introduction
For the author, the most important thing to learn mmdetection is to learn how to DIY your own model, so it is very important to understand how the classical model is built step by step. This chapter will start from scratch and deconstruct the construction process of the one-stage detection model (taking FCOS as an example) in mmdetection. This paper has detailed explanations and comments in the specific code part of FCOS. Students who have DIY model requirements like the author can read it carefully~
Composition of one-stage detection model
The OneStageDetector makes intensive prediction of target location and category directly on the extracted feature map. The model composition of the one-stage detector is relatively simple, and the key components are backbone, neck and bbox_head:

Generally speaking, the differences of detection models in different stages are mainly concentrated in two parts: bbox_head and loss function, which are also the focus of this chapter.
Construction of FCOS model in mmdet
Method introduction
Thesis address: FCOS: Fully Convolutional One-Stage Object Detection

(the above figure is from the original paper)
FCOS adopts the full convolution network structure, and takes an additional center prediction branch on the classification branch of the detection head to predict the offset degree of the target from the center, which can improve the quality of the detection frame. This is a very interesting work. Students interested in the specific details of the model can read the original text by themselves. This paper mainly discusses the implementation process of FCOS in mmdetection.
Returning to the "three elements" of the first stage detection model structure mentioned above, FCOS has no special requirements on the Backbone. Neck uses the most commonly used feature pyramid (FPN) in detection tasks, and its innovation is mainly reflected in the bbox_head part.
General construction process of mmdet model
stay mmdetection/tools/train.py In, the model is constructed as follows:
from mmdet.models import build_detector
"""As you can see, the construction of the model depends on cfg.model,cfg.train_cfg,cfg.test_cfg Three dictionaries"""
model = build_detector(
cfg.model,
train_cfg=cfg.get('train_cfg'),
test_cfg=cfg.get('test_cfg'))
"""Model parameter initialization"""
model.init_weights()
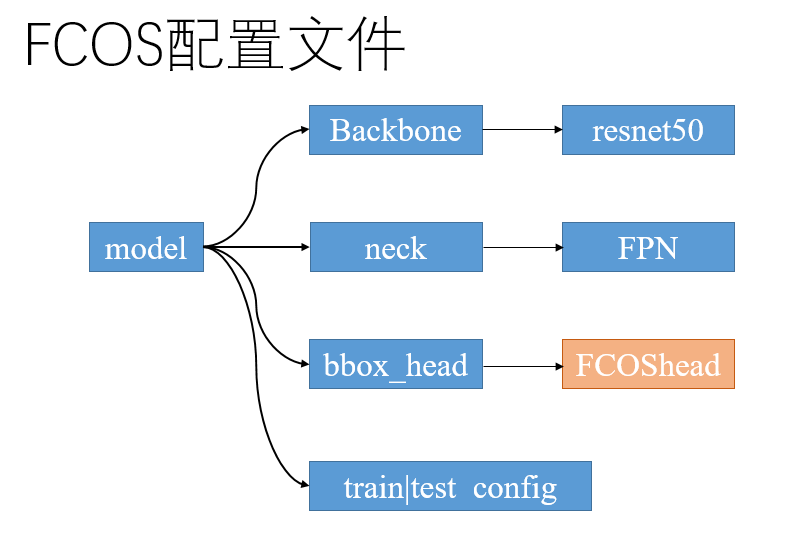
Next we see the FCOS configuration file , the author notes the important parts:
"""model part"""
model = dict(
"""type Indicates the class of the model(class)"""
type='FCOS',
"""appoint backbone,backbone It is generally the most flexible part of the model,It can be easily replaced with other networks"""
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=False),
norm_eval=True,
style='caffe',
init_cfg=dict(
type='Pretrained',
checkpoint='open-mmlab://detectron/resnet50_caffe')),
"""Use here FPN As neck,And specified FPN Number of input and output channels and whether to use relu Equal parameters"""
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
start_level=1,
add_extra_convs='on_output', # use P5
num_outs=5,
relu_before_extra_convs=True),
"""It's specified here bbox_head,Can see type by'FCOShead',yes FCOS Core components of"""
bbox_head=dict(
type='FCOSHead',
num_classes=80,
in_channels=256,
stacked_convs=4,
feat_channels=256,
strides=[8, 16, 32, 64, 128],
"""loss Attributable to bbox_head part,The loss function for detecting the first three branches is specified here"""
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='IoULoss', loss_weight=1.0),
loss_centerness=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)),
"""Configuration part of training and testing"""
train_cfg=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.4,
min_pos_iou=0,
ignore_iof_thr=-1),
allowed_border=-1,
pos_weight=-1,
debug=False),
test_cfg=dict(
nms_pre=1000,
min_bbox_size=0,
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100))
The basic structure of the configuration file is shown in the figure below. FCOShead is a key part of the model:
Next, see the build function build of the detection model_ detector():
from mmcv.utils import Registry
MODELS = Registry('models', parent=MMCV_MODELS)
DETECTORS = MODELS
def build_detector(cfg, train_cfg=None, test_cfg=None):
"""Build detector."""
if train_cfg is not None or test_cfg is not None:
warnings.warn(
'train_cfg and test_cfg is deprecated, '
'please specify them in model', UserWarning)
assert cfg.get('train_cfg') is None or train_cfg is None, \
'train_cfg specified in both outer field and model field '
assert cfg.get('test_cfg') is None or test_cfg is None, \
'test_cfg specified in both outer field and model field '
return DETECTORS.build(
cfg, default_args=dict(train_cfg=train_cfg, test_cfg=test_cfg))
DETECTORS is a registry instance of mmcv, DETECTORS Build (cfg) is to instantiate a model according to the model category (keyword 'type') given by cfg. In this example, if the category of the model is type = 'FCOS', this function will build and return an FCOS model.
FCOS
We are mmdetection/mmdet/models/detectors/fcos.py Find the definition of FCOS category:
# Copyright (c) OpenMMLab. All rights reserved.
from ..builder import DETECTORS
from .single_stage import SingleStageDetector
@DETECTORS.register_module()
class FCOS(SingleStageDetector):
"""Implementation of `FCOS <https://arxiv.org/abs/1904.01355>`_"""
def __init__(self,
backbone,
neck,
bbox_head,
train_cfg=None,
test_cfg=None,
pretrained=None,
init_cfg=None):
super(FCOS, self).__init__(backbone, neck, bbox_head, train_cfg,
test_cfg, pretrained, init_cfg)
Unexpectedly, the definition of FCOS is very simple, that is, it inherits the SingleStageDetector and instantiates it.
