- home page
- special column
- front end
- Article details
Audio signal classification and recognition based on Mel spectrum (pytoch)
 Integrity and win-win Published 5 minutes ago
Integrity and win-win Published 5 minutes agoThis project will use pytoch to realize a simple audio signal classifier, which can be applied to mechanical signal classification and recognition, bird call signal recognition and other application scenarios.
The project uses librosa for audio signal processing, and the backbone uses mobilenet_v2. On the Urbansound8K data, the accuracy of final convergence is 99% in the training set and 82% in the test set. If you want to further improve the recognition accuracy, you can use heavier backbone and more data enhancement methods.
Complete project code: https://download.csdn.net/dow...
catalogue
- Project structure
- Environment configuration
3. Data processing
(1) Dataset Urbansound8K
(2) Custom dataset
(3) Audio feature extraction:
4. Train Pipeline
5. Forecast demo.py
- Project structure
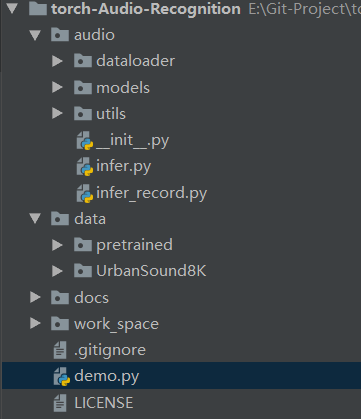
- Environment configuration
Use the pip command to install libsora, pyaudio,pydub and other libraries
3. Data processing
(1) Dataset Urbansound8K
Urbansound8K is a widely used public data set for automatic urban environmental sound classification,
It includes 10 categories: air conditioning sound, car whistle sound, children's play sound, dog barking, drilling sound, engine idling sound, gunshot sound, portable drill, police whistle sound and street music sound.
Dataset Download: https://www.ctocio.com/?s=%E9...
(2) Custom dataset
You can record audio signals and make your own data sets. Refer to [audio/dataloader/record_audio.py]
Each folder stores one category of audio data. The length of each audio data is about 3 seconds. It is recommended that each category of audio data be balanced
Production train and test data list: refer to [audio/dataloader/create_data.py]
(3) Audio feature extraction:
Audio signal is a one-dimensional speech signal, which can not be directly used for model training. librosa needs to be used to convert audio into Mel spectrum.
librosa provides python interface, which is often used in the analysis of audio and music signals
wav, sr = librosa.load(data_path, sr=16000)
Obtain Mel spectrum of audio using librosa
spec_image = librosa.feature.melspectrogram(y=wav, sr=sr, hop_length=256)
For the usage of librosa, please refer to:
Audio feature extraction -- using librosa Toolkit
Principle and application of Mel spectrum
4. Train Pipeline
(1) Build training and test data
def build_dataset(self, cfg):
"""Build training data and test data"""
input_shape = eval(cfg.input_shape)
# get data
train_dataset = AudioDataset(cfg.train_data, data_dir=cfg.data_dir, mode='train', spec_len=input_shape[3])
train_loader = DataLoader(dataset=train_dataset, batch_size=cfg.batch_size, shuffle=True,
num_workers=cfg.num_workers)
test_dataset = AudioDataset(cfg.test_data, data_dir=cfg.data_dir, mode='test', spec_len=input_shape[3])
test_loader = DataLoader(dataset=test_dataset, batch_size=cfg.batch_size, shuffle=False,
num_workers=cfg.num_workers)
print("train nums:{}".format(len(train_dataset)))
print("test nums:{}".format(len(test_dataset)))
return train_loader, test_loaderBecause librosa.load is very slow to load audio data, it is recommended to use cache first to facilitate acceleration
def load_audio(audio_file, cache=False):
"""
Load and preprocess audio
:param audio_file:
:param cache: librosa.load Loading audio data is particularly slow. It is recommended to use caching for acceleration
:return:
"""
# Read audio data
cache_path = audio_file + ".pk"
# t = librosa.get_duration(filename=audio_file)
if cache and os.path.exists(cache_path):
tmp = open(cache_path, 'rb')
wav, sr = pickle.load(tmp)
else:
wav, sr = librosa.load(audio_file, sr=16000)
if cache:
f = open(cache_path, 'wb')
pickle.dump([wav, sr], f)
f.close()
# Compute a Mel scaled spectrogram
spec_image = librosa.feature.melspectrogram(y=wav, sr=sr, hop_length=256)
return spec_image(2) Build backbone model
Backbone is a network structure based on CNN+FC. Different from the image CNN classification model, the input dimension (batch,3,H,W) of the image CNN classification model is depth=3, while the Mel spectrum of the audio signal is depth=1, which can be regarded as a gray image and the input dimension (batch,1,H,W). Therefore, in practical use, Only the first layer of the backbone needs to be classified by the traditional CNN image_ Channels = 1. It should be noted that the pre trained model of imagenet cannot be used due to inconsistent dimensions.
