1. motivation
1. Aiming at the problem of how to extract the appropriate features of the image, this paper proposes a convolution branch of multiple branches, each branch adopts different receptive fields, and decomposes the image into different receptive fields
2. Aiming at how to find similar patch es for missing regions, this paper proposes a Markov random field (ID-MRF) term,
3. For the result that there are many possibilities for the repair result of the missing area, a new confidence driven reconstruction loss (similar to the spatial attenuation loss) is proposed, which is generated according to the spatial position constraint of the missing area
2. Specific methods
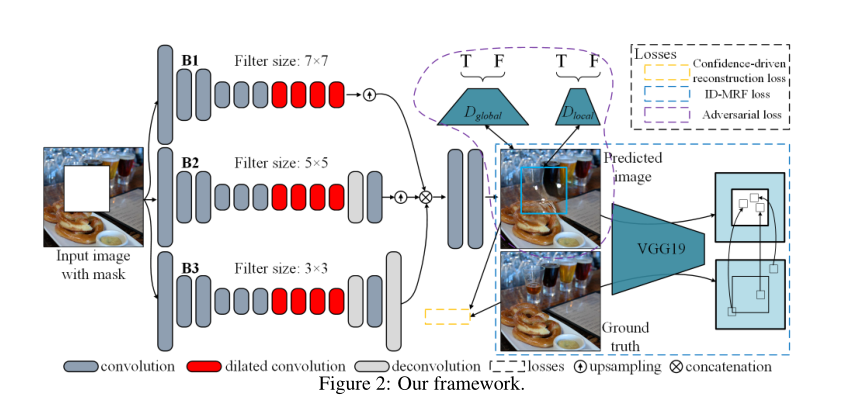
The training is an end-to-end method. The input is X broken picture and mask m, the filling value of the damaged area is 0, M is binary mask, 0 represents known pixels and 1 represents the damaged area.
###2.1 network architecture
As shown in the figure above, it contains three sub networks. A generative network, a global and local discriminator network, and a pre trained VGG network are used to calculate ID MRF loss. In the test phase, only the generated network is used.
The generator network consists of three parallel branches of encoding decoding convolution structure to extract different levels of features of input data (broken picture and mask M). A shared decoder network concatenates the features extracted by the three branches (the size of the feature map here is as large as the size of the original picture) as input, The combined features are decoded into the data space of the natural image (i.e. image restoration). As shown in Figure 2, the three branches use different receptive fields for feature extraction. Different receptive fields will inevitably lead to different sizes of the final feature map, so the feature maps extracted from the three branches are not good at concat combination. In this paper, bilinear interpolation is used for up sampling to expand the size of the feature map.
Although the three branches seem to be independent of each other, they affect each other due to the shared decoder
2.2 ID-MRF Regularization
This part solves the above semantic structure matching and iterative MRF optimization problem with large amount of calculation. The plan is to adopt the normalization of MRF only in the training stage ID-MRF optimizes the difference between the content of the generated region (repaired region) and the nearest neighbor region of the corresponding real image in the feature space. Because it is only used in training, the complete ground truth image can let us know the high-quality nearest neighbor and give the network appropriate constraints.
To calculate the ID-MRF loss, you can simply use a direct similarity measure (such as cosine similarity) to find the nearest neighbor of the patch in the generated content. However, this process often produces smooth structures, because a flat area is easy to connect to similar patterns and quickly reduces the diversity of structures. We use the relative distance measure [17,16,22] to model the relationship between local features and target feature sets. It can restore the subtle details shown in Figure 3(b).

Specifically, use Y g ∗ Y_g^* Yg * represents the content of the repair result of the missing area, Y g ∗ L Y_g^{*L} Yg * L and Y L Y^L YL represents the characteristics of layer L from the pre training model, respectively.
patch v and s are from
Y
g
∗
L
Y_g^{*L}
Yg * L and
Y
L
Y^L
YL, the relative similarity between v and s is defined as:
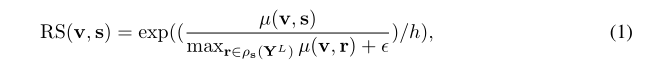
Note: Y is a real picture
Here (.) Is to calculate cosine similarity. r ∈ p s ( Y L ) r\in ps(Y^L) r ∈ ps(YL) means that r belongs to something other than s Y L Y^L YL,h and ϵ \epsilon ϵ Are two normal numbers. If v ratio Y L Y^L Other patch es in YL are more like s, and RS (V, s) will become larger.
Next, RS(v,s) is normalized to:

Finally, according to formula 2, Y g ∗ L Y_g^{*L} Yg * L and Y L Y^L The ID-MRF loss between YL is defined as:

Z here is the standardized parameter, which belongs to Y L Y^L YL's patch s, v ' = a r g m a x v ∈ Y g ∗ L R S ( v , s ) ∗ v'=arg max_{v\in Y_g^{*L} }RS(v,s)^* v'=argmaxv∈Yg∗LRS(v,s)∗.
Taste v 'relative to
Y
g
∗
L
Y_g^{*L}
Other patches in Yg * L are closer to patch s. An extreme example is
Y
g
∗
L
Y_g^{*L}
All paths in Yg * L are very close to a patch s. And other patch r 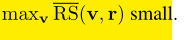
Therefore, the value of Lm (L) is greater.
On the other hand, when Y g ∗ L Y_g^{*L} patch and in Yg * L Y L Y^L The candidates in YL are very close, Y L Y^L Every patch r in YL Y g ∗ L Y_g^{*L} Yg * l has a unique nearest neighbor. Then the result is that RS' (v,r) becomes larger and LM(L) becomes smaller.
From this point of view, minimize LM(L) encouragement Y g ∗ L Y_g^{*L} Each patch V in Yg * L is different from Y L Y^L The patch in YL makes it diversified.
