If DBoW3 is not installed, the following error will be reported when compiling directly:
fatal error: DBoW3/DBoW3.h: No such file or directory
#include "DBoW3/DBoW3.h"
^~~~~~~~~~~~~~~
compilation terminated.
CMakeFiles/gen_vocab.dir/build.make:82: recipe for target 'CMakeFiles/gen_vocab.dir/gen_vocab_large.cpp.o' failed
make[2]: *** [CMakeFiles/gen_vocab.dir/gen_vocab_large.cpp.o] Error 1
CMakeFiles/Makefile2:99: recipe for target 'CMakeFiles/gen_vocab.dir/all' failed
make[1]: *** [CMakeFiles/gen_vocab.dir/all] Error 2
Makefile:103: recipe for target 'all' failed
make: *** [all] Error 2
Before compiling the program, you need to install DBoW. The download link of the second version of the installation file is as follows:
https://github.com/rmsalinas/DBow3 https://github.com/rmsalinas/DBow3 After downloading, the installation method is very simple. Store the files in the folder you want to store and enter the dbow master folder:
https://github.com/rmsalinas/DBow3 After downloading, the installation method is very simple. Store the files in the folder you want to store and enter the dbow master folder:
mkdir build
cd build
cmake ..
make -j4
sudo make install
When compiling CH11, the following error occurred:
make[2]: *** No rule to make target '/usr/local/lib/libDBoW3.a', needed by 'loop_closure'. Stop. make[1]: *** [CMakeFiles/Makefile2:80: CMakeFiles/loop_closure.dir/all] Error 2 make: *** [Makefile:84: all] Error 2
The problem is that libdbow3.0 was not found A this file, so I used dbow3 in / home/liqiang/slambook/3rdparty in the first version tar. GZ. The download link is as follows:
The installation method is the same as above.
feature_training.cpp
#include "DBoW3/DBoW3.h" / / word bag support header file
#include <opencv2/core/core. HPP > / / opencv core module
#include <opencv2/highgui/highgui. HPP > / / GUI module
#include <opencv2/features2d/features2d. HPP > / / feature file
#include <iostream>
#include <vector>
#include <string>
using namespace cv;
using namespace std;
/***************************************************
* This section demonstrates how to train a dictionary according to ten figures in the data / directory
* ************************************************/
int main( int argc, char** argv )
{
// read the image
cout<<"reading images... "<<endl;//Outputting reading images
vector<Mat> images; //image
for ( int i=0; i<10; i++ )//Traverse and read ten images
{
string path = "./data/"+to_string(i+1)+".png";
images.push_back( imread(path) );
}
// detect ORB features
cout<<"detecting ORB features ... "<<endl;//Output detecting ORB features
Ptr< Feature2D > detector = ORB::create();
vector<Mat> descriptors;//descriptor
for ( Mat& image:images )
{
vector<KeyPoint> keypoints; //Key points
Mat descriptor;//descriptor
detector->detectAndCompute( image, Mat(), keypoints, descriptor );//Detection and calculation
descriptors.push_back( descriptor );
}
// Create dictionary
cout<<"creating vocabulary ... "<<endl;//Output (creating vocabulary...) Create dictionary
DBoW3::Vocabulary vocab;//Default constructor k=10,d=5
vocab.create( descriptors );
cout<<"vocabulary info: "<<vocab<<endl;//Dictionary information
vocab.save( "vocabulary.yml.gz" );//Save dictionary package
cout<<"done"<<endl;//Output done
return 0;
}
CMakeLists.txt
cmake_minimum_required( VERSION 2.8 )
project( loop_closure )
set( CMAKE_BUILD_TYPE "Release" )
set( CMAKE_CXX_FLAGS "-std=c++14 -O3" )
# opencv
find_package( OpenCV 3.1 REQUIRED )
include_directories( ${OpenCV_INCLUDE_DIRS} )
# dbow3
# dbow3 is a simple lib so I assume you installed it in default directory
set( DBoW3_INCLUDE_DIRS "/usr/local/include" )
set( DBoW3_LIBS "/usr/local/lib/libDBoW3.a" )
add_executable( feature_training feature_training.cpp )
target_link_libraries( feature_training ${OpenCV_LIBS} ${DBoW3_LIBS} )
add_executable( loop_closure loop_closure.cpp )
target_link_libraries( loop_closure ${OpenCV_LIBS} ${DBoW3_LIBS} )
add_executable( gen_vocab gen_vocab_large.cpp )
target_link_libraries( gen_vocab ${OpenCV_LIBS} ${DBoW3_LIBS} )Execution results:
./feature_training ../data/
reading images... detecting ORB features ... creating vocabulary ... vocabulary info: Vocabulary: k = 10, L = 5, Weighting = tf-idf, Scoring = L1-norm, Number of words = 0 done
Number of words = 0 appears here, which is obviously wrong. Through the inspection program, there is a small problem in reading the data path in the data folder. Modify:

Add one more in the path That's it.
The execution results after modifying the program are as follows:
reading images... detecting ORB features ... creating vocabulary ... vocabulary info: Vocabulary: k = 10, L = 5, Weighting = tf-idf, Scoring = L1-norm, Number of words = 4981 done
Where weight is the weight and Scoring is the score.
loop_closure.cpp
#include "DBoW3/DBoW3.h" / / word bag support header file
#include <opencv2/core/core. HPP > / / opencv core module
#include <opencv2/highgui/highgui. HPP > / / GUI module
#include <opencv2/features2d/features2d. HPP > / / feature file
#include <iostream>
#include <vector>
#include <string>
using namespace cv;
using namespace std;
/***************************************************
* This section demonstrates how to calculate the similarity score based on the previously trained dictionary
* ************************************************/
int main(int argc, char **argv) {
// Read the images and database
cout << "reading database" << endl;//Outputting Reading database
DBoW3::Vocabulary vocab("../vocabulary.yml.gz");//vocabulary.yml.gz path
// DBoW3::Vocabulary vocab("./vocab_larger.yml.gz"); // use large vocab if you want:
if (vocab.empty()) {
cerr << "Vocabulary does not exist." << endl;//Output volatile does not exist
return 1;
}
cout << "reading images... " << endl;//Outputting reading images
vector<Mat> images;
for (int i = 0; i < 10; i++) {
string path = "../data/" + to_string(i + 1) + ".png";//Image reading path
images.push_back(imread(path));
}
// NOTE: in this case we are comparing images with a vocabulary generated by themselves, this may lead to overfit. Here we use the dictionaries they generate to compare their own similarities, which may produce over fitting
// detect ORB features
cout << "detecting ORB features ... " << endl;//Outputting detecting ORB features (testing ORB characteristics)
Ptr<Feature2D> detector = ORB::create();//The default image has 500 feature points
vector<Mat> descriptors;//The descriptor extracts ORB features from 10 images and stores them in the vector container
for (Mat &image:images) {
vector<KeyPoint> keypoints;//Key points
Mat descriptor;//descriptor
detector->detectAndCompute(image, Mat(), keypoints, descriptor);//Detection and calculation
descriptors.push_back(descriptor);
}
// we can compare the images directly or we can compare one image to a database
// images :
cout << "comparing images with images " << endl;//Outputting comparing images with images
for (int i = 0; i < images.size(); i++)
{
DBoW3::BowVector v1;
//descriptors[i] represents all the sub sets of ORB descriptions in image I. the function transform() calculates the word vector described by the previous dictionary. The value of the element in each vector is either 0, indicating that there is no word in image I; Or the weight of the word
//The BoW description vector contains the ID and weight of each word, which constitute the whole sparse vector
//When comparing two vectors, DBoW3 calculates a score for us
vocab.transform(descriptors[i], v1);
for (int j = i; j < images.size(); j++)
{
DBoW3::BowVector v2;
vocab.transform(descriptors[j], v2);
double score = vocab.score(v1, v2);//p296 formula (11.9)
cout << "image " << i << " vs image " << j << " : " << score << endl;//Output the similarity score between one image and another image
}
cout << endl;
}
// or with database
//During database query, DBoW sorts the above scores and gives the most similar results
cout << "comparing images with database " << endl;
DBoW3::Database db(vocab, false, 0);
for (int i = 0; i < descriptors.size(); i++)
db.add(descriptors[i]);
cout << "database info: " << db << endl;//Output database info as
for (int i = 0; i < descriptors.size(); i++)
{
DBoW3::QueryResults ret;
db.query(descriptors[i], ret, 4); // max result=4
cout << "searching for image " << i << " returns " << ret << endl << endl;
}
cout << "done." << endl;
}CMakeLists.txt
Same as above.
