1, Definition of HIVE
Hive is a data warehouse tool based on Hadoop, which can map structured data files into a data table, and can read, write and manage data files in a way similar to SQL. This Hive SQL is abbreviated as HQL. Hive's execution engines can be MR, Spark and Tez.
essence
The essence of Hive is to convert HQL into MapReduce task, complete the analysis and query of the whole data, and reduce the complexity of writing MapReduce.
2, Advantages and disadvantages of Hive
advantage
1. Low learning cost: it provides a SQL like query language HQL, so that developers familiar with SQL language do not need to care about details and can get started quickly
2. Massive data analysis: the bottom layer is based on massive computing to MapReduce
3. Scalability: the computing / expansion capability is designed for large data sets (MR as the computing engine and HDFS as the storage system). Hive can freely expand the scale of the cluster without restarting the service in general.
4. Extensibility: Hive supports user-defined functions, and users can implement their own functions according to their own needs.
5. Good fault tolerance: HQL can still be executed if a data node has a problem.
6. Statistical management: it provides unified metadata management
shortcoming
1.Hive's HQL expression ability is limited
2. The iterative algorithm cannot be expressed
3.Hive's efficiency is relatively low
4. The MapReduce job automatically generated by hive is usually not intelligent enough
5.Hive tuning is difficult and the granularity is coarse
3, Hive's architecture
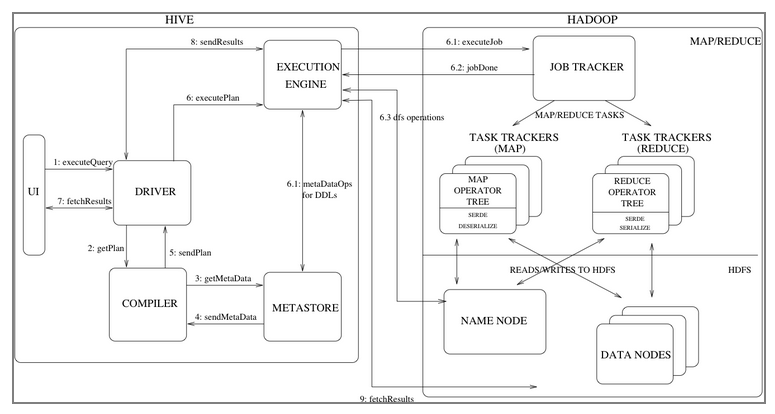 Hive has some important components:
Hive has some important components:
UI: mainly various clients of Hive. This is the window for users to use Hive, including the previously used CLI S such as HiveCli and Beeline, as well as some Web GUI interfaces. Users submit their own operation requests through the UI.
Driver: it receives user queries and implements session processing. It implements API s such as execution and pulling data based on JDBC/ODBC.
Compiler: parse the query statements, do semantic analysis, and finally generate the execution plan with the help of the metadata of the table and partition queried in the Metastore. This is similar to the traditional RDBMS. Of course, Hive also has an Optimizer, which is not drawn in the figure.
Metastore: stores metadata information of tables and partitions, including fields, field types, serialization and deserialization information required for reading and writing data.
Execution Engine: the Execution Engine is used to execute the execution plan generated by the Compiler. It is the bridge between Hive and Hadoop. At present, Hive supports computing engines including MR (gradually abandoned), Tez and Spark.
Let's take a look at the complete process of a query (the following step n corresponds to the array sequence number in the figure):
- The user submits his query request to the Driver (step 1) through the UI;
- The Driver creates a session to process the user's request, and sends the request to the Compiler to generate an execution plan (step 2);
- The Compiler obtains some necessary metadata information (step 3 and 4) from the Metastore, performs type checking and some optimization operations, and then finally generates an execution plan and sends it to the Driver (step 5), and then the Driver sends the execution plan to the Execution Engine (hereinafter referred to as EE).
