WeChat official account SteveCode reply: flowable can get source code.
yqmm-flowable
Deployment and operation of flowable UI
Download flowable-6.6.0 from the official website: https://github.com/flowable/flowable-engine/releases/download/flowable-6.6.0/flowable-6.6.0.zip
Compress the flowable-6.6.0 \ wars \ flowable UI in the package War dropped into Tomcat and ran
open http://localhost:8080/flowable-ui login with account: admin/test

Enter app Model creates a process and then exports it to the project for use, or configures apache-tomcat-9.0.37 \ webapps \ flowable UI \ WEB-INF \ classes \ flowable default Properties connect to the local database
Configure it like this:
server.port=8080
server.servlet.context-path=/flowable-ui
spring.jmx.unique-names=true
# This is needed to force use of JDK proxies instead of using CGLIB
spring.aop.proxy-target-class=false
spring.aop.auto=false
spring.application.name=flowable-ui
spring.banner.location=classpath:/org/flowable/spring/boot/flowable-banner.txt
# The default domain for generating ObjectNames must be specified. Otherwise when multiple Spring Boot applications start in the same servlet container
# all would be created with the same name (com.zaxxer.hikari:name=dataSource,type=HikariDataSource) for example
spring.jmx.default-domain=${spring.application.name}
#
# SECURITY
#
spring.security.filter.dispatcher-types=REQUEST,FORWARD,ASYNC
# Expose all actuator endpoints to the web
# They are exposed, but only authenticated users can see /info and /health abd users with access-admin can see the others
management.endpoints.web.exposure.include=*
# Full health details should only be displayed when a user is authorized
management.endpoint.health.show-details=when_authorized
# Only users with role access-admin can access full health details
management.endpoint.health.roles=access-admin
# Spring prefixes the roles with ROLE_. However, Flowable does not have that concept yet, so we need to override that with an empty string
flowable.common.app.role-prefix=
#
# SECURITY OAuth2
# Examples are for Keycloak
#
#spring.security.oauth2.resourceserver.jwt.issuer-uri=<keycloakLocation>/auth/realms/<realmName>
#spring.security.oauth2.client.registration.keycloak.client-id=<clientId>
#spring.security.oauth2.client.registration.keycloak.client-secret=<clientSecret>
#spring.security.oauth2.client.registration.keycloak.client-name=Flowable UI Keycloak
#spring.security.oauth2.client.registration.keycloak.authorization-grant-type=authorization_code
#spring.security.oauth2.client.provider.keycloak.issuer-uri=<keycloakLocation>/auth/realms/<realmName>
#spring.security.oauth2.client.provider.keycloak.user-name-attribute=preferred_username
#flowable.common.app.security.type=oauth2
#flowable.common.app.security.oauth2.authorities-attribute=groups
#flowable.common.app.security.oauth2.groups-attribute=userGroups
#flowable.common.app.security.oauth2.default-authorities=access-task
#flowable.common.app.security.oauth2.default-groups=flowableUser
#flowable.common.app.security.oauth2.full-name-attribute=name
#flowable.common.app.security.oauth2.email-attribute=email
#
# DATABASE&nullCatalogMeansCurrent=true
#
#spring.datasource.driver-class-name=org.h2.Driver
#spring.datasource.url=jdbc:h2:~/flowable-db/engine-db;AUTO_SERVER=TRUE;AUTO_SERVER_PORT=9093;DB_CLOSE_DELAY=-1
#important
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
#important
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/flowable?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai&nullCatalogMeansCurrent=true
#spring.datasource.driver-class-name=org.postgresql.Driver
#spring.datasource.url=jdbc:postgresql://localhost:5432/flowable
#spring.datasource.driver-class-name=com.microsoft.sqlserver.jdbc.SQLServerDriver
