1, Stacked RNN
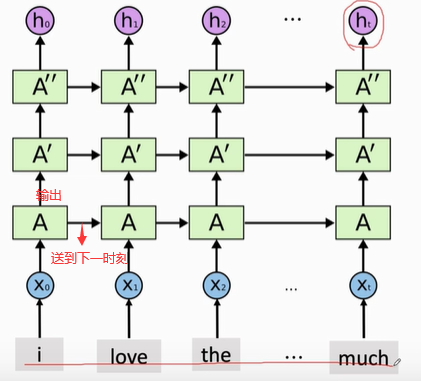
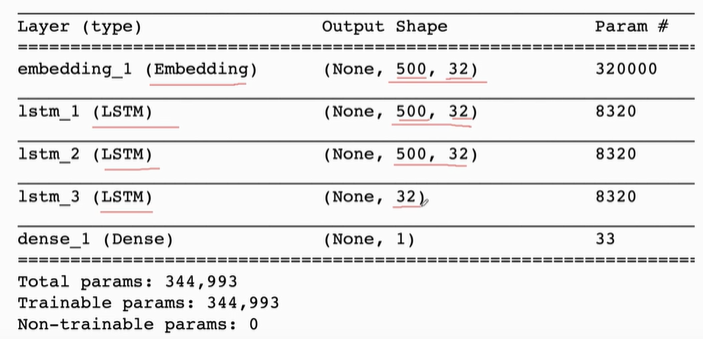
from keras.models import Sequential from keras.layers import LSTM,Embedding,Dense # Set super parameters vocabulary = 10000 # There are 10000 words in the dictionary embedding_dim=32 # shape(x)=32, and the dimension of word vector x is 32 word_num = 500 # Each film review has 500 words. If it exceeds 500 words, it will be cut off; If it's less than 500, it'll be enough. state_dim =32 # shape(h) = 32, the dimension of state vector h is 32 # Start building the network model = Sequential() # Establish Sequential() model # Add layers to the model and Embedding layers to map words into vectors model.add(Embedding(vocabulary,embedding_dim,input_length=word_num)) # You need to specify the dimension of the state vector h and set the return of the RNN layer_ Sequences = false, which means that RNN only outputs the last state vector h and rounds off the previous state vector model.add(LSTM(state_dim,return_sequences=True,dropout=0.2)) model.add(LSTM(state_dim,return_sequences=True,dropout=0.2)) model.add(LSTM(state_dim,return_sequences=False,dropout=0.2)) # Full connection layer, input the last state h of RNN and output the number between 0-1 model.add(Dense(1, activation="sigmoid")) model.summary()
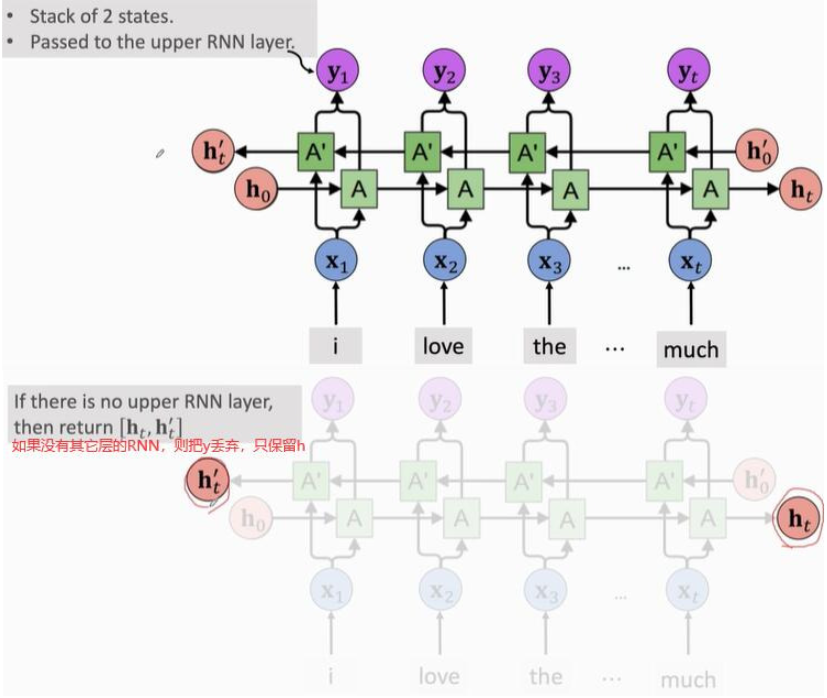
2, Bidirectional RNN
- Train two RNN s, one from left to right and the other from right to left.
