- Propeller tool assembly - PaddleX
- The whole process development tool of the propeller integrates all the capabilities required for in-depth learning and development such as the core framework, model library, tools and components of the propeller, and opens up the whole process of in-depth learning and development.
- PaddleX also provides a concise Python API and a graphical development client for one click download and installation. Users can choose the corresponding development mode according to the actual production needs to obtain the best experience of the whole process development of the propeller.
- Competition link: New year competition of flying oar pilot group in the opening season - twelve cat classification problems
- AI learning map : the answer score reaches the baseline value (70) and wins a big gift (100 computing power and 100 points)- Question 1: Twelve cat classifications
Data description
This competition requires contestants to classify 12 kinds of cats, which belongs to the classic image classification task in CV direction. As the cornerstone of other image tasks, image classification task can make everyone get started with computer vision faster. The competition data set contains pictures of 12 kinds of cats and is divided into training set and test set.
- Training set: provide high-definition color pictures and the classification of the pictures. There are 2160 pictures of cats, including annotation files.
- Test set: only color pictures are provided, with a total of 240 pictures of cats, excluding label files.

1 import dependency
!pip install paddlex
import warnings
warnings.filterwarnings('ignore')
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import paddle
import paddlex as pdx
from paddlex import transforms as T
import numpy as np
import pandas as pd
import shutil
import glob
import cv2
import imghdr
from PIL import Image
2 data cleaning
- Generate ImageNet format folder, and the target data format is as follows:
Dataset/ # Image classification dataset root directory |--class A/ # All pictures in the current folder belong to category A | |--a_1.jpg | |--a_2.jpg | |--... | |--... | |--... | |--class Z/ # All pictures in the current folder belong to category Z | |--z1.jpg | |--z2.jpg | |--... | |--...
- Because we have a train in our training center_ list. Txt stores the corresponding category information, so we first put all the pictures in the corresponding category folder, and then use PaddleX to automatically divide the data.
2.1 decompressing data sets
pdx.utils.decompress('data/data10954/cat_12_train.zip')
pdx.utils.decompress('data/data10954/cat_12_test.zip')
Generate 12 category folders.
for i in range(12):
cls_path = os.path.join('data/data10954/ImageNetDataset/', '%02d' % int(i))
if not os.path.exists(cls_path):
os.makedirs(cls_path)
- Why use 00 / 01 / As a category? Because the PaddleX partition is sorted according to the string, the 2 / 3 /. After the partition The numerical number of is after 10 / 11.
- We hope that the category number output by the model is consistent with our folder (i.e. the number submitted by the competition), so it is set to XX format.
2.2 abnormal format cleaning
- Generate a one-to-one correspondence between the file name and the category, and then put the pictures into the target folder according to the category cls: data / data10954 / imagenetdataset / * / * jpg.
train_df = pd.read_csv('data/data10954/train_list.txt', header=None, sep='\t')
train_df.columns = ['name', 'cls']
train_df['name'] = train_df['name'].apply(lambda x: str(x).strip().split('/')[-1])
train_df['cls'] = train_df['cls'].apply(lambda x: '%02d' % int(str(x).strip()))
train_df.head()
| name | cls | |
|---|---|---|
| 0 | 8GOkTtqw7E6IHZx4olYnhzvXLCiRsUfM.jpg | 00 |
| 1 | hwQDH3VBabeFXISfjlWEmYicoyr6qK1p.jpg | 00 |
| 2 | RDgZKvM6sp3Tx9dlqiLNEVJjmcfQ0zI4.jpg | 00 |
| 3 | ArBRzHyphTxFS2be9XLaU58m34PudlEf.jpg | 00 |
| 4 | kmW7GTX6uyM2A53NBZxibYRpQnIVatCH.jpg | 00 |
- The model input picture format should be RGB three channel, if imghdr If what does not recognize the picture format, it will be deleted.