SingleStageDetector
Let's take a look at the SingleStageDetector. Here we also make some comments on the key parts:
@DETECTORS.register_module()
class SingleStageDetector(BaseDetector):
"""Base class of one-stage detector
One stage detector in backbone+neck The output is directly used for dense bounding box prediction
"""
def __init__(self,
backbone,
neck=None,
bbox_head=None,
train_cfg=None,
test_cfg=None,
pretrained=None,
init_cfg=None):
super(SingleStageDetector, self).__init__(init_cfg)
if pretrained:
warnings.warn('DeprecationWarning: pretrained is deprecated, '
'please use "init_cfg" instead')
backbone.pretrained = pretrained
"""establish backbone,build Function function and build_detecor identical"""
self.backbone = build_backbone(backbone)
if neck is not None:
"""establish neck, Generally used in testing FPN And its various variants"""
self.neck = build_neck(neck)
bbox_head.update(train_cfg=train_cfg)
bbox_head.update(test_cfg=test_cfg)
"""establish bbox_head"""
self.bbox_head = build_head(bbox_head)
self.train_cfg = train_cfg
self.test_cfg = test_cfg
"""feature extraction """
def extract_feat(self, img):
"""use backbone and neck Feature extraction"""
x = self.backbone(img)
if self.with_neck:
x = self.neck(x)
return x
def forward_dummy(self, img):
"""Forward propagation algorithm x ---> backbone+neck ---> feat ---> bbox_head ---> outs"""
x = self.extract_feat(img)
outs = self.bbox_head(x)
return outs
def forward_train(self,
img,
img_metas,
gt_bboxes,
gt_labels,
gt_bboxes_ignore=None):
"""
parameter:
img (Tensor): Enter a picture in the shape of(N,C,H,W),Generally speaking, it should be a normalized picture.
img_metas (list[dict]): contain'image_scale','flip','filename','ori_shape'Dictionary list of equivalent meta information
gt_bboxes (list[Tensor]): Bounding box real dimension, shape(xmin,ymin,xmax,ymax).
gt_labels (list[Tensor]): Category of bounding box
gt_bboxes_ignore (None | list[Tensor]): Specifies a bounding box that can be ignored when calculating losses.
Return value:
dict[str, Tensor]: Dictionary containing multiple loss functions.
"""
super(SingleStageDetector, self).forward_train(img, img_metas)
"""Extract features and use bbox_head The forward propagation function of the loss is obtained"""
x = self.extract_feat(img)
losses = self.bbox_head.forward_train(x, img_metas, gt_bboxes,
gt_labels, gt_bboxes_ignore)
return losses
The above is the training part of SingleStageDetector, and the following is the test part:
def simple_test(self, img, img_metas, rescale=False):
"""Simple test functions without test phase data enhancement
parameter:
rescale (bool, optional): Whether to shrink the test results to the original size. The default is False.
Return value:
list[list[np.ndarray]]: Test results of each category in each picture, the first list Dimensions represent different pictures, the second one list Dimensions represent different categories.
"""
"""Extract features and use bbox_head of simple_test Function to test"""
feat = self.extract_feat(img)
results_list = self.bbox_head.simple_test(
feat, img_metas, rescale=rescale)
"""use bbox2result Function processes the detection result and returns"""
bbox_results = [
bbox2result(det_bboxes, det_labels, self.bbox_head.num_classes)
for det_bboxes, det_labels in results_list
]
return bbox_results
def aug_test(self, imgs, img_metas, rescale=False):
"""And simple_test The functions are basically the same, except that data enhancement is used in the test
"""
assert hasattr(self.bbox_head, 'aug_test'), \
f'{self.bbox_head.__class__.__name__}' \
' does not support test-time augmentation'
feats = self.extract_feats(imgs)
"""use bbox_head of aug_test function"""
results_list = self.bbox_head.aug_test(
feats, img_metas, rescale=rescale)
bbox_results = [
bbox2result(det_bboxes, det_labels, self.bbox_head.num_classes)
for det_bboxes, det_labels in results_list
]
return bbox_results
Through the analysis of SingleStageDetector class code, we can know that bbox is used in key steps such as forward propagation and testing_ Head's training and testing functions show that for the one-stage detection model, bbox_head is the most important part.
Backbone and Neck
Here are just some brief introductions to backbone and neck.
backbone:Resnet
Backbone is the backbone network, which is generally composed of a large number of convolution, pooling, normalization and activation layers. It is often used for image feature extraction. In this paper, FCOS uses the most classic resnet50 as the backbone network. In mmdetection, the backbone network, like other components in the detection model, also needs to write and register classes:
"""
codes from mmdet/models/bakcbones/resnet.py
"""
@BACKBONES.register_module()
class ResNet(BaseModule):
"""ResNet backbone."""
The usage of Resnet is very simple. It accepts the image input with shape (N,C,H,W) and returns the output of four stage s. Here is an official example:
from mmdet.models import ResNet import torch m = ResNet(18) m.eval() input = torch.rand((1,3,32,32)) level_outputs = m.forward(input) for level_output in level_outputs: print(level_output.shape)
The results obtained are:
torch.Size([1, 64, 8, 8]) torch.Size([1, 128, 4, 4]) torch.Size([1, 256, 2, 2]) torch.Size([1, 512, 1, 1])
neck:FPN
Feature pyramid network is the most commonly used neck structure in detection tasks, which is mainly used for multi-scale information fusion:
@NECKS.register_module() class FPN(BaseModule):
FPN accepts multiple inputs of different scales and returns a tuple containing different scale characteristics of the same number of channels:
from mmdet.models import ResNet
from mmdet.models import FPN
import torch
m = ResNet(18)
m.eval()
input = torch.rand((1,3,32,32))
level_outputs = m.forward(input)
in_channels = [64,128,256,512]
fpn = FPN(in_channels=in_channels,out_channels=256,num_outs=len(level_outputs))
fpn.eval()
outputs = fpn.forward(level_outputs)
for output in outputs:
print(output.shape)
The results of the above test code are:
torch.Size([1, 256, 8, 8]) torch.Size([1, 256, 4, 4]) torch.Size([1, 256, 2, 2]) torch.Size([1, 256, 1, 1])
It can be seen that all input channels are processed to 256
bbox_head
Finally, it's the highlight of this paper. Next, we will make a detailed analysis of the first stage detection head in mmdetection.
