Reprinted from AI Studio
Project link https://aistudio.baidu.com/aistudio/projectdetail/3539295
1. Project background
Considering that I study the interdisciplinary of artificial intelligence and oil and gas, I want to try whether I can start with basic rock recognition and do a small task of rock recognition.
The idea of this task comes from the second phase of AI talent Creation Camp. Interested partners are welcome to participate in the development of flying oars!
It can also be regarded as achieving a small goal. (people were forced out)
1.1 rock and oil and gas
Rock Detection and identification is the basic work of geological survey and mineral resources exploration. Accurate rock identification and classification is very important for geological detection and identification. Generally, it can be identified in many ways, such as gravity and magnetism, logging, earthquake, remote sensing, electromagnetism, geochemistry, hand specimen and thin section analysis methods.

1.2 daily details
In daily life, when we sprinkle a small amount of water on the sponge, we will find that the water penetrates into the pores of the sponge and will not flow out. Similar to this phenomenon, oil and natural gas are stored in pores and fractures of rocks. The rocks storing oil and gas are called reservoirs.
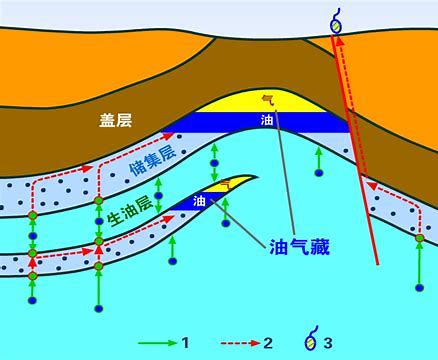
1.3 relationship between rock characteristics and oil
There are many kinds of rocks, nearly 100 of which have been recognized by people, but the rocks that can form reservoirs must have certain porosity and permeability. The porosity directly determines the amount of oil and gas stored in the rock stratum, and the permeability controls the productivity of oil and gas in the reservoir. There are many types of reservoirs found in China, mainly including sandstone reservoir, carbonate reservoir, volcanic reservoir, crystalline rock reservoir and argillaceous rock reservoir.
1.4 existing rock identification system
The "geological cloud" mineral and rock identification system of China Geological Survey of the Ministry of natural resources is a typical application of artificial intelligence (AI) technology in geological informatization. The basic principle is to use artificial intelligence to store the confirmed mineral and rock images in the geological cloud server, establish the recognition model, and recognize the newly collected mineral and rock images through computer deep learning. This system is an auxiliary tool for geological beginners and non geological workers to quickly understand and identify minerals and rocks.
Source: https://www.cgs.gov.cn/xwl/sp/yangshi/201810/t20181019_469426.html
1.5 self perception
When I saw the above system, I wondered if I could make one myself. He can do it, so can I! I am also a graduate student of the Great China Dynasty! I also learn AI! Besides, Baidu PaddlePaddle's kit has many tricks to play with flowers.
2. Data set selection
This data set is actually modified from the data set published by Baidu
The original dataset is this:
https://aistudio.baidu.com/aistudio/datasetdetail/85829#/
After modifying the toss for several versions, it was later found that the previously tossed data set had been made public and could not be deleted... In private, will someone look at the data set in the future and find that the quality is so poor, will they scold me to death?
Modified dataset 3.0:
https://aistudio.baidu.com/aistudio/datasetdetail/129645
However, in the later stage, due to insufficient understanding of the data set, I privately wrote some batch Modification codes and batch renaming procedures to deal with the pictures.
This data set mainly focuses on the basic rock categories, including "basalt", "granite", "marble", "quartzite", "coal", "limestone" and "sandstone".
Each category is a folder. It is recommended to use PaddleX to automatically divide this data set, which is convenient for thieves!
One of the pictures looks like this: it's very dark!

Of course it's black. It's coal!