Execution results:
At Ubuntu 20 04 when executing:
reading database reading images... detecting ORB features ... comparing images with images image 0 vs image 0 : 1 image 0 vs image 1 : 0.0322942 image 0 vs image 2 : 0.0348326 image 0 vs image 3 : 0.0292106 image 0 vs image 4 : 0.0307606 image 0 vs image 5 : 0.0386504 image 0 vs image 6 : 0.0267389 image 0 vs image 7 : 0.0254779 image 0 vs image 8 : 0.041301 image 0 vs image 9 : 0.0501515 image 1 vs image 1 : 1 image 1 vs image 2 : 0.041587 image 1 vs image 3 : 0.034046 image 1 vs image 4 : 0.0318553 image 1 vs image 5 : 0.0354084 image 1 vs image 6 : 0.0221539 image 1 vs image 7 : 0.0296462 image 1 vs image 8 : 0.0397894 image 1 vs image 9 : 0.0306703 image 2 vs image 2 : 1 image 2 vs image 3 : 0.0322172 image 2 vs image 4 : 0.0371113 image 2 vs image 5 : 0.0338423 image 2 vs image 6 : 0.0360772 image 2 vs image 7 : 0.044198 image 2 vs image 8 : 0.0354693 image 2 vs image 9 : 0.0351865 image 3 vs image 3 : 1 image 3 vs image 4 : 0.0278296 image 3 vs image 5 : 0.0338019 image 3 vs image 6 : 0.0349277 image 3 vs image 7 : 0.0294855 image 3 vs image 8 : 0.0299692 image 3 vs image 9 : 0.0469051 image 4 vs image 4 : 1 image 4 vs image 5 : 0.0630388 image 4 vs image 6 : 0.0355424 image 4 vs image 7 : 0.0294301 image 4 vs image 8 : 0.0295447 image 4 vs image 9 : 0.026492 image 5 vs image 5 : 1 image 5 vs image 6 : 0.0365682 image 5 vs image 7 : 0.0275375 image 5 vs image 8 : 0.0309867 image 5 vs image 9 : 0.0337013 image 6 vs image 6 : 1 image 6 vs image 7 : 0.0297398 image 6 vs image 8 : 0.0345615 image 6 vs image 9 : 0.0337139 image 7 vs image 7 : 1 image 7 vs image 8 : 0.0182667 image 7 vs image 9 : 0.0225071 image 8 vs image 8 : 1 image 8 vs image 9 : 0.0432488 image 9 vs image 9 : 1
The following error message appears. I don't know why. I changed a computer, Ubuntu 18 04 is OK. It's the same code (I haven't figured it out yet)
comparing images with database terminate called after throwing an instance of 'std::length_error' what(): cannot create std::vector larger than max_size() Aborted (core dumped)
Here is Ubuntu 18 Results from 04:
./loop_closure
reading database reading images... detecting ORB features ... comparing images with images image 0 vs image 0 : 1 image 0 vs image 1 : 0.0322942 image 0 vs image 2 : 0.0348326 image 0 vs image 3 : 0.0292106 image 0 vs image 4 : 0.0307606 image 0 vs image 5 : 0.0386504 image 0 vs image 6 : 0.0267389 image 0 vs image 7 : 0.0254779 image 0 vs image 8 : 0.041301 image 0 vs image 9 : 0.0501515 image 1 vs image 1 : 1 image 1 vs image 2 : 0.041587 image 1 vs image 3 : 0.034046 image 1 vs image 4 : 0.0318553 image 1 vs image 5 : 0.0354084 image 1 vs image 6 : 0.0221539 image 1 vs image 7 : 0.0296462 image 1 vs image 8 : 0.0397894 image 1 vs image 9 : 0.0306703 image 2 vs image 2 : 1 image 2 vs image 3 : 0.0322172 image 2 vs image 4 : 0.0371113 image 2 vs image 5 : 0.0338423 image 2 vs image 6 : 0.0360772 image 2 vs image 7 : 0.044198 image 2 vs image 8 : 0.0354693 image 2 vs image 9 : 0.0351865 image 3 vs image 3 : 1 image 3 vs image 4 : 0.0278296 image 3 vs image 5 : 0.0338019 image 3 vs image 6 : 0.0349277 image 3 vs image 7 : 0.0294855 image 3 vs image 8 : 0.0299692 image 3 vs image 9 : 0.0469051 image 4 vs image 4 : 1 image 4 vs image 5 : 0.0630388 image 4 vs image 6 : 0.0355424 image 4 vs image 7 : 0.0294301 image 4 vs image 8 : 0.0295447 image 4 vs image 9 : 0.026492 image 5 vs image 5 : 1 image 5 vs image 6 : 0.0365682 image 5 vs image 7 : 0.0275375 image 5 vs image 8 : 0.0309867 image 5 vs image 9 : 0.0337013 image 6 vs image 6 : 1 image 6 vs image 7 : 0.0297398 image 6 vs image 8 : 0.0345615 image 6 vs image 9 : 0.0337139 image 7 vs image 7 : 1 image 7 vs image 8 : 0.0182667 image 7 vs image 9 : 0.0225071 image 8 vs image 8 : 1 image 8 vs image 9 : 0.0432488 image 9 vs image 9 : 1 comparing images with database database info: Database: Entries = 10, Using direct index = no. Vocabulary: k = 10, L = 5, Weighting = tf-idf, Scoring = L1-norm, Number of words = 4983 searching for image 0 returns 4 results: <EntryId: 0, Score: 1> <EntryId: 9, Score: 0.0501515> <EntryId: 8, Score: 0.041301> <EntryId: 5, Score: 0.0386504> searching for image 1 returns 4 results: <EntryId: 1, Score: 1> <EntryId: 2, Score: 0.041587> <EntryId: 8, Score: 0.0397894> <EntryId: 5, Score: 0.0354084> searching for image 2 returns 4 results: <EntryId: 2, Score: 1> <EntryId: 7, Score: 0.044198> <EntryId: 1, Score: 0.041587> <EntryId: 4, Score: 0.0371113> searching for image 3 returns 4 results: <EntryId: 3, Score: 1> <EntryId: 9, Score: 0.0469051> <EntryId: 6, Score: 0.0349277> <EntryId: 1, Score: 0.034046> searching for image 4 returns 4 results: <EntryId: 4, Score: 1> <EntryId: 5, Score: 0.0630388> <EntryId: 2, Score: 0.0371113> <EntryId: 6, Score: 0.0355424> searching for image 5 returns 4 results: <EntryId: 5, Score: 1> <EntryId: 4, Score: 0.0630388> <EntryId: 0, Score: 0.0386504> <EntryId: 6, Score: 0.0365682> searching for image 6 returns 4 results: <EntryId: 6, Score: 1> <EntryId: 5, Score: 0.0365682> <EntryId: 2, Score: 0.0360772> <EntryId: 4, Score: 0.0355424> searching for image 7 returns 4 results: <EntryId: 7, Score: 1> <EntryId: 2, Score: 0.044198> <EntryId: 6, Score: 0.0297398> <EntryId: 1, Score: 0.0296462> searching for image 8 returns 4 results: <EntryId: 8, Score: 1> <EntryId: 9, Score: 0.0432488> <EntryId: 0, Score: 0.041301> <EntryId: 1, Score: 0.0397894> searching for image 9 returns 4 results: <EntryId: 9, Score: 1> <EntryId: 0, Score: 0.0501515> <EntryId: 3, Score: 0.0469051> <EntryId: 8, Score: 0.0432488> done.
gen_vocab_large.cpp
When the code in the book is executed, the following errors will be reported. The txt file described in the code is not under the folder. It is not clear where there is a problem.

