Actual combat PP tinypose + picodet: application of new intelligent body measurement mode
Introduction to PP tinypose
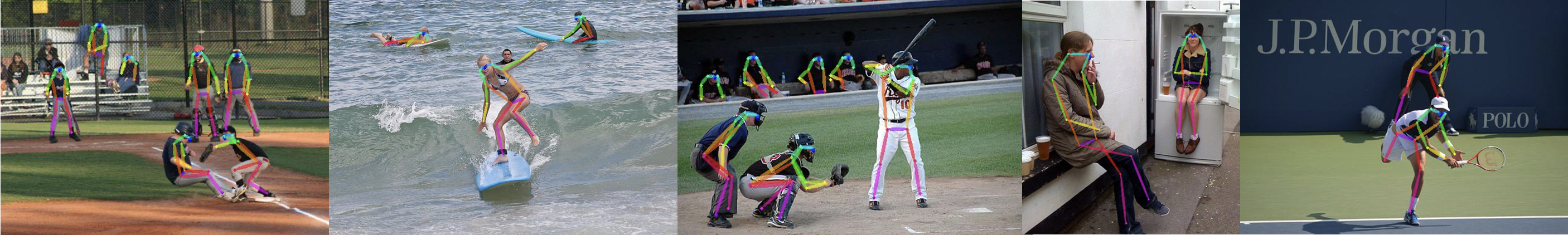
PP tinypose is a real-time attitude detection model optimized by paddedetection for mobile devices, which can smoothly perform multi person attitude estimation tasks on mobile devices. Excellent lightweight detection model developed by paddedetection PicoDet At the same time, we provide a characteristic lightweight pedestrian detection model.
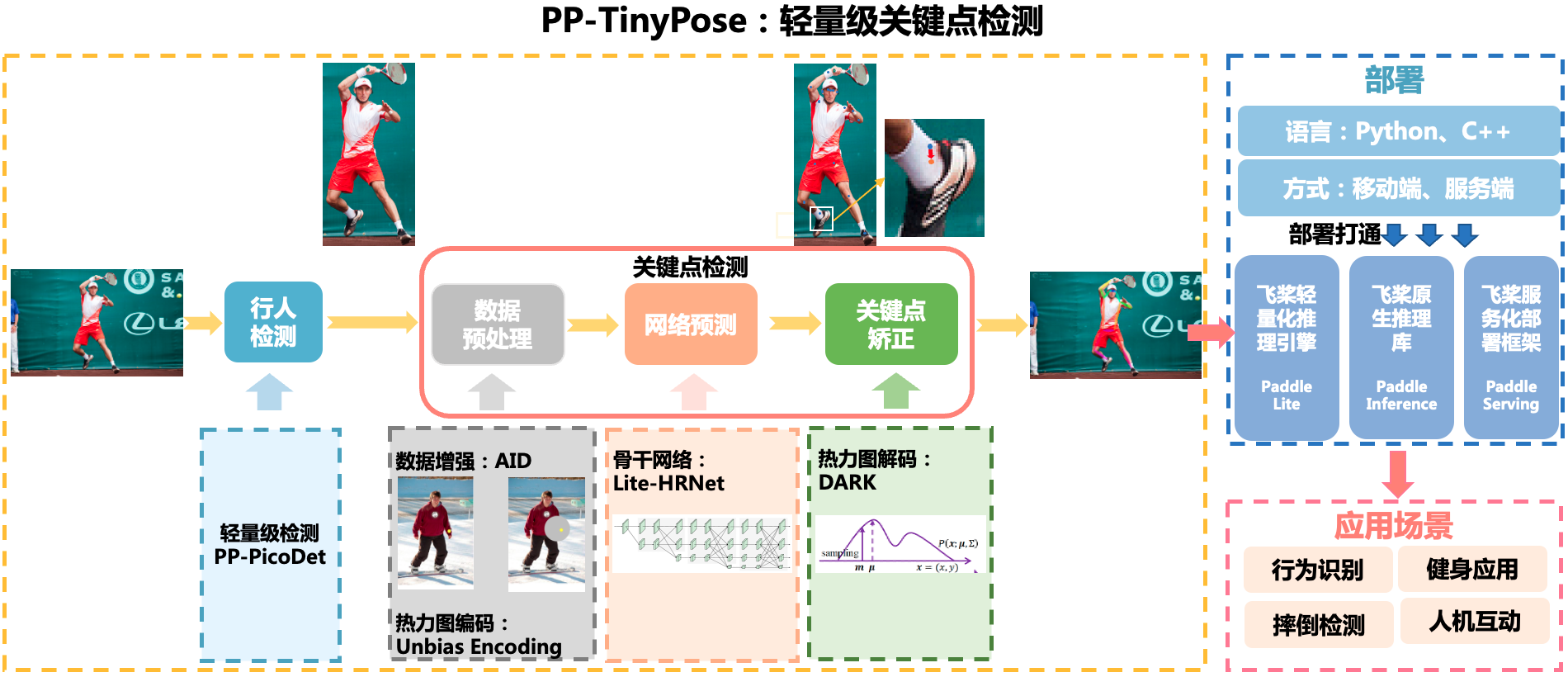
Introduction to paddedetection
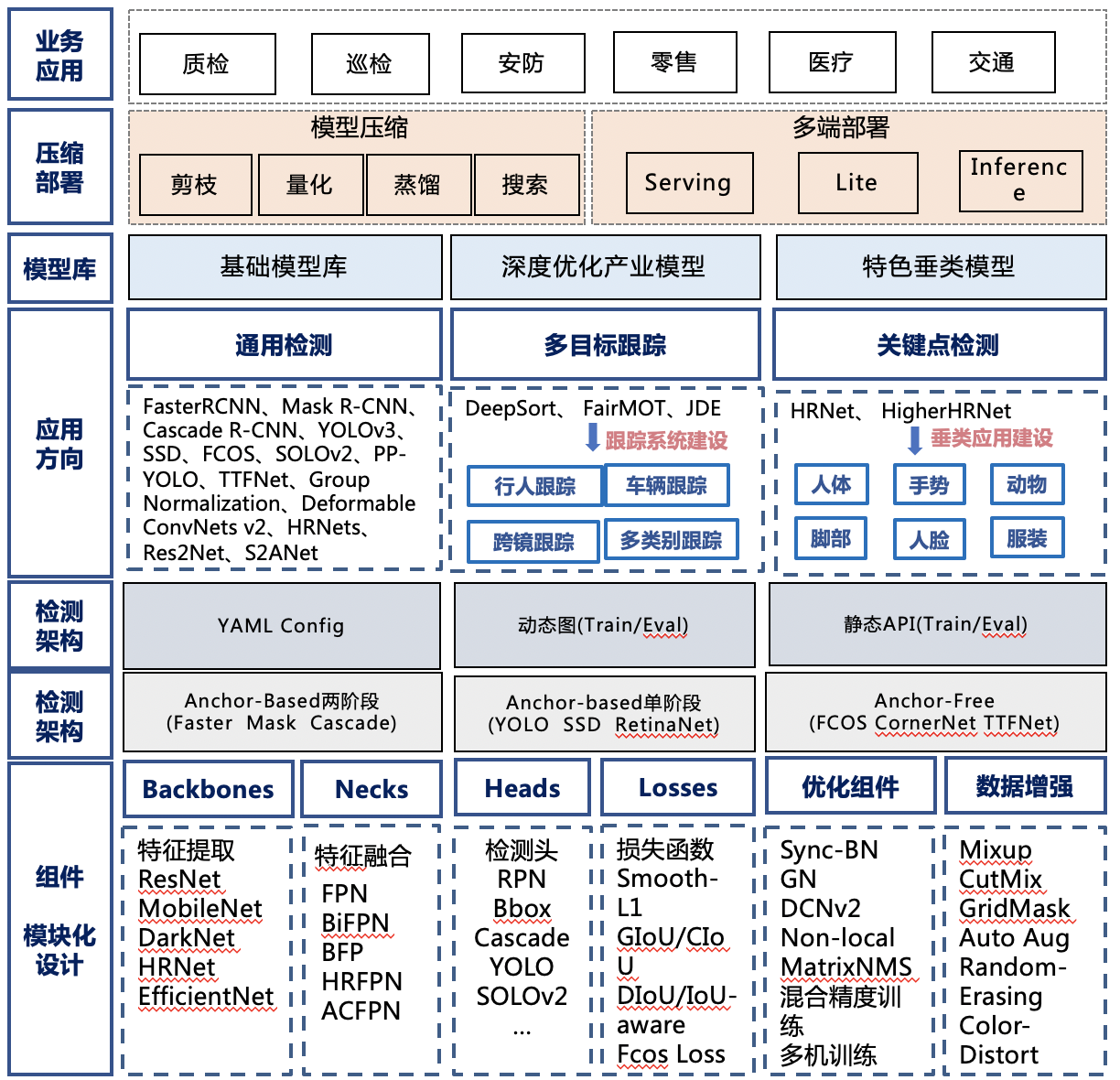
PaddleDetection is an end to end target detection suite based on PaddlePaddle, which provides a variety of mainstream target detection, case segmentation, tracking, and key point detection algorithms. At present, it introduces a variety of server and mobile terminal industrial SOTA models, and integrates model compression and high performance deployment capabilities across platforms. It can help developers to finish the end-to-end full development process faster and better.
- Github address: https://github.com/PaddlePaddle/PaddleDetection
- Gitee address: https://gitee.com/PaddlePaddle/PaddleDetection
Hands on practice
Preparing code and running environment
Download the paddedetection code and complete the environment configuration