An obvious advantage of this method is that it improves the Y g ∗ L Y_g^{*L} Yg * L and Y L Y^L Similarity between YL feature distributions. By minimizing the loss of ID-MRF, not only local nerve patch in Y L Y^L The corresponding candidate textures are found in YL, and the feature distribution is closer, which is helpful to capture the changes of complex textures.
Our final ID-MRF loss is calculated on several feature layers of VGG19. According to general practice [5,14], we use conv4_2 describe the semantic structure of image. Then use conv3_2 and conv4_2 4 describe the image texture as:
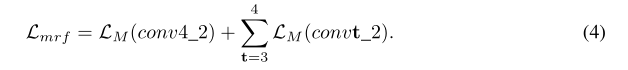
2.3 Information Fusion
-
Space reconstruction loss
The damaged area close to the boundary should have more constraints than that far from the boundary.
-
Generate countermeasure loss
Adopt more optimized w-GAN to realize
2.4 final loss function
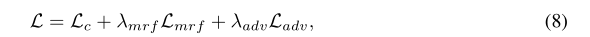
###2.5 training methods
First, the use of reconstruction alone is imminent λ m r f and λ a d v \lambda_{mrf} and \ lambda_{adv} λ mrf # and λ adv # is set to 0 for training to stabilize the subsequent confrontation training.
After G-convergence, we set up the model λ mrf = 0.05 and λ adv = 0.001 fine tune until convergence. Adam optimizer [13] is used to optimize the training process, and the learning rate is 1e4. set up β 1 = 0.5, β 2 = 0.9. The batch size is 16.
3. Detailed explanation and implementation of pytorch source code of gmcnn
3.1 training configuration code, train_options.py
import argparse
import os
import time
class TrainOptions:
def __init__(self):
self.parser = argparse.ArgumentParser()
self.initialized = False
def initialize(self):
# experiment specifics
self.parser.add_argument('--dataset', type=str, default='Celebhq',help='dataset of the experiment.')
#self.parser.add_argument('--data_file', type=str, default='', help='the file storing training image paths')
self.parser.add_argument('--data_file', type=str, default='/root/workspace/pyproject/inpainting_gmcnn-master/pytorch/util/celeba_256_train.txt', help='the file storing training image paths')#This file is the absolute path of each picture stored
self.parser.add_argument('--gpu_ids', type=str, default='0', help='gpu ids: e.g. 0 0,1,2')
self.parser.add_argument('--checkpoint_dir', type=str, default='./checkpoints', help='models are saved here')
# self.parser.add_argument('--load_model_dir', type=str, default='', help='pretrained models are given here')
self.parser.add_argument('--load_model_dir', type=str, default='/root/workspace/pyproject/inpainting_gmcnn-master/pytorch/checkpoints/20210509-164655_GMCNN_Celebhq_b8_s256x256_gc32_dc64_randmask-rect_pretrain', help='pretrained models are given here')
self.parser.add_argument('--phase', type=str, default='train')
# input/output sizes
# self.parser.add_argument('--batch_size', type=int, default=16, help='input batch size')
self.parser.add_argument('--batch_size', type=int, default=8, help='input batch size')
# for setting inputs
self.parser.add_argument('--random_crop', type=int, default=1,
help='using random crop to process input image when '
'the required size is smaller than the given size')
self.parser.add_argument('--random_mask', type=int, default=1)
self.parser.add_argument('--mask_type', type=str, default='rect')
self.parser.add_argument('--pretrain_network', type=int, default=0)#wm, whether it is a pre training network, 1 stands for pre training, pre training is to generate the network only by reconstructing the loss training, 0 stands for fine-tuning the network, plus ID-MRF and generating confrontation loss
self.parser.add_argument('--lambda_adv', type=float, default=1e-3)
self.parser.add_argument('--lambda_rec', type=float, default=1.4)
self.parser.add_argument('--lambda_ae', type=float, default=1.2)
self.parser.add_argument('--lambda_mrf', type=float, default=0.05)
self.parser.add_argument('--lambda_gp', type=float, default=10)
self.parser.add_argument('--random_seed', type=bool, default=False)
self.parser.add_argument('--padding', type=str, default='SAME')
self.parser.add_argument('--D_max_iters', type=int, default=5)#During training, the generator trains every 5 times, and then updates the network of the discriminator once
self.parser.add_argument('--lr', type=float, default=1e-5, help='learning rate for training')
self.parser.add_argument('--train_spe', type=int, default=1000)
self.parser.add_argument('--epochs', type=int, default=40)
self.parser.add_argument('--viz_steps', type=int, default=5)
self.parser.add_argument('--spectral_norm', type=int, default=1)
self.parser.add_argument('--img_shapes', type=str, default='256,256,3',
help='given shape parameters: h,w,c or h,w')
self.parser.add_argument('--mask_shapes', type=str, default='128,128',
help='given mask parameters: h,w')
self.parser.add_argument('--max_delta_shapes', type=str, default='32,32')
self.parser.add_argument('--margins', type=str, default='0,0')
# for generator
self.parser.add_argument('--g_cnum', type=int, default=32,
help='# of generator filters in first conv layer')
self.parser.add_argument('--d_cnum', type=int, default=64,
help='# of discriminator filters in first conv layer')
# for id-mrf computation
self.parser.add_argument('--vgg19_path', type=str, default='vgg19_weights/imagenet-vgg-verydeep-19.mat')
# for instance-wise features
self.initialized = True
def parse(self):
if not self.initialized:
self.initialize()
self.opt = self.parser.parse_args()
self.opt.dataset_path = self.opt.data_file
str_ids = self.opt.gpu_ids.split(',')
self.opt.gpu_ids = []
for str_id in str_ids:
id = int(str_id)
if id >= 0:
self.opt.gpu_ids.append(str(id))
assert self.opt.random_crop in [0, 1]
self.opt.random_crop = True if self.opt.random_crop == 1 else False
assert self.opt.random_mask in [0, 1]
self.opt.random_mask = True if self.opt.random_mask == 1 else False