Of course, the Mel spectrum (grayscale image) can be transformed into a 3-channel RGB image, which is no different from ordinary RGB images. You can also use the pre trained model of imagenet, such as
The Mel spectrum (gray-scale image) is transformed into a 3-channel RGB image
spec_image = cv2.cvtColor(spec_image, cv2.COLOR_GRAY2RGB)
def build_model(self, cfg):
if cfg.net_type == "mbv2":
model = mobilenet_v2.mobilenet_v2(num_classes=cfg.num_classes)
elif cfg.net_type == "resnet34":
model = resnet.resnet34(num_classes=args.num_classes)
elif cfg.net_type == "resnet18":
model = resnet.resnet18(num_classes=args.num_classes)
else:
raise Exception("Error:{}".format(cfg.net_type))
model.to(self.device)
return model(3) Training parameter configuration
For relevant command line parameters, refer to:
def get_parser():
data_dir = "/media/pan/Newly added volume/dataset/UrbanSound8K"
# data_dir = "E:/dataset/UrbanSound8K"
train_data = 'data/UrbanSound8K/train.txt'
test_data = 'data/UrbanSound8K/test.txt'
parser = argparse.ArgumentParser(description=__doc__)
parser.add_argument('--batch_size', type=int, default=32, help='Batch size of training')
parser.add_argument('--num_workers', type=int, default=4, help='Number of threads reading data')
parser.add_argument('--num_epoch', type=int, default=100, help='Number of rounds of training')
parser.add_argument('--num_classes', type=int, default=10, help='Number of categories classified')
parser.add_argument('--learning_rate', type=float, default=1e-3, help='Initial learning rate')
parser.add_argument('--input_shape', type=str, default='(None, 1, 128, 128)', help='Shape of data entry')
parser.add_argument('--gpu_id', type=int, default=0, help='GPU ID')
parser.add_argument('--net_type', type=str, default="mbv2", help='backbone')
parser.add_argument('--data_dir', type=str, default=data_dir, help='Data path')
parser.add_argument('--train_data', type=str, default=train_data, help='Data list path of training data')
parser.add_argument('--test_data', type=str, default=test_data, help='Data list path for test data')
parser.add_argument('--work_dir', type=str, default='work_space/', help='Path to model save')
return parserAfter configuring the data path, other parameters are set by default, and you can start training:
python train.py
After training, use mobilenet_v2, the accuracy of the final training set is about 99% and the test set is about 81%, which seems a little over fitting.
If you want to further improve the recognition accuracy, you can use a heavier backbone, such as resnet34, and adopt more data enhancement methods to improve the universality of the model.
