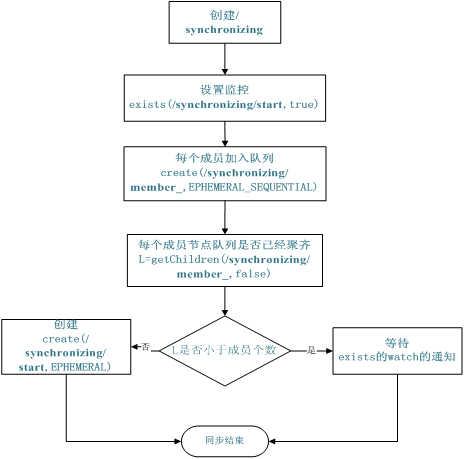
The key codes of synchronization queue are as follows. Please see the attachment for the complete code:
Synchronization queue
void addQueue() throws KeeperException, InterruptedException{
zk.exists(root + "/start",true);
zk.create(root + "/" + name, new byte[0], Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
synchronized (mutex) {
List<String> list = zk.getChildren(root, false);
if (list.size() < size) {
mutex.wait();
} else {
zk.create(root + "/start", new byte[0], Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
}
}
}When the queue is not full, it enters wait(), and then it will wait for the notice of Watch. The code of Watch is as follows:
public void process(WatchedEvent event) {
if(event.getPath().equals(root + "/start") &&
event.getType() == Event.EventType.NodeCreated){
System.out.println("Get informed");
super.process(event);
doAction();
}
}The implementation idea of FIFO queue with Zookeeper is as follows:
The implementation idea is also very simple, that is, create a subdirectory / queue of serial type in a specific directory_ i. This ensures that all members are numbered when they join the queue. When they leave the queue, they can return all the elements in the current queue through the getChildren() method, and then consume the smallest one, so as to ensure FIFO.
The following is the sample code of the queue form of producers and consumers. For the complete code, please see the attachment:
Producer code
boolean produce(int i) throws KeeperException, InterruptedException{
ByteBuffer b = ByteBuffer.allocate(4);
byte[] value;
b.putInt(i);
value = b.array();
zk.create(root + "/element", value, ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT_SEQUENTIAL);
return true;
}Consumer code
int consume() throws KeeperException, InterruptedException{
int retvalue = -1;
Stat stat = null;
while (true) {
synchronized (mutex) {
List<String> list = zk.getChildren(root, true);
if (list.size() == 0) {
mutex.wait();
} else {
Integer min = new Integer(list.get(0).substring(7));
for(String s : list){
Integer tempValue = new Integer(s.substring(7));
if(tempValue < min) min = tempValue;
}
byte[] b = zk.getData(root + "/element" + min,false, stat);
zk.delete(root + "/element" + min, 0);
ByteBuffer buffer = ByteBuffer.wrap(b);
retvalue = buffer.getInt();
return retvalue;
}
}
}
}summary
As a sub project of Hadoop project, Zookeeper is an essential module of Hadoop cluster management. It is mainly used to control the data in the cluster, such as managing the NameNode in Hadoop cluster, master selection in Hbase, state synchronization between servers, etc.
This paper introduces the basic knowledge of Zookeeper and several typical application scenarios. These are the basic functions of Zookeeper. The most important thing is that Zoopkeeper provides a set of good distributed cluster management mechanism, which is based on the hierarchical directory tree data structure and effectively manages the nodes in the tree, so that a variety of distributed data management models can be designed, It is not limited to the several common application scenarios mentioned above.
The following will briefly introduce ZooKeeper client programming from four aspects: basic usage, Watchert usage, asynchronous call and ACL.