assert self.opt.pretrain_network in [0, 1]
self.opt.pretrain_network = True if self.opt.pretrain_network == 1 else False
assert self.opt.spectral_norm in [0, 1]
self.opt.spectral_norm = True if self.opt.spectral_norm == 1 else False
assert self.opt.padding in ['SAME', 'MIRROR']
assert self.opt.mask_type in ['rect', 'stroke']
str_img_shapes = self.opt.img_shapes.split(',')
self.opt.img_shapes = [int(x) for x in str_img_shapes]
str_mask_shapes = self.opt.mask_shapes.split(',')
self.opt.mask_shapes = [int(x) for x in str_mask_shapes]
str_max_delta_shapes = self.opt.max_delta_shapes.split(',')
self.opt.max_delta_shapes = [int(x) for x in str_max_delta_shapes]
str_margins = self.opt.margins.split(',')
self.opt.margins = [int(x) for x in str_margins]
# model name and date
self.opt.date_str = time.strftime('%Y%m%d-%H%M%S')
self.opt.model_name = 'GMCNN'
self.opt.model_folder = self.opt.date_str + '_' + self.opt.model_name
self.opt.model_folder += '_' + self.opt.dataset
self.opt.model_folder += '_b' + str(self.opt.batch_size)
self.opt.model_folder += '_s' + str(self.opt.img_shapes[0]) + 'x' + str(self.opt.img_shapes[1])
self.opt.model_folder += '_gc' + str(self.opt.g_cnum)
self.opt.model_folder += '_dc' + str(self.opt.d_cnum)
self.opt.model_folder += '_randmask-' + self.opt.mask_type if self.opt.random_mask else ''
self.opt.model_folder += '_pretrain' if self.opt.pretrain_network else ''
if os.path.isdir(self.opt.checkpoint_dir) is False:
os.mkdir(self.opt.checkpoint_dir)
self.opt.model_folder = os.path.join(self.opt.checkpoint_dir, self.opt.model_folder)
if os.path.isdir(self.opt.model_folder) is False:
os.mkdir(self.opt.model_folder)
# set gpu ids
if len(self.opt.gpu_ids) > 0:
os.environ['CUDA_VISIBLE_DEVICES'] = ','.join(self.opt.gpu_ids)
args = vars(self.opt)
print('------------ Options -------------')
for k, v in sorted(args.items()):
print('%s: %s' % (str(k), str(v)))
print('-------------- End ----------------')
return self.opt
3.2 training code train py
import os
from torch.utils.data import DataLoader
from torchvision import transforms
import torchvision.utils as vutils
from tensorboardX import SummaryWriter
from data.data import InpaintingDataset, ToTensor
from model.net import InpaintingModel_GMCNN
from options.train_options import TrainOptions
from util.utils import getLatest
import tqdm
config = TrainOptions().parse()#wm obtains the training configuration information and super parameters
print("Training configuration information config:",config)#wm
print('loading data........')
#wm, load the data set according to the absolute path of the picture
dataset = InpaintingDataset(config.dataset_path, '', transform=transforms.Compose([
ToTensor()#The image data will be converted into tensor, and the values are between 0-1
]))
#wm, generate batch of data set_ Size iterator
dataloader = DataLoader(dataset, batch_size=config.batch_size, shuffle=True, num_workers=4, drop_last=True)
print('data load end.........')
print('configuring model..')
ourModel = InpaintingModel_GMCNN(in_channels=4, opt=config)#wm, instantiate a GMCNN model according to the training configuration information parameters
ourModel.print_networks()#Print model network
if config.load_model_dir != '':
print('Loading pretrained model from {}'.format(config.load_model_dir))
ourModel.load_networks(getLatest(os.path.join(config.load_model_dir, '*.pth')))
print('Loading done.')
# ourModel = torch.nn.DataParallel(ourModel).cuda()
print('model setting up..')
print('training initializing..')
writer = SummaryWriter(log_dir=config.model_folder)#Instantiate a log class using tensorboardX
cnt = 0#Used to record the number of batches trained_ size
#config.epochs=30
for epoch in range(config.epochs):
for i, data in enumerate(dataloader):
gt = data['gt'].cuda()
# normalize to values between -1 and 1,
gt = gt / 127.5 - 1
data_in = {'gt': gt}
ourModel.setInput(data_in)#wm, a batch_ The pictures in size are sent to the network
ourModel.optimize_parameters()#wm, through this batch_size data to train the network and optimize the parameters
if (i+1) % config.viz_steps == 0: #viz_steps=5
ret_loss = ourModel.get_current_losses()#wm to obtain various loss values calculated from the current batch data
if config.pretrain_network is False:
print(
'[%d, %5d] G_loss: %.4f (rec: %.4f, ae: %.4f, adv: %.4f, mrf: %.4f), D_loss: %.4f'
% (epoch + 1, i + 1, ret_loss['G_loss'], ret_loss['G_loss_rec'], ret_loss['G_loss_ae'],
ret_loss['G_loss_adv'], ret_loss['G_loss_mrf'], ret_loss['D_loss']))
writer.add_scalar('adv_loss', ret_loss['G_loss_adv'], cnt)
writer.add_scalar('D_loss', ret_loss['D_loss'], cnt)
writer.add_scalar('G_mrf_loss', ret_loss['G_loss_mrf'], cnt)
else:
print('[%d, %5d] G_loss: %.4f (rec: %.4f, ae: %.4f)'
% (epoch + 1, i + 1, ret_loss['G_loss'], ret_loss['G_loss_rec'], ret_loss['G_loss_ae']))
#wm, add the values of various losses to the log class writer. cnt is the number of batches trained_ size
writer.add_scalar('G_loss', ret_loss['G_loss'], cnt)
writer.add_scalar('reconstruction_loss', ret_loss['G_loss_rec'], cnt)
writer.add_scalar('autoencoder_loss', ret_loss['G_loss_ae'], cnt)
#images contains three types of graphs
images = ourModel.get_current_visuals_tensor()
im_completed = vutils.make_grid(images['completed'], normalize=True, scale_each=True)#Repaired graph
im_input = vutils.make_grid(images['input'], normalize=True, scale_each=True)#Input masked graph
im_gt = vutils.make_grid(images['gt'], normalize=True, scale_each=True)#Real picture
# wm, add the graph generated in the training process to the log class writer. cnt is the number of batches trained_ size
writer.add_image('gt', im_gt, cnt)
writer.add_image('input', im_input, cnt)
writer.add_image('completed', im_completed, cnt)
#wm, 1000 batches per training_ Size, save the model once
if (i+1) % config.train_spe == 0:#wm,train_spe=1000
print('saving model ..')