terminate called after throwing an instance of 'std::logic_error' what(): basic_string::_M_construct null not valid Aborted (core dumped)
Make a little change to the code:
#include "DBoW3/DBoW3.h" / / word bag support header file
#include <opencv2/core/core. HPP > / / opencv core module
#include <opencv2/highgui/highgui. HPP > / / GUI module
#include <opencv2/features2d/features2d. HPP > / / feature file
#include <iostream>
#include <vector>
#include <string>
using namespace cv;
using namespace std;
int main( int argc, char** argv )
{
String directoryPath = "/home/liqiang/slambook2/ch11/rgbd_dataset_freiburg1_desk2/rgb";//Image path
vector<String> imagesPath;
glob(directoryPath, imagesPath);
// string dataset_dir = argv[1];
// ifstream fin ( dataset_dir+"/home/liqiang/slambook2/ch11/rgbd_dataset_freiburg1_desk2/rgb" );
// if ( !fin )
// {
// cout<<"please generate the associate file called associate.txt!"<<endl;
// return 1;
// }
// vector<string> rgb_files, depth_files;
// vector<double> rgb_times, depth_times;
// while ( !fin.eof() )
// {
// string rgb_time, rgb_file, depth_time, depth_file;
// fin>>rgb_time>>rgb_file>>depth_time>>depth_file;
// rgb_times.push_back ( atof ( rgb_time.c_str() ) );
// depth_times.push_back ( atof ( depth_time.c_str() ) );
// rgb_files.push_back ( dataset_dir+"/"+rgb_file );
// depth_files.push_back ( dataset_dir+"/"+depth_file );
// if ( fin.good() == false )
// break;
// }
// fin.close();
cout<<"generating features ... "<<endl;//Output generating features
vector<Mat> descriptors;//descriptor
Ptr< Feature2D > detector = ORB::create();
int index = 1;
for ( String path : imagesPath )
{
Mat image = imread(path);
vector<KeyPoint> keypoints; //Key points
Mat descriptor;//descriptor
detector->detectAndCompute( image, Mat(), keypoints, descriptor );
descriptors.push_back( descriptor );
cout<<"extracting features from image " << index++ <<endl;//Outputting extracting features from image
}
cout<<"extract total "<<descriptors.size()*500<<" features."<<endl;
// create vocabulary
cout<<"creating vocabulary, please wait ... "<<endl;//Output creating dictionary, please wait
DBoW3::Vocabulary vocab;
vocab.create( descriptors );
cout<<"vocabulary info: "<<vocab<<endl;
vocab.save( "vocab_larger.yml.gz" );//Save dictionary
cout<<"done"<<endl;
return 0;
}
The data set needs to be downloaded from the image path, and the download address is as follows:
Computer Vision Group - Dataset Download

CMakeLists.txt
Same as above.
Execution results:
./gen_vocab generating features ... extracting features from image 1 extracting features from image 2 extracting features from image 3 extracting features from image 4 extracting features from image 5 extracting features from image 6 extracting features from image 7 extracting features from image 8 extracting features from image 9 extracting features from image 10 ..... extracting features from image 634 extracting features from image 635 extracting features from image 636 extracting features from image 637 extracting features from image 638 extracting features from image 639 extracting features from image 640 extract total 320000 features. creating vocabulary, please wait ... vocabulary info: Vocabulary: k = 10, L = 5, Weighting = tf-idf, Scoring = L1-norm, Number of words = 89315 done
After execution, a vocab will be generated under the build folder_ larger. yml. GZ, and then you can use this dictionary to execute loop_closure.cpp, just add loop_ closure. It's ok to modify the dictionary in CPP.
Execute loop again_ closure. CPP, the execution results are as follows:
reading database reading images... detecting ORB features ... comparing images with images image 0 vs image 0 : 1 image 0 vs image 1 : 0.00401522 image 0 vs image 2 : 0.00575911 image 0 vs image 3 : 0.0057625 image 0 vs image 4 : 0.00516026 image 0 vs image 5 : 0.00289918 image 0 vs image 6 : 0.00280098 image 0 vs image 7 : 0.00329088 image 0 vs image 8 : 0.00869696 image 0 vs image 9 : 0.0304572 image 1 vs image 1 : 1 image 1 vs image 2 : 0.0241793 image 1 vs image 3 : 0.00553848 image 1 vs image 4 : 0.00522892 image 1 vs image 5 : 0.00702649 image 1 vs image 6 : 0.00331991 image 1 vs image 7 : 0.0035423 image 1 vs image 8 : 0.00950168 image 1 vs image 9 : 0.00598861 image 2 vs image 2 : 1 image 2 vs image 3 : 0.00634031 image 2 vs image 4 : 0.00541992 image 2 vs image 5 : 0.0149133 image 2 vs image 6 : 0.00789202 image 2 vs image 7 : 0.00498983 image 2 vs image 8 : 0.00329779 image 2 vs image 9 : 0.00490939 image 3 vs image 3 : 1 image 3 vs image 4 : 0.00195016 image 3 vs image 5 : 0.0150889 image 3 vs image 6 : 0.0073025 image 3 vs image 7 : 0.00476159 image 3 vs image 8 : 0.0110854 image 3 vs image 9 : 0.00516915 image 4 vs image 4 : 1 image 4 vs image 5 : 0.0105219 image 4 vs image 6 : 0.00596558 image 4 vs image 7 : 0.00467202 image 4 vs image 8 : -0 image 4 vs image 9 : 0.00676682 image 5 vs image 5 : 1 image 5 vs image 6 : 0.0015908 image 5 vs image 7 : 0.00508986 image 5 vs image 8 : 0.00442575 image 5 vs image 9 : 0.00177321 image 6 vs image 6 : 1 image 6 vs image 7 : 0.00579406 image 6 vs image 8 : 0.0069873 image 6 vs image 9 : 0.00166793 image 7 vs image 7 : 1 image 7 vs image 8 : 0.00720273 image 7 vs image 9 : 0.00174475 image 8 vs image 8 : 1 image 8 vs image 9 : 0.00937256 image 9 vs image 9 : 1 comparing images with database database info: Database: Entries = 10, Using direct index = no. Vocabulary: k = 10, L = 5, Weighting = tf-idf, Scoring = L1-norm, Number of words = 99566 searching for image 0 returns 4 results: <EntryId: 0, Score: 1> <EntryId: 9, Score: 0.0304572> <EntryId: 8, Score: 0.00869696> <EntryId: 3, Score: 0.0057625> searching for image 1 returns 4 results: <EntryId: 1, Score: 1> <EntryId: 2, Score: 0.0241793> <EntryId: 8, Score: 0.00950168> <EntryId: 5, Score: 0.00702649> searching for image 2 returns 4 results: <EntryId: 2, Score: 1> <EntryId: 1, Score: 0.0241793> <EntryId: 5, Score: 0.0149133> <EntryId: 6, Score: 0.00789202> searching for image 3 returns 4 results: <EntryId: 3, Score: 1> <EntryId: 5, Score: 0.0150889> <EntryId: 8, Score: 0.0110854> <EntryId: 6, Score: 0.0073025> searching for image 4 returns 4 results: <EntryId: 4, Score: 1> <EntryId: 5, Score: 0.0105219> <EntryId: 9, Score: 0.00676682> <EntryId: 6, Score: 0.00596558> searching for image 5 returns 4 results: <EntryId: 5, Score: 1> <EntryId: 3, Score: 0.0150889> <EntryId: 2, Score: 0.0149133> <EntryId: 4, Score: 0.0105219> searching for image 6 returns 4 results: <EntryId: 6, Score: 1> <EntryId: 2, Score: 0.00789202> <EntryId: 3, Score: 0.0073025> <EntryId: 8, Score: 0.0069873> searching for image 7 returns 4 results: <EntryId: 7, Score: 1> <EntryId: 8, Score: 0.00720273> <EntryId: 6, Score: 0.00579406> <EntryId: 5, Score: 0.00508986> searching for image 8 returns 4 results: <EntryId: 8, Score: 1> <EntryId: 3, Score: 0.0110854> <EntryId: 1, Score: 0.00950168> <EntryId: 9, Score: 0.00937256> searching for image 9 returns 4 results: <EntryId: 9, Score: 1> <EntryId: 0, Score: 0.0304572> <EntryId: 8, Score: 0.00937256> <EntryId: 4, Score: 0.00676682> done.
After class exercises
1. Please write a small program to calculate PR curve. It may be easier to use MATLAB or Python because they are good at drawing.