After understanding these four aspects, ZK can be used to complete some more advanced tasks, such as distributed lock, Master election, consistency service guarantee, configuration management, etc. This is also briefly described in the official documents,
reference resources: http://zookeeper.apache.org/doc/r3.4.3/recipes.html
Basic data structure
class Stat {
private long czxid;
private long mzxid;
private long ctime;
private long mtime;
private int version;
private int cversion;
private int aversion;
private long ephemeralOwner;
private int dataLength;
private int numChildren;
private long pzxid;
}
class Id {
private String scheme; //world,auth,digest,ip
private String id;
}
class ACL {
private int perms; //CREATE,READ,WRITE,DELETE,ADMIN
private org.apache.zookeeper.data.Id id;
} Basic use
try {
static String hostport = "127.0.0.1:2181";
ZooKeeper zooKeeper = new ZooKeeper(hostport, 300000, null); //Create an instance of ZooKeeper without setting the default watcher
String path = "/test";
zooKeeper.create(path, path.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); //Create a node
Stat stat = new Stat();
byte[] b = zooKeeper.getData(path, false, stat); //Obtain node information and stored data
System.out.println(stat);
System.out.println(new String(b));
stat = zooKeeper.exists(path, false); //Check whether the node represented by path exists
zooKeeper.setData(path, "helloworld".getBytes(), stat.getVersion()); //Set the data of the node
//zooKeeper.delete(path, -1); // Delete node
zooKeeper.close(); //Close instance
} catch (Exception e) {
e.printStackTrace();
} ZooKeeper controls the permissions of nodes through Auth and ACL.
Auth means some kind of authentication. Because a ZooKeeper cluster may be used by multiple projects and each project belongs to different project groups, they certainly don't want other projects to access their related nodes during development. At this time, they can assign an auth to each project group, and then each project group passes auth authentication before continuing relevant operations, In this way, a user authenticated by auth cannot operate other nodes created after auth authentication, so as to realize the isolation between various projects. ZooKeeper provides the following methods to complete the certification, as shown below:
Void addAuthInfo(String scheme, byte[] auth). The usage example is as follows:
@Test
public void testFirstStep() {
try {
zk = new ZooKeeper(hostport, 1000000, null);
String auth_type = "digest";
String auth = "joey:some";
String p = "/acl_digest";
zk.addAuthInfo(auth_type, auth.getBytes());
zk.create(p, "hello".getBytes(), Ids.CREATOR_ALL_ACL, CreateMode.PERSISTENT);
Stat stat = new Stat();
System.out.println(new String(zk.getData(p, false, stat)));
zk.close();
} catch(Exception ex) {
ex.printStackTrace();
}
}
@Test
public void testSecondStep() {
String p = "/acl_digest";
try {
zk = new ZooKeeper(hostport, 1000000, null);
String authType = "digest";
String badAuth = "joey:someBAD";
zk.addAuthInfo(authType, badAuth.getBytes());
Stat stat = new Stat();
System.out.println(new String(zk.getData(p, false, stat)));
} catch(Exception ex) {
ex.printStackTrace(); //Throw exception
} finally {
try {
zk.delete(p, -1);
zk.close();
} catch (Exception e) {
e.printStackTrace();
}
}
} ACL is used to control the access of Znode. Similar to UNIX file access permission, ACL provides the ability to set certain permissions for certain types of users (such as reading, writing and executing permissions for Owner in Unix). However, there are no concepts such as Owner and Group in ZooKeeper. Therefore, ID is used to represent a certain type of users in ZooKeeper, and certain permissions can be set for ID. (ZooKeeper has no limit on the number of IDS, unlike UNIX files, which only support three types of users)
Permissions supported by ZooKeeper:
CREATE: you can create a child node
READ: you can get data from a node and list its children.
WRITE: you can set data for a node
DELETE: you can delete a child node
ADMIN: you can set permissions
Built in sheet of ZooKeeper: (scheme is one of the attributes of ID)
world has a single id, anyone, that represents anyone.
auth doesn't use any id, represents any authenticated user.
digest uses a username:password string to generate MD5 hash which is then used as an ACL ID identity. Authentication is done by sending theusername:password in clear text. When used in the ACL the expression will be the username:base64 encoded SHA1 password digest.
ip uses the client host IP as an ACL ID identity. The ACL expression is of the form addr/bits where the most significant bits of addr are matched against the most significant bits of the client host IP.