ourModel.save_networks(epoch+1)
cnt += 1
ourModel.save_networks(epoch+1)#Save the model of the last epoch
writer.export_scalars_to_json(os.path.join(config.model_folder, 'GMCNN_scalars.json'))
writer.close()
3.3 build GMCNN net py
import torch
import torch.nn as nn
import torch.nn.functional as F
from model.basemodel import BaseModel
from model.basenet import BaseNet
from model.loss import WGANLoss, IDMRFLoss
from model.layer import init_weights, PureUpsampling, ConfidenceDrivenMaskLayer, SpectralNorm
import numpy as np
# generative multi-column convolutional neural net
#1. The branch convolution network of gmcnn, that is, the network of repairer, uses different receptive fields for feature extraction
class GMCNN(BaseNet):
def __init__(self, in_channels, out_channels, cnum=32, act=F.elu, norm=F.instance_norm, using_norm=False):
super(GMCNN, self).__init__()
self.act = act
self.using_norm = using_norm
if using_norm is True:
self.norm = norm
else:
self.norm = None
ch = cnum
# network structure
self.EB1 = []#wm, first branch
self.EB2 = []#wm, second branch
self.EB3 = []#wm, third branch
self.decoding_layers = []#A shared decoder layer
self.EB1_pad_rec = []
self.EB2_pad_rec = []
self.EB3_pad_rec = []
self.EB1.append(nn.Conv2d(in_channels, ch, kernel_size=7, stride=1))
self.EB1.append(nn.Conv2d(ch, ch * 2, kernel_size=7, stride=2))
self.EB1.append(nn.Conv2d(ch * 2, ch * 2, kernel_size=7, stride=1))
self.EB1.append(nn.Conv2d(ch * 2, ch * 4, kernel_size=7, stride=2))
self.EB1.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=7, stride=1))
self.EB1.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=7, stride=1))
self.EB1.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=7, stride=1, dilation=2))
self.EB1.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=7, stride=1, dilation=4))
self.EB1.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=7, stride=1, dilation=8))
self.EB1.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=7, stride=1, dilation=16))
self.EB1.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=7, stride=1))
self.EB1.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=7, stride=1))
self.EB1.append(PureUpsampling(scale=4))
self.EB1_pad_rec = [3, 3, 3, 3, 3, 3, 6, 12, 24, 48, 3, 3, 0]
self.EB2.append(nn.Conv2d(in_channels, ch, kernel_size=5, stride=1))
self.EB2.append(nn.Conv2d(ch, ch * 2, kernel_size=5, stride=2))
self.EB2.append(nn.Conv2d(ch * 2, ch * 2, kernel_size=5, stride=1))
self.EB2.append(nn.Conv2d(ch * 2, ch * 4, kernel_size=5, stride=2))
self.EB2.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=5, stride=1))
self.EB2.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=5, stride=1))
self.EB2.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=5, stride=1, dilation=2))
self.EB2.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=5, stride=1, dilation=4))
self.EB2.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=5, stride=1, dilation=8))
self.EB2.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=5, stride=1, dilation=16))
self.EB2.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=5, stride=1))
self.EB2.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=5, stride=1))
self.EB2.append(PureUpsampling(scale=2, mode='nearest'))
self.EB2.append(nn.Conv2d(ch * 4, ch * 2, kernel_size=5, stride=1))
self.EB2.append(nn.Conv2d(ch * 2, ch * 2, kernel_size=5, stride=1))
self.EB2.append(PureUpsampling(scale=2))
self.EB2_pad_rec = [2, 2, 2, 2, 2, 2, 4, 8, 16, 32, 2, 2, 0, 2, 2, 0]
self.EB3.append(nn.Conv2d(in_channels, ch, kernel_size=3, stride=1))
self.EB3.append(nn.Conv2d(ch, ch * 2, kernel_size=3, stride=2))
self.EB3.append(nn.Conv2d(ch * 2, ch * 2, kernel_size=3, stride=1))
self.EB3.append(nn.Conv2d(ch * 2, ch * 4, kernel_size=3, stride=2))
self.EB3.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=3, stride=1))
self.EB3.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=3, stride=1))
self.EB3.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=3, stride=1, dilation=2))
self.EB3.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=3, stride=1, dilation=4))
self.EB3.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=3, stride=1, dilation=8))
self.EB3.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=3, stride=1, dilation=16))
self.EB3.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=3, stride=1))
self.EB3.append(nn.Conv2d(ch * 4, ch * 4, kernel_size=3, stride=1))
self.EB3.append(PureUpsampling(scale=2, mode='nearest'))
self.EB3.append(nn.Conv2d(ch * 4, ch * 2, kernel_size=3, stride=1))
self.EB3.append(nn.Conv2d(ch * 2, ch * 2, kernel_size=3, stride=1))
self.EB3.append(PureUpsampling(scale=2, mode='nearest'))
self.EB3.append(nn.Conv2d(ch * 2, ch, kernel_size=3, stride=1))
self.EB3.append(nn.Conv2d(ch, ch, kernel_size=3, stride=1))
self.EB3_pad_rec = [1, 1, 1, 1, 1, 1, 2, 4, 8, 16, 1, 1, 0, 1, 1, 0, 1, 1]
self.decoding_layers.append(nn.Conv2d(ch * 7, ch // 2, kernel_size=3, stride=1))
self.decoding_layers.append(nn.Conv2d(ch // 2, out_channels, kernel_size=3, stride=1))
self.decoding_pad_rec = [1, 1]
