Ox tail sweeps the shadow and tiger head opens the blind box. Three volume online disc competition, ranking evaluation 0.59168
Baidu online AI competition: document image shadow elimination, and the prize pool is a mysterious gift package. The prize pool is a blind box. I'm a little curious.

1, Document image shadow elimination
In life, when using mobile phones to scan documents, due to angle reasons, it is inevitable to leave annoying shadows left in the photos when raising hands to shoot. In order to help people solve such problems and reduce the interference caused by shadows, players need to train the model through deep learning technology, process the pictures with shadows collected in a given real scene, restore the original appearance of the pictures, and finally output the processed result pictures.
| Shaded picture | Effect after removing shadows |
|---|---|
 |  |
This competition hopes that the players will combine the current cutting-edge image processing technology and computer vision technology to improve the training performance and generalization ability of the model, and pay attention to the performance problems of the model in practical application while ensuring the accuracy of the effect, so as to be as small and fast as possible.
2, Data analysis
In the latest released data set of this competition, all image data are collected from the real scene, and then processed through technical means to generate available desensitization data sets. The task is in the form of image to image, so the source data and GT data are provided in the form of pictures. It can be quickly integrated into the competition based on the latest training data released in this competition. In order to achieve better algorithm effect, this competition is not limited to using additional training data to optimize the model.
Data set composition
|- root
|- images |- gts
The newly released data set of this competition consists of training set, test set of list A and test set of List B, of which 1410 samples are in training set (picture number is discontinuous), 300 samples are in test set of list A (picture number is continuous) and 397 samples are in test set of list B;
images is the source image data with shadow, and gts is the truth data without shadow; (GT of test data set is not open)
Images and images in gts correspond one by one according to the image name.
#1. Prepare raw materials: decompress the data set of the competition !unzip data/data126294/delight_train_dataset.zip -d data/ >>/dev/null !unzip data/data126294/delight_testA_dataset.zip -d data/ >>/dev/null
## Data EDA
import os.path
import glob
import re
from PIL import Image
path = '/home/aistudio/data/delight_train_dataset/images' #Training data path
dirname='/home/aistudio/work/'
im_files = glob.glob(os.path.join(path, "*.jpg"))
im_files.sort()
print('Number of training sets {}'.format(len(im_files)))
train_file = open(os.path.join(dirname, 'train.txt'), 'w')
for index,filename in enumerate(im_files):
im = Image.open(filename)#Return a Image object #Open this image
filepath = os.path.join(dirname, filename)
print("%s\t%s\t%s\n" % (filename,im.size[0],im.size[1]),file=train_file) #Enter the image name, image height and width into the specified txt.
train_file.close()
path = '/home/aistudio/data/delight_testA_dataset/images' #Training data path
im_files = glob.glob(os.path.join(path, "*.jpg"))
im_files.sort()
print('Number of test sets {}'.format(len(im_files)))
test_file = open(os.path.join(dirname, 'test.txt'), 'w')
for index,filename in enumerate(im_files):
im = Image.open(filename)#Return a Image object #Open this image
filepath = os.path.join(dirname, filename)
print ("%s\t%s\t%s\n" % (filename,im.size[0],im.size[1]),file=test_file) #Enter the image name, image height and width into the specified txt.
test_file.close()
Number of training sets 1410 Number of test sets 300
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_table('/home/aistudio/work/train.txt',header=None,index_col=False)
plt.figure(figsize=(10,4))
plt.title('Width of TrainSet') #Training set image width distribution
hc = df[2].groupby(df[1])
hc.count().plot.bar()
plt.figure(figsize=(10,4))
plt.title('Height of TrainSet') #Training set image height distribution
wc = df[1].groupby(df[2])
wc.count().plot.bar()
<matplotlib.axes._subplots.AxesSubplot at 0x7f783bd9f3d0>
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_table('/home/aistudio/work/test.txt',header=None,index_col=False)
plt.figure(figsize=(10,4))
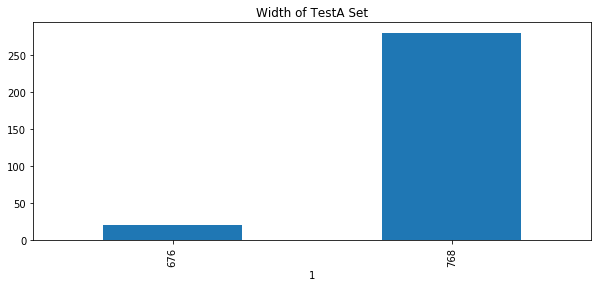
plt.title('Width of TestA Set') #Test set A image width distribution
hc = df[2].groupby(df[1])
hc.count().plot.bar()
plt.figure(figsize=(10,4))
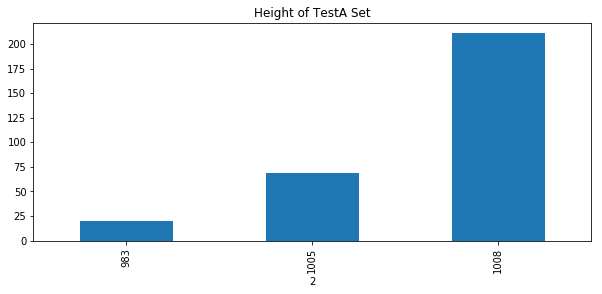
plt.title('Height of TestA Set') #Test set A image height distribution
wc = df[1].groupby(df[2])
wc.count().plot.bar()
<matplotlib.axes._subplots.AxesSubplot at 0x7f783bedb690>
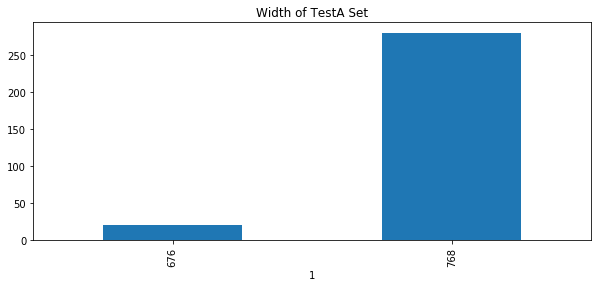
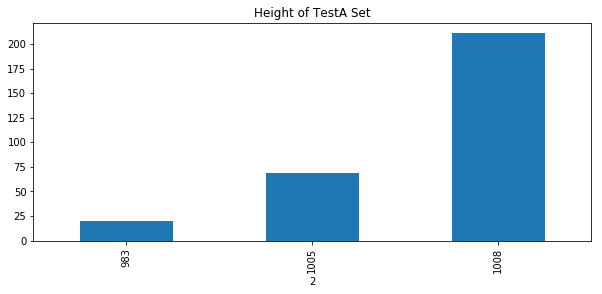
According to the length and width of the pictures of the training set and the test set, the size of the picture during training can be set to 512 * 512.