Complete training code train.py:
--coding: utf-8 --
"""
@Author : panjq @E-mail : pan_jinquan@163.com @Date : 2021-07-28 09:09:32
"""
import argparse
import os
import numpy as np
import torch
import tensorboardX as tensorboard
from datetime import datetime
from tqdm import tqdm
from torch.utils.data import DataLoader
from torch.optim.lr_scheduler import StepLR, MultiStepLR
from audio.dataloader.audio_dataset import AudioDataset
from audio.utils.utility import print_arguments
from audio.utils import file_utils
from audio.models import mobilenet_v2, resnet
class Train(object):
"""Training Pipeline"""
def __init__(self, cfg):
self.device = "cuda:{}".format(cfg.gpu_id) if torch.cuda.is_available() else "cpu"
self.num_epoch = cfg.num_epoch
self.net_type = cfg.net_type
self.work_dir = os.path.join(cfg.work_dir, self.net_type)
self.model_dir = os.path.join(self.work_dir, "model")
self.log_dir = os.path.join(self.work_dir, "log")
file_utils.create_dir(self.model_dir)
file_utils.create_dir(self.log_dir)
self.tensorboard = tensorboard.SummaryWriter(self.log_dir)
self.train_loader, self.test_loader = self.build_dataset(cfg)
# Get model
self.model = self.build_model(cfg)
# Get optimization method
self.optimizer = torch.optim.Adam(params=self.model.parameters(),
lr=cfg.learning_rate,
weight_decay=5e-4)
# Get learning rate decay function
self.scheduler = MultiStepLR(self.optimizer, milestones=[50, 80], gamma=0.1)
# Get loss function
self.losses = torch.nn.CrossEntropyLoss()
def build_dataset(self, cfg):
"""Build training data and test data"""
input_shape = eval(cfg.input_shape)
# get data
train_dataset = AudioDataset(cfg.train_data, data_dir=cfg.data_dir, mode='train', spec_len=input_shape[3])
train_loader = DataLoader(dataset=train_dataset, batch_size=cfg.batch_size, shuffle=True,
num_workers=cfg.num_workers)
test_dataset = AudioDataset(cfg.test_data, data_dir=cfg.data_dir, mode='test', spec_len=input_shape[3])
test_loader = DataLoader(dataset=test_dataset, batch_size=cfg.batch_size, shuffle=False,
num_workers=cfg.num_workers)
print("train nums:{}".format(len(train_dataset)))
print("test nums:{}".format(len(test_dataset)))
return train_loader, test_loader
def build_model(self, cfg):
"""Build model"""
if cfg.net_type == "mbv2":
model = mobilenet_v2.mobilenet_v2(num_classes=cfg.num_classes)
elif cfg.net_type == "resnet34":
model = resnet.resnet34(num_classes=args.num_classes)
elif cfg.net_type == "resnet18":
model = resnet.resnet18(num_classes=args.num_classes)
else:
raise Exception("Error:{}".format(cfg.net_type))
model.to(self.device)
return model
def epoch_test(self, epoch):
"""Model test"""
loss_sum = []
accuracies = []
self.model.eval()
with torch.no_grad():
for step, (inputs, labels) in enumerate(tqdm(self.test_loader)):
inputs = inputs.to(self.device)
labels = labels.to(self.device).long()
output = self.model(inputs)
# Calculate loss value
loss = self.losses(output, labels)
# Calculation accuracy
output = torch.nn.functional.softmax(output, dim=1)
output = output.data.cpu().numpy()
output = np.argmax(output, axis=1)
labels = labels.data.cpu().numpy()
acc = np.mean((output == labels).astype(int))
accuracies.append(acc)
loss_sum.append(loss)
acc = sum(accuracies) / len(accuracies)
loss = sum(loss_sum) / len(loss_sum)
print("Test epoch:{:3.3f},Acc:{:3.3f},loss:{:3.3f}".format(epoch, acc, loss))
print('=' * 70)
return acc, loss
def epoch_train(self, epoch):
"""model training"""
loss_sum = []
accuracies = []
self.model.train()
for step, (inputs, labels) in enumerate(tqdm(self.train_loader)):
inputs = inputs.to(self.device)