self.EB1 = nn.ModuleList(self.EB1)#Combine list module connections into a network structure
self.EB2 = nn.ModuleList(self.EB2)
self.EB3 = nn.ModuleList(self.EB3)
self.decoding_layers = nn.ModuleList(self.decoding_layers)
# padding operations
padlen = 49
self.pads = [0] * padlen
for i in range(padlen):
self.pads[i] = nn.ReflectionPad2d(i)
self.pads = nn.ModuleList(self.pads)
def forward(self, x):#Copy three copies of a picture and send them to three branches respectively
x1, x2, x3 = x, x, x
for i, layer in enumerate(self.EB1):
pad_idx = self.EB1_pad_rec[i]
x1 = layer(self.pads[pad_idx](x1))#padding the periphery of the feature map, and then convolution
if self.using_norm:
x1 = self.norm(x1)
if pad_idx != 0:
x1 = self.act(x1)#Characteristic graph result of branch 1
for i, layer in enumerate(self.EB2):
pad_idx = self.EB2_pad_rec[i]
x2 = layer(self.pads[pad_idx](x2))
if self.using_norm:
x2 = self.norm(x2)
if pad_idx != 0:
x2 = self.act(x2)#Characteristic graph results of branch 2
for i, layer in enumerate(self.EB3):
pad_idx = self.EB3_pad_rec[i]
x3 = layer(self.pads[pad_idx](x3))
if self.using_norm:
x3 = self.norm(x3)
if pad_idx != 0:
x3 = self.act(x3)#Characteristic graph result of branch 3
x_d = torch.cat((x1, x2, x3), 1)#wm, combine the results of the three branches with cat
#wm, via encoder
x_d = self.act(self.decoding_layers[0](self.pads[self.decoding_pad_rec[0]](x_d)))
x_d = self.decoding_layers[1](self.pads[self.decoding_pad_rec[1]](x_d))
x_out = torch.clamp(x_d, -1, 1)#wm, limit the value between - 1 and 1
return x_out#A batch is returned_ Size, the data type is tensor, and the range of values is (- 1, 1)
# return one dimensional output indicating the probability of realness or fakeness
#2. Basic discriminator module
class Discriminator(BaseNet):
def __init__(self, in_channels, cnum=32, fc_channels=8*8*32*4, act=F.elu, norm=None, spectral_norm=True):
super(Discriminator, self).__init__()
self.act = act
self.norm = norm
self.embedding = None
self.logit = None
ch = cnum
self.layers = []
if spectral_norm:
self.layers.append(SpectralNorm(nn.Conv2d(in_channels, ch, kernel_size=5, padding=2, stride=2)))
self.layers.append(SpectralNorm(nn.Conv2d(ch, ch * 2, kernel_size=5, padding=2, stride=2)))
self.layers.append(SpectralNorm(nn.Conv2d(ch * 2, ch * 4, kernel_size=5, padding=2, stride=2)))
self.layers.append(SpectralNorm(nn.Conv2d(ch * 4, ch * 4, kernel_size=5, padding=2, stride=2)))
self.layers.append(SpectralNorm(nn.Linear(fc_channels, 1)))#Returns a scalar, which represents the score of the image. It gives a high score for the real image and a low score for the repaired image
else:
self.layers.append(nn.Conv2d(in_channels, ch, kernel_size=5, padding=2, stride=2))
self.layers.append(nn.Conv2d(ch, ch * 2, kernel_size=5, padding=2, stride=2))
self.layers.append(nn.Conv2d(ch*2, ch*4, kernel_size=5, padding=2, stride=2))
self.layers.append(nn.Conv2d(ch*4, ch*4, kernel_size=5, padding=2, stride=2))
self.layers.append(nn.Linear(fc_channels, 1))#Returns a scalar, which represents the score of the image. It gives a high score for the real image and a low score for the repaired image
self.layers = nn.ModuleList(self.layers)#Combine the module connections in the list into a network structure
def forward(self, x):
for layer in self.layers[:-1]:
x = layer(x)
if self.norm is not None:
x = self.norm(x)
x = self.act(x)
self.embedding = x.view(x.size(0), -1)#The characteristic graph obtained by convolution is expanded into one-dimensional vector
self.logit = self.layers[-1](self.embedding)
return self.logit#Returns a scalar, which represents the score of the image. It gives a high score for the real image and a low score for the repaired image
#3 integrated discriminator, using the basic discriminator module, combines the global discriminator and the local discriminator. The difference is that the size of the feature map is different, that is, the length of the last layer is different after it is expanded into a one-dimensional vector
class GlobalLocalDiscriminator(BaseNet):
def __init__(self, in_channels, cnum=32, g_fc_channels=16*16*32*4, l_fc_channels=8*8*32*4, act=F.elu, norm=None,
spectral_norm=True):
super(GlobalLocalDiscriminator, self).__init__()
self.act = act
self.norm = norm
self.global_discriminator = Discriminator(in_channels=in_channels, fc_channels=g_fc_channels, cnum=cnum,
act=act, norm=norm, spectral_norm=spectral_norm)
self.local_discriminator = Discriminator(in_channels=in_channels, fc_channels=l_fc_channels, cnum=cnum,
act=act, norm=norm, spectral_norm=spectral_norm)
def forward(self, x_g, x_l):
x_global = self.global_discriminator(x_g)
x_local = self.local_discriminator(x_l)
return x_global, x_local#What is put back is the score of the global discriminator and the score of the local discriminator
from util.utils import generate_mask
#4. Use the previous modules to form the GMCNN repair model
class InpaintingModel_GMCNN(BaseModel):
def __init__(self, in_channels, act=F.elu, norm=None, opt=None):
super(InpaintingModel_GMCNN, self).__init__()
self.opt = opt
self.init(opt)