- After EE gets the execution plan, it will send it to the appropriate components (step 6.1, 6.2, 6.3). Hive's data is stored on HDFS, so it is necessary to deal with HDFS when executing. For example, first go to the NameNode to query the location of data, and then go to the DataNode to obtain data. If it is a DDL operation (such as CREATE, DROP, ALTER, etc.), you should also communicate with hive's MetaStore. The figure shows the use of Mr. MR may have multiple stages, and some temporary files will be generated in the middle. These files are stored on HDFS. If it is a DML operation, the temporary file will be renamed directly (HDFS renaming is an atomic operation) to the final table name. If it is a query statement, the Driver will call the fetch statement to directly read the temporary file from HDFS through the Execution Engine.
4, Table type details
- Table classification
In Hive, there are two types of tables:
Internal table: also called management table. The table directory will be created in the directory corresponding to the corresponding library under / user/hive/warehouse / of hdfs.
External table: the external table will create a directory according to the path specified by LOCATION when creating the table. If LOCATION is not specified, the LOCATION is the same as that of the internal table. Generally, the data provided by a third party or public is used.
- The difference between the two
Difference between internal table and external table at creation time
Internal table
CRAATE TABLE T_INNER(ID INT);
External table
CREATE EXTERNAL TABLE T_OUTER(ID INT) LOCATION 'HDFS:///AA/BB/CC';
Two things to do when creating Hive table:
- Create a table directory under HDFS
- Create the description data (metadata) of the corresponding table in the meta database Mysql
drop has different characteristics:
- Metadata will be cleared when drop ping
- During drop, the table directory of the internal table will be deleted, but the table directory of the external table will not be deleted.
Usage scenario
Internal table: it is usually used to test or a small amount of data, and you can modify and delete data at any time.
External tables are used when the data does not want to be deleted after use (recommended). Therefore, the lowest table of the whole data warehouse uses external tables.
Basic operation of Hive
1. Annotation syntax:
-- Single-Line Comments // Single-Line Comments /* * multiline comment */
2. Case rules:
Hive's database name and table name are not case sensitive
Suggested keyword capitalization
3. Naming rules:
- Names cannot start with numbers
- Keywords cannot be used
- Try not to use special symbols
- If there are many tables, table names and field names can be prefixed by defining rules
4. Quickly create libraries and tables:
-- hive There is a default database default,If it is not clear which library to use, the default database is used. hive> create database user; hive> create database if not exists user; hive> create database if not exists db comment 'this is a database of practice'; -- The essence of creating libraries: in hive of warehouse Create a directory (Library name) under directory.db (named directory) -- Switch libraries: hive> use uer; --Create table hive> create table t_user(id int,name string); -- Use library+Create a table as a table: hive> create table db.t_user(id int,name string); --Add a separator for loading data when creating a table create table t_user ( id int, name string ) row format delimited fields terminated by ',';
5. View table
# View tables in the current database show tables; # View tables in another database show tables in zoo; # View table information desc tableName; # View details desc formatted tableName; #View and create table information show create table tableName;
6. Modification table
Modify table name
alter table t7 rename to a1;
Modify column name
alter table a1 change column name string;
Modify the position of the column
alter table log1 change column ip string after status;
Modify field type
alter table a1 change column name string;
Add field
alter table a1 add columns (sex int);
replace field
alter table a1 replace columns ( id int, name string, size int, pic string );
Internal and external table conversion
Internal table to external table, true Be sure to capitalize;
alter table a1 set tblproperties('EXTERNAL'='TRUE');
false It doesn't matter case
alter table a1 set tblproperties('EXTERNAL'='false');
7. Load data into Hive
- Read files in load mode
-- from hdfs Load data in hive> load data inpath 'hivedata/user.csv' into table user; -- Load data locally hive> load data local inpath 'hivedata/user.csv' into table user;
The nature of loading data:
- If the data is local, the essence of loading data is to copy the data to the table directory on hdfs.
