I usually read blogs or learn knowledge. What I learned is scattered. There is no independent concept of knowledge module, and it is easy to forget after learning. So I set up my own Note warehouse (a note warehouse I maintain for a long time. If I'm interested, I can click a star ~ your star is a great driving force for my writing). Classify and put everything I usually learn in it. It's also convenient to review when necessary.
kotlin's coprocess encapsulates the API of threads. This threading framework allows us to write asynchronous code easily.
Although the collaborative process has been very convenient, it will be more convenient if it is used together with the KTX extension of the architecture components provided by Google.
1. Add KTX dependency
//Use Kotlin collaboration with architecture components //ViewModelScope implementation 'androidx.lifecycle:lifecycle-viewmodel-ktx:2.3.1' //LifecycleScope implementation 'androidx.lifecycle:lifecycle-runtime-ktx:2.2.0' //liveData implementation 'androidx.lifecycle:lifecycle-livedata-ktx:2.2.0'
2. viewModelScope
2.1 using coprocessor in ViewModel in the old way
Before using ViewModelScope, let's review the previous ways of using orchestration in ViewModel. Manage CoroutineScope by yourself and cancel it when it is not needed (usually in onCleared()). Otherwise, it may cause problems such as resource waste and memory leakage.
class JetpackCoroutineViewModel : ViewModel() {
//When using a collaboration in this ViewModel, you need to use this job to control cancellation
private val viewModelJob = SupervisorJob()
//Specify where the collaboration is executed, and the uiScope can be easily cancelled by viewModelJob
private val uiScope = CoroutineScope(Dispatchers.Main + viewModelJob)
fun launchDataByOldWay() {
uiScope.launch {
//Execute in the background
val result = getNetData()
//Modify UI
log(result)
}
}
override fun onCleared() {
super.onCleared()
viewModelJob.cancel()
}
//Switch the time-consuming task to the IO thread for execution
private suspend fun getNetData() = withContext(Dispatchers.IO) {
//Analog network time consuming
delay(1000)
//Simulation return results
"{}"
}
}
There seems to be a lot of template code, and it's easy to forget to cancel the collaboration when it's not needed.
2.2 new way to use collaboration in ViewModel
It is in this case that Google created ViewModelScope for us. It facilitates us to use the collaboration process by adding extended properties to the ViewModel class, and will automatically cancel its child collaboration process when the ViewModel is destroyed.
class JetpackCoroutineViewModel : ViewModel() {
fun launchData() {
viewModelScope.launch {
//Execute in the background
val result = getNetData()
//Modify UI
log(result)
}
}
//Switch the time-consuming task to the IO thread for execution
private suspend fun getNetData() = withContext(Dispatchers.IO) {
//Analog network time consuming
delay(1000)
//Simulation return results
"{}"
}
}
All the initialization and cancellation of CoroutineScope have been completed for us. We only need to use viewModelScope in the code to start a new collaboration, and we don't have to worry about forgetting to cancel.
Let's take a look at how Google implements it.
2.3 underlying implementation of viewmodelscope
Click in to see the source code and know the root. In case of any strange bug in the future, you can think of a solution faster when you know the principle.
private const val JOB_KEY = "androidx.lifecycle.ViewModelCoroutineScope.JOB_KEY"
/**
* [CoroutineScope] tied to this [ViewModel].
* This scope will be canceled when ViewModel will be cleared, i.e [ViewModel.onCleared] is called
*
* This scope is bound to
* [Dispatchers.Main.immediate][kotlinx.coroutines.MainCoroutineDispatcher.immediate]
*/
public val ViewModel.viewModelScope: CoroutineScope
get() {
//Get the value from the cache first, and return it directly if there is any
val scope: CoroutineScope? = this.getTag(JOB_KEY)
if (scope != null) {
return scope
}
//Create a CloseableCoroutineScope without cache
return setTagIfAbsent(
JOB_KEY,
CloseableCoroutineScope(SupervisorJob() + Dispatchers.Main.immediate)
)
}
internal class CloseableCoroutineScope(context: CoroutineContext) : Closeable, CoroutineScope {
override val coroutineContext: CoroutineContext = context
override fun close() {
coroutineContext.cancel()
}
}
The source code first introduces what viewModelScope is. It is actually an extended attribute of ViewModel. Its actual type is CloseableCoroutineScope. This name looks like a coroutine that can be cancelled. Sure enough, it implements Closeable and cancels it in the close method.