#A mask weight for calculating the loss is obtained. The mask weight of the good pixel is large, and the mask weight of the missing area is relatively small, which is in the shape of Gauss
self.confidence_mask_layer = ConfidenceDrivenMaskLayer()
#Instantiate a fixer
self.netGM = GMCNN(in_channels, out_channels=3, cnum=opt.g_cnum, act=act, norm=norm).cuda() #wm, three parallel networks + one decoder, and put them on cuda
init_weights(self.netGM)#wm, initialize network
self.model_names = ['GM']
if self.opt.phase == 'test':
return
self.netD = None
#wm, put the network parameters of the generator into the Adam optimizer
self.optimizer_G = torch.optim.Adam(self.netGM.parameters(), lr=opt.lr, betas=(0.5, 0.9))
self.optimizer_D = None
self.wganloss = None
self.recloss = nn.L1Loss()
self.aeloss = nn.L1Loss()
self.mrfloss = None
self.lambda_adv = opt.lambda_adv#Generate the hyperparameter of the counter loss weight
self.lambda_rec = opt.lambda_rec#Reconstruction of lost hyperparameters
self.lambda_ae = opt.lambda_ae
self.lambda_gp = opt.lambda_gp#Medium super parameters of w-gan
self.lambda_mrf = opt.lambda_mrf#Weight hyperparameter of mrf loss
self.G_loss = None
self.G_loss_reconstruction = None
self.G_loss_mrf = None
self.G_loss_adv, self.G_loss_adv_local = None, None
self.G_loss_ae = None
self.D_loss, self.D_loss_local = None, None
self.GAN_loss = None
self.gt, self.gt_local = None, None
self.mask, self.mask_01 = None, None
self.rect = None
self.im_in, self.gin = None, None
self.completed, self.completed_local = None, None
self.completed_logit, self.completed_local_logit = None, None
self.gt_logit, self.gt_local_logit = None, None
self.pred = None
#wm, if the model is not pre trained, a discriminator network needs to be instantiated. Pre training here refers to pre training the model only with reconstruction loss:
if self.opt.pretrain_network is False:
if self.opt.mask_type == 'rect':
self.netD = GlobalLocalDiscriminator(3, cnum=opt.d_cnum, act=act,
g_fc_channels=opt.img_shapes[0]//16*opt.img_shapes[1]//16*opt.d_cnum*4,
l_fc_channels=opt.mask_shapes[0]//16*opt.mask_shapes[1]//16*opt.d_cnum*4,
spectral_norm=self.opt.spectral_norm).cuda()
else:
self.netD = GlobalLocalDiscriminator(3, cnum=opt.d_cnum, act=act,
spectral_norm=self.opt.spectral_norm,
g_fc_channels=opt.img_shapes[0]//16*opt.img_shapes[1]//16*opt.d_cnum*4,
l_fc_channels=opt.img_shapes[0]//16*opt.img_shapes[1]//16*opt.d_cnum*4).cuda()
init_weights(self.netD)#Initialize discriminator
self.optimizer_D = torch.optim.Adam(filter(lambda x: x.requires_grad, self.netD.parameters()), lr=opt.lr,
betas=(0.5, 0.9))#Put the network parameters of the discriminator into the Adam optimizer
self.wganloss = WGANLoss()#Instantiation WGAN loss
self.mrfloss = IDMRFLoss()#Instantiation IDMRF loss
#Initialize various variables and obtain the input picture data of the input generator network
def initVariables(self):
self.gt = self.input['gt']#Get a batch_ True graph of size
mask, rect = generate_mask(self.opt.mask_type, self.opt.img_shapes, self.opt.mask_shapes)#wm, generate mask, and location of rectangular hole
self.mask_01 = torch.from_numpy(mask).cuda().repeat([self.opt.batch_size, 1, 1, 1])#0 represents the intact area and 1 represents the missing area, which is converted from numpy format to tensor
self.mask = self.confidence_mask_layer(self.mask_01)#Mask weight parameter, which is used to calculate the reconstruction loss
if self.opt.mask_type == 'rect':
self.rect = [rect[0, 0], rect[0, 1], rect[0, 2], rect[0, 3]]
#Used to get the real picture of the part
self.gt_local = self.gt[:, :, self.rect[0]:self.rect[0] + self.rect[1],self.rect[2]:self.rect[2] + self.rect[3]]
else:
self.gt_local = self.gt
self.im_in = self.gt * (1 - self.mask_01)#Only the intact area is the original true value, and the value of the empty area is 0
self.gin = torch.cat((self.im_in, self.mask_01), 1)#This is the first input to repair the image data in the network, four channels
#Forward calculation of the generator to obtain various losses of the generator
def forward_G(self):
self.G_loss_reconstruction = self.recloss(self.completed * self.mask, self.gt.detach() * self.mask)#The final repair result and the loss of the real image are calculated, and the mask weight is used
self.G_loss_reconstruction = self.G_loss_reconstruction / torch.mean(self.mask_01)
self.G_loss_ae = self.aeloss(self.pred * (1 - self.mask_01), self.gt.detach() * (1 - self.mask_01))#Calculate the loss of the original intact area and the predicted intact area
self.G_loss_ae = self.G_loss_ae / torch.mean(1 - self.mask_01)
self.G_loss = self.lambda_rec * self.G_loss_reconstruction + self.lambda_ae * self.G_loss_ae#Multiply the reconstruction loss by the relevant weight coefficient
if self.opt.pretrain_network is False:#If it is not pre training, the generation countermeasure loss and ID-MRF loss must also be calculated
# discriminator
self.completed_logit, self.completed_local_logit = self.netD(self.completed, self.completed_local)#Obtain the global score and local score of the repaired graph by the discriminator network
