----Then day04 notes continue editing-----
3.2 external table:
Description of external table:
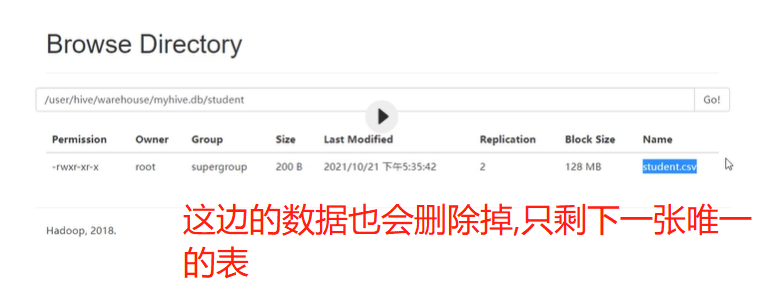
Because the external table loads the data of other hdfs paths into the table, the hive table will think that it does not completely monopolize the data. Therefore, when deleting the hive table, the data is still stored in hdfs and will not be deleted.
Internal table: when deleting a table, the table structure and table data will be deleted.
External table: when deleting a table, it is considered that the data of the table will be used by others, and you do not have the right to exclusive data, so only the table structure (metadata) will be deleted, and the data of the table will not be deleted.
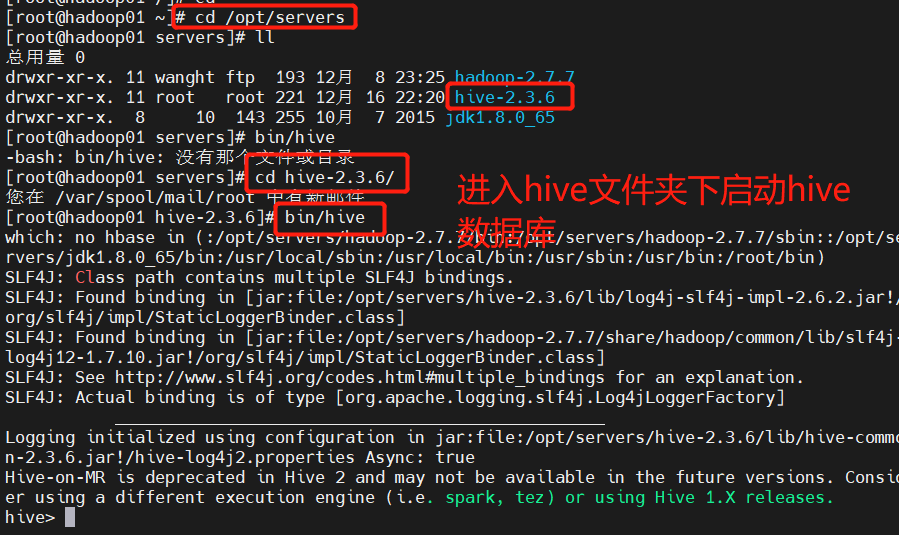
Operation case:
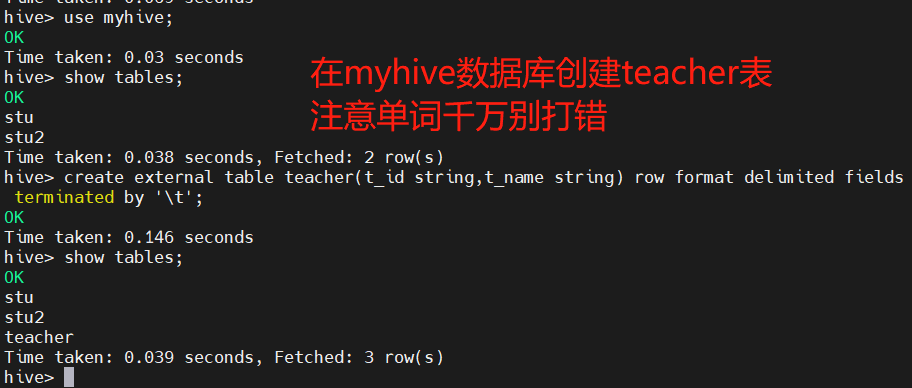