Before testing, you need to install scikit learn and matplotlib:
To install scikit learn: Installing scikit-learn — scikit-learn 1.0.1 documentation
pip3 install -U scikit-learn
matplotlib:
pip install matplotlib
The following code is reproduced in: Three minutes will take you to understand roc curve and PR curve_ Guo_Python blog - CSDN blog_ roc curve and PR curve
pr.py:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve,roc_curve
def draw_pr(confidence_scores, data_labels):
plt.figure()
plt.title('PR Curve')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.grid()
#Accuracy, recall, threshold
precision,recall,thresholds = precision_recall_curve(data_labels,confidence_scores)
from sklearn.metrics import average_precision_score
AP = average_precision_score(data_labels, confidence_scores) # Calculate AP
plt.plot(recall, precision, label = 'pr_curve(AP=%0.2f)' % AP)
plt.legend()
plt.show()
def draw_roc(confidence_scores, data_labels):
#True rate
fpr, tpr, thresholds = roc_curve(data_labels, confidence_scores)
plt.figure()
plt.grid()
plt.title('Roc Curve')
plt.xlabel('FPR')
plt.ylabel('TPR')
from sklearn.metrics import auc
auc=auc(fpr, tpr) #AUC calculation
plt.plot(fpr,tpr,label = 'roc_curve(AUC=%0.2f)' % auc)
plt.legend()
plt.show()
if __name__ == '__main__':
# The confidence of positive samples, that is, the probability that the model is identified as 1
confidence_scores = np.array([0.9, 0.78, 0.6, 0.46, 0.4, 0.37, 0.2, 0.16])
# Real label
data_labels = np.array([1,1,0,1,0,0,1,1])
draw_pr(confidence_scores, data_labels)
draw_roc(confidence_scores, data_labels)
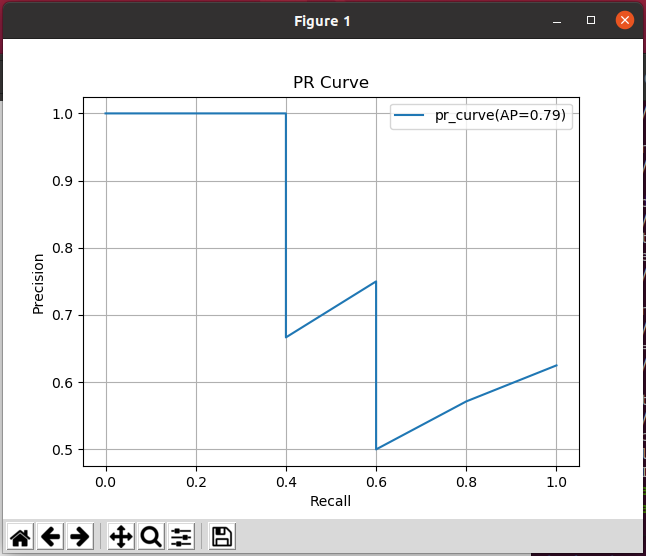
When running under Ubuntu, I put the python file under the ch11 folder:
python pr.py
Execution results:
Reproduced at:
Roc curve and pr curve understanding and simple code implementation_ JMU-HZH blog - CSDN blog_ Realization of pr curve
pr1.py:
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve,roc_curve
plt.figure()
plt.title('PR Curve')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.grid()
#Just understand the meaning of the two curves, so the data is simple to construct
confidence_scores = np.array([0.9,0.46,0.78,0.37,0.6,0.4,0.2,0.16])
confidence_scores=sorted(confidence_scores,reverse=True)#Confidence ranking from large to small
print(confidence_scores)
data_labels = np.array([1,1,0,1,0,0 ,1,1])#Label corresponding to confidence
#Accuracy, recall, threshold
precision,recall,thresholds = precision_recall_curve(data_labels,confidence_scores)
print(precision)
print(recall)
print(thresholds)
plt.plot(recall,precision)
plt.show()
#True rate
fpr, tpr, thresholds = roc_curve(data_labels, confidence_scores)
#print(fpr)
#print(tpr)
plt.figure()
plt.grid()
plt.title('Roc Curve')
plt.xlabel('FPR')
plt.ylabel('TPR')
from sklearn.metrics import auc
auc=auc(fpr, tpr)#AUC calculation
plt.plot(fpr,tpr,label='roc_curve(AUC=%0.2f)'%auc)
plt.legend()
plt.show()
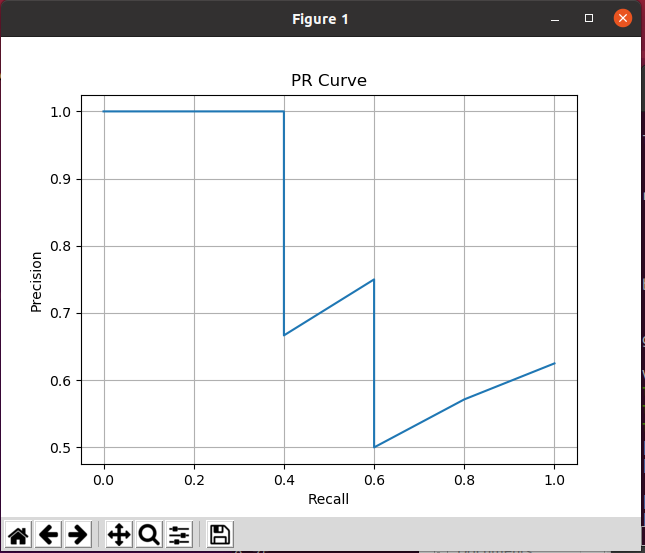
Execution results:
python pr1.py
[0.9, 0.78, 0.6, 0.46, 0.4, 0.37, 0.2, 0.16] [0.625 0.57142857 0.5 0.6 0.75 0.66666667 1. 1. 1. ] [1. 0.8 0.6 0.6 0.6 0.4 0.4 0.2 0. ] [0.16 0.2 0.37 0.4 0.46 0.6 0.78 0.9 ]
2. To verify the loopback detection algorithm, it is necessary to manually mark the loopback data set, such as [103]. However, it is inconvenient to mark the loop manually. We will consider calculating the loop according to the standard trajectory. That is, if the pose of two frames in the track is very similar, they are considered loop. Please calculate the loop in a data set according to the standard trajectory given by the TUM data set. Are the images of these loops really similar?
Reproduced at: Visual SLAM Lecture 14 (Second Edition) lesson 11 problem solving - Zhihu
#include <pangolin/pangolin.h>
#include <Eigen/Core>
#include <Eigen/Geometry>
#include <unistd.h>
using namespace std;
using namespace Eigen;
// path to groundtruth file
string groundtruth_file = "/home/liqiang/slambook2/ch11/rgbd_dataset_freiburg2_rpy/groundtruth.txt";
// Set the detection interval so that the detection has sparsity and covers the whole environment at the same time
int delta = 50;
// Norm of difference of homogeneous transformation matrix
// Less than this value, the pose is considered very close
double threshold = 0.4;
int main(int argc, char **argv) {
vector<Isometry3d, Eigen::aligned_allocator<Isometry3d>> poses;
vector<string> times;
ifstream fin(groundtruth_file);
if (!fin) {
cout << "cannot find trajectory file at " << groundtruth_file << endl;
return 1;
}
int num = 0;
while (!fin.eof())
{
string time_s;
double tx, ty, tz, qx, qy, qz, qw;
fin >> time_s >> tx >> ty >> tz >> qx >> qy >> qz >> qw;
Isometry3d Twr(Quaterniond(qw, qx, qy, qz));
Twr.pretranslate(Vector3d(tx, ty, tz));
// It is equivalent to starting from the 150th pose, because the standard trajectory is recorded earlier than the photos (there is no corresponding photo for the first 120 poses)
if (num > 120 && num % delta == 0){
times.push_back(time_s);
poses.push_back(Twr);
}
num++;
}
cout << "read total " << num << " pose entries" << endl;
cout << "selected total " << poses.size() << " pose entries" << endl;
//Set the number of picture intervals to restart detection after loop detection
cout << "**************************************************" << endl;
cout << "Detection Start!!!" << endl;
cout << "**************************************************" << endl;
for (size_t i = 0 ; i < poses.size() - delta; i += delta){
for (size_t j = i + delta ; j < poses.size() ; j++){
Matrix4d Error = (poses[i].inverse() * poses[j]).matrix() - Matrix4d::Identity();
if (Error.norm() < threshold){
cout << "The first" << i << "Photo and page" << j << "This photo forms a loop" << endl;
cout << "The pose error is" << Error.norm() << endl;
cout << "The first" << i << "The timestamp of this photo is" << endl << times[i] << endl;
cout << "The first" << j << "The timestamp of this photo is" << endl << times[j] << endl;
cout << "**************************************************" << endl;
break;
}
}
}
cout << "Detection Finish!!!" << endl;
cout << "**************************************************" << endl;
return 0;
}I tried this code, but it didn't run through. The error message was killed. I didn't understand what it meant. There may be insufficient memory or too much computation. If you want to try, run it.
3. Learn DBoW3 or DBoW2 library, find some pictures by yourself, and see if the loop can be detected correctly.
The datasets I use are: Computer Vision Group - Dataset Download

Then create a new folder data1 under ch11 and select 21 pictures to put in.