#spring.datasource.url=jdbc:sqlserver://localhost:1433;databaseName=flowablea
#spring.datasource.driver-class-name=oracle.jdbc.driver.OracleDriver
#spring.datasource.url=jdbc:oracle:thin:@localhost:1521:FLOWABLE
#spring.datasource.driver-class-name=com.ibm.db2.jcc.DB2Driver
#spring.datasource.url=jdbc:db2://localhost:50000/flowable
#important
spring.datasource.username=root
spring.datasource.password=root
# JNDI CONFIG
# If uncommented, the datasource will be looked up using the configured JNDI name.
# This will have preference over any datasource configuration done below that doesn't use JNDI
#
# Eg for JBoss: java:jboss/datasources/flowableDS
#
#spring.datasource.jndi-name==jdbc/flowableDS
# Set whether the lookup occurs in a J2EE container, i.e. if the prefix "java:comp/env/" needs to be added if the JNDI
# name doesn't already contain it. Default is "true".
#datasource.jndi.resourceRef=true
#
# Connection pool (see https://github.com/brettwooldridge/HikariCP#configuration-knobs-baby)
#
spring.datasource.hikari.poolName=${spring.application.name}
# 10 minutes
spring.datasource.hikari.maxLifetime=600000
# 5 minutes
spring.datasource.hikari.idleTimeout=300000
spring.datasource.hikari.minimumIdle=10
spring.datasource.hikari.maximumPoolSize=50
# test query for H2, MySQL, PostgreSQL and Microsoft SQL Server
#spring.datasource.hikari.connection-test-query=select 1
# test query for Oracle
#spring.datasource.hikari.connection-test-query=SELECT 1 FROM DUAL
# test query for DB2
#spring.datasource.hikari.connection-test-query=SELECT current date FROM sysibm.sysdummy1
#
# Default Task Executor (will be used for @Async)
#
spring.task.execution.pool.core-size=2
spring.task.execution.pool.max-size=50
spring.task.execution.pool.queue-capacity=10000
spring.task.execution.thread-name-prefix=flowable-ui-task-Executor-
#
# Task scheduling
#
spring.task.scheduling.pool.size=5
#
# EMAIL
#
#flowable.mail.server.host=localhost
#flowable.mail.server.port=1025
#flowable.mail.server.username=
#flowable.mail.server.password=
#
# FLOWABLE
#
flowable.process.definition-cache-limit=512
#flowable.dmn.strict-mode=false
flowable.process.async.executor.default-async-job-acquire-wait-time-in-millis=5000
flowable.process.async.executor.default-timer-job-acquire-wait-time-in-millis=5000
flowable.cmmn.async.executor.default-async-job-acquire-wait-time-in-millis=5000
flowable.cmmn.async.executor.default-timer-job-acquire-wait-time-in-millis=5000
# The maximum file upload limit. Set to -1 to set to 'no limit'. Expressed in bytes
spring.servlet.multipart.max-file-size=10MB
# The maximum request size limit. Set to -1 to set to 'no limit'.
# When multiple files can be uploaded this needs to be more than the 'max-file-size'.
spring.servlet.multipart.max-request-size=10MB
# For development purposes, data folder is created inside the sources ./data folder
flowable.content.storage.root-folder=data/
flowable.content.storage.create-root=true
flowable.common.app.idm-admin.user=admin
flowable.common.app.idm-admin.password=test
flowable.experimental.debugger.enabled=false
# Rest API in task application
# If false, disables the rest api in the task app
flowable.task.app.rest-enabled=true
# Configures the way user credentials are verified when doing a REST API call:
# 'any-user' : the user needs to exist and the password need to match. Any user is allowed to do the call (this is the pre 6.3.0 behavior)
# 'verify-privilege' : the user needs to exist, the password needs to match and the user needs to have the 'rest-api' privilege