- The two RNN s are independent and do not share parameters or states
- Two RNN s output their own state vectors respectively, and then merge their state vectors as vector y.
from keras.models import Sequential from keras.layers import LSTM,Embedding,Dense,Bidirectional # Set super parameters vocabulary = 10000 # There are 10000 words in the dictionary embedding_dim=32 # shape(x)=32, and the dimension of word vector x is 32 word_num = 500 # Each film review has 500 words. If it exceeds 500 words, it will be cut off; If it's less than 500, it'll be enough. state_dim =32 # shape(h) = 32, the dimension of state vector h is 32 # Start building the network model = Sequential() # Establish Sequential() model # Add layers to the model and Embedding layers to map words into vectors model.add(Embedding(vocabulary,embedding_dim,input_length=word_num)) # You need to specify the dimension of the state vector h and set the return of the RNN layer_ Sequences = false, keep the last state of the two chains and round off the previous state vector model.add(Bidirectional(LSTM(state_dim,return_sequences=False,dropout=0.2))) # Full connection layer, input the last state h of RNN and output the number between 0-1 model.add(Dense(1, activation="sigmoid")) model.summary()

3, Pretrain (pre training)
Pre training is very common in deep learning: for example, when training convolutional neural network, if the network is too large and the training set is not large enough, pre training can be done on big data first, which can make the neural network have better initialization and avoid over fitting.
Observation: The embedding layer contributes most of the parameters!
There are 320000 parameters, but we only have 20000 training samples. This embedding layer is too large, resulting in over fitting of the model.
Solution: pre train the embedding layer.

3.1 Pretrain the Embedding Layer
The first step is to find a larger data set, which can be emotional analysis data or other types of data, but the task is better to be close to the task of emotional analysis. It is better to learn the word vector with positive or negative emotions. The more similar the two tasks are, the better the transformer after pre training will be, After having a large data set, build a neural network. The structure of the neural network can be whatever (RNN can not be used, as long as the neural network has embedded layer), and then train the neural network on the large data set.
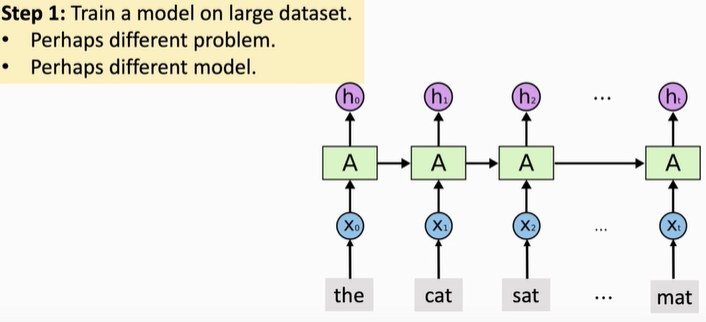
Step 2: after the training, discard all the upper layers and only retain the embedded layer and the trained model parameters.
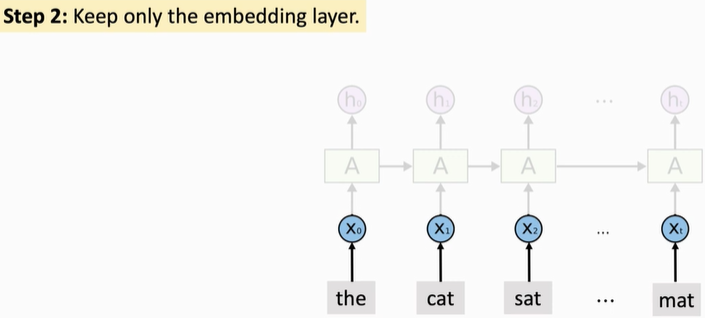
The third step is to build your own RNN network. This new RNN network can have a different structure from the previous pre training. After construction, the new RNN layer and the full connection layer are initialized randomly, and the parameters of the Embedding Layer are pre trained. Fix the parameters of the Embedding Layer. Do not train this Embedding Layer, but only train other layers.
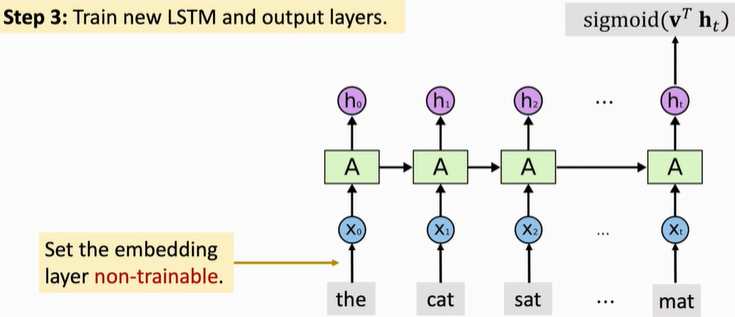
4, Summary
- SimpleRNN and LSTM are two kinds of RNNs; always use LSTM instead of SimpleRNN.
- Use Bi-RNN instead of RNN whenever possible.
- Stacked RNN may be better than a single RNN layer (if n is big).
- Pretrain the embedding layer (if n is small). If the training data is small, pre train on the large data set