First of all, we need to know that in mmdetection, the FCOS detector follows the following class inheritance relationship:
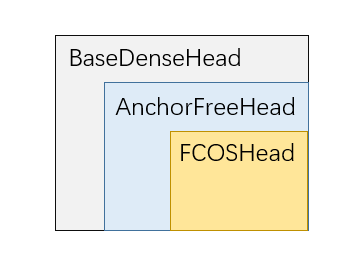
BaseDenseHead
This class is the base class of dense detection headers. All headers that directly predict on the feature graph (including one-stage detector and RPN) inherit from this class from the root. Let's take a look at the code and the author's comments. See for the source code mmdet/models/dense_heads/base_dense_head.py
"""This category is abstract"""
class BaseDenseHead(BaseModule, metaclass=ABCMeta):
"""Base class for DenseHeads."""
def __init__(self, init_cfg=None):
super(BaseDenseHead, self).__init__(init_cfg)
"""This category contains loss and get_bboxes Two abstract methods, subclasses must be replicated"""
@abstractmethod
def loss(self, **kwargs):
"""Calculate the loss of the detection head."""
pass
@abstractmethod
def get_bboxes(self, **kwargs):
"""Convert the batch output of the test head to frame prediction."""
pass
def forward_train(self,
x,
img_metas,
gt_bboxes,
gt_labels=None,
gt_bboxes_ignore=None,
proposal_cfg=None,
**kwargs):
"""
Args:
x (list[Tensor]): Different scale inputs from the feature pyramid.
img_metas (list[dict]): Meta information of picture.
gt_bboxes (Tensor): Bounding box true value, shape(N,4)
gt_labels (Tensor): The real category label of the bounding box in the shape of(N,)
gt_bboxes_ignore (Tensor): Ground truth bboxes to be
ignored, shape (num_ignored_gts, 4).
proposal_cfg (mmcv.Config): Test / postprocessing configuration,
if None, test_cfg would be used
Returns:
tuple:
losses: (dict[str, Tensor]): Loss function dictionary.
proposal_list (list[Tensor]): Generated on each picture proposal.
"""
outs = self(x)
"""If given gt_labels Add the category label to the calculation of the loss function"""
if gt_labels is None:
loss_inputs = outs + (gt_bboxes, img_metas)
else:
loss_inputs = outs + (gt_bboxes, gt_labels, img_metas)
"""Calculation loss function"""
losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
# Returns the loss function dictionary and, if necessary, the generated proposal
if proposal_cfg is None:
return losses
else:
proposal_list = self.get_bboxes(*outs, img_metas, cfg=proposal_cfg)
return losses, proposal_list
def simple_test(self, feats, img_metas, rescale=False):
"""Simple test function.
Returns:
list[tuple[Tensor, Tensor]]: Each item in the list is a tuple of length 2. First tensor in tuple
Shape is(N,5), Dimension 5 represents (tl_x, tl_y, br_x, br_y, score).The second tensor is the category prediction result,
The shape of its tensor is(N,)
"""
return self.simple_test_bboxes(feats, img_metas, rescale=rescale)
Basesensehead is an abstract class, and its subclasses must duplicate loss() and get_bboxes() two abstract methods.
AnchorFreeHead
Anchor free method means that the anchor frame of the specified size is not set in advance, but the target position is predicted directly. Let's first look at the initialization function of AnchorFreeHead class:
from abc import abstractmethod
import torch
import torch.nn as nn
from mmcv.cnn import ConvModule
from mmcv.runner import force_fp32
from mmdet.core import multi_apply
from ..builder import HEADS, build_loss
from .base_dense_head import BaseDenseHead
"""There are many parameters of the initialization function. Here, a simple comment is made for each parameter"""
@HEADS.register_module()
class AnchorFreeHead(BaseDenseHead, BBoxTestMixin):
"""Anchor-free head (FCOS, Fovea, RepPoints, etc.).
""" # noqa: W605
_version = 1
def __init__(self,
num_classes, # Number of detection categories (excluding background classes)
in_channels, # Enter the number of channels of the characteristic graph
feat_channels=256, # Number of channels in hidden layer
stacked_convs=4, # Number of convolution layers of detection head stack
strides=(4, 8, 16, 32, 64), # Down sampling coefficients of different scale features
dcn_on_last_conv=False, # Whether to use DCN in the last convolution layer
conv_bias='auto', # Whether the convolution layer uses bias, "auto" stands for normal_ CFG decision
loss_cls=dict( # Loss function of classification. The default value is FocalLoss
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='IoULoss', loss_weight=1.0), #The loss of border regression is IouLoss by default
conv_cfg=None,
norm_cfg=None,
train_cfg=None,
test_cfg=None,
init_cfg=dict( # Initialize configuration
type='Normal',
layer='Conv2d',
std=0.01,
override=dict(
type='Normal',
name='conv_cls',
std=0.01,
bias_prob=0.01))):
super(AnchorFreeHead, self).__init__(init_cfg)
self.num_classes = num_classes
self.cls_out_channels = num_classes
self.in_channels = in_channels
self.feat_channels = feat_channels
self.stacked_convs = stacked_convs
self.strides = strides
self.dcn_on_last_conv = dcn_on_last_conv
assert conv_bias == 'auto' or isinstance(conv_bias, bool)
self.conv_bias = conv_bias
"""Build loss function"""
self.loss_cls = build_loss(loss_cls)
self.loss_bbox = build_loss(loss_bbox)
self.train_cfg = train_cfg
self.test_cfg = test_cfg
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg
self.fp16_enabled = False
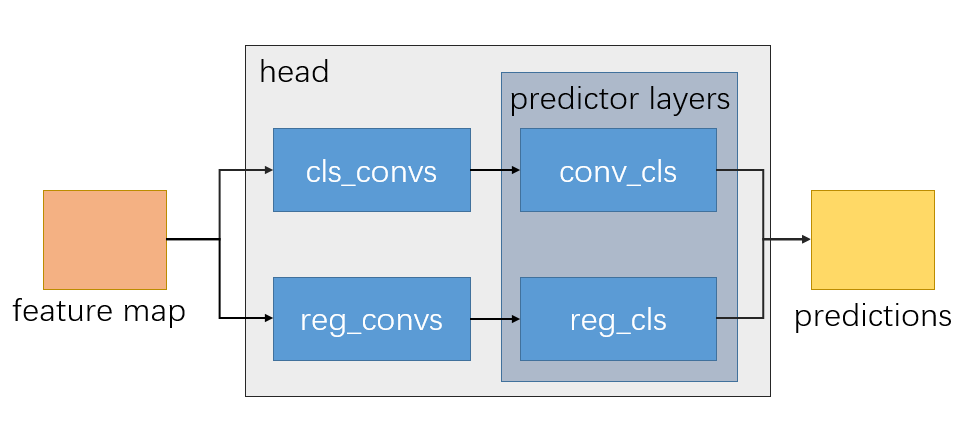
Initialize layers
self._init_layers()
def _init_layers(self):
"""Initialize each layer of the detection head."""