# If nothing set, defaults to 'verify-privilege'
flowable.rest.app.authentication-mode=verify-privilege
# Enable form field validation after form submission on the engine side
flowable.form-field-validation-enabled=false
# Flowable Admin Properties
# Passwords for rest endpoints and master configs are stored encrypted in the database using AES/CBC/PKCS5PADDING
# It needs a 128-bit initialization vector (http://en.wikipedia.org/wiki/Initialization_vector)
# and a 128-bit secret key represented as 16 ascii characters below
#
# Do note that if these properties are changed after passwords have been saved, all existing passwords
# will not be able to be decrypted and the password would need to be reset in the UI.
flowable.admin.app.security.encryption.credentials-i-v-spec=j8kdO2hejA9lKmm6
flowable.admin.app.security.encryption.credentials-secret-spec=9FGl73ngxcOoJvmL
#flowable.admin.app.security.preemptive-basic-authentication=true
# Flowable IDM Properties
#
# LDAP
#
#flowable.idm.ldap.enabled=true
#flowable.idm.ldap.server=ldap://localhost
#flowable.idm.ldap.port=10389
#flowable.idm.ldap.user=uid=admin, ou=system
#flowable.idm.ldap.password=secret
#flowable.idm.ldap.base-dn=o=flowable
#flowable.idm.ldap.query.user-by-id=(&(objectClass=inetOrgPerson)(uid={0}))
#flowable.idm.ldap.query.user-by-full-name-like=(&(objectClass=inetOrgPerson)(|({0}=*{1}*)({2}=*{3}*)))
#flowable.idm.ldap.query.all-users=(objectClass=inetOrgPerson)
#flowable.idm.ldap.query.groups-for-user=(&(objectClass=groupOfUniqueNames)(uniqueMember={0}))
#flowable.idm.ldap.query.all-groups=(objectClass=groupOfUniqueNames)
#flowable.idm.ldap.query.group-by-id=(&(objectClass=groupOfUniqueNames)(uniqueId={0}))
#flowable.idm.ldap.attribute.user-id=uid
#flowable.idm.ldap.attribute.first-name=cn
#flowable.idm.ldap.attribute.last-name=sn
#flowable.idm.ldap.attribute.email=mail
#flowable.idm.ldap.attribute.group-id=cn
#flowable.idm.ldap.attribute.group-name=cn
#flowable.idm.ldap.cache.group-size=10000
#flowable.idm.ldap.cache.group-expiration=180000
#
# Keycloak
#
#flowable.idm.app.keycloak.enabled=true
#flowable.idm.app.keycloak.server=<keycloakLocation>
#flowable.idm.app.keycloak.authentication-realm=master
#flowable.idm.app.keycloak.authentication-user=admin
#flowable.idm.app.keycloak.authentication-password=admin
#flowable.idm.app.keycloak.realm=<realm>
#
# DEFAULT ADMINISTRATOR ACCOUNT
#
flowable.idm.app.admin.user-id=admin
flowable.idm.app.admin.password=test
flowable.idm.app.admin.first-name=Test
flowable.idm.app.admin.last-name=Administrator
flowable.idm.app.admin.email=test-admin@example-domain.tld
# Enable and configure JMS
#flowable.task.app.jms-enabled=true
#spring.activemq.broker-url=tcp://localhost:61616
# Enable and configure RabbitMQ
#flowable.task.app.rabbit-enabled=true
#spring.rabbitmq.addresses=localhost:5672
#spring.rabbitmq.username=guest
#spring.rabbitmq.password=guest
# Enable and configure Kafka
#flowable.task.app.kafka-enabled=true
#spring.kafka.bootstrap-servers=localhost:9092
be careful:
You need to copy the java driver jar (MySQL connector java XXX. Jar) to apache-tomcat-9.0.37 \ webapps \ flowable rest \ WEB-INF \ lib
mysql 8.X remember to replace the current version
Flow chart Description:
- Events are usually used to model what happens in the process life cycle. In the diagram, there are two circles: start and end.
- A sequence flow is a connector between two elements in a process. In the picture is [arrow line segment].
- The gateway is used to control the flow of execution. In the picture is [diamond (with X in the middle)]
- user task is used to model tasks that need to be executed manually. In the picture is [rectangle].
Description of flow sheet:
1. All database tables of Flowable are represented by ACT_ start. The second part is the two character identifier that explains the purpose of the table. The naming of service API s also roughly conforms to this rule.
2,ACT_RE_: 'RE 'stands for repository. The table with this prefix contains "static" information, such as process definitions and process resources (pictures, rules, etc.).
3,ACT_RU_: 'RU 'stands for runtime. These tables store runtime information, such as process instance, user task, variable, job, and so on. Flowable saves run-time data only in the running process instance, and deletes records at the end of the process instance. This ensures that the runtime table is small and fast.