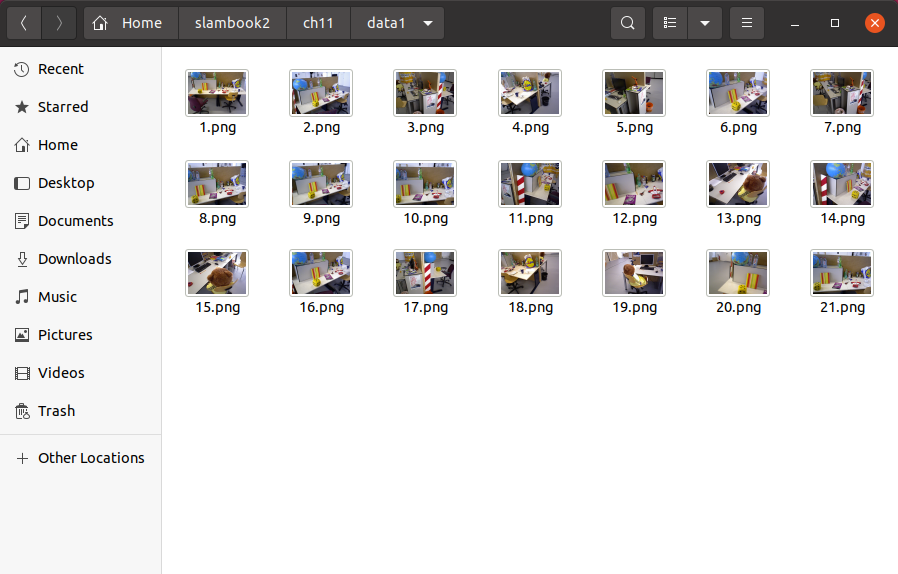
Then modify the image path:

gen_vocab_large3.cpp
#include "DBoW3/DBoW3.h" / / word bag support header file
#include <opencv2/core/core. HPP > / / opencv core module
#include <opencv2/highgui/highgui. HPP > / / GUI module
#include <opencv2/features2d/features2d. HPP > / / feature file
#include <iostream>
#include <vector>
#include <string>
using namespace cv;
using namespace std;
int main( int argc, char** argv )
{
String directoryPath = "/home/liqiang/slambook2/ch11/data1";//Image path
vector<String> imagesPath;
glob(directoryPath, imagesPath);
// string dataset_dir = argv[1];
// ifstream fin ( dataset_dir+"/home/liqiang/slambook2/ch11/rgbd_dataset_freiburg1_desk2/rgb" );
// if ( !fin )
// {
// cout<<"please generate the associate file called associate.txt!"<<endl;
// return 1;
// }
// vector<string> rgb_files, depth_files;
// vector<double> rgb_times, depth_times;
// while ( !fin.eof() )
// {
// string rgb_time, rgb_file, depth_time, depth_file;
// fin>>rgb_time>>rgb_file>>depth_time>>depth_file;
// rgb_times.push_back ( atof ( rgb_time.c_str() ) );
// depth_times.push_back ( atof ( depth_time.c_str() ) );
// rgb_files.push_back ( dataset_dir+"/"+rgb_file );
// depth_files.push_back ( dataset_dir+"/"+depth_file );
// if ( fin.good() == false )
// break;
// }
// fin.close();
cout<<"generating features ... "<<endl;//Output generating features
vector<Mat> descriptors;//descriptor
Ptr< Feature2D > detector = ORB::create();
int index = 1;
for ( String path : imagesPath )
{
Mat image = imread(path);
vector<KeyPoint> keypoints; //Key points
Mat descriptor;//descriptor
detector->detectAndCompute( image, Mat(), keypoints, descriptor );
descriptors.push_back( descriptor );
cout<<"extracting features from image " << index++ <<endl;//Outputting extracting features from image
}
cout<<"extract total "<<descriptors.size()*500<<" features."<<endl;
// create vocabulary
cout<<"creating vocabulary, please wait ... "<<endl;//Output creating dictionary, please wait
DBoW3::Vocabulary vocab;
vocab.create( descriptors );
cout<<"vocabulary info: "<<vocab<<endl;
vocab.save( "vocab_larger3.yml.gz" );//Save dictionary
cout<<"done"<<endl;
return 0;
}
CMakeLists.txt
cmake_minimum_required( VERSION 2.8 )
project( loop_closure )
set( CMAKE_BUILD_TYPE "Release" )
set( CMAKE_CXX_FLAGS "-std=c++14 -O3" )
# opencv
find_package( OpenCV 3.1 REQUIRED )
include_directories( ${OpenCV_INCLUDE_DIRS} )
# Add Pangolin dependency
find_package( Pangolin )
include_directories( ${Pangolin_INCLUDE_DIRS} )
# Add Eigen header file
include_directories("/usr/include/eigen3")
add_executable( 2 2.cpp )
target_link_libraries( 2 ${OpenCV_LIBS} ${DBoW3_LIBS} ${Pangolin_LIBRARIES} )
# dbow3
# dbow3 is a simple lib so I assume you installed it in default directory
set( DBoW3_INCLUDE_DIRS "/usr/local/include" )
set( DBoW3_LIBS "/usr/local/lib/libDBoW3.a" )
add_executable( feature_training feature_training.cpp )
target_link_libraries( feature_training ${OpenCV_LIBS} ${DBoW3_LIBS} )
add_executable( loop_closure loop_closure.cpp )
target_link_libraries( loop_closure ${OpenCV_LIBS} ${DBoW3_LIBS} )
add_executable( loop_closure1 loop_closure1.cpp )
target_link_libraries( loop_closure1 ${OpenCV_LIBS} ${DBoW3_LIBS} )
add_executable( loop_closure3 loop_closure3.cpp )
target_link_libraries( loop_closure3 ${OpenCV_LIBS} ${DBoW3_LIBS} )
add_executable( gen_vocab gen_vocab_large.cpp )
target_link_libraries( gen_vocab ${OpenCV_LIBS} ${DBoW3_LIBS} )
add_executable( gen_vocab1 gen_vocab_large1.cpp )
target_link_libraries( gen_vocab1 ${OpenCV_LIBS} ${DBoW3_LIBS} )
add_executable( gen_vocab2 gen_vocab_large2.cpp )
target_link_libraries( gen_vocab2 ${OpenCV_LIBS} ${DBoW3_LIBS} )
add_executable( gen_vocab3 gen_vocab_large3.cpp )
target_link_libraries( gen_vocab3 ${OpenCV_LIBS} ${DBoW3_LIBS} )Execution results:
./gen_vocab3
generating features ... extracting features from image 1 extracting features from image 2 extracting features from image 3 extracting features from image 4 extracting features from image 5 extracting features from image 6 extracting features from image 7 extracting features from image 8 extracting features from image 9 extracting features from image 10 extracting features from image 11 extracting features from image 12 extracting features from image 13 extracting features from image 14 extracting features from image 15 extracting features from image 16 extracting features from image 17 extracting features from image 18 extracting features from image 19 extracting features from image 20 extracting features from image 21 extract total 10500 features. creating vocabulary, please wait ... vocabulary info: Vocabulary: k = 10, L = 5, Weighting = tf-idf, Scoring = L1-norm, Number of words = 10381 done
After execution, a vocab will be generated in the build folder_ larger3. yml. GZ compressed package. Finally, put the compressed package under ch11 and execute loop_closure3.
Modify the following two places:


loop_closure3.cpp
#include "DBoW3/DBoW3.h" / / word bag support header file
#include <opencv2/core/core. HPP > / / opencv core module
#include <opencv2/highgui/highgui. HPP > / / GUI module
#include <opencv2/features2d/features2d. HPP > / / feature file
#include <iostream>
#include <vector>
#include <string>
using namespace cv;
using namespace std;
/***************************************************
* This section demonstrates how to calculate the similarity score based on the previously trained dictionary
* ************************************************/
int main(int argc, char **argv) {
// Read the images and database
cout << "reading database" << endl;//Outputting Reading database
DBoW3::Vocabulary vocab("../vocab_larger3.yml.gz");//vocabulary.yml.gz path
// DBoW3::Vocabulary vocab("./vocab_larger.yml.gz"); // use large vocab if you want:
if (vocab.empty()) {
cerr << "Vocabulary does not exist." << endl;//Output volatile does not exist
return 1;
}
cout << "reading images... " << endl;//Outputting reading images
vector<Mat> images;
for (int i = 0; i < 21; i++) {
string path = "../data1/" + to_string(i + 1) + ".png";//Image reading path
images.push_back(imread(path));
}
// NOTE: in this case we are comparing images with a vocabulary generated by themselves, this may lead to overfit. Here we use the dictionaries they generate to compare their own similarities, which may produce over fitting
// detect ORB features
cout << "detecting ORB features ... " << endl;//Outputting detecting ORB features (testing ORB characteristics)
Ptr<Feature2D> detector = ORB::create();//The default image has 500 feature points
vector<Mat> descriptors;//The descriptor extracts ORB features from 10 images and stores them in the vector container
for (Mat &image:images) {
vector<KeyPoint> keypoints;//Key points
Mat descriptor;//descriptor
detector->detectAndCompute(image, Mat(), keypoints, descriptor);//Detection and calculation
descriptors.push_back(descriptor);
}
// we can compare the images directly or we can compare one image to a database
// images :
cout << "comparing images with images " << endl;//Outputting comparing images with images
for (int i = 0; i < images.size(); i++)
{
DBoW3::BowVector v1;
//descriptors[i] represents all the sub sets of ORB descriptions in image I. the function transform() calculates the word vector described by the previous dictionary. The value of the element in each vector is either 0, indicating that there is no word in image I; Or the weight of the word
//The BoW description vector contains the ID and weight of each word, which constitute the whole sparse vector
//When comparing two vectors, DBoW3 calculates a score for us
vocab.transform(descriptors[i], v1);
for (int j = i; j < images.size(); j++)
{
DBoW3::BowVector v2;
vocab.transform(descriptors[j], v2);
double score = vocab.score(v1, v2);//p296 formula (11.9)
cout << "image " << i << " vs image " << j << " : " << score << endl;//Output the similarity score between one image and another image
}
cout << endl;
}
// or with database
//During database query, DBoW sorts the above scores and gives the most similar results
cout << "comparing images with database " << endl;
DBoW3::Database db(vocab, false, 0);
for (int i = 0; i < descriptors.size(); i++)
db.add(descriptors[i]);
cout << "database info: " << db << endl;//Output database info as
for (int i = 0; i < descriptors.size(); i++)
{
DBoW3::QueryResults ret;
db.query(descriptors[i], ret, 4); // max result=4
cout << "searching for image " << i << " returns " << ret << endl << endl;
}
cout << "done." << endl;
}
CMakeLists.txt
Refer to the above, cmakelists Txt has added the relevant cpp execution file.