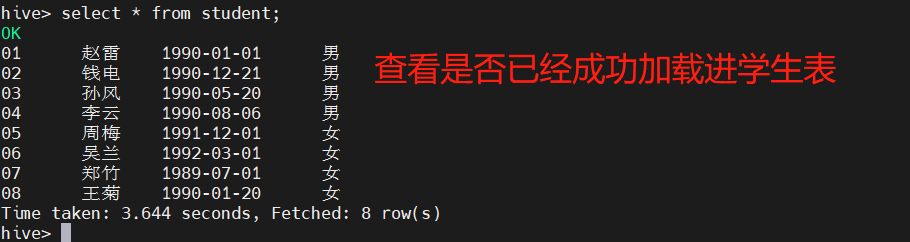
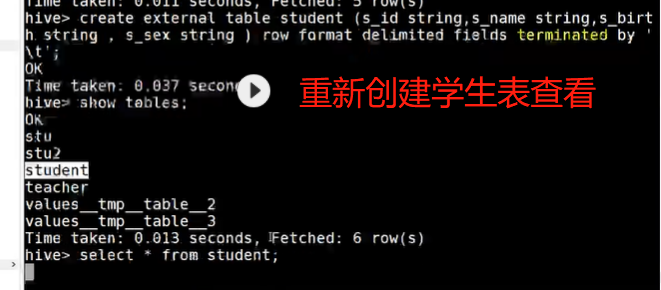
Create external tables of teacher and student tables respectively, and load data into the tables
Create teacher table:
create external table teacher (t_id string,t_name string) row format delimited fields terminated by '\t';
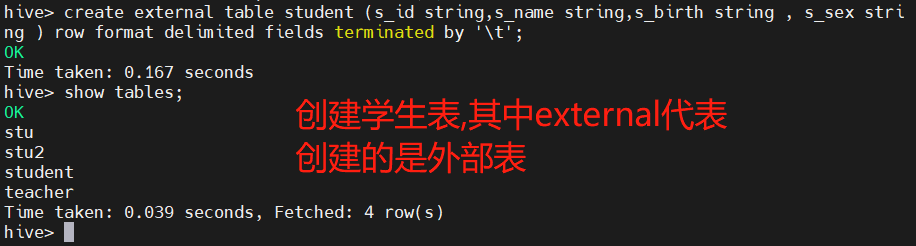
Create student table:
create external table student (s_id string,s_name string,s_birth string , s_sex string ) row format delimited fields terminated by '\t';
There are two ways to load data into a table:
The first is to load data from the local file system into the table
load data local inpath '/opt/servers/hivedatas/student.csv' into table student;
Load data and overwrite existing data
load data local inpath '/opt/servers/hivedatas/student.csv' overwrite into table student;
