preface:
Part of the reason why Zookeeper responds quickly is that its node data is loaded into memory. It avoids querying on disk every time a node is queried.
The ZKDatabase introduced in this article exists as an in memory database of Zookeeper.
Let's mainly look at how it loads data at startup, synchronizes changes during transaction execution, and synchronizes data to the snapshot log.
1. Basic structure of zkdatabase
/**
* This class maintains the in memory database of zookeeper
* server states that includes the sessions, datatree and the
* committed logs. It is booted up after reading the logs
* and snapshots from the disk.
*/
public class ZKDatabase {
// This article mainly analyzes the attribute dataTree, which is the node storage object in memory
protected DataTree dataTree;
protected ConcurrentHashMap<Long, Integer> sessionsWithTimeouts;
protected FileTxnSnapLog snapLog;
public ZKDatabase(FileTxnSnapLog snapLog) {
dataTree = new DataTree();
sessionsWithTimeouts = new ConcurrentHashMap<Long, Integer>();
this.snapLog = snapLog;
}
}ZKDatabase realizes the memory loading of data mainly through DataTree. Let's look at the structure of DataTree
1.1 DataTree
/**
* This class maintains the tree data structure. It doesn't have any networking
* or client connection code in it so that it can be tested in a stand alone
* way.
* <p>
* The tree maintains two parallel data structures: a hashtable that maps from
* full paths to DataNodes and a tree of DataNodes. All accesses to a path is
* through the hashtable. The tree is traversed only when serializing to disk.
*/
public class DataTree {
// map set corresponding to all nodes
private final ConcurrentHashMap<String, DataNode> nodes = new ConcurrentHashMap<String, DataNode>();
// map set corresponding to temporary node
private final Map<Long, HashSet<String>> ephemerals = new ConcurrentHashMap<Long, HashSet<String>>();
}It is easy to see that the node information is stored in nodes in the form of Map in the Zookeeper server. The key is the path and the value is the DataNode. Let's take a look at the basic information of DataNode
1.2 DataNode
public class DataNode implements Record {
// Parent node
DataNode parent;
// Node data information
byte data[];
// acl permission information
Long acl;
// Node stat information
public StatPersisted stat;
// Child node set
private Set<String> children = null;
DataNode() {
}
public DataNode(DataNode parent, byte data[], Long acl, StatPersisted stat) {
this.parent = parent;
this.data = data;
this.acl = acl;
this.stat = stat;
}
}DataNode basically contains all the information of a node, and stat information is stored in Statpersisted object.
Summary: through the analysis of ZKDatabase structure, we know that the node information is stored in DataTree in the form of map, and the node information is stored in DataNode
2. When zookeeper server starts, load snapshot data into ZKDatabase
In the previous analysis of the startup process of the stand-alone version of Zookeeper server, a knowledge point was directly skipped, that is, load the snapshot data into memory at startup, that is, the following code
public class NIOServerCnxnFactory extends ServerCnxnFactory implements Runnable {
public void startup(ZooKeeperServer zks) throws IOException,
InterruptedException {
...
// Load data into memory. We know this operation first. We will explain it later when analyzing the transaction log
zks.startdata();
...
}
}This is the sentence ZookeeperServer.startdata(), which loads the snapshot data into memory. Let's take a look at it together.
2.1 ZookeeperServer.startdata()
public class ZooKeeperServer implements SessionExpirer, ServerStats.Provider {
public void startdata()
throws IOException, InterruptedException {
//check to see if zkDb is not null
if (zkDb == null) {
// Create ZKDatabase
zkDb = new ZKDatabase(this.txnLogFactory);
}
if (!zkDb.isInitialized()) {
// Initialize load data
loadData();
}
}
public void loadData() throws IOException, InterruptedException {
// This problem will be analyzed later
if(zkDb.isInitialized()){
setZxid(zkDb.getDataTreeLastProcessedZxid());
}
else {
// The key point here is to call the loadDataBase() method directly. Look at 2.2 directly
setZxid(zkDb.loadDataBase());
}
...