Every time you use viewModelScope, you will get it from the cache first. If not, you will create a CloseableCoroutineScope. It should be noted that the execution of CloseableCoroutineScope is executed in the main thread.
What we need to know now is how the cache is stored and retrieved.
//ViewModel.java
// Can't use ConcurrentHashMap, because it can lose values on old apis (see b/37042460)
@Nullable
private final Map<String, Object> mBagOfTags = new HashMap<>();
/**
* Returns the tag associated with this viewmodel and the specified key.
*/
@SuppressWarnings({"TypeParameterUnusedInFormals", "unchecked"})
<T> T getTag(String key) {
if (mBagOfTags == null) {
return null;
}
synchronized (mBagOfTags) {
return (T) mBagOfTags.get(key);
}
}
/**
* Sets a tag associated with this viewmodel and a key.
* If the given {@code newValue} is {@link Closeable},
* it will be closed once {@link #clear()}.
* <p>
* If a value was already set for the given key, this calls do nothing and
* returns currently associated value, the given {@code newValue} would be ignored
* <p>
* If the ViewModel was already cleared then close() would be called on the returned object if
* it implements {@link Closeable}. The same object may receive multiple close calls, so method
* should be idempotent.
*/
@SuppressWarnings("unchecked")
<T> T setTagIfAbsent(String key, T newValue) {
T previous;
synchronized (mBagOfTags) {
previous = (T) mBagOfTags.get(key);
if (previous == null) {
mBagOfTags.put(key, newValue);
}
}
T result = previous == null ? newValue : previous;
if (mCleared) {
// It is possible that we'll call close() multiple times on the same object, but
// Closeable interface requires close method to be idempotent:
// "if the stream is already closed then invoking this method has no effect." (c)
closeWithRuntimeException(result);
}
return result;
}
Now we know that it exists in mBagOfTags of ViewModel, which is a HashMap.
I know how to save it, so when is it used?
@MainThread
final void clear() {
mCleared = true;
// Since clear() is final, this method is still called on mock objects
// and in those cases, mBagOfTags is null. It'll always be empty though
// because setTagIfAbsent and getTag are not final so we can skip
// clearing it
if (mBagOfTags != null) {
synchronized (mBagOfTags) {
for (Object value : mBagOfTags.values()) {
// see comment for the similar call in setTagIfAbsent
closeWithRuntimeException(value);
}
}
}
onCleared();
}
private static void closeWithRuntimeException(Object obj) {
if (obj instanceof Closeable) {
try {
((Closeable) obj).close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
I searched for mBagOfTags in ViewModel and found a clear method, which traverses mBagOfTags, and then closes all value s that are Closeable. In the above source code, when using viewModelScope for the first time, a closeablecoroutinesecope will be created. It implements the Closeable interface and the close method, which is just used for cancellation.
After seeing this, we know that the collaboration built by viewModelScope is cancelled when the clear method of ViewModel is called back.
Moreover, there is the familiar onCleared method call in the clear method. We know what onCleared is for. When the ViewModel is no longer used, it will call back this method. Generally, we need to do some finishing work in this method, such as canceling the observer subscription and closing resources.
Well, let's make a bold guess. This clear() method should also be called when ViewModel is about to end its life.
After searching, I found that the clear method was called in ViewModelStore.
public class ViewModelStore {
private final HashMap<String, ViewModel> mMap = new HashMap<>();
final void put(String key, ViewModel viewModel) {
ViewModel oldViewModel = mMap.put(key, viewModel);
if (oldViewModel != null) {
oldViewModel.onCleared();
}
}
final ViewModel get(String key) {
return mMap.get(key);
}
Set<String> keys() {
return new HashSet<>(mMap.keySet());
}
/**
* Clears internal storage and notifies ViewModels that they are no longer used.