self.G_loss_mrf = self.mrfloss((self.completed_local+1)/2.0, (self.gt_local.detach()+1)/2.0)#Calculate ID-MRF loss
self.G_loss = self.G_loss + self.lambda_mrf * self.G_loss_mrf#Generator loss plus ID-MRF loss
self.G_loss_adv = -self.completed_logit.mean()#Generate global loss of confrontation
self.G_loss_adv_local = -self.completed_local_logit.mean()#Local loss of confrontation
self.G_loss = self.G_loss + self.lambda_adv * (self.G_loss_adv + self.G_loss_adv_local)#Total loss
# The forward calculation discriminator obtains various losses of the discriminator
def forward_D(self):
self.completed_logit, self.completed_local_logit = self.netD(self.completed.detach(), self.completed_local.detach())#d score the global and local identification of the repaired image
self.gt_logit, self.gt_local_logit = self.netD(self.gt, self.gt_local)#Score the global and local identification of real pictures
# hinge loss
self.D_loss_local = nn.ReLU()(1.0 - self.gt_local_logit).mean() + nn.ReLU()(1.0 + self.completed_local_logit).mean()#Local loss discriminator
self.D_loss = nn.ReLU()(1.0 - self.gt_logit).mean() + nn.ReLU()(1.0 + self.completed_logit).mean()#Loss to global picture discriminator
self.D_loss = self.D_loss + self.D_loss_local
#Gradient of back propagation calculation generator
def backward_G(self):
self.G_loss.backward()
#Gradient of back propagation computational discriminator
def backward_D(self):
self.D_loss.backward(retain_graph=True)
#Forward flow of data flow
def optimize_parameters(self):
self.initVariables()
self.pred = self.netGM(self.gin)#Send the damaged pictures to the repair network for repair, and get the prediction results
self.completed = self.pred * self.mask_01 + self.gt * (1 - self.mask_01)#Replace the predicted image and intact area with the previous true value, and then the final repair result is obtained
if self.opt.mask_type == 'rect':
self.completed_local = self.completed[:, :, self.rect[0]:self.rect[0] + self.rect[1],
self.rect[2]:self.rect[2] + self.rect[3]]
else:
self.completed_local = self.completed
if self.opt.pretrain_network is False:#If it is not in the pre training stage and only uses the reconstruction loss to train the generator network, there is also the generation of countermeasure loss
for i in range(self.opt.D_max_iters):
self.optimizer_D.zero_grad()#The gradient of the discriminator network is 0
self.optimizer_G.zero_grad()#The gradient of the generator network is 0
self.forward_D()#Forward propagation discriminator
self.backward_D()#Back propagation
self.optimizer_D.step()#Update network parameters of discriminator
self.optimizer_G.zero_grad()#The gradient of the generator network is 0
self.forward_G()#Generator forward propagation
self.backward_G()#Generator back propagation
self.optimizer_G.step()#Update the network parameters of the generator
#Return all the current losses, and use the dictionary structure data to return
def get_current_losses(self):
l = {'G_loss': self.G_loss.item(), 'G_loss_rec': self.G_loss_reconstruction.item(),
'G_loss_ae': self.G_loss_ae.item()}#If it is the pre training stage, there is only reconstruction loss
if self.opt.pretrain_network is False:
l.update({'G_loss_adv': self.G_loss_adv.item(),
'G_loss_adv_local': self.G_loss_adv_local.item(),
'D_loss': self.D_loss.item(),
'G_loss_mrf': self.G_loss_mrf.item()})
return l
#Get the current network input image, real image, and finally repair the image. The image data is in tensor format
def get_current_visuals(self):
return {'input': self.im_in.cpu().detach().numpy(), 'gt': self.gt.cpu().detach().numpy(),
'completed': self.completed.cpu().detach().numpy()}
#Get the current network input image, real image, and finally repair the image. The image data is in tensor format
def get_current_visuals_tensor(self):
return {'input': self.im_in.cpu().detach(), 'gt': self.gt.cpu().detach(),
'completed': self.completed.cpu().detach()}
#Evaluate images
def evaluate(self, im_in, mask):
im_in = torch.from_numpy(im_in).type(torch.FloatTensor).cuda() / 127.5 - 1
mask = torch.from_numpy(mask).type(torch.FloatTensor).cuda()
im_in = im_in * (1-mask)
xin = torch.cat((im_in, mask), 1)
ret = self.netGM(xin) * mask + im_in * (1-mask)
ret = (ret.cpu().detach().numpy() + 1) * 127.5
return ret.astype(np.uint8)
3.4 some commonly used loss Py, including ID MRF loss
import torch
import torch.nn as nn
import torch.autograd as autograd
import torch.nn.functional as F
from model.layer import VGG19FeatLayer
from functools import reduce
class WGANLoss(nn.Module):
def __init__(self):
super(WGANLoss, self).__init__()
def __call__(self, input, target):
d_loss = (input - target).mean()
g_loss = -input.mean()
return {'g_loss': g_loss, 'd_loss': d_loss}
def gradient_penalty(xin, yout, mask=None):
gradients = autograd.grad(yout, xin, create_graph=True,
grad_outputs=torch.ones(yout.size()).cuda(), retain_graph=True, only_inputs=True)[0]
if mask is not None:
gradients = gradients * mask
gradients = gradients.view(gradients.size(0), -1)
gp = ((gradients.norm(2, dim=1) - 1) ** 2).mean()
return gp
def random_interpolate(gt, pred):
batch_size = gt.size(0)
alpha = torch.rand(batch_size, 1, 1, 1).cuda()