#Decompress data set !unzip -oq data/data129645/RockData.zip -d data/ #One run is enough #One run is enough #One run is enough
#View dataset tree !tree data/RockData/
# Import dependency Library import cv2 import os import numpy as np import matplotlib.pyplot as plt
#Picture sampling
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
%matplotlib inline
#Read the path of a folder in the dataset
file_dir = '/home/aistudio/data/RockData/Coal/'
#Set up a list to store picture names
filesum = []
#Read picture name
for root, dirs, files in os.walk(file_dir):
filesum.append(files)
filesum = filesum[0]
#Print the picture name to see if the effect is not as expected
#print(filesum)
#Define canvas size
plt.figure(figsize=(8, 8))
#Cycle to read and display pictures
for i in range(1,5):
plt.subplot(2,2,i)
plt.title(filesum[i])
image = file_dir+filesum[i]
#print(f">>>{image}")
plt.imshow(cv2.imread(image,1))
plt.tight_layout()
plt.show()

3. PaddleX installation
Here I use the PaddleX suite, which will greatly save development efficiency in dealing with image classification. The relevant documents are as follows:
PaddleX project official website:
https://www.paddlepaddle.org.cn/paddle/paddlex
PaddleX Github address:
https://github.com/PaddlePaddle/PaddleX
PaddleX API development mode can be used quickly:
https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/quick_start_API.md
PaddleX indicators and logs:
https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/appendix/metrics.md
#Install version 2.1.0 using pip installation: !pip install paddlex==2.1.0 -i https://mirror.baidu.com/pypi/simple
#When training the model, we need to divide the training set, verification set and test set #Therefore, it is necessary to divide the above data. The data set can be randomly divided into 70% training set, 20% verification set and 10% test set by directly using the paddlex command #The divided data sets generate additional labels txt, train_ list. txt, val_ list. txt, test_ list. Txt four files, after which you can train directly. !paddlex --split_dataset --format ImageNet --dataset_dir /home/aistudio/data/RockData --val_value 0.2 --test_value 0.1
3.1 MobileNetV3
The model uses MobileNetV3 Baidu modification, which is the MobileNetV3 pre training model obtained by Baidu based on distillation method. The model structure is consistent with MobileNetV3, but the accuracy is higher.
3.2 open source versions of other platforms of mobilenetv3
(1) PyTorch implementation 1: https://github.com/xiaolai-sqlai/mobilenetv3
(2) PyTorch implementation 2: https://github.com/kuan-wang/pytorch-mobilenet-v3
(3) PyTorch implementation 3: https://github.com/leaderj1001/MobileNetV3-Pytorch
(4) Caffe implementation: https://github.com/jixing0415/caffe-mobilenet-v3
(5) TensorFLow implementation: https://github.com/Bisonai/mobilenetv3-tensorflow
3.3 main contents
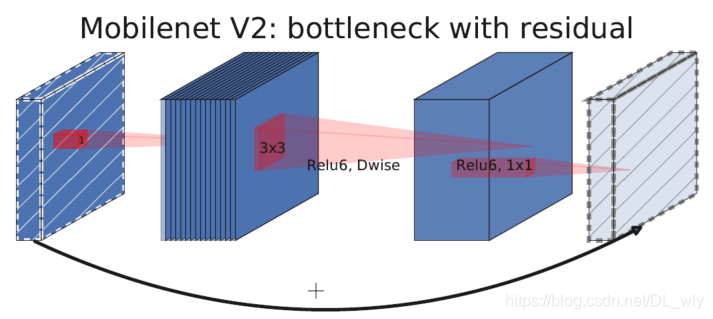
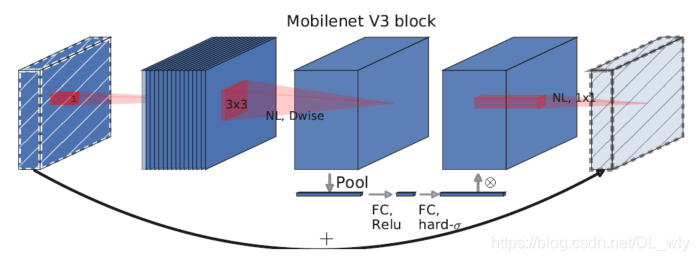
The above two figures are the network block structure of MobileNetV2 and MobileNetV3.