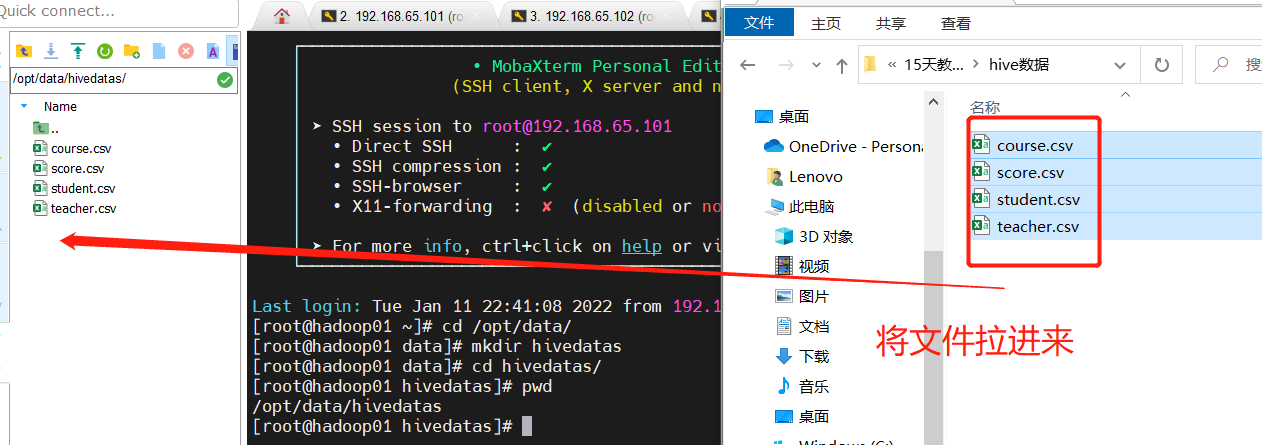
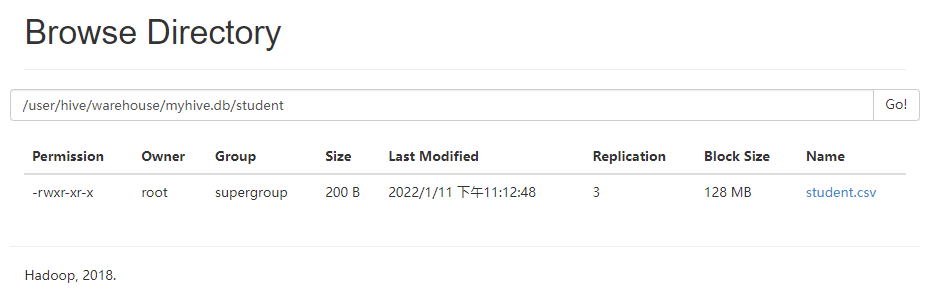
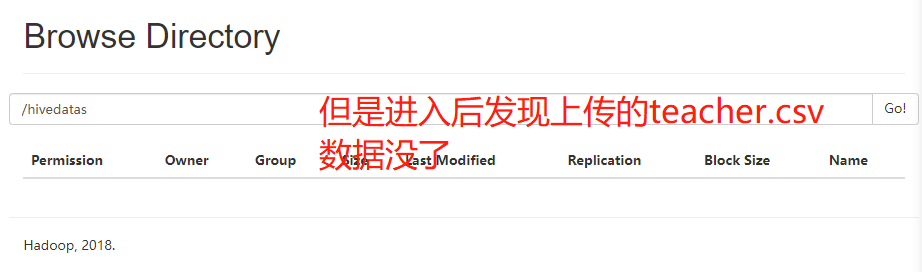
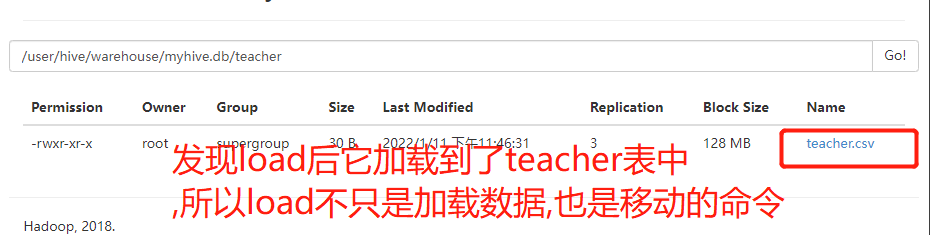
The second is to load data from the hdfs file system into the table (you need to upload the data to the hdfs file system in advance, which is actually an operation of moving files)
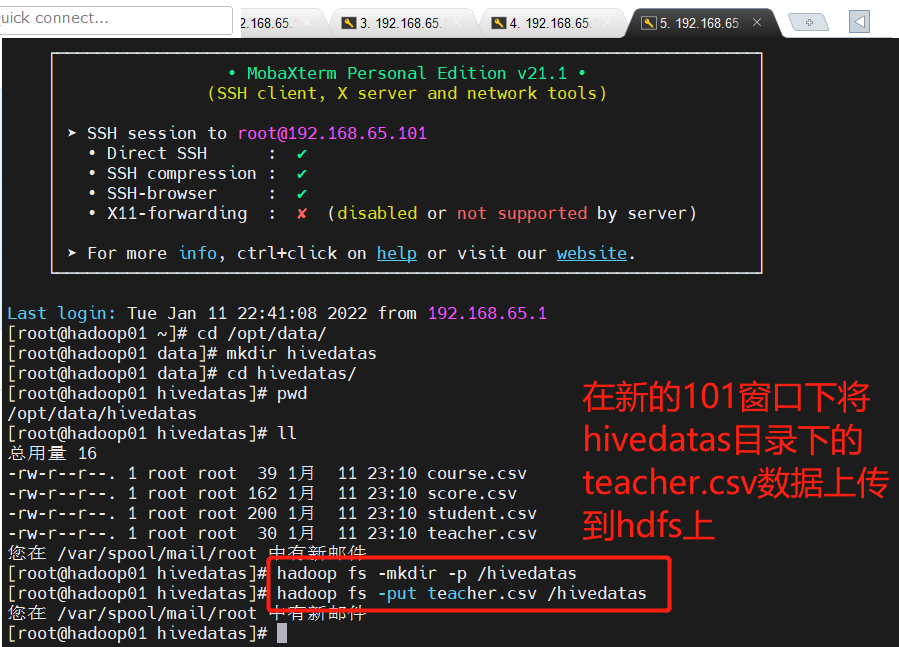
cd /opt/servers/hivedatas hdfs dfs -mkdir -p /hivedatas hdfs dfs -put teacher.csv /hivedatas/ load data inpath '/hivedatas/teacher.csv' into table teacher;
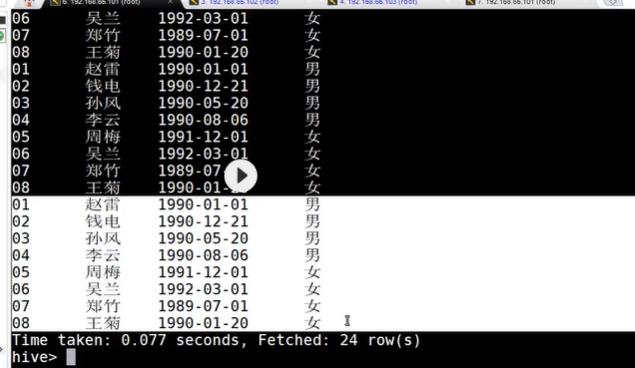
If the student table is deleted, the data in hdfs still exists, and after the table is re created, the data in the table will exist directly, because our student table uses an external table. After the drop table, the data in the table will still remain on hdfs.