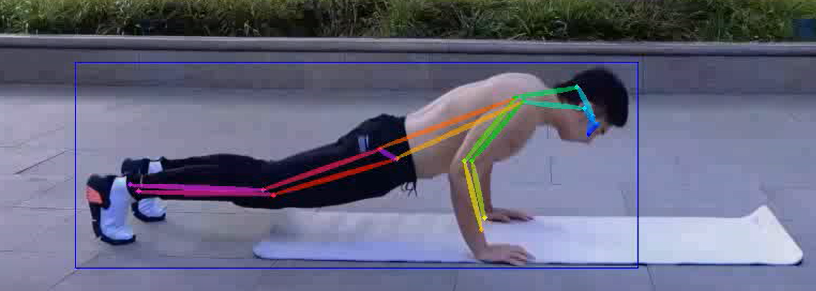
Effect display
Take 2 pictures from the video to show
Project background
According to the latest data in the report on nutrition and chronic diseases of Chinese residents (2020), there are more than 1% of adults in China/2 People are overweight or obese, adult residents(≥18 The overweight rate was 34.3%,The obesity rate was 16.4%. This is the first time in a national survey report that more than 1/2 Such a number. At the same time, 1/5(19%)6-17 1 year old children and adolescents/10(10.4%)Of children under 6 years old are overweight or obese. According to the absolute population, 600 million people in China are overweight and obese, which is the first in the world. Recently, the lancet-Diabetes and Endocrinology ( The Lancet Diabetes & Endocrinology)Published a Chinese obesity album( Obesity in China Series). At present, the album has launched two articles "epidemiology and determinants of obesity in China" and "clinical management and treatment of obesity in China". At the same time, most people in the gym, due to economic reasons, not everyone can get the support of professional fitness coaches, so fitness can not achieve the effect, so we came up with an idea, can we train one AI Assistant to help us correct our fitness actions and achieve better fitness results. When you see the pictures below, do you feel guilty again after having supper tonight

1. Environmental preparation
- First, clone the paddedetection code on github
- Installation related environment dependencies
- Switch to the relevant path
# Download the paddedetection code !unzip -oq /home/aistudio/data/data121638/PaddleDetection.zip
# Installation related environment dependencies !pip install --upgrade pip -i https://mirror.baidu.com/pypi/simple !pip install paddlepaddle-gpu==2.2.0.post101 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html -i https://mirror.baidu.com/pypi/simple !cd PaddleDetection && pip install --upgrade -r requirements.txt -i https://mirror.baidu.com/pypi/simple
- Use the following command to switch the default working directory to the paddedetection folder
import os
os.chdir("./PaddleDetection/")
!pwd
2. Prepare training data
- If you need to realize the training of user-defined data, you need to convert the user-defined data set into COCO format. For details, please refer to [key point data preparation document]. ( https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.3/docs/tutorials/PrepareKeypointDataSet_cn.md)
- In the corresponding configuration file (. yml), modify the annotation file path, data path, etc. to make them consistent with the user-defined dataset you want to use.