}
}2.2 ZKDatabase.loadDataBase()
public class ZKDatabase {
protected FileTxnSnapLog snapLog;
public long loadDataBase() throws IOException {
// Directly call the FileTxnSnapLog method
long zxid = snapLog.restore(dataTree, sessionsWithTimeouts, commitProposalPlaybackListener);
initialized = true;
return zxid;
}
}2.3 FileTxnSnapLog.restore()
public class FileTxnSnapLog {
public long restore(DataTree dt, Map<Long, Integer> sessions,
PlayBackListener listener) throws IOException {
// Call deserialization
snapLog.deserialize(dt, sessions);
// Here, load the requests that have not been updated to the snapshot log but have been added to the transaction log, and add the corresponding nodes to the DataTree again
return fastForwardFromEdits(dt, sessions, listener);
}
}2.4 FileSnap.deserialize() is finally executed here
public class FileSnap implements SnapShot {
public long deserialize(DataTree dt, Map<Long, Integer> sessions)
throws IOException {
// Get up to 100 valid snapshot log files directly from the dataDir directory
List<File> snapList = findNValidSnapshots(100);
if (snapList.size() == 0) {
return -1L;
}
File snap = null;
boolean foundValid = false;
for (int i = 0; i < snapList.size(); i++) {
snap = snapList.get(i);
InputStream snapIS = null;
CheckedInputStream crcIn = null;
try {
LOG.info("Reading snapshot " + snap);
snapIS = new BufferedInputStream(new FileInputStream(snap));
// Check checksum
crcIn = new CheckedInputStream(snapIS, new Adler32());
InputArchive ia = BinaryInputArchive.getArchive(crcIn);
// Deserialize file
deserialize(dt,sessions, ia);
long checkSum = crcIn.getChecksum().getValue();
long val = ia.readLong("val");
if (val != checkSum) {
throw new IOException("CRC corruption in snapshot : " + snap);
}
foundValid = true;
break;
} ...
}
...
}
public void deserialize(DataTree dt, Map<Long, Integer> sessions,
InputArchive ia) throws IOException {
FileHeader header = new FileHeader();
// Deserialize header file information, check magic number
header.deserialize(ia, "fileheader");
if (header.getMagic() != SNAP_MAGIC) {
throw new IOException("mismatching magic headers "
+ header.getMagic() +
" != " + FileSnap.SNAP_MAGIC);
}
// The data information is deserialized here as follows
SerializeUtils.deserializeSnapshot(dt,ia,sessions);
}
}
public class SerializeUtils {
public static void deserializeSnapshot(DataTree dt,InputArchive ia,
Map<Long, Integer> sessions) throws IOException {
// session information
int count = ia.readInt("count");
while (count > 0) {
long id = ia.readLong("id");
int to = ia.readInt("timeout");
sessions.put(id, to);
if (LOG.isTraceEnabled()) {
ZooTrace.logTraceMessage(LOG, ZooTrace.SESSION_TRACE_MASK,
"loadData --- session in archive: " + id
+ " with timeout: " + to);
}
count--;
}
// The node information is finally handed over to the DataTree for deserialization
dt.deserialize(ia, "tree");
}
}
When analyzing snapshot log generation in the previous article, we saw how to serialize the information of DataTree to disk file. At this time, when the Zookeeper server is started, the file is deserialized into the DataTree. The deserialization process is not complicated, and readers can read it by themselves.
Show the whole process through a sequence diagram:
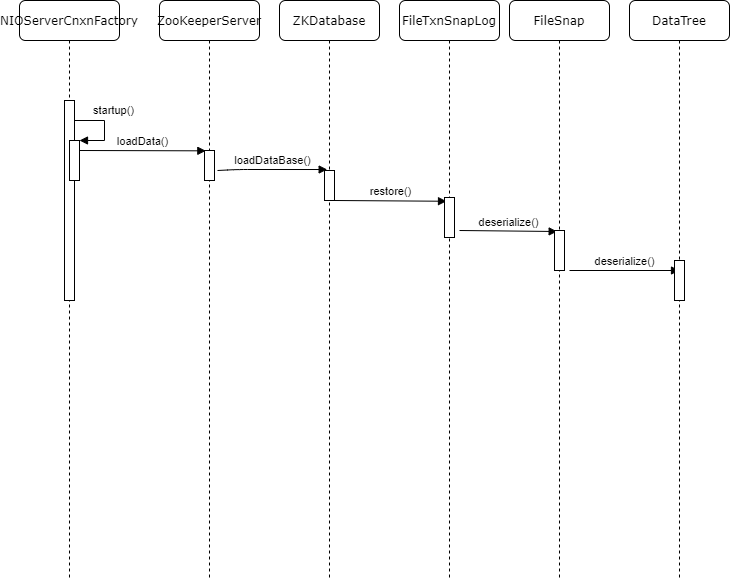
3. Operation on DataTree during transaction request
In 2, we analyzed the loading of the snapshot log when the Zookeeper server starts to load the node data into memory. Each time a client request is received, the node information saved in the DataTree will actually be changed. Let's analyze an example to show the change process of DataTree.
DataTree provides a series of node operation methods. Here, we only analyze the createNode() method.
3.1 FinalRequestProcessor.processRequest()
As analyzed before, the request will go through three requestprocessors, and the FinalRequestProcessor analyzed here is the last one
public class FinalRequestProcessor implements RequestProcessor {
ZooKeeperServer zks;
public void processRequest(Request request) {
...