# alpha = alpha.expand(gt.size()).cuda()
interpolated = gt * alpha + pred * (1 - alpha)
return interpolated
class IDMRFLoss(nn.Module):
def __init__(self, featlayer=VGG19FeatLayer):
super(IDMRFLoss, self).__init__()
self.featlayer = featlayer()
self.feat_style_layers = {'relu3_2': 1.0, 'relu4_2': 1.0}
self.feat_content_layers = {'relu4_2': 1.0}
self.bias = 1.0
self.nn_stretch_sigma = 0.5
self.lambda_style = 1.0
self.lambda_content = 1.0
def sum_normalize(self, featmaps):
reduce_sum = torch.sum(featmaps, dim=1, keepdim=True)
return featmaps / reduce_sum
def patch_extraction(self, featmaps):
patch_size = 1
patch_stride = 1
patches_as_depth_vectors = featmaps.unfold(2, patch_size, patch_stride).unfold(3, patch_size, patch_stride)
self.patches_OIHW = patches_as_depth_vectors.permute(0, 2, 3, 1, 4, 5)
dims = self.patches_OIHW.size()
self.patches_OIHW = self.patches_OIHW.view(-1, dims[3], dims[4], dims[5])
return self.patches_OIHW
def compute_relative_distances(self, cdist):
epsilon = 1e-5
div = torch.min(cdist, dim=1, keepdim=True)[0]
relative_dist = cdist / (div + epsilon)
return relative_dist
def exp_norm_relative_dist(self, relative_dist):
scaled_dist = relative_dist
dist_before_norm = torch.exp((self.bias - scaled_dist)/self.nn_stretch_sigma)
self.cs_NCHW = self.sum_normalize(dist_before_norm)
return self.cs_NCHW
def mrf_loss(self, gen, tar):
meanT = torch.mean(tar, 1, keepdim=True)
gen_feats, tar_feats = gen - meanT, tar - meanT
gen_feats_norm = torch.norm(gen_feats, p=2, dim=1, keepdim=True)
tar_feats_norm = torch.norm(tar_feats, p=2, dim=1, keepdim=True)
gen_normalized = gen_feats / gen_feats_norm
tar_normalized = tar_feats / tar_feats_norm
cosine_dist_l = []
BatchSize = tar.size(0)
for i in range(BatchSize):
tar_feat_i = tar_normalized[i:i+1, :, :, :]
gen_feat_i = gen_normalized[i:i+1, :, :, :]
patches_OIHW = self.patch_extraction(tar_feat_i)
cosine_dist_i = F.conv2d(gen_feat_i, patches_OIHW)
cosine_dist_l.append(cosine_dist_i)
cosine_dist = torch.cat(cosine_dist_l, dim=0)
cosine_dist_zero_2_one = - (cosine_dist - 1) / 2
relative_dist = self.compute_relative_distances(cosine_dist_zero_2_one)
rela_dist = self.exp_norm_relative_dist(relative_dist)
dims_div_mrf = rela_dist.size()
k_max_nc = torch.max(rela_dist.view(dims_div_mrf[0], dims_div_mrf[1], -1), dim=2)[0]
div_mrf = torch.mean(k_max_nc, dim=1)
div_mrf_sum = -torch.log(div_mrf)
div_mrf_sum = torch.sum(div_mrf_sum)
return div_mrf_sum
def forward(self, gen, tar):
gen_vgg_feats = self.featlayer(gen)
tar_vgg_feats = self.featlayer(tar)
style_loss_list = [self.feat_style_layers[layer] * self.mrf_loss(gen_vgg_feats[layer], tar_vgg_feats[layer]) for layer in self.feat_style_layers]
self.style_loss = reduce(lambda x, y: x+y, style_loss_list) * self.lambda_style
#The reduce function accumulates elements
content_loss_list = [self.feat_content_layers[layer] * self.mrf_loss(gen_vgg_feats[layer], tar_vgg_feats[layer]) for layer in self.feat_content_layers]
self.content_loss = reduce(lambda x, y: x+y, content_loss_list) * self.lambda_content
return self.style_loss + self.content_loss
class StyleLoss(nn.Module):
def __init__(self, featlayer=VGG19FeatLayer, style_layers=None):
super(StyleLoss, self).__init__()
self.featlayer = featlayer()
if style_layers is not None:
self.feat_style_layers = style_layers
else:
self.feat_style_layers = {'relu2_2': 1.0, 'relu3_2': 1.0, 'relu4_2': 1.0}
def gram_matrix(self, x):
b, c, h, w = x.size()
feats = x.view(b * c, h * w)
g = torch.mm(feats, feats.t())
return g.div(b * c * h * w)
def _l1loss(self, gen, tar):
return torch.abs(gen-tar).mean()
def forward(self, gen, tar):
gen_vgg_feats = self.featlayer(gen)
tar_vgg_feats = self.featlayer(tar)
style_loss_list = [self.feat_style_layers[layer] * self._l1loss(self.gram_matrix(gen_vgg_feats[layer]), self.gram_matrix(tar_vgg_feats[layer])) for
layer in self.feat_style_layers]
style_loss = reduce(lambda x, y: x + y, style_loss_list)
return style_loss
class ContentLoss(nn.Module):
def __init__(self, featlayer=VGG19FeatLayer, content_layers=None):
super(ContentLoss, self).__init__()
self.featlayer = featlayer()
if content_layers is not None:
self.feat_content_layers = content_layers
else:
self.feat_content_layers = {'relu4_2': 1.0}
def _l1loss(self, gen, tar):
return torch.abs(gen-tar).mean()
def forward(self, gen, tar):
gen_vgg_feats = self.featlayer(gen)
tar_vgg_feats = self.featlayer(tar)
content_loss_list = [self.feat_content_layers[layer] * self._l1loss(gen_vgg_feats[layer], tar_vgg_feats[layer]) for
layer in self.feat_content_layers]
content_loss = reduce(lambda x, y: x + y, content_loss_list)
return content_loss
class TVLoss(nn.Module):
def __init__(self):
super(TVLoss, self).__init__()
def forward(self, x):
h_x, w_x = x.size()[2:]
h_tv = torch.abs(x[:, :, 1:, :] - x[:, :, :h_x-1, :])
w_tv = torch.abs(x[:, :, :, 1:] - x[:, :, :, :w_x-1])
loss = torch.sum(h_tv) + torch.sum(w_tv)
return loss
4 references
4.1 original paper
Image Inpainting via Generative Multi-column
Convolutional Neural Networks
4.2 source code
https://github.com/shepnerd/inpainting_gmcnn