self._init_cls_convs()
self._init_reg_convs()
self._init_predictor()
The composition of AnchorFreeHead detection head is shown in the following figure:
Let's take a look at the initialization functions of each layer:
def _init_cls_convs(self):
"""Initialize classification volume layer."""
self.cls_convs = nn.ModuleList()
"""The number of layers of the classification part is determined by self.stacked_convs Parameter determination"""
for i in range(self.stacked_convs):
chn = self.in_channels if i == 0 else self.feat_channels
if self.dcn_on_last_conv and i == self.stacked_convs - 1:
conv_cfg = dict(type='DCNv2')
else:
conv_cfg = self.conv_cfg
"""there ConvModule yes mmcv Convolution encapsulated in-normalization-Activate the layer. The activation function is used by default ReLU"""
self.cls_convs.append(
ConvModule(
chn,
self.feat_channels,
3,
stride=1,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=self.norm_cfg,
bias=self.conv_bias))
def _init_reg_convs(self):
"""Initialization of border regression layer, code and_init_cls_convs similar."""
self.reg_convs = nn.ModuleList()
for i in range(self.stacked_convs):
chn = self.in_channels if i == 0 else self.feat_channels
if self.dcn_on_last_conv and i == self.stacked_convs - 1:
conv_cfg = dict(type='DCNv2')
else:
conv_cfg = self.conv_cfg
self.reg_convs.append(
ConvModule(
chn,
self.feat_channels,
3,
stride=1,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=self.norm_cfg,
bias=self.conv_bias))
def _init_predictor(self):
"""Initialize prediction layer."""
"""conv_cls The number of output channels is self.cls_out_channels=num_classes,This is the number of categories"""
self.conv_cls = nn.Conv2d(
self.feat_channels, self.cls_out_channels, 3, padding=1)
"""conv_reg The number of output channels is 4, corresponding to the 4 coordinate parameters of the frame"""
self.conv_reg = nn.Conv2d(self.feat_channels, 4, 3, padding=1)
See the forward propagation function again:
def forward(self, feats):
"""Forward propagation function.
Args:
feats (tuple[Tensor]): The characteristic diagram obtained from the upstream network, tuple Each of tensor Represent different
Characteristics of scale.
Returns:
tuple: It usually includes classification confidence score and bounding box prediction results.
cls_scores (list[Tensor]): For the classification prediction results of different scale feature maps, the number of feature map channels is num_points(Prediction points)*num_classes(Number of categories),That is, each category of each point is predicted.
bbox_preds (list[Tensor]): The frame offset of feature maps with different scales, and the number of channels is num_points*4
"""
"""multi_apply It can act on the input parameter function feats On each item in"""
return multi_apply(self.forward_single, feats)[:2]
def forward_single(self, x):
"""Forward propagation function for single feature layer processing.
Args:
x (Tensor): FPN feature maps of the specified stride.
Returns:
tuple: Confidence score for each category, Frame prediction, after cls_convs and reg_convs Characteristics after processing.
"""
cls_feat = x
reg_feat = x
"""The classification confidence is obtained"""
for cls_layer in self.cls_convs:
cls_feat = cls_layer(cls_feat)
cls_score = self.conv_cls(cls_feat)
"""Get border prediction"""
for reg_layer in self.reg_convs:
reg_feat = reg_layer(reg_feat)
bbox_pred = self.conv_reg(reg_feat)
return cls_score, bbox_pred, cls_feat, reg_feat
You can see that the forward propagation process of AnchorFreeHead is relatively simple. Let's take a look at the calculation of loss function and the processing of test results:
"""loss It is an abstract class method, which means that the specific model needs to define its own loss function"""
@abstractmethod
@force_fp32(apply_to=('cls_scores', 'bbox_preds'))
def loss(self,
cls_scores,
bbox_preds,
gt_bboxes,
gt_labels,
img_metas,
gt_bboxes_ignore=None):
"""Calculate the loss function of the detection head.
Args:
cls_scores (list[Tensor]): Classification and prediction results for different scale feature maps.
bbox_preds (list[Tensor]): Frame prediction results for different scale feature maps.
gt_bboxes (list[Tensor]): True value of the bounding box of the target to be detected.
gt_labels (list[Tensor]): Category true value of each border
img_metas (list[dict]): Meta information of each image, e.g.,
image size, scaling factor, etc.
gt_bboxes_ignore (None | list[Tensor]): specify which bounding
boxes can be ignored when computing the loss.
"""
raise NotImplementedError
@abstractmethod
@force_fp32(apply_to=('cls_scores', 'bbox_preds'))
def get_bboxes(self,
cls_scores,
bbox_preds,
img_metas,
cfg=None,
rescale=None):
"""This function is in BaseDenseHead I've seen it in. It's also an abstract method. I won't repeat it.
"""
raise NotImplementedError
@abstractmethod
def get_targets(self, points, gt_bboxes_list, gt_labels_list):
"""Calculate the prediction objectives of classification, regression and other tasks(target),For calculation of loss function.
Args:
points (list[Tensor]): The anchor point of each layer of the feature pyramid, and each item in the list is(num_points,2).
gt_bboxes_list (list[Tensor]): Real border information,
The shape of each item is (num_gt, 4).
gt_labels_list (list[Tensor]): True category label for the border,
The shape of each item is (num_gt,).