MobileNetV3 integrates the ideas of the following three models:
Deep wise separable convolutions of MobileNetV1
The inverted residual with linear bottleneck of MobileNetV2
MnasNet's lightweight attention model based on squeeze and excitation structure
Please refer to "Searching for MobileNetV3" for detailed papers
I won't repeat it here
4. Configure the super parameters and train the model
#Data processing during training and verification
from paddlex import transforms as T
train_transforms = T.Compose([
#Free cutting of pictures
T.RandomCrop(crop_size=224),
T.Normalize()])
eval_transforms = T.Compose([
#Custom image size
T.ResizeByShort(short_size=256),
T.CenterCrop(crop_size=224),
T.Normalize()
])
import paddlex as pdx
#Define dataset, PDX datasets. ImageNet means to read the classified data set in ImageNet format:
train_dataset = pdx.datasets.ImageNet(
data_dir='/home/aistudio/data/RockData',
file_list='/home/aistudio/data/RockData/train_list.txt',
label_list='/home/aistudio/data/RockData/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.ImageNet(
data_dir='/home/aistudio/data/RockData',
file_list='/home/aistudio/data/RockData/val_list.txt',
label_list='/home/aistudio/data/RockData/labels.txt',
transforms=eval_transforms)
2022-03-02 11:48:47 [INFO] Starting to read file list from dataset... 2022-03-02 11:48:47 [INFO] 1442 samples in file /home/aistudio/data/RockData/train_list.txt 2022-03-02 11:48:47 [INFO] Starting to read file list from dataset... 2022-03-02 11:48:47 [INFO] 408 samples in file /home/aistudio/data/RockData/val_list.txt
4.1 General statistical information of training
The following fields will be displayed during output. The specific meanings are as follows:
| field | Examples | meaning |
|---|---|---|
| Epoch | Epoch=4/20 | [number of iterations] all training data will be trained for 20 rounds and is currently in the fourth round |
| Step | Step=62/66 | [iterative steps] the number of iterative steps required for all training data to be trained for one round is 66, which is currently in step 62 |
| loss | loss=0.007226 | [loss function value] the average loss function value loss of the training samples participating in the current iteration steps. The lower the loss value, the better the fitting effect of the model on the training set (as above, the first line in the log indicates that the loss value of the 62nd Batch of the fourth epoch is 0.007226) |
| lr | lr=0.008215 | [learning rate] the learning rate during the iteration of the current model |
| time_each_step | time_each_step=0.41s | [iteration time of each step] the average iteration time of each step calculated in the training process |
| eta | eta=0:9:44 | [remaining time] the remaining time required to complete the model training is estimated to be 0 hours, 9 minutes and 44 seconds |
4.2 training log field
In addition to general statistical information, the training log of classification tasks also includes two unique fields: acc1 and acc5.
Note: acck accuracy is calculated for a picture: the prediction scores of the model in each category are sorted from high to low, and the first k prediction categories are taken out. If these K prediction categories include truth value category, the picture is considered to be classified correctly.
acc1 represents the average top1 accuracy of the training samples participating in the current iteration steps. The higher the value, the better the model;
acc5 represents the average accuracy of top5 (if the number of categories n is less than 5, it is topn) of the training samples participating in the current iteration steps. The higher the value, the better the model.
For example:
[TRAIN] Epoch=1/10, Step=20/22, loss=1.064334, acc1=0.671875, acc5=0.968750, lr=0.025000, time_each_step=0.15s, eta=0:0:31
Representative:
Epoch=1/10 [number of iteration rounds] all training data will be trained for 10 rounds, and is currently in the first round;
Step=20/22 [iterative steps] the number of iterative steps required for all training data to be trained for one round is 22, which is currently in step 20;
loss=1.064334 [loss function value] loss value is 1.064334;
Acc1 = 0.671875. Acc1 indicates that the average top1 accuracy of the whole verification set is 0.671875;
Acc5 = 0.968750. Acc5 means that the average top5 accuracy of the whole verification set is 0.968750;
lr=0.025000 [learning rate] the learning rate in the iteration process of the current model;
time_each_step=0.15s [iteration time of each step] the average time of each iteration calculated in the training process;
eta=0:0:31 [remaining time] the remaining time required for the completion of model training is estimated to be 0 hours, 0 minutes and 31 seconds;
#Using the MobileNetV3 pre training model obtained by Baidu based on distillation method, the model structure is consistent with MobileNetV3, but the accuracy is higher.