- In this project, we prepared a mini data set. You can experience how to walk through the whole training process through this mini data set.
- The data set does not need to be downloaded from the Internet. Run the following cell directly
# Download / decompress the dataset and organize the dataset path !wget https://bj.bcebos.com/v1/paddledet/data/keypoint/coco_val_person_mini.tar !tar -xf coco_val_person_mini.tar -C ./dataset/ !mv ./dataset/coco_val_person_mini/* ./dataset/coco !cp ./dataset/coco/annotations/aic_coco_train_cocoformat.json ./dataset/ !cp ./dataset/coco/annotations/instances_val2017.json ./dataset/coco/annotations/person_keypoints_val2017.json
3. Model training
- This project requires two model trainings, namely pedestrian_ The pedestrian detection model and TinyPose key point detection model of detection take a long time. Students who can't wait can go to the model on github_ Zoo downloads the model, but the accuracy is low
- Call the startup command Python tools / train.exe during training Py later life development profile and pre training weight
- The configuration file in this project has been configured and does not need to be modified
- model_zoo link: https://github.com/PaddlePaddle/PaddleDetection/tree/develop#ModelZoo
!python tools/train.py -c configs/picodet/application/pedestrian_detection/picodet_s_320_pedestrian.yml \
-o pretrain_weights=https://paddledet.bj.bcebos.com/models/picodet_s_320_coco.pdparams \
--eval
- Training TinyPose key point detection model
!python tools/train.py -c configs/keypoint/tiny_pose/tinypose_128x96.yml
- After the above model training is completed, it will be saved in output / picodet by default_ s_ 320_ Pedestrian and output/tinypose_128x96 folder
4. Model evaluation
- When the training is completed, use the following command to evaluate the accuracy of the model.
- Here we use the model we have trained. If you want to use your own training model, please change the value after weights = to the corresponding model The storage path of the pdparams file.
- Use the startup command Python tools / eval Py can perform an evaluation, and then declare the configuration file and weight path
# Pedestrian detection model !python tools/eval.py -c configs/picodet/application/pedestrian_detection/picodet_s_320_pedestrian.yml \ -o weights=https://paddledet.bj.bcebos.com/models/picodet_s_320_pedestrian.pdparams #Key point detection model !python tools/eval.py -c configs/keypoint/tiny_pose/tinypose_128x96.yml \ -o weights=https://bj.bcebos.com/v1/paddledet/models/keypoint/tinypose_128x96.pdparams
5. Model prediction
- 1. Export the two models to output_inference
- 2. After the model is exported, the joint deployment prediction is carried out. The predicted targets can be pictures and videos
- 3. The prediction results are saved in paddedetection /
Model export
- The pedestrian detection and key point detection models are derived respectively, and the trained models are used here. If you want to use your own training model, please change the value after weights = to the corresponding model The storage path of the pdparams file.
- Start python tools/export_model.py start export
- The exported model will be stored in output by default_ Information / path
# Export pedestrian detection model
!python tools/export_model.py -c configs/picodet/application/pedestrian_detection/picodet_s_320_pedestrian.yml \
-o weights=https://paddledet.bj.bcebos.com/models/picodet_s_320_pedestrian.pdparams
# Export key detection model
!python tools/export_model.py -c configs/keypoint/tiny_pose/tinypose_128x96.yml \
-o weights=https://bj.bcebos.com/v1/paddledet/models/keypoint/tinypose_128x96.pdparams
Realize prediction
- After the model is exported, we use the joint deployment prediction method to predict the picture or video.