./loop_closure3
reading database reading images... detecting ORB features ... comparing images with images image 0 vs image 0 : 1 image 0 vs image 1 : 0.0179514 image 0 vs image 2 : 0.0257712 image 0 vs image 3 : 0.0248006 image 0 vs image 4 : 0.0215647 image 0 vs image 5 : 0.00544075 image 0 vs image 6 : 0.0224883 image 0 vs image 7 : 0.0172719 image 0 vs image 8 : 0.0177548 image 0 vs image 9 : 0.0362582 image 0 vs image 10 : 0.0162675 image 0 vs image 11 : 0.0222014 image 0 vs image 12 : 0.0204588 image 0 vs image 13 : 0.0170047 image 0 vs image 14 : 0.0165957 image 0 vs image 15 : 0.0241384 image 0 vs image 16 : 0.0131228 image 0 vs image 17 : 0.0231237 image 0 vs image 18 : 0.0126125 image 0 vs image 19 : 0.0264222 image 0 vs image 20 : 0.0319604 image 1 vs image 1 : 1 image 1 vs image 2 : 0.0225294 image 1 vs image 3 : 0.0291438 image 1 vs image 4 : 0.024401 image 1 vs image 5 : 0.0427242 image 1 vs image 6 : 0.00947695 image 1 vs image 7 : 0.0336035 image 1 vs image 8 : 0.0554665 image 1 vs image 9 : 0.0313537 image 1 vs image 10 : 0.0127257 image 1 vs image 11 : 0.0170929 image 1 vs image 12 : 0.024939 image 1 vs image 13 : 0.0188714 image 1 vs image 14 : 0.0191085 image 1 vs image 15 : 0.0482948 image 1 vs image 16 : 0.0242885 image 1 vs image 17 : 0.0134153 image 1 vs image 18 : 0.017274 image 1 vs image 19 : 0.0283448 image 1 vs image 20 : 0.00922942 image 2 vs image 2 : 1 image 2 vs image 3 : 0.0159252 image 2 vs image 4 : 0.0253237 image 2 vs image 5 : 0.0118317 image 2 vs image 6 : 0.0571594 image 2 vs image 7 : 0.0189714 image 2 vs image 8 : 0.0155815 image 2 vs image 9 : 0.0195412 image 2 vs image 10 : 0.0184117 image 2 vs image 11 : 0.0152941 image 2 vs image 12 : 0.0178018 image 2 vs image 13 : 0.0233106 image 2 vs image 14 : 0.0168851 image 2 vs image 15 : 0.0137194 image 2 vs image 16 : 0.0498792 image 2 vs image 17 : 0.0240186 image 2 vs image 18 : 0.0219548 image 2 vs image 19 : 0.0209176 image 2 vs image 20 : 0.0140803 image 3 vs image 3 : 1 image 3 vs image 4 : 0.0234056 image 3 vs image 5 : 0.0284397 image 3 vs image 6 : 0.02011 image 3 vs image 7 : 0.0216389 image 3 vs image 8 : 0.0176086 image 3 vs image 9 : 0.0155744 image 3 vs image 10 : 0.0170962 image 3 vs image 11 : 0.0225567 image 3 vs image 12 : 0.0234662 image 3 vs image 13 : 0.0182703 image 3 vs image 14 : 0.01482 image 3 vs image 15 : 0.020363 image 3 vs image 16 : 0.0176234 image 3 vs image 17 : 0.0233771 image 3 vs image 18 : 0.0155559 image 3 vs image 19 : 0.016011 image 3 vs image 20 : 0.0177395 image 4 vs image 4 : 1 image 4 vs image 5 : 0.0119718 image 4 vs image 6 : 0.0274229 image 4 vs image 7 : 0.0149015 image 4 vs image 8 : 0.0252062 image 4 vs image 9 : 0.0127473 image 4 vs image 10 : 0.0123496 image 4 vs image 11 : 0.0234471 image 4 vs image 12 : 0.0255185 image 4 vs image 13 : 0.018047 image 4 vs image 14 : 0.0397562 image 4 vs image 15 : 0.0105365 image 4 vs image 16 : 0.0148716 image 4 vs image 17 : 0.0347258 image 4 vs image 18 : 0.0131217 image 4 vs image 19 : 0.0191835 image 4 vs image 20 : 0.0211236 image 5 vs image 5 : 1 image 5 vs image 6 : 0.0141552 image 5 vs image 7 : 0.0205087 image 5 vs image 8 : 0.023158 image 5 vs image 9 : 0.0193337 image 5 vs image 10 : 0.0187104 image 5 vs image 11 : 0.025994 image 5 vs image 12 : 0.0196689 image 5 vs image 13 : 0.0257136 image 5 vs image 14 : 0.0124622 image 5 vs image 15 : 0.0692064 image 5 vs image 16 : 0.0210536 image 5 vs image 17 : 0.0252288 image 5 vs image 18 : 0.0119623 image 5 vs image 19 : 0.0251428 image 5 vs image 20 : 0.0231639 image 6 vs image 6 : 1 image 6 vs image 7 : 0.0176295 image 6 vs image 8 : 0.0157532 image 6 vs image 9 : 0.0177508 image 6 vs image 10 : 0.0141089 image 6 vs image 11 : 0.0116931 image 6 vs image 12 : 0.0177043 image 6 vs image 13 : 0.0113189 image 6 vs image 14 : 0.0165114 image 6 vs image 15 : 0.0238359 image 6 vs image 16 : 0.0286878 image 6 vs image 17 : 0.0242205 image 6 vs image 18 : 0.0238473 image 6 vs image 19 : 0.0183829 image 6 vs image 20 : 0.0160894 image 7 vs image 7 : 1 image 7 vs image 8 : 0.0484327 image 7 vs image 9 : 0.0799389 image 7 vs image 10 : 0.0140699 image 7 vs image 11 : 0.0353015 image 7 vs image 12 : 0.0162742 image 7 vs image 13 : 0.0123849 image 7 vs image 14 : 0.0155762 image 7 vs image 15 : 0.0236286 image 7 vs image 16 : 0.021078 image 7 vs image 17 : 0.00994403 image 7 vs image 18 : 0.0104469 image 7 vs image 19 : 0.00981495 image 7 vs image 20 : 0.0793399 image 8 vs image 8 : 1 image 8 vs image 9 : 0.0242055 image 8 vs image 10 : 0.0144976 image 8 vs image 11 : 0.0289231 image 8 vs image 12 : 0.0134452 image 8 vs image 13 : 0.0107451 image 8 vs image 14 : 0.013121 image 8 vs image 15 : 0.0440592 image 8 vs image 16 : 0.023649 image 8 vs image 17 : 0.0226309 image 8 vs image 18 : 0.0167086 image 8 vs image 19 : 0.0163815 image 8 vs image 20 : 0.019543 image 9 vs image 9 : 1 image 9 vs image 10 : 0.0196453 image 9 vs image 11 : 0.0360537 image 9 vs image 12 : 0.0216228 image 9 vs image 13 : 0.00905572 image 9 vs image 14 : 0.0117925 image 9 vs image 15 : 0.0203327 image 9 vs image 16 : 0.0124184 image 9 vs image 17 : 0.014915 image 9 vs image 18 : 0.0190471 image 9 vs image 19 : 0.0135781 image 9 vs image 20 : 0.136697 image 10 vs image 10 : 1 image 10 vs image 11 : 0.0150776 image 10 vs image 12 : 0.0147019 image 10 vs image 13 : 0.0437288 image 10 vs image 14 : 0.0212159 image 10 vs image 15 : 0.0175276 image 10 vs image 16 : 0.0244171 image 10 vs image 17 : 0.0173673 image 10 vs image 18 : 0.0180583 image 10 vs image 19 : 0.0198632 image 10 vs image 20 : 0.0186188 image 11 vs image 11 : 1 image 11 vs image 12 : 0.0145951 image 11 vs image 13 : 0.00686832 image 11 vs image 14 : 0.0105737 image 11 vs image 15 : 0.0193443 image 11 vs image 16 : 0.0145832 image 11 vs image 17 : 0.0164647 image 11 vs image 18 : 