# num_classes is the number of categories. It needs to be customized. The default is 1000
num_classes = len(train_dataset.labels)
model = pdx.cls.MobileNetV3_small(num_classes=num_classes)
model.train(num_epochs=10,
train_dataset=train_dataset,
train_batch_size=64,
eval_dataset=eval_dataset,
lr_decay_epochs=[4, 6, 8],
save_dir='output/mobilenetv3_small',
#The output of training is saved in output/mobilenetv3_small
use_vdl=True)
#use_vdl=True indicates that you can start visual DL and view the changes of visual indicators.
5. Test model effect
#During the training of the model, the model will be saved once every certain number of rounds
#The best round of evaluation on the validation set will be saved in save_dir directory under best_model folder
#Load the model for prediction:
import paddlex as pdx
model = pdx.load_model('output/mobilenetv3_small/best_model')
result = model.predict('/home/aistudio/data/RockData/Coal/Coal271.jpg')
#Set forecast result as title
plt.title(result[0]['category'])
#Display predicted image
plt.imshow(cv2.imread('/home/aistudio/data/RockData/Coal/Coal271.jpg',1))
#Print forecast results
print("Predict Result: ", result)
print("Category is:", result[0]['category'])
2022-03-02 11:57:22 [INFO] Model[MobileNetV3_small] loaded.
Predict Result: [{'category_id': 1, 'category': 'Coal', 'score': 0.97934693}]
Category is: Coal

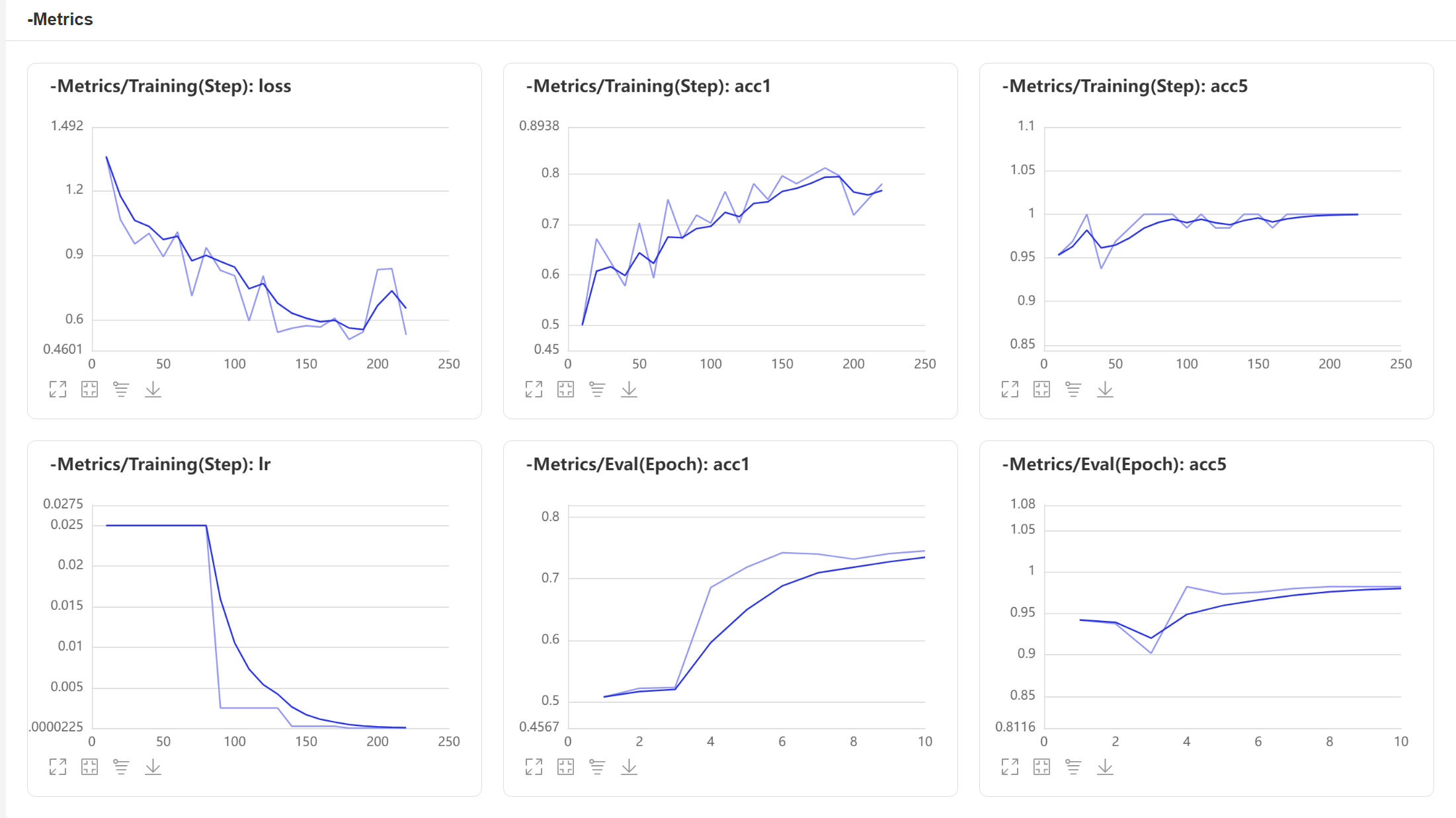
6. Visual model effect
Click the penultimate item on the left toolbar of AIstudio: [data model visualization]
Set logdir to [! cat output/mobilenetv3_small/vdl_log /]
Click [start VisualDL service]
Additional (optional) model deployment
If you don't use the model to deploy, the following code doesn't need to be run
The following code is to generate the model required for deployment
For detailed documents, please refer to:
PaddleX deployment model export
!paddlex --export_inference --model_dir=./output/mobilenetv3_small/best_model/ --save_dir=./inference_model
7. Summary
7.1 data sets
This time I completed the task of rock identification with PaddleX. In the process of using PaddleX, I was greatly helped by the support of official documents and course resources.
As we all know, the quality of data sets can directly affect the results of model operation.