*/
public final void clear() {
for (ViewModel vm : mMap.values()) {
vm.clear();
}
mMap.clear();
}
}
Viewmodelstore is a container for holding viewmodels. In the clear method of ViewModelStore, the clear method of all ViewModel in the ViewModelStore is called. Where is the clear of viewmodelstore called? I followed up and found that it was in the construction method of ComponentActivity.
public ComponentActivity() {
Lifecycle lifecycle = getLifecycle();
getLifecycle().addObserver(new LifecycleEventObserver() {
@Override
public void onStateChanged(@NonNull LifecycleOwner source,
@NonNull Lifecycle.Event event) {
if (event == Lifecycle.Event.ON_DESTROY) {
if (!isChangingConfigurations()) {
getViewModelStore().clear();
}
}
}
});
}
When the life cycle of the Activity reaches onDestroy, call the clear of ViewModelStore to finish the work. However, note that there is a premise for this call. This time, onDestroy will not call the clear method because of configuration changes.
OK, so far, let's figure out how the collaboration of viewModelScope is automatically cancelled (mBagOfTags of ViewModel) and when it is cancelled (clear() of ViewModel).
3. lifecycleScope
For Lifecycle, Google provides a Lifecycle scope. We can create Coroutine directly through launch.
3.1 use
For example, in onCreate of Activity, the text of TextView is updated every 100 milliseconds.
lifecycleScope.launch {
repeat(100000) {
delay(100)
tvText.text = "$it"
}
}
Because LifeCycle can sense the life cycle of components, once the Activity is onDestroy, the LifeCycle scope above will be used accordingly. The call to the launch closure will also be canceled.
In addition, lifecycleScope also provides launchWhenCreated, launchWhenStarted and launchWhenResumed methods. The closures of these methods have the scope of the collaboration, which are executed when CREATED, STARTED and RESUMED respectively.
//Mode 1
lifecycleScope.launchWhenStarted {
repeat(100000) {
delay(100)
tvText.text = "$it"
}
}
//Mode 2
lifecycleScope.launch {
whenStarted {
repeat(100000) {
delay(100)
tvText.text = "$it"
}
}
}
Whether calling launchWhenStarted directly or calling whenStarted in launch can achieve the same effect.
3.2 underlying implementation of lifecycle scope
Let's take a look at lifecyclescope How did launch do it
/**
* [CoroutineScope] tied to this [LifecycleOwner]'s [Lifecycle].
*
* This scope will be cancelled when the [Lifecycle] is destroyed.
*
* This scope is bound to
* [Dispatchers.Main.immediate][kotlinx.coroutines.MainCoroutineDispatcher.immediate].
*/
val LifecycleOwner.lifecycleScope: LifecycleCoroutineScope
get() = lifecycle.coroutineScope
Good guy, extended attributes again. This extension is the LifecycleOwner, which returns a LifecycleCoroutineScope. Every time you get, the lifecycle is returned Coroutinescope, look what this is.
/**
* [CoroutineScope] tied to this [Lifecycle].
*
* This scope will be cancelled when the [Lifecycle] is destroyed.
*
* This scope is bound to
* [Dispatchers.Main.immediate][kotlinx.coroutines.MainCoroutineDispatcher.immediate]
*/
val Lifecycle.coroutineScope: LifecycleCoroutineScope
get() {
while (true) {
val existing = mInternalScopeRef.get() as LifecycleCoroutineScopeImpl?