- The predicted visualization result image will be stored under output / by default.
!python deploy/python/det_keypoint_unite_infer.py --det_model_dir=output_inference/picodet_s_320_pedestrian \
--keypoint_model_dir=output_inference/tinypose_128x96 \
--image_file=demo/1.png --device=GPU --keypoint_threshold=0.35
# Visual prediction picture
import cv2
import matplotlib.pyplot as plt
import numpy as np
image = cv2.imread('output/000000570688_vis.jpg')
plt.figure(figsize=(15,10))
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.show()
6. The video is predicted below
- During video prediction, the processing result of the returned video is under paddedetection /, and a json file is generated at the same time
- json contains the number of frames of the predicted video, the x, y coordinates and confidence of the key points
!python deploy/python/det_keypoint_unite_infer.py --det_model_dir=output_inference/picodet_s_320_pedestrian \ --keypoint_model_dir=output_inference/tinypose_128x96 \ --video_file=1.MP4 \ --output_dir=../ \ --keypoint_threshold=0.2 \ .2 \ --device=gpu --save_res=True
7. Apply
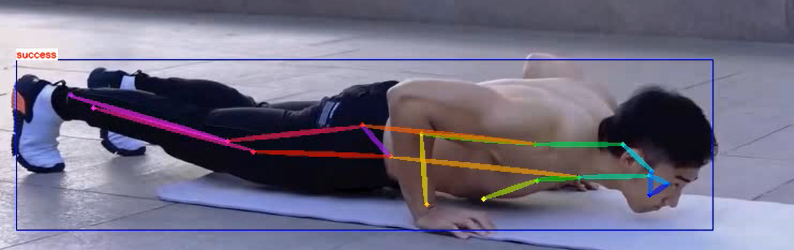
We can be right json After reading the files and videos, make a logical judgment, and then make a standard judgment of push ups. The judgment logic is given below:
COCO keypoint indexes: 0: 'nose', 1: 'left_eye', 2: 'right_eye', 3: 'left_ear', 4: 'right_ear', 5: 'left_shoulder', 6: 'right_shoulder', 7: 'left_elbow', 8: 'right_elbow', 9: 'left_wrist', 10: 'right_wrist', 11: 'left_hip', 12: 'right_hip', 13: 'left_knee', 14: 'right_knee', 15: 'left_ankle', 16: 'right_ankle'
A total of 17 key points are detected, corresponding to 17 parts of the human body respectively. Here, only 5, 7, 9 and 6, 8 and 10 will be used, corresponding to the left and right arms of the human body respectively. In this project, when the angle of the left or right elbow passes through 90 degrees, or the height of the elbow is higher than the shoulder, it means that the push up action is completed. At this time, it will be displayed in the video success
Logic judgment core code: if (left_small_arm+left_big_arm)>a or (right_small_arm+right_big_arm)>b: if kpts_arr[5,1]<kpts_arr[7,1] or kpts_arr[6,1]<kpts_arr[8,1]:
%cd ../
import os
import sys
import cv2
import numpy as np
import json
import collections
from source import check_fall_down, videovis
#1) The first parameter of the script is the key point prediction result json file
jsonf = "PaddleDetection/det_keypoint_unite_video_results.json"
with open(jsonf, "r") as rf:
kpts_data = json.load(rf)
print("all data length: {}".format(len(kpts_data)))
#2) If you need video to print text, the key visualization result file is placed in the same path
videof = "1.mp4"
#3) Read the key point results and put them into the judgment file
fallframes = check_fall_down(kpts_data)
#4) According to the detected fall frame, it is displayed in the video
videovis(videof, kpts_data, fallframes)
8. Summary and sublimation
- The prediction effect of the project has reached a high degree of confidence and has high application value. You can try it
- Other developers can develop faster and lighter models
Personal profile
I'm a third year undergraduate from Jiangsu University of science and technology. I've just come into contact with in-depth learning. I hope you will pay more attention
Interests: target detection, reinforcement learning, natural language processing
Personal link:
Ma Junxiao
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/824948
Please click here View the basic usage of this environment
Please click here for more detailed instructions.