"""
raise NotImplementedError
Because the Anchor box is not used in the anchor freehead, we generally use the anchor point as the anchor point to calculate the target value to be predicted, and then calculate the loss function and get the predicted frame. Anchor points are generated as follows:
def _get_points_single(self,
featmap_size,
stride,
dtype,
device,
flatten=False):
"""Obtain the location point of single scale feature map."""
h, w = featmap_size
"""generate x,y Coordinates of dimensions, and each feature map point is set as a positioning point"""
x_range = torch.arange(w, device=device).to(dtype)
y_range = torch.arange(h, device=device).to(dtype)
"""use meshgrid Function to generate 2D coordinates"""
y, x = torch.meshgrid(y_range, x_range)
"""Expand to one-dimensional vector"""
if flatten:
y = y.flatten()
x = x.flatten()
return y, x
def get_points(self, featmap_sizes, dtype, device, flatten=False):
"""Generate anchor points for multi-scale feature map.
Args:
featmap_sizes (list[tuple]): Size of multiscale feature map.
dtype (torch.dtype): data type.
device (torch.device): Computing hardware(cpu or gpu).
Returns:
tuple: Location point of each feature map.
"""
mlvl_points = []
for i in range(len(featmap_sizes)):
mlvl_points.append(
self._get_points_single(featmap_sizes[i], self.strides[i],
dtype, device, flatten))
return mlvl_points
Here is an example to briefly introduce torch Usage of meshgrid() function:
import torch
""" meshgrid The function is used to generate multi-dimensional coordinate points
"""
w = 5
h = 5
x_range = torch.arange(w)
y_range = torch.arange(h)
y,x = torch.meshgrid(y_range,x_range)
print(y)
"""
results:
Generated 5 X5 Two dimensional coordinates of, tensor y Representing each point y Coordinate value
tensor([[0, 0, 0, 0, 0],
[1, 1, 1, 1, 1],
[2, 2, 2, 2, 2],
[3, 3, 3, 3, 3],
[4, 4, 4, 4, 4]])
"""
To summarize several components of AnchorFreeHead:
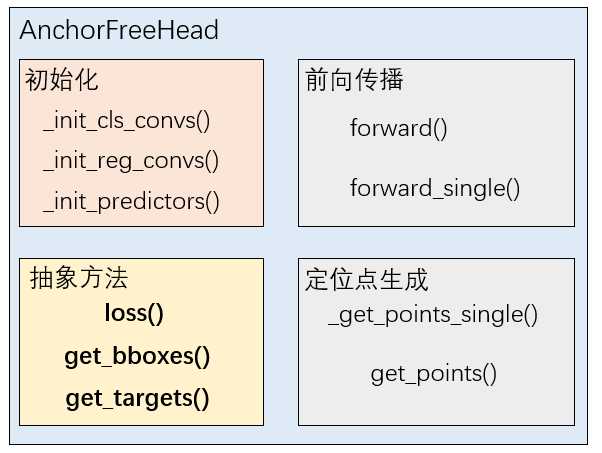
FCOSHead
The code part of FCOSHead will be explained below, which will involve the details of FCOS model construction. Interested students can take a look at the article first.
initialization
First see the initialization part of FCOSHead:
@HEADS.register_module()
class FCOSHead(AnchorFreeHead):
def __init__(self,
num_classes,# Number of categories (excluding background)
in_channels, # Enter the number of channels of the characteristic graph
regress_ranges=((-1, 64), (64, 128), (128, 256), (256, 512),
(512, INF)), # Regression range of multi-scale positioning points (in fact, the regression of a certain point is limited to a certain layer)
center_sampling=False,
center_sample_radius=1.5,
norm_on_bbox=False,
centerness_on_reg=False,
loss_cls=dict( # Classified loss, default to Focal Loss
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='IoULoss', loss_weight=1.0),# Regression loss
loss_centerness=dict( # Center forecast loss
type='CrossEntropyLoss',
use_sigmoid=True,
loss_weight=1.0),
norm_cfg=dict(type='GN', num_groups=32, requires_grad=True),
init_cfg=dict(
type='Normal',
layer='Conv2d',
std=0.01,
override=dict(
type='Normal',
name='conv_cls',
std=0.01,
bias_prob=0.01)),
**kwargs):
self.regress_ranges = regress_ranges
self.center_sampling = center_sampling
self.center_sample_radius = center_sample_radius
self.norm_on_bbox = norm_on_bbox
self.centerness_on_reg = centerness_on_reg
super().__init__(
num_classes,
in_channels,
loss_cls=loss_cls,
loss_bbox=loss_bbox,
norm_cfg=norm_cfg,
init_cfg=init_cfg,
**kwargs)
self.loss_centerness = build_loss(loss_centerness) #Build central forecast loss function
def _init_layers(self):
"""Initialize layers.
Call the parent class first AnchorFreeHead Initialization function, get self.conv_cls,self.conv_reg, self.cls_convs,
self.reg_convs, self.loss_cls, self.loss_bbox Equal network and loss function components
"""
super()._init_layers()
"""One layer convolution is used to predict the central probability value"""
self.conv_centerness = nn.Conv2d(self.feat_channels, 1, 3, padding=1)
self.scales = nn.ModuleList([Scale(1.0) for _ in self.strides])
Forward propagation
See forward propagation again:
def forward(self, feats):
"""Forward propagation.
"""
return multi_apply(self.forward_single, feats, self.scales,
self.strides)
def forward_single(self, x, scale, stride):
"""Forward propagation of single scale feature map.
"""
"""Here, we first use the forward propagation function of the parent class to obtain cls_score, bbox_pred, cls_feat, reg_feat"""
cls_score, bbox_pred, cls_feat, reg_feat = super().forward_single(x)
"""According to the parameter, specify which characteristic graph is used to predict the central probability value"""
if self.centerness_on_reg:
centerness = self.conv_centerness(reg_feat)
else:
centerness = self.conv_centerness(cls_feat)
# scale the bbox_pred of different level
# float to avoid overflow when enabling FP16
bbox_pred = scale(bbox_pred).float()
"""because bbox_pred Are theoretically nonnegative, so use ReLU perhaps exp Keep nonnegative"""
if self.norm_on_bbox:
bbox_pred = F.relu(bbox_pred)
if not self.training:
bbox_pred *= stride
else:
bbox_pred = bbox_pred.exp()
"""Return classification score,Frame prediction and center value prediction"""
return cls_score, bbox_pred, centerness
Generation of prediction target
The loss function measures the difference between the predicted value and the real value:
L
=
(
p
r
e
d
,
t
a
r
g
e
t
)
L = (pred,target)
L=(pred,target)
For classification tasks, the real value is the category label to which the target belongs. However, for border regression, different models usually return to different targets, and the target is related to the scale, which is also one of the biggest difficulties in detecting model coding.