if (existing != null) {
return existing
}
val newScope = LifecycleCoroutineScopeImpl(
this,
SupervisorJob() + Dispatchers.Main.immediate
)
if (mInternalScopeRef.compareAndSet(null, newScope)) {
newScope.register()
return newScope
}
}
}
The coroutineScope of Lifecycle is also an extended attribute. It is a LifecycleCoroutineScope. It can be seen from the comments that after the Lifecycle is destroyed, the collaboration will be cancelled. First of all, the previously stored cache will be fetched from mInternalScopeRef. If it is not regenerated, it will be put into a LifecycleCoroutineScopeImpl, and the register function of LifecycleCoroutineScopeImpl will be called. mInternalScopeRef here is an attribute in the Lifecycle class: AtomicReference < Object > mInternalScopeRef = new AtomicReference < > (); (AtomicReference can make an object atomic.). AtomicReference is used here, of course, for thread safety.
Since LifecycleCoroutineScopeImpl is generated, let's see what it is first
internal class LifecycleCoroutineScopeImpl(
override val lifecycle: Lifecycle,
override val coroutineContext: CoroutineContext
) : LifecycleCoroutineScope(), LifecycleEventObserver {
init {
// in case we are initialized on a non-main thread, make a best effort check before
// we return the scope. This is not sync but if developer is launching on a non-main
// dispatcher, they cannot be 100% sure anyways.
if (lifecycle.currentState == Lifecycle.State.DESTROYED) {
coroutineContext.cancel()
}
}
fun register() {
//Start a collaboration process. If the current Lifecycle state is greater than or equal to INITIALIZED, register the Lifecycle observer to observe the Lifecycle
launch(Dispatchers.Main.immediate) {
if (lifecycle.currentState >= Lifecycle.State.INITIALIZED) {
lifecycle.addObserver(this@LifecycleCoroutineScopeImpl)
} else {
coroutineContext.cancel()
}
}
}
override fun onStateChanged(source: LifecycleOwner, event: Lifecycle.Event) {
//If it is observed that the current life cycle is less than or equal to DESTROYED, remove the current observer and cancel the collaboration
if (lifecycle.currentState <= Lifecycle.State.DESTROYED) {
lifecycle.removeObserver(this)
coroutineContext.cancel()
}
}
}
In the above code, there are two important functions: register and onStateChanged. The register function is called when initializing LifecycleCoroutineScopeImpl. First, add an observer in the register function to observe the changes of the life cycle, and then remove the observer and cancel the collaboration when the life cycle is determined to be DESTROYED in the onStateChanged function.
There is a small detail. Why can the register function directly start the coroutine? Because LifecycleCoroutineScopeImpl inherits LifecycleCoroutineScope, which implements the CoroutineScope interface (actually implemented in LifecycleCoroutineScopeImpl).
public abstract class LifecycleCoroutineScope internal constructor() : CoroutineScope {
internal abstract val lifecycle: Lifecycle
......
}
Now we have a clear understanding of the process. When lifecycleScope is used, it will build a collaborative process, observe the life cycle of components, and cancel the collaborative process at the appropriate time.
In the above example, we have seen a piece of code:
//Mode 1
lifecycleScope.launchWhenStarted {
repeat(100000) {
delay(100)
tvText.text = "$it"
}
}
//Mode 2
lifecycleScope.launch {
whenStarted {
repeat(100000) {
delay(100)
tvText.text = "$it"
}
}
}
You can directly use the launchWhenCreated, launchWhenStarted and launchWhenResumed provided by lifecycleScope to execute the collaboration process in the corresponding life cycle.
Click inside to have a look
abstract class LifecycleCoroutineScope internal constructor() : CoroutineScope {
internal abstract val lifecycle: Lifecycle
/**
* Launches and runs the given block when the [Lifecycle] controlling this
* [LifecycleCoroutineScope] is at least in [Lifecycle.State.CREATED] state.
*
* The returned [Job] will be cancelled when the [Lifecycle] is destroyed.
* @see Lifecycle.whenCreated
* @see Lifecycle.coroutineScope
*/
fun launchWhenCreated(block: suspend CoroutineScope.() -> Unit): Job = launch {
lifecycle.whenCreated(block)
}
/**
* Launches and runs the given block when the [Lifecycle] controlling this
* [LifecycleCoroutineScope] is at least in [Lifecycle.State.STARTED] state.