- If the data is on hdfs, the essence of loading data is to move the data to the table directory of hdfs.
- If the same data is loaded repeatedly, it will not be overwritten
be careful:
Hive uses a strict read-time mode: it does not check the integrity of the data when loading the data. If it is found that the data is wrong during reading, it will use NULL instead.
Mysql uses the write time mode: it checks when writing data.
- insert into data
First create a table with the same structure as the old table
create table usernew( id int, name string ) comment 'this is a table' row format delimited fields terminated by ',' lines terminated by '\n' stored as textfile;
- Clone table
Without data, only the structure of the table is cloned
-- from usernew Clone new table structure to userold create table if not exists userold like usernew;
Clone table with data
create table t7 as select * from t6;
8.Hive Shell skills
View all hive parameters
hive> set
Execute Hive command only once
[root@hadoop01 hive]# hive -e "select * from cat"
Execute a single sql file
[root@hadoop01 hive]# hive -f /path/cat.sql
Execute Linux commands
Prefix! Last with semicolon;ending,Can execute linux Command of hive> ! pwd ;
Execute HDFS command
hive> dfs -ls /tmp
5, Partition table
1. Reasons for zoning
As the system runs longer and longer, the amount of data in the table is larger and larger, and hive query usually uses full table scanning, which will lead to a large number of unnecessary data scanning, which greatly reduces the efficiency of query.
In order to improve the efficiency of query, partition technology is introduced. Using partition technology can avoid hive doing full table scanning, so as to submit query efficiency. The user's entire table can be divided into multiple subdirectories on storage (subdirectories are named after the value of partition variables).
It allows users to narrow the scope of data scanning when making data statistics, because you can specify which partition to count in select, such as data of a day, data of a region, etc
Zoning essence Create a directory under the table directory or partition directory, The directory name of the partition is the specified field=value
2. Create partition table
Specify the partition name through the following partitioned by. In addition, the partition name (dt) is a pseudo field, which is a field outside part1
create table if not exists part1( id int, name string ) -- According to the demand, three-level partition is required only when the data is very large -- Primary partition partitioned by (dt string) -- Secondary partition partitioned by (year string,month string) -- Three level zoning partitioned by (year string,month string,day string) row format delimited fields terminated by ',';
3. Basic operation of partition table
- Partition table loading data
-- Primary partition load data local inpath "/opt/data/user.txt" into table part1 partition(dt="2019-08-08"); -- Secondary partition load data local inpath '/opt/soft/data/user.txt' into table part2 partition(year='2020',month='02'); -- Three level zoning load data local inpath '/opt/soft/data/user.txt' into table part3 partition(year='2020',month='02',day='20');
- New partition
alter table part5 add partition(dt='2020-03-21');
- Add partitions and set data
alter table part5 add partition(dt='2020-11-11') location '/user/hive/warehouse/part1/dt=2019-08-08';
- Modify the path of the partition's hdfs
alter table part5 partition(dt='2020-03-21') set location 'hdfs://hadoop01:8020/user/hive/warehouse//part1/dt=2019-09-11'
- delete a partition
alter table part5 drop partition(dt='2020-03-24'),partition(dt='2020-03- 26');
4. Partition table type
- Static partition
Load data to the value of the specified partition, and specify the partition name when adding a partition or loading a partition
- Dynamic partition
The data is unknown. Determine the partition to be created according to the value of the partition.
Property configuration of dynamic partition Can I partition dynamically hive.exec.dynamic.partition=true Set to non strict mode hive.exec.dynamic.partition.mode=nonstrict Maximum number of partitions hive.exec.max.dynamic.partitions=1000 Maximum number of partition nodes hive.exec.max.dynamic.partitions.pernode=100
Create dynamic partition table
create table dy_part1( id int, name string ) partitioned by (dt string) row format delimited fields terminated by ',';
Load data
After creating a temporary table and importing data: insert into dy_part1 partition(dt) select id,name,dt from temp_part;
- Mixed partition
Both static and dynamic.