FCOS directly predicts the positioning points on the feature map. Let's first look at how FCOSHead generates positioning points:
def _get_points_single(self,
featmap_size,
stride,
dtype,
device,
flatten=False):
"""Call the parent class first AnchorFreeHead Generating basis points for functions"""
y, x = super()._get_points_single(featmap_size, stride, dtype, device)
"""Stack the coordinates of the two dimensions together, and points The shape of the is(h*w,2),And use stride The information is converted to a center point and mapped to
In the original image.
"""
points = torch.stack((x.reshape(-1) * stride, y.reshape(-1) * stride),
dim=-1) + stride // 2
return points
The function of this function can be clearly shown in a figure:

Then see_ get_target_single() function:
def _get_target_single(self, gt_bboxes, gt_labels, points, regress_ranges,
num_points_per_lvl):
"""It is a single picture (note that it is a single picture, consider batch_size,(not a single scale feature map).
Feature maps with different scales have different numbers of feature points, which will naturally generate different numbers of positioning points. Here we use num_points1,num_points2,
...,num_points5 To represent(Diminishing). Record and for sum_points=num_points1 + num_points2 +...+num_points5
Args:
gt_bboxes(Tensor): Shape is(num_gts,4)
gt_labels(Tensor): Shape is(num_gts,)
points(Tensor): Points of all scale feature maps,Shape is(sum_points,2)
regress_ranges(Tensor):The regression range corresponding to the points of all scale characteristic maps has the same shape points
num_points_per_level()
"""
num_points = points.size(0)
num_gts = gt_labels.size(0)
"""If not gt_bboxes,Return 0 value"""
if num_gts == 0:
return gt_labels.new_full((num_points,), self.num_classes), \
gt_bboxes.new_zeros((num_points, 4))
"""calculation gt_bboxes Area of"""
areas = (gt_bboxes[:, 2] - gt_bboxes[:, 0]) * (
gt_bboxes[:, 3] - gt_bboxes[:, 1])
# TODO: figure out why these two are different
# areas = areas[None].expand(num_points, num_gts)
"""take areas Expand,areas[None]Indicates adding a dimension at the beginning,After this step is completed areas The shape of the is(num_points,num_gts)"""
areas = areas[None].repeat(num_points, 1)
"""take regress_ranges The final dimension is(num_points,num_gts,2)"""
regress_ranges = regress_ranges[:, None, :].expand(
num_points, num_gts, 2)
"""take gt_bboxes Expand, and the final dimension is(num_points,num_gts,4)"""
gt_bboxes = gt_bboxes[None].expand(num_points, num_gts, 4)
"""Gets the of the generated anchor point x,y Coordinates and expand them into shapes(num_points,num_gts)"""
xs, ys = points[:, 0], points[:, 1]
xs = xs[:, None].expand(num_points, num_gts)
ys = ys[:, None].expand(num_points, num_gts)
"""Get each build point for each gt_bbox Return target
Here we explain why the first two dimensions of each tensor are extended to(num_points,num_gts),Just to make everyone
Generate anchor points with each gt_boox Calculate the regression error, and then allocate the regression task
Here is the center point to gt_bbox The difference between up, down, left and right.
"""
left = xs - gt_bboxes[..., 0]
right = gt_bboxes[..., 2] - xs
top = ys - gt_bboxes[..., 1]
bottom = gt_bboxes[..., 3] - ys
"""Combine the regression objectives of the four dimensions, pay attention to stack The function increases the dimension, dim=-1 Resulting in the final
bbox_targets Shape is(num_points,num_gts,4),That is, each point to each gt_bbox Intensive computing
"""
bbox_targets = torch.stack((left, top, right, bottom), -1)
"""What will be decided next bbox_targets It can be used as a positive sample for training"""
"""1.If center_sampling==True,That is, from the center point radius*stride The range of is sampled (i.e. near the center point), and the sample in it is regarded as a positive sample"""
if self.center_sampling:
# condition1: inside a `center bbox`
"""The default radius here is 1.5"""
radius = self.center_sample_radius
"""calculation gt_bbox The center point of the, center_xs,center_ys All shapes are(num_points,num_gts)"""
center_xs = (gt_bboxes[..., 0] + gt_bboxes[..., 2]) / 2
center_ys = (gt_bboxes[..., 1] + gt_bboxes[..., 3]) / 2
center_gts = torch.zeros_like(gt_bboxes)
stride = center_xs.new_zeros(center_xs.shape)
"""The points on different scale feature maps are projected to the original size"""
lvl_begin = 0
for lvl_idx, num_points_lvl in enumerate(num_points_per_lvl):
lvl_end = lvl_begin + num_points_lvl
"""Replace the original stride Extension 1.5 times"""
stride[lvl_begin:lvl_end] = self.strides[lvl_idx] * radius
lvl_begin = lvl_end
"""According to the center point and stride Determine the selection range of positive samples( xmin,ymin,xmax,ymax)"""
x_mins = center_xs - stride
y_mins = center_ys - stride
x_maxs = center_xs + stride
y_maxs = center_ys + stride
"""torch.where(condition,a,b),The position where the condition holds is a Value, which is not valid b value.