*
* The returned [Job] will be cancelled when the [Lifecycle] is destroyed.
* @see Lifecycle.whenStarted
* @see Lifecycle.coroutineScope
*/
fun launchWhenStarted(block: suspend CoroutineScope.() -> Unit): Job = launch {
lifecycle.whenStarted(block)
}
/**
* Launches and runs the given block when the [Lifecycle] controlling this
* [LifecycleCoroutineScope] is at least in [Lifecycle.State.RESUMED] state.
*
* The returned [Job] will be cancelled when the [Lifecycle] is destroyed.
* @see Lifecycle.whenResumed
* @see Lifecycle.coroutineScope
*/
fun launchWhenResumed(block: suspend CoroutineScope.() -> Unit): Job = launch {
lifecycle.whenResumed(block)
}
}
It turns out that these functions are the functions in the LifecycleCoroutineScope class returned by the extended attribute lifecycleScope of LifecycleOwner. There is nothing in these functions. They directly call the functions corresponding to lifecycle
/**
* Runs the given block when the [Lifecycle] is at least in [Lifecycle.State.CREATED] state.
*
* @see Lifecycle.whenStateAtLeast for details
*/
suspend fun <T> Lifecycle.whenCreated(block: suspend CoroutineScope.() -> T): T {
return whenStateAtLeast(Lifecycle.State.CREATED, block)
}
/**
* Runs the given block when the [Lifecycle] is at least in [Lifecycle.State.STARTED] state.
*
* @see Lifecycle.whenStateAtLeast for details
*/
suspend fun <T> Lifecycle.whenStarted(block: suspend CoroutineScope.() -> T): T {
return whenStateAtLeast(Lifecycle.State.STARTED, block)
}
/**
* Runs the given block when the [Lifecycle] is at least in [Lifecycle.State.RESUMED] state.
*
* @see Lifecycle.whenStateAtLeast for details
*/
suspend fun <T> Lifecycle.whenResumed(block: suspend CoroutineScope.() -> T): T {
return whenStateAtLeast(Lifecycle.State.RESUMED, block)
}
These functions were originally suspend functions and extended Lifecycle functions. They eventually call the whenStateAtLeast function and pass in the minimum Lifecycle state flag (minState) of the execution coroutine.
suspend fun <T> Lifecycle.whenStateAtLeast(
minState: Lifecycle.State,
block: suspend CoroutineScope.() -> T
) = withContext(Dispatchers.Main.immediate) {
val job = coroutineContext[Job] ?: error("when[State] methods should have a parent job")
val dispatcher = PausingDispatcher()
val controller =
LifecycleController(this@whenStateAtLeast, minState, dispatcher.dispatchQueue, job)
try {
//Execution coordination
withContext(dispatcher, block)
} finally {
//Close out work remove life cycle observation
controller.finish()
}
}
@MainThread
internal class LifecycleController(
private val lifecycle: Lifecycle,
private val minState: Lifecycle.State,
private val dispatchQueue: DispatchQueue,
parentJob: Job
) {
private val observer = LifecycleEventObserver { source, _ ->
if (source.lifecycle.currentState == Lifecycle.State.DESTROYED) {
//Destroyed - > cancel collaboration
handleDestroy(parentJob)
} else if (source.lifecycle.currentState < minState) {
dispatchQueue.pause()
} else {
//implement
dispatchQueue.resume()
}
}
init {
// If Lifecycle is already destroyed (e.g. developer leaked the lifecycle), we won't get
// an event callback so we need to check for it before registering
// see: b/128749497 for details.
if (lifecycle.currentState == Lifecycle.State.DESTROYED) {
handleDestroy(parentJob)
} else {
//Observe life cycle changes
lifecycle.addObserver(observer)
}
}
@Suppress("NOTHING_TO_INLINE") // avoid unnecessary method
private inline fun handleDestroy(parentJob: Job) {
parentJob.cancel()
finish()
}
/**
* Removes the observer and also marks the [DispatchQueue] as finished so that any remaining
* runnables can be executed.