for i in range(len(train_df)):
img_path = os.path.join('data/data10954/cat_12_train', train_df.at[i, 'name'])
if os.path.exists(img_path) and imghdr.what(img_path):
img = Image.open(img_path)
if img.mode != 'RGB':
img = img.convert('RGB')
img.save(img_path)
else:
os.remove(img_path)
print('delete:', img_path)
delete: data/data10954/cat_12_train/ieOvwupZbC4Xckj73znWxo0ARMKD5FrP.jpg delete: data/data10954/cat_12_train/ovY2atRg8fsZ4jTbKC0UJIOd7mlPEy9u.jpg
- SRC from source path_ Move path to destination path dst_path.
- Note: in the previous step, only the exception picture was deleted, but the DataFrame was not updated. Therefore, use try except to ignore the situation where the record in the DataFrame still exists but the picture does not exist.
for i in range(len(train_df)):
src_path = os.path.join(
'data/data10954/cat_12_train',
train_df.at[i, 'name'])
dst_path = os.path.join(
os.path.join(
'data/data10954/ImageNetDataset/',
train_df.at[i, 'cls']),
train_df.at[i, 'name'])
try:
shutil.move(src_path, dst_path)
except Exception as e:
print(e)
[Errno 2] No such file or directory: 'data/data10954/cat_12_train/ieOvwupZbC4Xckj73znWxo0ARMKD5FrP.jpg' [Errno 2] No such file or directory: 'data/data10954/cat_12_train/ovY2atRg8fsZ4jTbKC0UJIOd7mlPEy9u.jpg'
3 data division
- PaddleX - Data Partitioning : 85% (1836) training + 15% (322) verification.
!paddlex --split_dataset --format ImageNet\
--dataset_dir data/data10954/ImageNetDataset\
--val_value 0.15\
--test_value 0
4 data transformation and reading
- PaddleX - Data Transformation : the data transformation method also has an important impact on the time-consuming and final effect of training.
train_transforms = T.Compose([
T.MixupImage(mixup_epoch=115),
T.ResizeByShort(short_size=256),
T.RandomCrop(crop_size=224, aspect_ratio=[0.75, 1.25], scaling=[0.3, 1.0]),
T.RandomHorizontalFlip(0.5),
T.RandomDistort(
brightness_range=0.4, brightness_prob=0.5,
contrast_range=0.4, contrast_prob=0.5,
saturation_range=0.4, saturation_prob=0.5,
hue_range=18, hue_prob=0.5),
T.RandomBlur(0.05),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
eval_transforms = T.Compose([
T.ResizeByShort(short_size=256),
T.CenterCrop(crop_size=224),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
- PaddleX - data reader : the reader for training and verification during model building training.
train_dataset = pdx.datasets.ImageNet(
data_dir='data/data10954/ImageNetDataset',
file_list='data/data10954/ImageNetDataset/train_list.txt',
label_list='data/data10954/ImageNetDataset/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.ImageNet(
data_dir='data/data10954/ImageNetDataset',
file_list='data/data10954/ImageNetDataset/val_list.txt',
label_list='data/data10954/ImageNetDataset/labels.txt',
transforms=eval_transforms)
5 configuration and training
- PaddleX - image classification model : select here ResNet101_vd_ssld , its TOP1 accuracy on ImageNet dataset reaches 0.8373.
model = pdx.cls.ResNet101_vd_ssld(num_classes=len(train_dataset.labels))
5.1 learning rate strategy
The learning rate strategy and parameters adopt the classic IMAGENET training method:
- LinearWarmup: warm up the learning rate by 5 epochs (warm up_steps = step_each_Epoch * 5);
- Piecewsedecay: the periodic learning rate decreases, and the learning rate of every 30 epochs decreases to 0.1 times of the original, a total of 120 epochs (learning_rate * (0.1**i));
- The Momentum optimizer with Momentum is selected, and the weight L2 regularization coefficient is 0.0005;
- The batch size and initial learning rate are linearly scaled from 256-0.1 to 64-0.025. Considering the small size of the data set and the use of pre training weight, they are reduced to 64-0.0125.