The function of the four codes here is to keep the positive sample points satisfying two conditions at the same time:
1. Within the central sampling range:( xmin,ymin,xmax,ymax)
2. stay gt_bboxes Within the scope of: gt_bboxes
So it will be x_mins and gt_bbox[0]Take the maximum value at x_max and gt_bbox[2]Whichever is the minimum
"""
center_gts[..., 0] = torch.where(x_mins > gt_bboxes[..., 0],
x_mins, gt_bboxes[..., 0])
center_gts[..., 1] = torch.where(y_mins > gt_bboxes[..., 1],
y_mins, gt_bboxes[..., 1])
center_gts[..., 2] = torch.where(x_maxs > gt_bboxes[..., 2],
gt_bboxes[..., 2], x_maxs)
center_gts[..., 3] = torch.where(y_maxs > gt_bboxes[..., 3],
gt_bboxes[..., 3], y_maxs)
"""Finally get center_gts Shape is(num_points,num_gts,4),Its meaning is to stipulate the right to participate in the return
Positive sample range
"""
cb_dist_left = xs - center_gts[..., 0]
cb_dist_right = center_gts[..., 2] - xs
cb_dist_top = ys - center_gts[..., 1]
cb_dist_bottom = center_gts[..., 3] - ys
center_bbox = torch.stack(
(cb_dist_left, cb_dist_top, cb_dist_right, cb_dist_bottom), -1)
"""Only with center_gts The point in its mask Just right"""
inside_gt_bbox_mask = center_bbox.min(-1)[0] > 0
else:
"""If center_sampling=False,Simply put gt_bbox The points in are regarded as positive sample points"""
inside_gt_bbox_mask = bbox_targets.min(-1)[0] > 0
"""Calculate the maximum to be regressed target,And according to ranges exclude"""
max_regress_distance = bbox_targets.max(-1)[0]
inside_regress_range = (
(max_regress_distance >= regress_ranges[..., 0])
& (max_regress_distance <= regress_ranges[..., 1]))
"""Will not be gt_bbox Corresponding to the point in area Set to maximum"""
areas[inside_gt_bbox_mask == 0] = INF
areas[inside_regress_range == 0] = INF
"""If a point still corresponds to multiple points gt_bbox,Then select gt_bbox The smallest area is used as the regression target"""
"""min_area_inds The shape of the is(num_points,),Where the elements represent gt_bbox Label for,num_pos_points express
Number of positive samples.
"""
min_area, min_area_inds = areas.min(dim=1)
labels = gt_labels[min_area_inds]
"""Will not correspond to any of the previous gt_bbox The point is set as the background sample point"""
labels[min_area == INF] = self.num_classes # set as BG
"""here range(num_points) and min_area_inds Equal length, indicating each point Select at most one gt_bbox"""
bbox_targets = bbox_targets[range(num_points), min_area_inds]
"""Final return value:
labels(Tensor):shape (num_points,)
bbox_targets(Tensor): (num_points,4)
"""
return labels, bbox_targets
As you can see_ get_ target_ The single function is used to select qualified positive sample points for a single picture, and calculate the objectives of classification and regression for the calculation of subsequent loss function.
See get again below_ Targets function:
def get_targets(,self, points, gt_bboxes_list, gt_labels_list):
"""Calculation of classification, regression and center value prediction for multiple images target
Args:
points (list[Tensor]): Anchor point of each feature layer, list(Tensor(num_points,2))
gt_bboxes_list (list[Tensor]): each Tensor The shape of the is (num_gt, 4).
gt_labels_list (list[Tensor]):each Tensor The shape of the is (num_gt, ).
Returns:
tuple:
concat_lvl_labels (list[Tensor]):. \
concat_lvl_bbox_targets (list[Tensor]): BBox targets of each \
level.
"""
assert len(points) == len(self.regress_ranges)
num_levels = len(points)
"""take regress_ranges Extension, and points Align shapes"""
expanded_regress_ranges = [
points[i].new_tensor(self.regress_ranges[i])[None].expand_as(
points[i]) for i in range(num_levels)
]
"""Here will be all regress_ranges and points Connect with just_get_targets_single Function correspondence.
concat_points Shape is(h1*w1+h2*w2+...+h5*w5,4)"""
concat_regress_ranges = torch.cat(expanded_regress_ranges, dim=0)
concat_points = torch.cat(points, dim=0)
"""Count the number of anchor points on each floor"""
num_points = [center.size(0) for center in points]
"""Generate for each picture labels(shape (num_all_points,))and bbox_targets(num_all_points,4),
And form two list"""
labels_list, bbox_targets_list = multi_apply(
self._get_target_single,
gt_bboxes_list,
gt_labels_list,
points=concat_points,
regress_ranges=concat_regress_ranges,
num_points_per_lvl=num_points)
"""here num_points It is a list in which elements generate positioning points for each layer. The following operation will each picture
Medium points According to different level Separate, equivalent to torch.split(labels,[num_lvl1,num_lvl2,...,num_lvl5],dim=0)
"""
labels_list = [labels.split(num_points, 0) for labels in labels_list]
bbox_targets_list = [
bbox_targets.split(num_points, 0)
for bbox_targets in bbox_targets_list
]
"""Different pictures are the same level of label and bbox_target Connect"""
concat_lvl_labels = []
concat_lvl_bbox_targets = []
for i in range(num_levels):
"""concat_lvl_labels Medium Tensor Shape is(num_points_leveli*num_imgs,)
concat_lvl_bbox_targets in Tensor Shape is(num_points_leveli*num_imgs,4)
"""
concat_lvl_labels.append(
torch.cat([labels[i] for labels in labels_list]))
bbox_targets = torch.cat(
[bbox_targets[i] for bbox_targets in bbox_targets_list])
if self.norm_on_bbox:
bbox_targets = bbox_targets / self.strides[i]
concat_lvl_bbox_targets.append(bbox_targets)
"""Finally, two lists are returned. The first dimension in the list represents different dimensions level Not different pictures"""
return concat_lvl_labels, concat_lvl_bbox_targets
So far, we have generated targets for classification and regression, but don't forget that FCOS also has a Centerness prediction branch, which is mainly responsible for measuring anchor points and GT_ The offset of the bbox center, which also needs to generate the target:
def centerness_target(self, pos_bbox_targets):
"""
Args:
pos_bbox_targets(Tensor):Only the center offset of the positive sample is calculated,shape (num_pos_bbox,4)
"""
left_right = pos_bbox_targets[:, [0, 2]]
top_bottom = pos_bbox_targets[:, [1, 3]]
if len(left_right) == 0:
centerness_targets = left_right[..., 0]
else:
centerness_targets = (
left_right.min(dim=-1)[0] / left_right.max(dim=-1)[0]) * (
top_bottom.min(dim=-1)[0] / top_bottom.max(dim=-1)[0])
"""The returned shape is(num_pos_bbox,)"""
return torch.sqrt(centerness_targets)
The centerness metric is calculated as follows:
l
∗
=
r
∗
,
t
∗
=
b
∗
l^*=r^*,t^*=b^*
When l * = r *, t * = b *, that is, when the point is just in the center, centrness = 1.