labels = labels.to(self.device).long()
output = self.model(inputs)
# Calculate loss value
loss = self.losses(output, labels)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# Calculation accuracy
output = torch.nn.functional.softmax(output, dim=1)
output = output.data.cpu().numpy()
output = np.argmax(output, axis=1)
labels = labels.data.cpu().numpy()
acc = np.mean((output == labels).astype(int))
accuracies.append(acc)
loss_sum.append(loss)
if step % 50 == 0:
lr = self.optimizer.state_dict()['param_groups'][0]['lr']
print('[%s] Train epoch %d, batch: %d/%d, loss: %f, accuracy: %f,lr:%f' % (
datetime.now(), epoch, step, len(self.train_loader), sum(loss_sum) / len(loss_sum),
sum(accuracies) / len(accuracies), lr))
acc = sum(accuracies) / len(accuracies)
loss = sum(loss_sum) / len(loss_sum)
print("Train epoch:{:3.3f},Acc:{:3.3f},loss:{:3.3f}".format(epoch, acc, loss))
print('=' * 70)
return acc, loss
def run(self):
# Start training
for epoch in range(self.num_epoch):
train_acc, train_loss = self.epoch_train(epoch)
test_acc, test_loss = self.epoch_test(epoch)
self.tensorboard.add_scalar("train_acc", train_acc, epoch)
self.tensorboard.add_scalar("train_loss", train_loss, epoch)
self.tensorboard.add_scalar("test_acc", test_acc, epoch)
self.tensorboard.add_scalar("test_loss", test_loss, epoch)
self.scheduler.step()
self.save_model(epoch, test_acc)
def save_model(self, epoch, acc):
"""Keep model"""
model_path = os.path.join(self.model_dir, 'model_{:0=3d}_{:.3f}.pth'.format(epoch, acc))
if not os.path.exists(os.path.dirname(model_path)):
os.makedirs(os.path.dirname(model_path))
torch.jit.save(torch.jit.script(self.model), model_path)
def get_parser():
data_dir = "/media/pan/Newly added volume/dataset/UrbanSound8K"
# data_dir = "E:/dataset/UrbanSound8K"
train_data = 'data/UrbanSound8K/train.txt'
test_data = 'data/UrbanSound8K/test.txt'
parser = argparse.ArgumentParser(description=__doc__)
parser.add_argument('--batch_size', type=int, default=32, help='Batch size of training')
parser.add_argument('--num_workers', type=int, default=4, help='Number of threads reading data')
parser.add_argument('--num_epoch', type=int, default=100, help='Number of rounds of training')
parser.add_argument('--num_classes', type=int, default=10, help='Number of categories classified')
parser.add_argument('--learning_rate', type=float, default=1e-3, help='Initial learning rate')
parser.add_argument('--input_shape', type=str, default='(None, 1, 128, 128)', help='Shape of data entry')
parser.add_argument('--gpu_id', type=int, default=0, help='GPU ID')
parser.add_argument('--net_type', type=str, default="mbv2", help='backbone')
parser.add_argument('--data_dir', type=str, default=data_dir, help='Data path')
parser.add_argument('--train_data', type=str, default=train_data, help='Data list path of training data')
parser.add_argument('--test_data', type=str, default=test_data, help='Data list path for test data')
parser.add_argument('--work_dir', type=str, default='work_space/', help='Path to model save')
return parser
if name == '__main__':
parser = get_parser() args = parser.parse_args() print_arguments(args) t = Train(args) t.run()
5. Forecast demo.py
--coding: utf-8 --
"""
@Author : panjq @E-mail : pan_jinquan@163.com @Date : 2021-07-28 09:09:32
"""
import os
import cv2
import argparse
import librosa
import torch
import numpy as np
from audio.dataloader.audio_dataset import load_audio, normalization
from audio.dataloader.record_audio import record_audio
from audio.utils import file_utils, image_utils
https://www.ctocio.com/?s=%E9...