- You can enter in the notebook? paddle. optimizer. lr. Piecweisedecay knows how to use this block, for example? paddle. optimizer. lr. Cosine annealingdecay cosine attenuation.
num_epochs = 120
learning_rate = 0.0125
lr_decay_epochs = [30, 60, 90]
train_batch_size = 64
step_each_epoch = train_dataset.num_samples // train_batch_size
boundaries = [b * step_each_epoch for b in lr_decay_epochs]
values = [learning_rate * (0.1**i) for i in range(len(lr_decay_epochs) + 1)]
lr = paddle.optimizer.lr.PiecewiseDecay(
boundaries=boundaries,
values=values)
lr = paddle.optimizer.lr.LinearWarmup(
learning_rate=lr,
warmup_steps=step_each_epoch * 5,
start_lr=0.0,
end_lr=learning_rate)
optimizer = paddle.optimizer.Momentum(
learning_rate=lr,
momentum=0.9,
weight_decay=paddle.regularizer.L2Decay(0.0005),
parameters=model.net.parameters())
5.2 start training
- You can enter Watch - N 0 NVIDIA SMI in the terminal to view the memory capacity, and adjust the size of picture transformation, batch size and other parameters as required.
- Capacity of this version: 9354MiB / 16384MiB.
- Because the division proportion of validation data is small and Mixup Data enhancement makes the high index model on the early verification set less robust than that at the end of training.
model.train(
train_dataset=train_dataset,
eval_dataset=eval_dataset,
num_epochs=num_epochs,
train_batch_size=train_batch_size,
optimizer=optimizer,
save_interval_epochs=1,
log_interval_steps=step_each_epoch * 5,
pretrain_weights='IMAGENET',
save_dir='output/ResNet101_vd_ssld',
use_vdl=True)
6 evaluation and prediction
6.1 model evaluation
model = pdx.load_model('output/ResNet101_vd_ssld/best_model')
Different data evaluation transformations will also lead to different results, such as the original transformation Eval below_ transforms_ Origin and modified transform eval_transforms_modify, the indicators are a little different.
eval_transforms_origin = T.Compose([
T.ResizeByShort(short_size=256),
T.CenterCrop(crop_size=224),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
eval_transforms_modify = T.Compose([
T.Resize(target_size=224),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
eval_dataset = pdx.datasets.ImageNet(
data_dir='data/data10954/ImageNetDataset',
file_list='data/data10954/ImageNetDataset/val_list.txt',
label_list='data/data10954/ImageNetDataset/labels.txt',
transforms=eval_transforms_origin)
model.evaluate(eval_dataset=eval_dataset, batch_size=64)
OrderedDict([('acc1', 0.9713542), ('acc5', 1.0)])
eval_dataset = pdx.datasets.ImageNet(
data_dir='data/data10954/ImageNetDataset',
file_list='data/data10954/ImageNetDataset/val_list.txt',
label_list='data/data10954/ImageNetDataset/labels.txt',
transforms=eval_transforms_modify)
model.evaluate(eval_dataset=eval_dataset, batch_size=64)
OrderedDict([('acc1', 0.9583333), ('acc5', 1.0)])
- It should be noted that if Eval is not specified during model training_ Dataset, the model saved in the training process will not have the built-in transformation method during evaluation. At this time, it needs to be in model Model. Needs to be specified in predict() predit(image, transforms=eval_transforms).