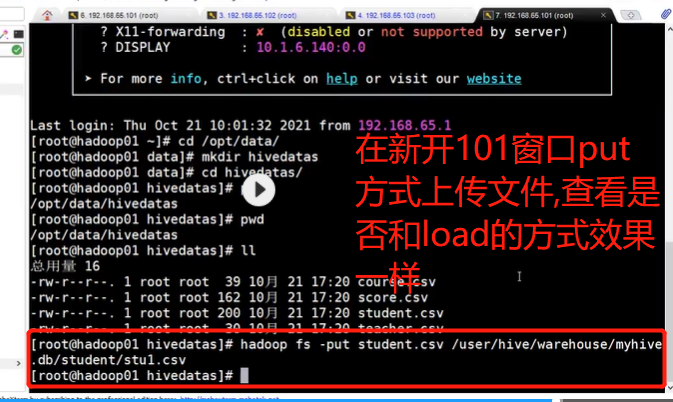
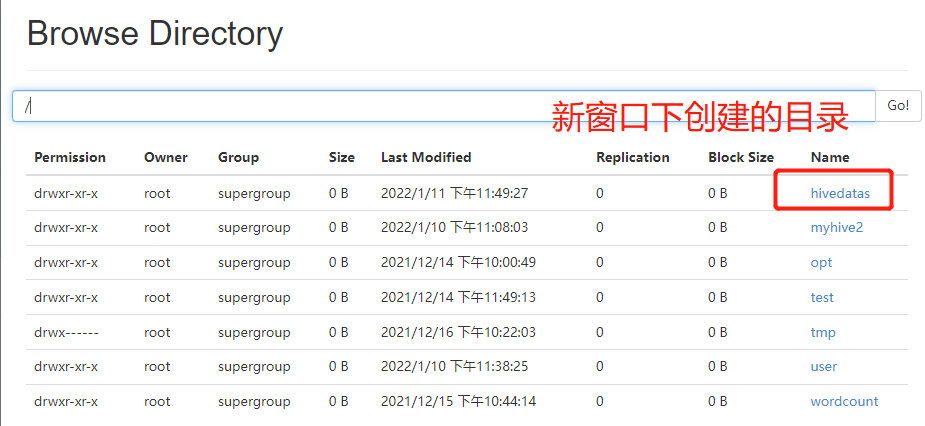
Upload data in a new window

The first method: load data from local files into the table

For testing, the following operations can be omitted:




Note: if the first load method loads data, it will not detect whether the data is repeated, but directly load it into the table, and will copy the same table in the database

Therefore, if we want to overwrite the previous data, we need to add a keyword "overwrite" in the command to load data

The second way is to load data from the hdfs file system into the table (you need to upload the data to the hdfs file system in advance, which is actually an operation of moving files) -- upload the teacher data

3.3 zoning table
In big data, the most commonly used idea is divide and conquer. We can cut large files into small files one by one, so it will be easy to operate a small file each time. Similarly, hive also supports this idea, that is, we can cut big data into small files one by one every day or every hour, In this way, it will be much easier to operate small files
- Create partition table syntax
create table score(s_id string,c_id string, s_score int) partitioned by (month string) row format delimited fields terminated by '\t';
- Create a watch band with multiple partitions
create table score2 (s_id string,c_id string, s_score int) partitioned by (year string,month string,day string) row format delimited fields terminated by '\t';
- Load data into partitioned table
load data local inpath '/opt/servers/hivedatas/score.csv' into table score partition (month='201806');
- Load data into a multi partition table
load data local inpath '/opt/servers/hivedatas/score.csv' into table score2 partition(year='2018',month='06',day='01');
- View partition
show partitions score;
- Add a partition
alter table score add partition(month='201805');
Add multiple partitions at the same time
alter table score add partition(month='201804') partition(month = '201803');
Note: after adding partitions, you can see that there is an additional folder under the table in the hdfs file system
- delete a partition
alter table score drop partition(month = '201806');
3.4 barrel separation table
Divide the data into multiple buckets according to the specified fields. In other words, divide the data according to the fields. You can divide the data into multiple files according to the fields
Turn on hive's bucket list function
set hive.enforce.bucketing=true;
Set the number of reduce
set mapreduce.job.reduces=3;
Create pass through table
create table course (c_id string,c_name string,t_id string) clustered by(c_id) into 3 buckets row format delimited fields terminated by '\t';
The data loading of the bucket table can only be overwritten through insert because it is difficult to load the data of the bucket table through the hdfs dfs -put file or load data
Create a common table, and load the data of the common table into the bucket table by inserting overwrite
To create a normal table:
create table course_common (c_id string,c_name string,t_id string) row format delimited fields terminated by '\t';
Load data in normal table
load data local inpath '/opt/servers/hivedatas/course.csv' into table course_common;
Load data into the bucket table through insert overwrite
insert overwrite table course select * from course_common cluster by(c_id);
Sampling by percentage: 30% of the data in the whole table
select * from course tablesample(30 percent);
4.hive query method
4.1select
Full table query