The processing of data sets by PaddleX makes the division of data sets very convenient and greatly reduces the time spent on manual adjustment of data sets. In the past, the operation of data set division can be completed with only one line of code.
At the same time, PaddleX's pre training model can quickly and easily develop AI tasks, making developers focus on data set sorting and parameter tuning.
In fact, this is also one of the main development directions of AI+X. AI+X often has poor results, which is actually due to the lack of data sets. In the oil and gas industry, the lack of data sets is the pain point and obstacle to the development of AI + oil and gas.
The future AI must be the combination of knowledge, data, algorithm and computing power.
7.2 PaddleX pre training model
PaddleX has a wealth of pre training models, including 38 kinds of pre training models for image classification. What's more, the use of its pre training model only needs to call the relevant API. All classification models provide the same training train, evaluation, predict ion and sensitivity analysis_ Sensitivity, clipping prune and online quantization quant_aware_train and other interfaces are very convenient.
In other words, as long as you can use any one of the models, you will be able to define and use other models!
The links of each model are as follows:
7.3 conclusion
Teenagers always like to toss about. Otherwise, the history of the world won't stir up waves. Later, they plan to build their own network to realize this task and have a deeper understanding of the bits and pieces in the process of AI training. However, due to the current level of chicken and chicken dishes, they still step by step to practice more training parameters, and look at the projects of big guys to absorb nutrients and grow themselves.
Most importantly, people are really forced out! If you don't force yourself, you won't know how powerful you are!
8. About Me
Climb the steps and see the scenery
A graduate student of artificial intelligence from China University of Petroleum (Beijing), head of CUP propeller pilot group, open source enthusiast and contributor of an open source system of the open atom open source foundation. Welcome to learn (volume) AI together!
Where To Find me 🔍
● Github: mrcangye
● Gitee: mrcangye
● PaddlePaddle: mrcangye
● Email: mrcangye@email.cn
WeChat official account: the Growth Diary of cangye
● China University of Petroleum (Beijing) propeller pilot group: [QQ group] 819267743