Create mixed partition table
create table dy_part2( id int, name string ) partitioned by (year string,month string,day string) row format delimited fields terminated by ',';
Load data
After creating a temporary table and importing data: insert into dy_part2 partition (year='2020',month,day) select id,name,month,day from temp_part2;
- be careful
1.hive partition uses off table fields. The partition field is a pseudo column, but the partition field can be queried
Filtering.
2. Chinese is not recommended for partition fields
3. It is generally not recommended to use dynamic partition, because dynamic partition will use mapreduce to query data. If there is too much partition data, it will lead to the performance bottleneck of namenode and resourcemanager. Therefore, it is recommended to predict the number of partitions as much as possible before using dynamic partitions.
4. The metadata and hdfs data content can be modified for the modification of partition attributes.
5, Barrel table
1. Significance of barrel separation
When the amount of data in a single partition or table is too large, and the partition cannot divide the data into finer granularity, it is necessary to use bucket splitting technology to divide the data into finer granularity.
2. Keywords and their principles
bucket
Principle of bucket Division: like the HashPartitioner principle in MR, it is the hash value of key and the number of modular reduce
In MR: divide the hash value of key by reduceTask to get the remainder
Hive: divide the module by the number of buckets according to the hash value of the bucket field
3. Operation of drum sorting table
- establish
create table t_stu( Sno int, Sname string, Sex string, Sage int, Sdept string ) row format delimited fields terminated by ',' stored as textfile;
- Load data
Loading data in load mode cannot reflect bucket splitting
load data local inpath '/root/hivedata/students.txt' into table t_stu;
Temporary table mode
Load data into temporary table load data local inpath '/hivedata/buc1.txt' into table temp_buc1 Import data into bucket table by bucket query insert overwrite table buc13 select id,name,age from temp_buc1 cluster by (id);
- Bucket query
Syntax:
tablesample(bucket x out of y on sno)
Note: tablesample must be immediately after the table name. x: represents the number of barrels to query from. Y: the total number of barrels to query. Y can be a multiple or factor of the total number of barrels, and x cannot be greater than y
There are 4 barrels by default Query the first bucket select * from buc3 tablesample(bucket 1 out of 4 on sno); Query the first bucket and the third bucket select * from buc3 tablesample(bucket 1 out of 2 on sno); Query the first half of the first bucket select * from buc3 tablesample(bucket 1 out of 8 on sno);
Y must be a multiple or factor of the total number of buckets in the table. hive determines the sampling proportion according to the size of Y. For example, the table is divided into four parts in total. When y=2, the data of (4 / 2 =) two buckets is extracted, and when y=8, the data of (4 / 8 =) one-half buckets is extracted.
X indicates which bucket to start from. If multiple partitions need to be taken, the subsequent partition number is the current partition number plus y. For example, the total number of buckets in a table is 4, and tablesample(bucket 1 out of 2) means that the data of two buckets are extracted in total (4 / 2 =), and the data of the 1st (x) and 3rd (x + y) buckets are extracted.
Note: the value of x must be less than or equal to the value of y, otherwise
FAILED: SemanticException [Error 10061]: Numerator should not be bigger than denominator in sample clause for table stu_buck
query sno Odd data select * from buc3 tablesample(bucket 2 out of 2 on sno); query sno Even and age People over 30 select * from buc3 tablesample(bucket 1 out of 2 on sno) where age>30; Find out three lines select * from buc3 limit 3; Find out three lines select * from buc3 tablesample(3 rows); Find out 13%Content of,(If the percentage is not realistic enough,At least one line will be displayed,If the percentage is 0,Display first bucket) select * from buc3 tablesample(13 percent); Find out 68 B Data contained,If 0 B,The first bucket is displayed by default, and three rows of data are required to be randomly selected: select * from buc3 tablesample(68B); Randomly display 3 pieces of data select * from t_stu order by rand() limit 3;