*/
@MainThread
fun finish() {
//Remove lifecycle observer
lifecycle.removeObserver(observer)
//Mark completed and execute the remaining executable Runnable
dispatchQueue.finish()
}
}
whenStateAtLeast is also an extension function of Lifecycle. The core logic is to add LifecycleObserver to LifecycleController to monitor the Lifecycle status, and determine whether to suspend execution, resume execution, or cancel execution through the status. When the execution is completed, that is, finally, finish the work from the finish of the Lifecycle controller: remove the Lifecycle monitor and start to execute the remaining tasks.
Once the execution is completed, the life cycle observer will be removed, which is equivalent to that the closure in functions such as launchWhenResumed will only be executed once. After execution, it will not be executed again even after onpause - > onresume.
4. liveData
In the process of using livedata at ordinary times, this scenario may be involved: request the network to get the results, then transfer the data through livedata, receive the notification in the Activity, and then update the UI. Very common scenarios. In this case, we can simplify the above scenario code through the official livedata constructor function.
4.1 use
val netData: LiveData<String> = liveData {
//When observing, it will be executed immediately within the life cycle
val data = getNetData()
emit(data)
}
//Switch the time-consuming task to the IO thread for execution
private suspend fun getNetData() = withContext(Dispatchers.IO) {
//Analog network time consuming
delay(5000)
//Simulation return results
"{}"
}
In the above example, getNetData() is a suspend function. Use the livedata constructor function to asynchronously call getNetData(), and then use emit() to submit the result. On the Activity side, if the netData is observed and active, the result will be received. We know that the suspend function needs to be called in the scope of the association, so there is a co scope in the closure of liveData.
One small detail is that if the component is just active when observing this netData, the code in the liveData closure will be executed immediately.
In addition to the above usage, you can also issue multiple values in liveData.
val netData2: LiveData<String> = liveData {
delay(3000)
val source = MutableLiveData<String>().apply {
value = "11111"
}
val disposableHandle = emitSource(source)
delay(3000)
disposableHandle.dispose()
val source2 = MutableLiveData<String>().apply {
value = "22222"
}
val disposableHandle2 = emitSource(source2)
}
It should be noted that when the latter one calls emitSource, it is necessary to call the dispose function to cut off the return value of the previous emitSource.
4.2 underlying implementation of livedata
Old rule, Ctrl + left mouse button click in to see the source code
@UseExperimental(ExperimentalTypeInference::class)
fun <T> liveData(
context: CoroutineContext = EmptyCoroutineContext,
timeoutInMs: Long = DEFAULT_TIMEOUT,
@BuilderInference block: suspend LiveDataScope<T>.() -> Unit
): LiveData<T> = CoroutineLiveData(context, timeoutInMs, block)
//The code we write in the closure behind liveData is passed to the block here. It is a suspend function with the context of LiveDataScope
First of all, the liveData function is actually a global function, which means you can use it anywhere, not limited to Activity or ViewModel.
Secondly, the liveData function returns a CoroutineLiveData object? What is returned is an object without executing any code here. Where does my code execute?
It depends on the code of CoroutineLiveData class
internal class CoroutineLiveData<T>(
context: CoroutineContext = EmptyCoroutineContext,
timeoutInMs: Long = DEFAULT_TIMEOUT,
block: Block<T>
) : MediatorLiveData<T>() {
private var blockRunner: BlockRunner<T>?
private var emittedSource: EmittedSource? = null
init {
// use an intermediate supervisor job so that if we cancel individual block runs due to losing
// observers, it won't cancel the given context as we only cancel w/ the intention of possibly
// relaunching using the same parent context.
val supervisorJob = SupervisorJob(context[Job])
// The scope for this LiveData where we launch every block Job.
// We default to Main dispatcher but developer can override it.