https://www.ctocio.com/?s=%E5...
https://www.ctocio.com/?s=%E5...
https://www.ctocio.com/?s=%E8...
https://www.ctocio.com/?s=%E5...
https://www.ctocio.com/?s=%E5...
https://www.ctocio.com/?s=%E5...
https://www.ctocio.com/?s=%E5...
https://www.ctocio.com/?s=%E5...
https://www.ctocio.com/?s=%E5...
https://www.ctocio.com/?s=%E5...
https://www.ctocio.com/?s=%E5...
https://www.ctocio.com/?s=%E5...
https://www.ctocio.com/?s=%E5...
class Predictor(object):
def __init__(self, cfg):
# self.device = "cuda:{}".format(cfg.gpu_id) if torch.cuda.is_available() else "cpu"
self.device = "cpu"
self.input_shape = eval(cfg.input_shape)
self.spec_len = self.input_shape[3]
self.model = self.build_model(cfg.model_file)
def build_model(self, model_file):
# Loading model
model = torch.jit.load(model_file, map_location="cpu")
model.to(self.device)
model.eval()
return model
def inference(self, input_tensors):
with torch.no_grad():
input_tensors = input_tensors.to(self.device)
output = self.model(input_tensors)
return output
def pre_process(self, spec_image):
"""Audio data preprocessing"""
if spec_image.shape[1] > self.spec_len:
input = spec_image[:, 0:self.spec_len]
else:
input = np.zeros(shape=(self.spec_len, self.spec_len), dtype=np.float32)
input[:, 0:spec_image.shape[1]] = spec_image
input = normalization(input)
input = input[np.newaxis, np.newaxis, :]
input_tensors = np.concatenate([input])
input_tensors = torch.tensor(input_tensors, dtype=torch.float32)
return input_tensors
def post_process(self, output):
"""Post processing of output results"""
scores = torch.nn.functional.softmax(output, dim=1)
scores = scores.data.cpu().numpy()
# Display the picture and output the label with the largest result
label = np.argmax(scores, axis=1)
score = scores[:, label]
return label, score
def detect(self, audio_file):
"""
:param audio_file: Audio file
:return: label:Predictive audio label
score: Confidence of predicted audio
"""
spec_image = load_audio(audio_file)
input_tensors = self.pre_process(spec_image)
# Execute forecast
output = self.inference(input_tensors)
label, score = self.post_process(output)
return label, score
def detect_file_dir(self, file_dir):
"""
:param file_dir: Audio file directory
:return:
"""
file_list = file_utils.get_files_lists(file_dir, postfix=["*.wav"])
for file in file_list:
print(file)
label, score = self.detect(file)
print(label, score)
def detect_record_audio(self, audio_dir):
"""
:param audio_dir: Record and recognize audio
:return:
"""
time = file_utils.get_time()
file = os.path.join(audio_dir, time + ".wav")
record_audio(file)
label, score = self.detect(file)
print(file)
print(label, score)
def get_parser():
model_file = 'data/pretrained/model_060_0.827.pth'
file_dir = 'data/audio'
parser = argparse.ArgumentParser(description=__doc__)
parser.add_argument('--num_classes', type=int, default=10, help='Number of categories classified')
parser.add_argument('--input_shape', type=str, default='(None, 1, 128, 128)', help='Shape of data entry')
parser.add_argument('--net_type', type=str, default="mbv2", help='backbone')
parser.add_argument('--gpu_id', type=int, default=0, help='GPU ID')
parser.add_argument('--model_file', type=str, default=model_file, help='Model file')
parser.add_argument('--file_dir', type=str, default=file_dir, help='Directory of audio files')
return parser
if name == '__main__':
parser = get_parser() args = parser.parse_args() p = Predictor(args) p.detect_file_dir(file_dir=args.file_dir) # audio_dir = 'data/record_audio'
 chrome
chrome