KetamaHash code to achieve consistency hash (distributed routing algorithm) and principle analysis
What is a consistent hash
As a common distributed routing algorithm, consistent hash can well realize the load balancing of the server. When users request, they can hit different servers through the distributed routing algorithm, which can ensure users' stickiness and good scalability. The addition and deletion nodes of the server will not cause large-scale data movement.
Consistent hash principle
In a word, the more intense the hash function is, the more balanced the hash distribution is. This is the essence of consistent hash.
Simple hash Routing: hash(key)% number of nodes
There are many problems with this hard hash method. If nodes are added or deleted, a large number of caches will fail to hit. Suppose a cluster with three nodes is added, 3 / 4 of the data will fail, and the failure rate will be greater in the case of a large number of nodes.
It may cause cache avalanche and push a large amount of data into the database
Consistency hash
Consistency hash mainly controls the hash distribution of the whole hash through more virtual nodes, which can alleviate the problem of a large number of cache failures caused by adding and deleting machines, and only a small part of the cache will be invalidated. This means that the above will not cause large-scale data movement.
Does more virtual nodes make the hash distribution more balanced? This involves the most fundamental problem. Hash algorithm and consistency hash recommend using KetamaHash algorithm to realize hash distribution. This paper also uses this hash algorithm to realize more balanced hash distribution.
Direct code
Two hash algorithms will be written below, due to fnv1_32_hash search consistency hash on csdn is basically based on this implementation, so one KetamaHash and one fnv1_32_hash, the effect of the two hash algorithms will be tested later. In fact, KetamaHash has a good effect
The first is the KetamaHash algorithm, which obtains the hash value through its getHash(key)
public class KetamaHash {
private static MessageDigest md5Digest;
static {
try {
md5Digest = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException var1) {
throw new RuntimeException("MD5 not supported", var1);
}
}
public int getHash(String origin) {
byte[] bKey = computeMd5(origin);
long rv = (long)(bKey[3] & 255) << 24 | (long)(bKey[2] & 255) << 16 | (long)(bKey[1] & 255) << 8 | (long)(bKey[0] & 255);
return (int)(rv & 4294967295L);
}
private static byte[] computeMd5(String k) {
MessageDigest md5;
try {
md5 = (MessageDigest)md5Digest.clone();
} catch (CloneNotSupportedException var3) {
throw new RuntimeException("clone of MD5 not supported", var3);
}
md5.update(k.getBytes());
return md5.digest();
}
}
fnv1_32_hash implementation (Baidu's)
public static int getHashCode(String str) {
final int p = 16777619;
int hash = (int)2166136261L;
for(int i = 0; i < str.length(); i++)
{
hash = (hash ^ str.charAt(i)) * p;
}
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// If the calculated value is negative, its absolute value is taken
if (hash < 0)
{
hash = Math.abs(hash);
}
return hash;
}
Code for consistency hash (ketamaHash.getHash(virnode) calculates hash)
public class hashtest {
//Physical node
List<String> realnodes = new ArrayList<String>();
//Number of virtual nodes (the total number of virtual nodes of each real node is about 1000-2000)
//Default 100
private int virNodeNum = 100;
//Define a TreeMap for storing hash es
private SortedMap<Integer,String> hashTree = new TreeMap<Integer, String>();
//Create class initialization to specify the number of virtual nodes per physical node
public hashtest(int virNodeNum){
this.virNodeNum = virNodeNum;
}
KetamaHash ketamaHash = new KetamaHash();
//Add a server node
public void addNode(String node)
{
//Add a physical node list
realnodes.add(node);
//Start virtual physical node
String virnode = null;
List<String> virnodes = new ArrayList<String>();
for (int i = 0; i <virNodeNum ; i++) {
//Name of the virtual node (for hash)
virnode = node+"vir/*/"+i;
//Add to virtual node list
virnodes.add(virnode);
//ketama calculates the hash value
int virhash = Math.abs(ketamaHash.getHash(virnode));
//int virhash = getHashCode(virnode);
//Save to hash tree
hashTree.put(virhash,node);
}
}
//Delete a node
public void removenode(String node) {
realnodes.remove(node);
Iterator<Map.Entry<Integer, String>> keys = hashTree.entrySet().iterator();
while (keys.hasNext())
{
Map.Entry<Integer, String> next = keys.next();
if(next.getValue().equals(node))
{
keys.remove();
}
}
}
//Routing node (get server node)
public String getNode(String key)
{
int virhash = Math.abs(ketamaHash.getHash(key));
//int virhash = getHashCode(key);
//Get the sub map greater than or equal to the key (hash ring clockwise)
SortedMap<Integer,String> sortedMap = hashTree.tailMap(virhash);
if (sortedMap.isEmpty())
{
return hashTree.get(hashTree.firstKey());
}
else
{
return sortedMap.get(sortedMap.firstKey());
}
}
}
Test effect
1, Using ketamaHash:
public static void main(String[] args) {
hashtest sda = new hashtest(500);
sda.addNode("192.168.2.3");
sda.addNode("192.168.2.4");
sda.addNode("192.168.2.5");
sda.addNode("192.168.2.6");
sda.addNode("192.168.2.6");
List<String> res = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
String node = sda.getNode("hello" + i);
res.add(node);
}
Map<String,Integer> map = new HashMap();
for(String item: res){
if(map.containsKey(item)){
map.put(item, map.get(item) + 1);
}else{
map.put(item, new Integer(1));
}
}
Iterator keys = map.keySet().iterator();
while(keys.hasNext()){
String key = (String) keys.next();
System.out.println("server address"+key + ":" +"Number of hits"+ map.get(key).intValue() + ", ");
}
}
Output results:
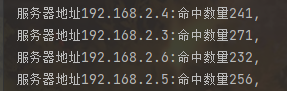
Using fnv1_32_hash
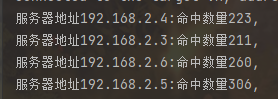
When you see the comparison of the results, you will find that the effect of using fin is not as uniform as that of ketamahash. The maximum number of hits is 306 and the minimum number is 211. The gap is still very large.
What does the above code mean? It means that each physical node is virtualized with 500 nodes for operation. Theoretically, the more virtual nodes, the more uniform the distribution.