// The supervisor job is added last to isolate block runs.
val scope = CoroutineScope(Dispatchers.Main.immediate + context + supervisorJob)
blockRunner = BlockRunner(
liveData = this,
block = block,
timeoutInMs = timeoutInMs,
scope = scope
) {
blockRunner = null
}
}
internal suspend fun emitSource(source: LiveData<T>): DisposableHandle {
clearSource()
val newSource = addDisposableSource(source)
emittedSource = newSource
return newSource
}
internal suspend fun clearSource() {
emittedSource?.disposeNow()
emittedSource = null
}
override fun onActive() {
super.onActive()
blockRunner?.maybeRun()
}
override fun onInactive() {
super.onInactive()
blockRunner?.cancel()
}
}
There is less code in it. It mainly inherits MediatorLiveData, and then executes the maybeRun function of BlockRunner when onActive. What is executed in the maybeRun of BlockRunner is actually the code block we wrote in livedata, and the onActive method is actually inherited from livedata. It will be called when an active observer listens to livedata.
This makes sense. In the above case, I observed netData in onCreate of Activity, so the code in liveData will be executed immediately.
//typealias type alias
//This will be used in the following BlockRunner, which is used to carry the code in the closure behind liveData
internal typealias Block<T> = suspend LiveDataScope<T>.() -> Unit
/**
* Handles running a block at most once to completion.
*/
internal class BlockRunner<T>(
private val liveData: CoroutineLiveData<T>,
private val block: Block<T>,
private val timeoutInMs: Long,
private val scope: CoroutineScope,
private val onDone: () -> Unit
) {
@MainThread
fun maybeRun() {
...
//The scope here is CoroutineScope(Dispatchers.Main.immediate + context + supervisorJob)
runningJob = scope.launch {
val liveDataScope = LiveDataScopeImpl(liveData, coroutineContext)
//The block here executes the code we wrote in liveData. When executing the block, the liveDataScope instance is passed in, and the liveDataScope context is changed
block(liveDataScope)
//complete
onDone()
}
}
...
}
internal class LiveDataScopeImpl<T>(
internal var target: CoroutineLiveData<T>,
context: CoroutineContext
) : LiveDataScope<T> {
...
// use `liveData` provided context + main dispatcher to communicate with the target
// LiveData. This gives us main thread safety as well as cancellation cooperation
private val coroutineContext = context + Dispatchers.Main.immediate
//Because there is a livedatascope impl context when executing the liveData closure, you can use the emit function
override suspend fun emit(value: T) = withContext(coroutineContext) {
target.clearSource()
//Set value for the livedata of the target, and the livedata returns the target. If you observe the target in the component, you will receive the value data here
target.value = value
}
}
A coroutine is started in the maybeRun function of BlockRunner. This scope is initialized in CoroutineLiveData: coroutinescope (dispatchers. Main. Immediate + context + supervisor job). Then, the code written in the closure behind liveData is executed in this scope, and there is the context of livedatascope impl. With the context of livedatascope impl, we can use the emit method in livedatascope impl. In fact, the emit method is very simple. It is to give a data to a liveData object, and the liveData is the one returned by liveData {}. At this time, because the data of liveData has changed, if a component observes the liveData and the component is active, the component will receive a callback for the data change.
The general process of the whole process is to build a collaborative process in LiveData {} and return a LiveData. Then the code in the closure we write is actually executed in a collaborative process. When we call the emit method, we are updating the value in the LiveData. Since it is the returned LiveData, it is naturally associated with the component life cycle. The results can be obtained only when the component is active, and some memory leakage problems are avoided.