# We set the evaluation transformation during training, so the saved model comes with us model.get_model_info()['Transforms']
[{'ResizeByShort': {'short_size': 256, 'max_size': -1, 'interp': 'LINEAR'}},
{'CenterCrop': {'crop_size': 224}},
{'Normalize': {'mean': [0.485, 0.456, 0.406],
'std': [0.229, 0.224, 0.225],
'min_val': [0, 0, 0],
'max_val': [255.0, 255.0, 255.0],
'is_scale': True}}]
6.2 model prediction
Extract some images in the validation set for visualization.
df_val = pd.read_csv('data/data10954/ImageNetDataset/val_list.txt', header=None, sep='\s+')
df_val.columns = ['path', 'cls']
df_val = df_val.sample(n=12, replace=False)
df_val.index = range(len(df_val))
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(8, 10))
for i in range(12):
plt.subplot(4, 3, i+1)
plt.axis('off')
image = cv2.imread(os.path.join('data/data10954/ImageNetDataset', df_val.at[i, 'path']))
result = model.predict(image)[0]
plt.title("%d (True) / %d (Predict) - %.4f" % (df_val.at[i, 'cls'], result['category_id'], result['score']))
plt.imshow(image[:, :, [2, 1, 0]])
plt.tight_layout()
plt.show()

- Generate the competition submission file in the left column work / result Click download under CSV.
- In order to avoid reading abnormal pictures in the test set, PIL is also used here Image. open. Convert ('rgb ') to convert the picture mode, and then convert it to numpy Ndarray (note that the RGB channel is converted to BGR).
test_list = sorted(glob.glob('data/data10954/cat_12_test/*.jpg'))
test_df = pd.DataFrame()
for i in range(len(test_list)):
img = Image.open(test_list[i]).convert('RGB')
img = np.asarray(img, dtype='float32')
img = img[:, :, [2, 1, 0]]
result = model.predict(img)
test_df.at[i, 'name'] = str(test_list[i]).split('/')[-1]
test_df.at[i, 'cls'] = int(result[0]['category_id'])
test_df[['name']] = test_df[['name']].astype(str)
test_df[['cls']] = test_df[['cls']].astype(int)
/')[-1]
test_df.at[i, 'cls'] = int(result[0]['category_id'])
test_df[['name']] = test_df[['name']].astype(str)
test_df[['cls']] = test_df[['cls']].astype(int)
test_df.to_csv('work/result.csv', index=False, header=False)
- Get the result file Question 1: Twelve cat classifications In, the generated version is updated csv submission, get the calculation force and integral (a 0.954 file is saved in this version).
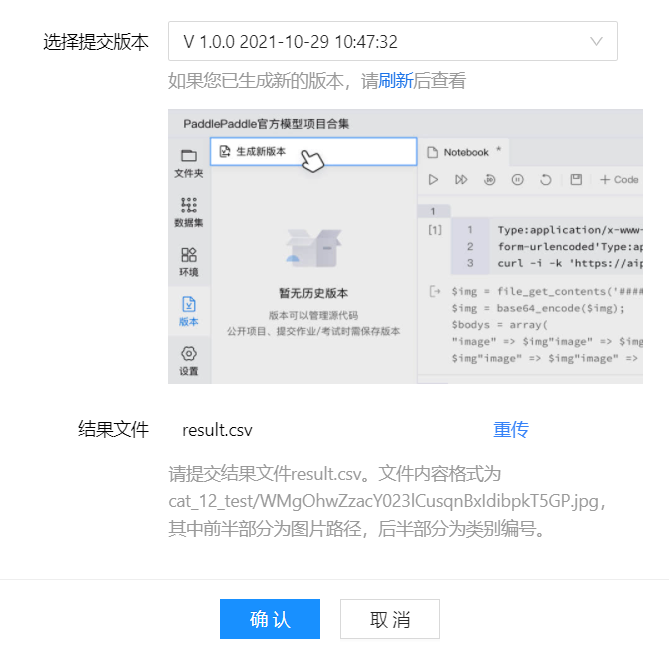
7 project summary
- The above is about the whole process of applying PaddleX to cat image twelve classification competition.
- It should be noted that the complexity of program code is not necessarily positively correlated with the submission score, and the specific steps and parameters can be modified by yourself.
- Information about the interpretability of the model can be referred to PaddleX 1.3.11 version document.
- More image classification techniques can be referred to PaddleClas - Ticks.