select * from score;
Select a specific column query
select s_id ,c_id from score;
Column alias
1) Rename a column.
2) Easy to calculate.
3) Immediately following the column name, you can also add the keyword 'AS' between the column name and alias
select s_id as myid ,c_id from score;
4.2 common functions
1) Find the total number of rows (count)
select count(1) from score;
2) Find the maximum value of the fraction (max)
select max(s_score) from score;
3) Find the minimum value of the score (min)
select min(s_score) from score;
4) Sum the scores (sum)
select sum(s_score) from score;
5) Average the scores (avg)
select avg(s_score) from score;
4.3. LIMIT statement
A typical query returns multiple rows of data. The LIMIT clause is used to LIMIT the number of rows returned.
select * from score limit 3;
4.4 WHERE statement
select * from score where s_score > 60;
4.5 grouping
GROUP BY statement
The GROUP BY statement is usually used with an aggregate function to group one or more queued results, and then aggregate each group.
Case practice:
(1) Calculate the average score of each student
select s_id ,avg(s_score) from score group by s_id;
(2) Calculate the maximum score of each student
select s_id ,max(s_score) from score group by s_id;
HAVING statement
1) Differences between having and where
(1) where functions for the columns in the table and queries the data; having plays a role in filtering data for columns in query results.
(2) Grouping functions cannot be written after where, but can be used after having.
(3) having is only used for group by group statistics statements.
2) Case practice:
Find the average score of each student
select s_id ,avg(s_score) from score group by s_id;
Ask each student whose average score is greater than 85
select s_id ,avg(s_score) avgscore from score group by s_id having avgscore > 85;
5.hive's FAQ
Are all offline data processing scenarios applicable to hive?
Not all scenarios are suitable. Hive has greater advantages in scenarios with simple logic and requiring fast results. However, when the business logic is very complex, it is still necessary to develop MapReduce programs to be more direct and effective.
Can Hive be used as the database of the business system?
No. The traditional database is required to provide the system with real-time addition, deletion, modification and query, while Hive does not support row level addition, deletion and modification, and the query speed is not higher than that of the traditional relational database, but the higher throughput, so it can not be used as a relational database.
Can Hive improve operation efficiency compared with traditional MR data processing?
Hive needs to compile HQL into MR to run, so its execution efficiency is lower than that of directly running MR program. However, for us, because we only need to write and debug HQL without developing and debugging complex MR programs, the work efficiency can be greatly improved.
Why doesn't Hive support row level addition, deletion and modification?
Hive does not support row level addition, deletion and modification. The fundamental reason is that its underlying HDFS does not support it. In HDFS, if you add, delete or modify a section or a line of the whole file, it will inevitably affect the storage layout of the whole file in the cluster. The data in the whole cluster needs to be summarized, re segmented, re sent to each node and backed up. This situation is not worth the loss. So the design pattern of HDFS makes him not suitable for this