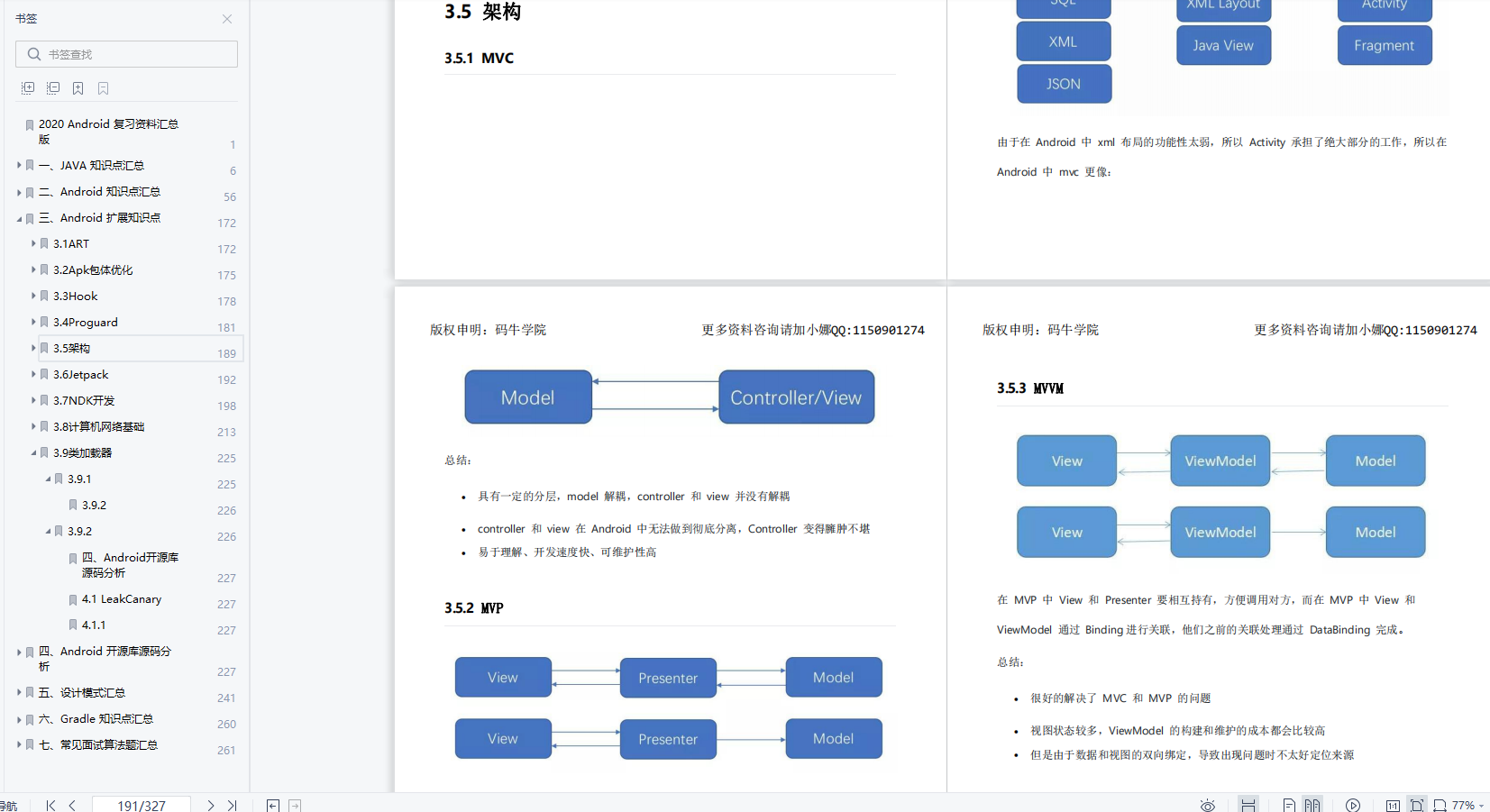
5. Summary
It has to be said that what the government provides is convenience, which can greatly facilitate our use of the collaborative process. Those who are using collaborative processes and have not yet used them with architectural components should use them quickly. Meizizi~
last
Xiaobian has collected some learning documents, interview questions, Android core notes and other documents related to Android Development on the Internet, hoping to help you learn and improve. If you need reference, you can go to me directly CodeChina address: https://codechina.csdn.net/u012165769/Android-T3 Access.