3, Train of thought
The document image shadow elimination task can be regarded as an image enhancement, which belongs to the low level visual task. It is similar to the moire elimination and handwritten text erasure tasks in Baidu online disk image processing challenge. It can also be completed based on the ideas and models of the above two tasks.
This project is also based on the idea of handwritten text erasure task. Try whether you can share one kind of model to solve a variety of image enhancement tasks.
MTRNet + + is adopted for the model, and the specific description can refer to the following items:
4, Uncoiling
#2. Prepare tools !pip install glob2 -q !pip install imutils -q !pip install scikit_image -q
#3. Generate data sets. The data set generation has been completed. This step is not required #%cd work/scripts/ #!python generate_bbox.py #!python create_dataset.py
#4. Repeated production. Set Mask to 8 to generate a fixed Mask %cd /home/aistudio/work/ !python train.py
(1) The log file is saved in the log directory of the folder under the output directory, and the parameters in the training process are saved in the model directory.
(2) Breakpoint continuation training, in config Set G in YML file_ MODEL_ Path and D_MODEL_PATH is the path where the model has been saved.
(3) You can view training indicators and images generated during training through the data model visualization function of VisualDL on the left.
Visualization of training indicators
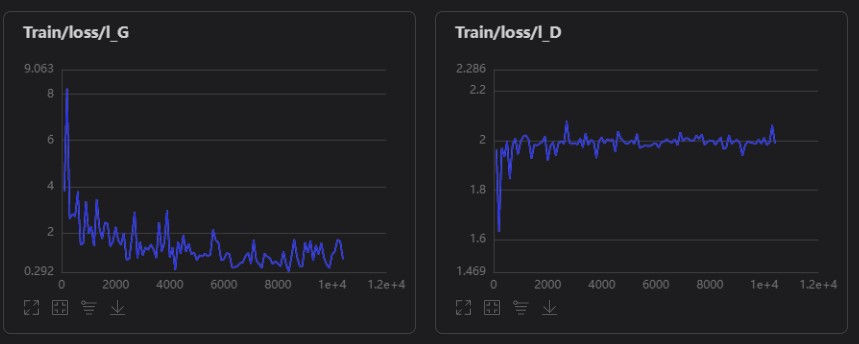
Images generated during training

In the above figure: the left is the input original image, the middle is the label image, and the right is the generated image
#5. Check the quality. The sliding window method is used for prediction enhancement, in which the sliding window and step size can be adjusted
%cd /home/aistudio/work/
!python test.py --config /home/aistudio/work/config/config.yml \
--mode 3 --dataset_root /home/aistudio/data/delight_testA_dataset/images/ \
--pretrained /home/aistudio/output/20220123-073327/model/MaskInpaintModel_gen_55000.pdparams
#6. Try the effect and submit the compressed file for scoring %cd /home/aistudio/work/test_result/ !zip result.zip *.jpg *.txt
The saved file is in test_ In the result path, enter the path to create readme Txt file, enter the required content:
Training framework: PaddlePaddle
Code running environment: V100
Whether to use GPU: Yes
Single picture time / s: 1
Model size: 45
Other notes: refer to MTRNet for algorithm++
5, Summary
Ranking results
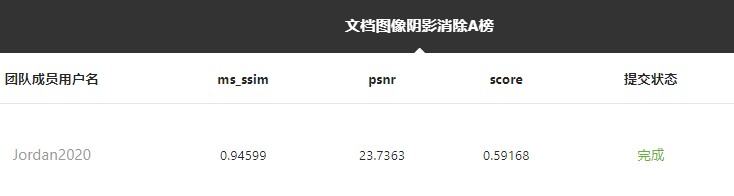
Rising point idea
1. Use external data and pre training model to fine tune the competition data set;
2. Adjust the model structure;
4. Adjust the super parameters in the Config file.