0.0173467 image 11 vs image 19 : 0.0160974 image 11 vs image 20 : 0.0500313 image 12 vs image 12 : 1 image 12 vs image 13 : 0.00650131 image 12 vs image 14 : 0.0809155 image 12 vs image 15 : 0.0164976 image 12 vs image 16 : 0.0315461 image 12 vs image 17 : 0.0174517 image 12 vs image 18 : 0.029972 image 12 vs image 19 : 0.0157822 image 12 vs image 20 : 0.0115077 image 13 vs image 13 : 1 image 13 vs image 14 : 0.0190167 image 13 vs image 15 : 0.0269287 image 13 vs image 16 : 0.0171848 image 13 vs image 17 : 0.0151769 image 13 vs image 18 : 0.0242274 image 13 vs image 19 : 0.00725557 image 13 vs image 20 : 0.00889539 image 14 vs image 14 : 1 image 14 vs image 15 : 0.0181876 image 14 vs image 16 : 0.03296 image 14 vs image 17 : 0.0200591 image 14 vs image 18 : 0.0362168 image 14 vs image 19 : 0.0128257 image 14 vs image 20 : 0.0160966 image 15 vs image 15 : 1 image 15 vs image 16 : 0.0233746 image 15 vs image 17 : 0.0147329 image 15 vs image 18 : 0.0240136 image 15 vs image 19 : 0.0301395 image 15 vs image 20 : 0.0211014 image 16 vs image 16 : 1 image 16 vs image 17 : 0.0128384 image 16 vs image 18 : 0.0139085 image 16 vs image 19 : 0.0200746 image 16 vs image 20 : 0.0090532 image 17 vs image 17 : 1 image 17 vs image 18 : 0.018697 image 17 vs image 19 : 0.017062 image 17 vs image 20 : 0.0147481 image 18 vs image 18 : 1 image 18 vs image 19 : 0.0196678 image 18 vs image 20 : 0.0187427 image 19 vs image 19 : 1 image 19 vs image 20 : 0.0131965 image 20 vs image 20 : 1 comparing images with database database info: Database: Entries = 21, Using direct index = no. Vocabulary: k = 10, L = 5, Weighting = tf-idf, Scoring = L1-norm, Number of words = 10381 searching for image 0 returns 4 results: <EntryId: 0, Score: 1> <EntryId: 9, Score: 0.0362582> <EntryId: 20, Score: 0.0319604> <EntryId: 19, Score: 0.0264222> searching for image 1 returns 4 results: <EntryId: 1, Score: 1> <EntryId: 8, Score: 0.0554665> <EntryId: 15, Score: 0.0482948> <EntryId: 5, Score: 0.0427242> searching for image 2 returns 4 results: <EntryId: 2, Score: 1> <EntryId: 6, Score: 0.0571594> <EntryId: 16, Score: 0.0498792> <EntryId: 0, Score: 0.0257712> searching for image 3 returns 4 results: <EntryId: 3, Score: 1> <EntryId: 1, Score: 0.0291438> <EntryId: 5, Score: 0.0284397> <EntryId: 0, Score: 0.0248006> searching for image 4 returns 4 results: <EntryId: 4, Score: 1> <EntryId: 14, Score: 0.0397562> <EntryId: 17, Score: 0.0347258> <EntryId: 6, Score: 0.0274229> searching for image 5 returns 4 results: <EntryId: 5, Score: 1> <EntryId: 15, Score: 0.0692064> <EntryId: 1, Score: 0.0427242> <EntryId: 3, Score: 0.0284397> searching for image 6 returns 4 results: <EntryId: 6, Score: 1> <EntryId: 2, Score: 0.0571594> <EntryId: 16, Score: 0.0286878> <EntryId: 4, Score: 0.0274229> searching for image 7 returns 4 results: <EntryId: 7, Score: 1> <EntryId: 9, Score: 0.0799389> <EntryId: 20, Score: 0.0793399> <EntryId: 8, Score: 0.0484327> searching for image 8 returns 4 results: <EntryId: 8, Score: 1> <EntryId: 1, Score: 0.0554665> <EntryId: 7, Score: 0.0484327> <EntryId: 15, Score: 0.0440592> searching for image 9 returns 4 results: <EntryId: 9, Score: 1> <EntryId: 20, Score: 0.136697> <EntryId: 7, Score: 0.0799389> <EntryId: 0, Score: 0.0362582> searching for image 10 returns 4 results: <EntryId: 10, Score: 1> <EntryId: 13, Score: 0.0437288> <EntryId: 16, Score: 0.0244171> <EntryId: 14, Score: 0.0212159> searching for image 11 returns 4 results: <EntryId: 11, Score: 1> <EntryId: 20, Score: 0.0500313> <EntryId: 9, Score: 0.0360537> <EntryId: 7, Score: 0.0353015> searching for image 12 returns 4 results: <EntryId: 12, Score: 1> <EntryId: 14, Score: 0.0809155> <EntryId: 16, Score: 0.0315461> <EntryId: 18, Score: 0.029972> searching for image 13 returns 4 results: <EntryId: 13, Score: 1> <EntryId: 10, Score: 0.0437288> <EntryId: 15, Score: 0.0269287> <EntryId: 5, Score: 0.0257136> searching for image 14 returns 4 results: <EntryId: 14, Score: 1> <EntryId: 12, Score: 0.0809155> <EntryId: 4, Score: 0.0397562> <EntryId: 18, Score: 0.0362168> searching for image 15 returns 4 results: <EntryId: 15, Score: 1> <EntryId: 5, Score: 0.0692064> <EntryId: 1, Score: 0.0482948> <EntryId: 8, Score: 0.0440592> searching for image 16 returns 4 results: <EntryId: 16, Score: 1> <EntryId: 2, Score: 0.0498792> <EntryId: 14, Score: 0.03296> <EntryId: 12, Score: 0.0315461> searching for image 17 returns 4 results: <EntryId: 17, Score: 1> <EntryId: 4, Score: 0.0347258> <EntryId: 5, Score: 0.0252288> <EntryId: 6, Score: 0.0242205> searching for image 18 returns 4 results: <EntryId: 18, Score: 1> <EntryId: 14, Score: 0.0362168> <EntryId: 12, Score: 0.029972> <EntryId: 13, Score: 0.0242274> searching for image 19 returns 4 results: <EntryId: 19, Score: 1> <EntryId: 15, Score: 0.0301395> <EntryId: 1, Score: 0.0283448> <EntryId: 0, Score: 0.0264222> searching for image 20 returns 4 results: <EntryId: 20, Score: 1> <EntryId: 9, Score: 0.136697> <EntryId: 7, Score: 0.0793399> <EntryId: 11, Score: 0.0500313> done.
Pick out several with high matching scores
(note that the image sequence number in the execution program is different from that under the data1 folder: 9 corresponds to png, and 10 and 20 correspond to 21. Everyone who has learned the basic syntax of c + + here should be able to understand.)
Group I: form a loop
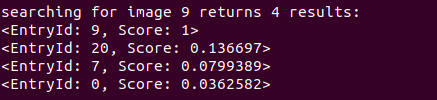


10.png 21.png
Group II: form a loop



15.png 13.png
Group III: form a loop
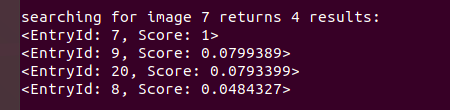


8.png 10.png
Group 4: form a loop
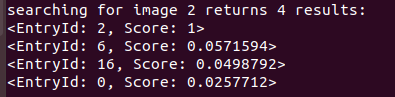


3.png 7.png
Summary: because my pictures are randomly selected, basically those with high matching scores constitute loopback, but sometimes detection errors occur. If the computer performance, you can try the whole data set or select more images from it for loopback detection.