ZK built-in ID:
ANYONE_ID_UNSAFE / / any user
AUTH_IDS / / users authenticated by Auth
Built in permission control set:
OPEN_ACL_UNSAFE: create a node that anyone can operate on
READ_ACL_UNSAFE: create a node that anyone can read
CREATOR_ALL_ACL: a user with Auth set can use the ACL set to create a node, and the node can only be operated by users authorized by the same Auth
The example code is as follows:
@Test
public void testACL_with_ip_scheme() {
try {
Id id = new Id();
id.setScheme("ip");
id.setId(InetAddress.getLocalHost().getHostAddress());
ACL acl = new ACL();
acl.setId(id); //Set permissions on the target specified by the ID
acl.setPerms(Perms.ALL);
List<ACL> acls = new ArrayList<ACL>();
acls.add(acl); //You can add multiple running IP addresses
String p = "/ip";
zk.create(p, p.getBytes(), acls, CreateMode.PERSISTENT);
zk.delete(p, -1); //Only users with the same IP can operate on this
} catch(Exception ex) {
ex.printStackTrace();
}
} Watcher
How Watcher can be set:
1) Watcher can be set in the constructor of ZooKeeper
2) Use zookeeper Register (Watcher) changes the default Watcher set in the constructor
3) The Watcher of the node corresponding to a path can be changed by calling some methods
The specific method of setting Watcher is as follows:
1) Constructor: state # changes # or # node # events
2) Register: modify the default Watcher specified in the constructor
3) getData: triggered by sets data on the node, or deletes the node.
4) getChildren: triggered by deletes the node or creates/delete a child under the node.
5) exists: triggered by creates/delete the node or sets the data on the node.
The watcher specified in the constructor stage is always valid (register mode belongs to this class), and the watcher set in other methods is only valid once. When calling a method, if you specify to turn on the watcher, if the node sets the watcher through getData, getChildren and exists, the Watcher will be triggered, and then the Watcher will be invalidated (but the default watcher is still in effect). Otherwise, the default watcher set in the constructor will be triggered.
The example code is as follows:
class ExistsWatcher implements Watcher {
@Override
public void process(WatchedEvent event) {
System.out.println("---------------------------");
System.out.println("setting by exist watcher");
System.out.println("path is : " + event.getPath());
System.out.println("type is : " + event.getType());
System.out.println("state is : " + event.getState());
System.out.println("---------------------------");
}
}
class DefaultWatcher implements Watcher {
@Override
public void process(WatchedEvent event) {
System.out.println("=====>Default Watch Event: " + event.getType());
}
}
@Test
public void testWatcher() {
try {
DefaultWatcher defaultWatcher = new DefaultWatcher();
ExistsWatcher existsWatcher = new ExistsWatcher();
String p = "/watcher";
ZooKeeper zk = new ZooKeeper(hostport, 300000, null);
zk.register(defaultWatcher);
Stat stat = zk.exists(p, existsWatcher);
zk.create(p, p.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
stat = zk.exists(p, true);
byte[] b = zk.getData(p, true, stat);
System.out.println(new String(b));
stat = zk.exists(p, true);
zk.setData(p, "Iloveyou".getBytes(), stat.getVersion());
stat = zk.exists(p, existsWatcher);
zk.delete(p, stat.getVersion());
zk.close();
} catch(Exception ex) {
ex.printStackTrace();
}
} The operation results are as follows:
=====>Default Watch Event: None --------------------------- setting by exist watcher path is : /watcher type is : NodeCreated state is : SyncConnected --------------------------- /watcher =====>Default Watch Event: NodeDataChanged --------------------------- setting by exist watcher path is : /watcher type is : NodeDeleted state is : SyncConnected ---------------------------
Asynchronous call
As the name suggests, asynchronous call means that after calling a method, you do not wait for its return, but then process the following tasks. When the method call is completed, a callback function is triggered. The callback function needs to be specified during the method call, and then process the result of the method call in the callback function.
In ZK, almost every method is provided with the version of asynchronous call, such as getData method. Its function prototype is as follows:
void getData(String path, boolean watch, DataCallback cb, Object ctx);
Of which:
DataCallback is a class that provides callback functions,
ctx is the parameter required by the callback function
The example code is as follows:
Children2Callback cb = new Children2Callback() {
@Override
public void processResult(int rc, String path, Object ctx,
List<String> children, Stat stat) {
for (String s : children) {
System.out.println("----->" + s);
}
System.out.println(ctx); //Output: helloworld
}
};
zk.getChildren(path, true, cb, "helloworld");