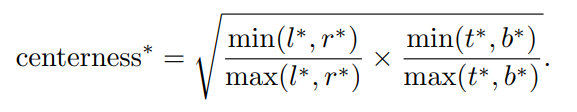
Calculation of loss
def loss(self,
cls_scores,
bbox_preds,
centernesses,
gt_bboxes,
gt_labels,
img_metas,
gt_bboxes_ignore=None):
"""calculation bbox_head Loss function of.
Args:
cls_scores (list[Tensor]): each level Category confidence score,
every last Tensor The character of is(B,num_points*num_class,H,W).
bbox_preds (list[Tensor]): every last level Border offset for, Tensor Shape is(B,num_points*4,H,W)
centernesses (list[Tensor]): every last level of"Centrality"forecast, The shape of each is(B,num_points,H,W).
gt_bboxes (list[Tensor]): The real target bounding box of each picture, shape (num_gts,4),(xmin,ymin,xmax,ymax)format.
gt_labels (list[Tensor]): each gt_bbox Category label for, shape (num_gts,)
Returns:
dict[str, Tensor]:Returns a dictionary containing each loss function.
"""
assert len(cls_scores) == len(bbox_preds) == len(centernesses)
"""size()[-2:] Representation fetch H,W,Here is the size of the feature map at each scale level"""
featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
"""Generate anchor points"""
all_level_points = self.get_points(featmap_sizes, bbox_preds[0].dtype,
bbox_preds[0].device)
"""The prediction target is generated according to the positioning point and the real label labels and bbox_targets All are lists. The first dimension in the list represents different dimensions
Characteristic scale.
"""
labels, bbox_targets = self.get_targets(all_level_points, gt_bboxes,
gt_labels)
"""Count the number of pictures to be processed at the same time, that is batch_size"""
num_imgs = cls_scores[0].size(0)
"""
Here with flatten_cls_score As an example, when calculating the loss function, 4 D of Tensor They are not suitable for calculation, so they need to be expanded first.
stay cls_scores Each of the cls_score Represents a level in conv_cls The category prediction results obtained,
shape = (B,num_points(1)*num_classes,H,W). use first permute(0,2,3,1)j Change shape to(B,H,W,num_classes),
Then continue reshape(-1,self.cls_out_channels),The final shape is(H*W*num_classes,self.cls_out_channels),that is
The prediction results of each point are arranged linearly
flatten_bbox_preds,flatten_centerness The treatment of is the same.
"""
flatten_cls_scores = [
cls_score.permute(0, 2, 3, 1).reshape(-1, self.cls_out_channels)
for cls_score in cls_scores
]
flatten_bbox_preds = [
bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)
for bbox_pred in bbox_preds
]
flatten_centerness = [
centerness.permute(0, 2, 3, 1).reshape(-1)
for centerness in centernesses
]
"""After splitting, all labels and target All connected at this time Tensor Equal length"""
flatten_cls_scores = torch.cat(flatten_cls_scores)
flatten_bbox_preds = torch.cat(flatten_bbox_preds)
flatten_centerness = torch.cat(flatten_centerness)
flatten_labels = torch.cat(labels)
flatten_bbox_targets = torch.cat(bbox_targets)
"""The anchor points are also expanded and expanded to generate the final frame prediction results"""
flatten_points = torch.cat(
[points.repeat(num_imgs, 1) for points in all_level_points])
"""Foreground (target) category range: [0, num_classes -1], Background category label: num_classes"""
bg_class_ind = self.num_classes
"""Tensor.nonzero()Get a non-zero index, here pos_inds Refers to the index value of the correction sample"""
pos_inds = ((flatten_labels >= 0)
& (flatten_labels < bg_class_ind)).nonzero().reshape(-1)
num_pos = torch.tensor(
len(pos_inds), dtype=torch.float, device=bbox_preds[0].device)
num_pos = max(reduce_mean(num_pos), 1.0)
"""Calculate the loss function of the classification"""
loss_cls = self.loss_cls(
flatten_cls_scores, flatten_labels, avg_factor=num_pos)
"""For frame regression and centrality prediction, the loss function is calculated only for positive samples"""
pos_bbox_preds = flatten_bbox_preds[pos_inds]
pos_centerness = flatten_centerness[pos_inds]
pos_bbox_targets = flatten_bbox_targets[pos_inds]
pos_centerness_targets = self.centerness_target(pos_bbox_targets)
# centerness weighted iou loss
centerness_denorm = max(
reduce_mean(pos_centerness_targets.sum().detach()), 1e-6)
if len(pos_inds) > 0:
pos_points = flatten_points[pos_inds]
"""because IOU Loss Two borders need to be calculated IOU,So first bbox delta Decode to frame for calculation"""
pos_decoded_bbox_preds = distance2bbox(pos_points, pos_bbox_preds)
pos_decoded_target_preds = distance2bbox(pos_points,
pos_bbox_targets)
loss_bbox = self.loss_bbox(
pos_decoded_bbox_preds,
pos_decoded_target_preds,
weight=pos_centerness_targets,
avg_factor=centerness_denorm)
loss_centerness = self.loss_centerness(
pos_centerness, pos_centerness_targets, avg_factor=num_pos)
else:
loss_bbox = pos_bbox_preds.sum()
loss_centerness = pos_centerness.sum()
"""Final return loss function dictionary"""
return dict(
loss_cls=loss_cls,
loss_bbox=loss_bbox,
loss_centerness=loss_centerness)
Summary
Summarize the training process with a chart:

In addition to the above, FCOSHead also contains_ get_bbox() and other methods are used to generate the final border. There is no key description here. Interested students can see the code by themselves~
summary
This chapter explains in great detail the code construction and operation process of FCOS method, including the overall structure of the model, the generation of prediction target value and the calculation of loss function. Here, I admire the code contributors of mmdetection, who split the model very clearly, and it's not difficult to understand when you look at it carefully. That's all for the study of this chapter. Students with questions can leave a message in the comment area~