4. What are the common measurement methods of research similarity score?
Please refer to the following articles for specific common measurement methods:
Similarity Measurement in machine learning - there are many methods to describe the similarity between samples. Generally speaking, the commonly used methods are correlation coefficient and Euclidean distance. This paper summarizes the common Similarity Measurement methods in machine learning. In classification, it is often necessary to estimate the Similarity Measurement between different samples, which https://zhuanlan.zhihu.com/p/55493039There are nine common distance measurement methods in data science, including Euclidean distance, Chebyshev distance, etc. - it is known that in data mining, we often need to calculate the similarity between samples. The usual method is to calculate the distance between samples. In this paper, data scientist Maarten Grootendorst introduces us nine distance measurement methods, including Euclidean distance, cosine similarity and so on. From towardsdahttps://zhuanlan.zhihu.com/p/350744027
https://zhuanlan.zhihu.com/p/55493039There are nine common distance measurement methods in data science, including Euclidean distance, Chebyshev distance, etc. - it is known that in data mining, we often need to calculate the similarity between samples. The usual method is to calculate the distance between samples. In this paper, data scientist Maarten Grootendorst introduces us nine distance measurement methods, including Euclidean distance, cosine similarity and so on. From towardsdahttps://zhuanlan.zhihu.com/p/350744027
(1) Euclidean distance
The matlab program is as follows:
Reproduced at: [data mining] Euclidean distance calculation with matlab_ Lamb Baa Baa blog - CSDN blog_ Calculating Euclidean distance with matlab
% Method 1
function dist = dist_E(x,y)
dist = [];
if(length(x)~=length(y))
disp('length of input vectors must agree') % disp The function outputs the content directly to the Matlab In the command window
else
z =(x-y).*(x-y);
dist = sqrt(sum(z));
end
end
% Method 2: formula method
function dist = dist_E(x,y)
[m,n] = size(x);
dist = 0;
for i=1:max(m,n)
dist = dist+(x(i)-y(i))^2;
end
dist = sqrt(dist);
end% Method 3: use pdist function function dist = dist_E(x,y) dist = [x;y]; dist = pdist(dist); % Calculate the Euclidean distance between each row of vectors end
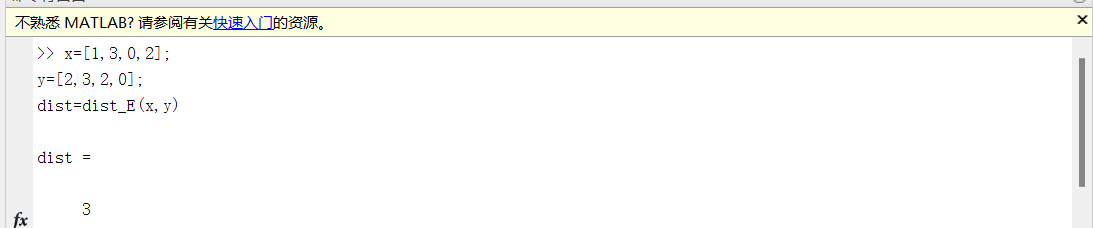
On the command line, enter:
x=[1,3,0,2]; y=[2,3,2,0]; dist=dist_E(x,y)
Press enter, and then you can calculate the Euclidean distance between the two vectors.
(2) Manhattan distance
import numpy as np
a=[8,2]
b=[5,10]
a_np = np.array(a)
b_np = np.array(b)
dist3 = np.sum(np.abs(a_np-b_np))
print(f"Manhattan Distance = {dist3}\n")
python manhatta.py
Manhattan Distance = 11
The following codes are reproduced in: [369]python implementation of various distance formulas_ Zhou Xiaodong - CSDN blog_ python Euclidean distance
(3) Chebyshev distance
# -*- coding: utf-8 -*-
from numpy import *
vector1 = mat([1,2,3])
vector2 = mat([4,7,5])
print (abs(vector1-vector2).max())
import numpy as np
x=np.random.random(10)
y=np.random.random(10)
#Method 1: solve according to the formula
d1=np.max(np.abs(x-y))
print('d1:',d1)
#Method 2: solve according to scipy library
from scipy.spatial.distance import pdist
X=np.vstack([x,y])
d2=pdist(X,'chebyshev')[0]
print('d2:',d2)
python Chebyshev.py
5 d1: 0.7956039912699736 d2: 0.7956039912699736
(3) Hamming distance
# -*- coding: utf-8 -*-
from numpy import *
matV = mat([[1,1,0,1,0,1,0,0,1],[0,1,1,0,0,0,1,1,1]])
smstr = nonzero(matV[0]-matV[1])
print(shape(smstr[0])[0])
import numpy as np
from scipy.spatial.distance import pdist
x=np.random.random(10)>0.5
y=np.random.random(10)>0.5
x=np.asarray(x,np.int32)
y=np.asarray(y,np.int32)
#Method 1: solve according to the formula
d1=np.mean(x!=y)
print('d1:', d1)
#Method 2: solve according to scipy library
X=np.vstack([x,y])
d2=pdist(X,'hamming')[0]
print('d2:', d2)
python hamming.py
6 d1: 0.4 d2: 0.4
(4) Normalized Euclidean distance
# -*- coding: utf-8 -*-
import numpy as np
x=np.random.random(10)
y=np.random.random(10)
X=np.vstack([x,y])
#Method 1: solve according to the formula
sk=np.var(X,axis=0,ddof=1)
d1=np.sqrt(((x - y) ** 2 /sk).sum())
print('d1:',d1)
#Method 2: solve according to scipy library
from scipy.spatial.distance import pdist
d2=pdist(X,'seuclidean')[0]
print('d2:',d2)
python Standardized_Euclidean.py
d1: 4.47213595499958 d2: 4.47213595499958
(5) Included angle cosine
# -*- coding: utf-8 -*-
import numpy as np
from scipy.spatial.distance import pdist
'''
x: [0.05627679 0.80556938 0.48002662 0.24378563 0.75763754 0.15353348
0.54491664 0.1775408 0.50011986 0.55041845]
y: [0.50068882 0.12200178 0.79041352 0.07332715 0.017892 0.57880032
0.56707591 0.48390753 0.631051 0.20035466]
'''
x = np.random.random(10)
y = np.random.random(10)
# solution1
dist1 = 1 - np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
# solution2
dist2 = pdist(np.vstack([x, y]), 'cosine')[0]
print('x', x)
print('y', y)
print('dist1:', dist1)
print('dist2:', dist2)
python Cosine.py
x [0.59758063 0.40859383 0.98186786 0.01670254 0.33830128 0.06095993 0.80674537 0.90611795 0.08119071 0.24229608] y [0.43176033 0.2846342 0.41233185 0.37309159 0.24177945 0.68055469 0.36115457 0.3278653 0.57811011 0.13355709] dist1: 0.31572330152121986 dist2: 0.31572330152121975
(6) Jackard distance & jackard similarity coefficient
# -*- coding: utf-8 -*-
from numpy import *
from scipy.spatial.distance import pdist # Import scipy distance formula
matV = mat([[1,1,0,1,0,1,0,0,1],[0,1,1,0,0,0,1,1,1]])
print ("dist.jaccard:", pdist(matV,'jaccard'))
import numpy as np
from scipy.spatial.distance import pdist
x = np.random.random(10) > 0.5
y = np.random.random(10) > 0.5
x = np.asarray(x, np.int32)
y = np.asarray(y, np.int32)
# Method 1: solve according to the formula
up = np.double(np.bitwise_and((x != y), np.bitwise_or(x != 0, y != 0)).sum())
down = np.double(np.bitwise_or(x != 0, y != 0).sum())
d1 = (up / down)
print('d1:', d1)
# Method 2: solve according to scipy library
X = np.vstack([x, y])
d2 = pdist(X, 'jaccard')[0]
print('d2:', d2)
python Jaccard.py
dist.jaccard: [0.75] d1: 1.0 d2: 1.0
(7) Correlation coefficient & correlation distance
# -*- coding: utf-8 -*-
import numpy as np
x=np.random.random(10)
y=np.random.random(10)
#Method 1: solve according to the formula
x_=x-np.mean(x)
y_=y-np.mean(y)
d1=np.dot(x_,y_)/(np.linalg.norm(x_)*np.linalg.norm(y_))
print('d1:', d1)
#Method 2: solve according to numpy library
X=np.vstack([x,y])
d2=np.corrcoef(X)[0][1]
print('d2:', d2)
python correlation.py
d1: 0.2479989126873464 d2: 0.24799891268734642
5. What is the principle of chow Liu tree? How is it used to build dictionaries and loop detection?
Refer to the following article: Graduation thesis arrangement (2): approximate discrete probability distribution with dependency tree | article | BEWINDOWEB
6. Read [118], in addition to the word bag model, what other methods are used for loop detection?
Refer to the following two articles:
Visual SLAM Lecture 14 (Second Edition) lesson 11 problem solving - Zhihu