ProcessTxnResult rc = null;
synchronized (zks.outstandingChanges) {
...
if (request.hdr != null) {
TxnHeader hdr = request.hdr;
Record txn = request.txn;
// Execute the processTxn() method
rc = zks.processTxn(hdr, txn);
}
}
...
}3.2 ZooKeeperServer.processTxn()
public class ZooKeeperServer implements SessionExpirer, ServerStats.Provider {
public ProcessTxnResult processTxn(TxnHeader hdr, Record txn) {
ProcessTxnResult rc;
int opCode = hdr.getType();
long sessionId = hdr.getClientId();
// Perform the operation of ZKDatabase
rc = getZKDatabase().processTxn(hdr, txn);
...
return rc;
}
}3.3 ZKDatabase.processTxn()
public class ZKDatabase {
public ProcessTxnResult processTxn(TxnHeader hdr, Record txn) {
// The operation is still DataTree
return dataTree.processTxn(hdr, txn);
}
}3.4 DataTree.processTxn()
public class DataTree {
public ProcessTxnResult processTxn(TxnHeader header, Record txn){
ProcessTxnResult rc = new ProcessTxnResult();
try {
rc.clientId = header.getClientId();
rc.cxid = header.getCxid();
rc.zxid = header.getZxid();
rc.type = header.getType();
rc.err = 0;
rc.multiResult = null;
switch (header.getType()) {
case OpCode.create:
CreateTxn createTxn = (CreateTxn) txn;
rc.path = createTxn.getPath();
// Create requests create nodes directly
createNode(
createTxn.getPath(),
createTxn.getData(),
createTxn.getAcl(),
createTxn.getEphemeral() ? header.getClientId() : 0,
createTxn.getParentCVersion(),
header.getZxid(), header.getTime());
break;
...
}
}
}
public String createNode(String path, byte data[], List<ACL> acl,
long ephemeralOwner, int parentCVersion, long zxid, long time)
throws KeeperException.NoNodeException,
KeeperException.NodeExistsException {
int lastSlash = path.lastIndexOf('/');
String parentName = path.substring(0, lastSlash);
String childName = path.substring(lastSlash + 1);
// Create node stat information
StatPersisted stat = new StatPersisted();
stat.setCtime(time);
stat.setMtime(time);
stat.setCzxid(zxid);
stat.setMzxid(zxid);
stat.setPzxid(zxid);
stat.setVersion(0);
stat.setAversion(0);
stat.setEphemeralOwner(ephemeralOwner);
DataNode parent = nodes.get(parentName);
if (parent == null) {
throw new KeeperException.NoNodeException();
}
synchronized (parent) {
Set<String> children = parent.getChildren();
if (children.contains(childName)) {
throw new KeeperException.NodeExistsException();
}
if (parentCVersion == -1) {
parentCVersion = parent.stat.getCversion();
parentCVersion++;
}
parent.stat.setCversion(parentCVersion);
parent.stat.setPzxid(zxid);
Long longval = aclCache.convertAcls(acl);
// Create node information and add it to nodes
DataNode child = new DataNode(parent, data, longval, stat);
parent.addChild(childName);
nodes.put(path, child);
if (ephemeralOwner != 0) {
HashSet<String> list = ephemerals.get(ephemeralOwner);
if (list == null) {
list = new HashSet<String>();
ephemerals.put(ephemeralOwner, list);
}
synchronized (list) {
list.add(path);
}
}
}
...
}
}Summary: for the client's request to create a node, the server will generate a DataNode, add it to nodes, and modify the basic information of its parentNode. The code is not complicated. The author uses a sequence diagram to show this process.
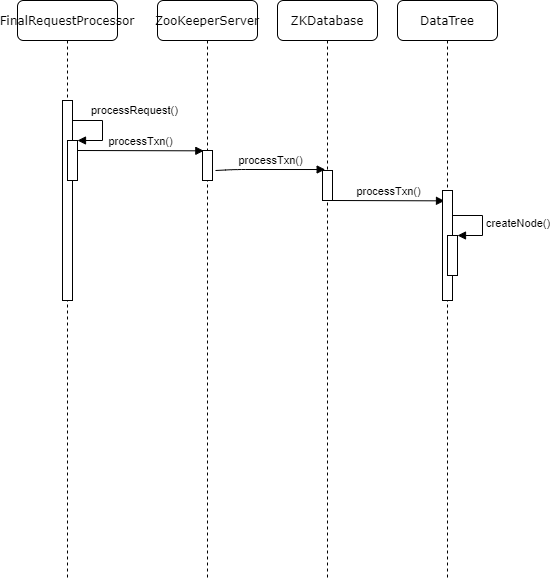
4. Serialize node information to snapshot file
The previous article mentioned the generation of snapshot files. See the view and analysis of snapshot logs for details.
Summary: as Zookeeper's in memory database, it provides a series of API s to support node operations. By cooperating with snapshot log, Zookeeper can quickly respond to client query requests.