4,ACT_ HI_: ' 'Hi' stands for history. These tables store historical data, such as completed process instances, variables, tasks, and so on.
5,ACT_GE_: General data. Use in multiple places.
General data sheet:
act_ge_bytearray: binary data table, such as byte stream file of process definition, process template and flow chart;
act_ge_property: property data sheet (not commonly used);
History table
- act_ hi_ Act Inst: History node table, which stores the node information of process instance operation (including start, end and other non task nodes);
- act_hi_attachment: historical attachment table, which stores the attachment information uploaded by the historical node (not commonly used);
- act_hi_comment: historical opinion form;
- act_hi_detail: History detail table, which stores some information about node operation (not commonly used);
- act_hi_identitylink: historical process personnel table, which stores candidate and handling personnel information of each process node. It is often used to query the completed tasks of a person or department;
- act_hi_procinst: historical process instance table, which stores the historical data of process instances (including running process instances);
- act_hi_taskinst: historical process task table, which stores historical task nodes;
- act_hi_varinst: process history variable table, which stores the variable information of the process history node;
Process definition table: - act_re_deployment: subordinate information table, which stores process definition and template deployment information;
- act_re_procdef: process definition information table, which stores process definition related description information, but its real content is stored in act_ ge_ In the bytearray table, it is stored in bytes;
- act_re_model: process template information table, which stores process template related description information, but its real content is stored in act_ ge_ In the bytearray table, it is stored in bytes;
Process runtime tables (6, RuntimeService interface operation tables)
- act_ru_task: the runtime process task node table, which stores the task node information of the running process. It is important and is often used to query the to-do tasks of personnel or departments;
- act_ru_event_subscr: monitoring information table, not commonly used;
- act_ru_execution: the runtime process execution instance table, which records the branch information of the running process (when there is no sub process, its data corresponds to the data in the act_ru_task table one by one);
- act_ru_identitylink: runtime process personnel table, which is important and is often used to query the to-do tasks of personnel or departments;
- act_ru_job: runtime scheduled task data table, which stores the scheduled task information of the process;
- act_ru_variable: runtime process variable data table, which stores the variable information of each node of the running process;
User table
- act_id_group: user group information table, which selects candidate group information corresponding to the node;
- act_id_info: user extension information table, which stores user extension information;
- act_id_membership: relationship table between users and user groups;
- act_id_user: user information table, which selects the handler or candidate information in the corresponding node;
Process engine API and service
1. The repository service is likely to be the first service to use the Flowable engine. This service provides operations for managing and controlling deployments and process definitions. Manage static information,
2. RuntimeService is used to start a new process instance of the process definition.
3. IdentityService is simple. It is used to manage (create, update, delete, query...) groups and users.
4. FormService is an optional service. In other words, Flowable can run well without it without sacrificing any functions.
5. The HistoryService exposes all historical data collected by the Flowable engine. To provide the ability to query historical data.
6. ManagementService is usually not used when writing user applications with Flowable. It can read the information of the database table and the original data of the table, and also provide the query and management operation of the job.
7. Dynamic bpmnservice can be used to modify parts of the process definition without redeploying it. For example, you can modify the handler setting of a user task in the process definition, or modify the class name in a service task.
Video Explanation
Documentation help:
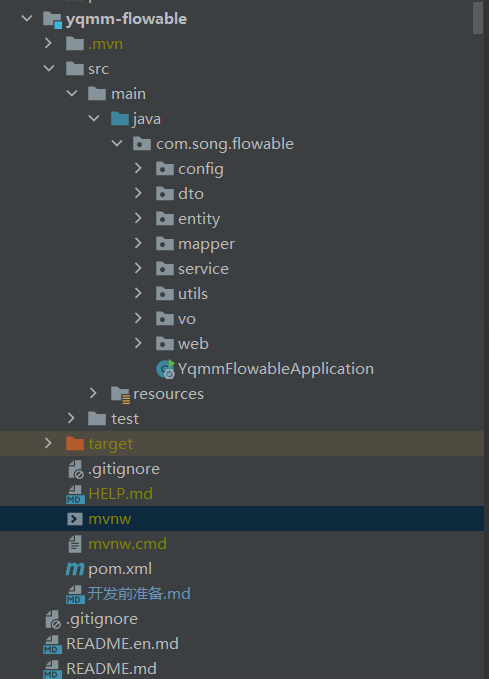
Code structure
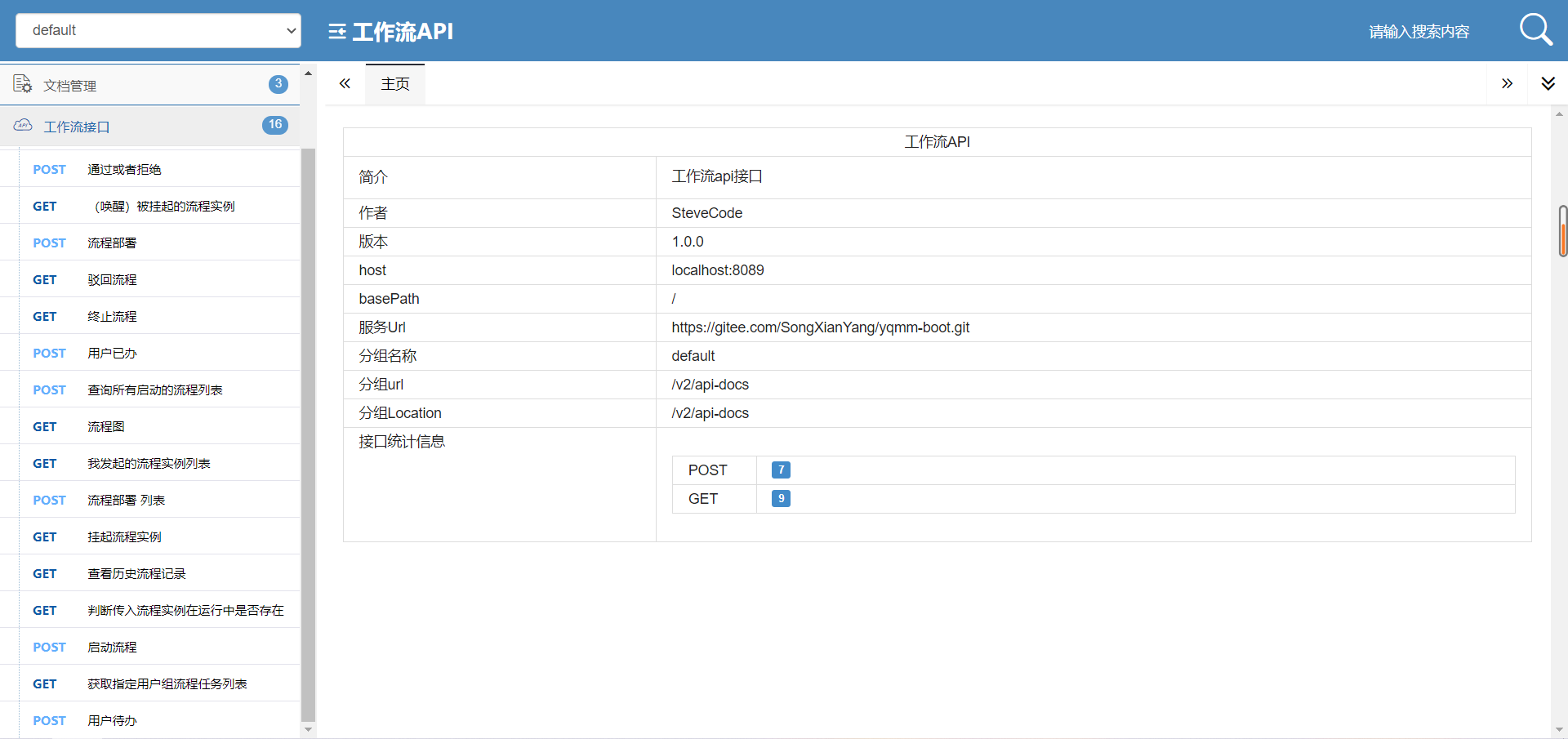
swagger path: http://localhost:8089/doc.html