Big data warehouse training - task 3
Data analysis and prediction of Taobao double 11
Case introduction
The case of Taobao double 11 data analysis and prediction course involves various typical operations involved in the whole process of data processing such as data preprocessing, storage, query and visual analysis, including the installation and use methods of Linux, MySQL, Hadoop, Hive and other systems and software. Through this case, it will help students make comprehensive use of big data course knowledge and various tool software to realize data analysis operation.
Case purpose
- Familiar with the installation and use of Linux system, MySQL, Hadoop, Hive and other systems and software;
- Understand the basic process of big data processing;
- Familiar with data preprocessing methods;
- Familiar with using hive for data analysis and processing.
Schedule
3 days
Preparatory knowledge
Case users need to have studied big data related courses, understand the basic concepts and principles of big data related technologies, understand the key technologies and basic principles of Windows operating system, Linux operating system, big data processing architecture Hadoop, data warehouse concepts and principles, relational database concepts and principles, etc.
hardware requirements
This case can be completed on a single machine or in a cluster environment.
software tool
Systems and software involved in this case:
- Linux system
- MySQL
- Hadoop
- Hive
......
data set
Taobao shopping behavior data set (50 million records, data offset, not real Taobao shopping transaction data, but does not affect learning)
Case task
- Installing Linux operating system
- Install relational database MySQL
- Install Hadoop, a big data processing framework
- Install data warehouse Hive
- Preprocess the original data set in the form of text file
- Import the data set of text file into Hive data warehouse
- Query and analyze the data in Hive data warehouse
Experimental steps
| Step Zero: experimental environment preparation |
| Step 1: upload local data set to Hive data warehouse |
| Step 2: Hive data analysis |
| Step 3: data visualization analysis (optional) |
The list of knowledge reserve, training skills and tasks required for each experimental step is as follows:
Step Zero: experimental environment preparation
| Required knowledge reserve | Key technologies and basic principles of Windows operating system, Linux operating system, big data processing architecture Hadoop, the concept and principle of column family database HBase, the concept and principle of data warehouse, and the concept and principle of relational database |
| Training skills | Operating system installation, virtual machine installation, basic Linux operation, Hadoop installation, Hive installation, etc |
| Task list | 1. Install Linux system; 2. Install Hadoop; 3. Install MySQL; 4. Install Hive |
Step 1: upload local data set to Hive data warehouse
| Required knowledge reserve | Basic commands of Linux system, Hadoop project structure, distributed file system HDFS concept and its basic principle, data warehouse concept and its basic principle, data warehouse Hive concept and its basic principle |
| Training skills | Hadoop installation and basic operation, HDFS basic operation, Linux Installation and basic operation, Hive data warehouse installation and basic operation, basic data preprocessing methods |
| Task list | 1. Install Linux system; 2. Data set downloading and viewing; 3. Data set preprocessing; 4. Import the data set into the distributed file system HDFS; 5. Create database on Hive data warehouse |
Step 2: Hive data analysis
| Required knowledge reserve | Hive concept of data warehouse and its basic principle, SQL statement and database query analysis |
| Training skills | Basic operations of Hive data warehouse, creating databases and tables, and using SQL statements for query analysis |
| Task list | 1. Start Hadoop and Hive; 2. Create databases and tables; 3. Simple query and analysis; 4. Statistical analysis of the number of queries; 5. Keyword condition query and analysis; 6. Analysis according to user behavior; 7. User real-time query and analysis, etc |
Step Zero: experimental environment preparation
Install the corresponding Linux, Hadoop, MySQL, Hive, etc.
Step 1: upload local data set to Hive data warehouse
Task list:
- Data set downloading and viewing
- Data set preprocessing
- Import datasets into distributed file system HDFS
- Create database on Hive data warehouse
Task steps:
The data set compression package used in this case is data_format.zip, the data set compressed package is the transaction data of Taobao for the first six months of double 11 in 2015 (including double 11) (the transaction data is offset, but does not affect the experimental results), which contains three files, namely the user behavior log file user_log.csv, repeat customer training set train CSV, repeat customer test set csv. The dataset is already in the case task package file.
The data format definitions of these three files are listed below:
User behavior log user_log.csv, the fields in the log are defined as follows:
-
user_id | buyer id
-
item_id | commodity id
-
cat_id | commodity category id
-
merchant_id | seller id
-
brand_id | brand id
-
Month | trading time: month
-
Day | trading time: day
-
action | behavior. The value range is {0,1,2,3}. 0 means clicking, 1 means adding to the shopping cart, 2 means buying, and 3 means paying attention to goods
-
age_range | buyer's age segmentation: 1 indicates age < 18,2 indicates age at [18,24], 3 indicates age at [25,29], 4 indicates age at [30,34], 5 indicates age at [35,39], 6 indicates age at [40,49], 7 and 8 indicate age > = 50,0 and NULL indicates unknown
-
Gender | gender: 0 for female, 1 for male, 2 and NULL for unknown
-
province | receiving address province
Repeat customer training set train CSV and repeat customer test set test CSV, training set and test set have the same fields. The field definitions are as follows:
-
user_id | buyer id
-
age_range | buyer's age segmentation: 1 indicates age < 18,2 indicates age at [18,24], 3 indicates age at [25,29], 4 indicates age at [30,34], 5 indicates age at [35,39], 6 indicates age at [40,49], 7 and 8 indicate age > = 50,0 and NULL indicates unknown
-
Gender | gender: 0 for female, 1 for male, 2 and NULL for unknown
-
merchant_id | merchant id
-
labe - | whether it is a repeat customer. A value of 0 indicates that it is not a repeat customer, a value of 1 indicates a repeat customer, and a value of - 1 indicates that the user has exceeded the prediction range we need to consider. NULL value only exists in the test set, which represents the value to be predicted.
Next, do the following.
1. First establish a directory for running this case:
1) Create a new directory dbtaobao under the / root directory
mkdir dbtaobao

2) Give hadoop users various operation permissions for the dbtaobao directory.
chmod 777 dbtaobao

3) Create a dataset directory under dbtaobao to save datasets.
cd dbtaobao mkdir dataset

4) Compress the dataset into data_format.zip to the dataset directory
- Check whether there are three files in the dataset Directory: test csv,train.csv,user_log.csv and take out user with the command_ log. Take a look at the first five records of CSV, as shown in the figure below. (tip: head -n target file)
cd dataset head -5 user_log.csv

2. Data set preprocessing
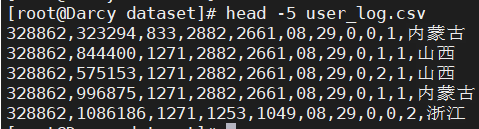
1)user_ log. The first line of CSV is the field name. When we import the data in the file into Hive, we do not need the field name in the first line. Therefore, please delete the record in the first line of the file, that is, the field name, during data preprocessing. (prompt: sed -i 'nd' target file, where n refers to the number of lines)
sed -i '1d' user_log.csv
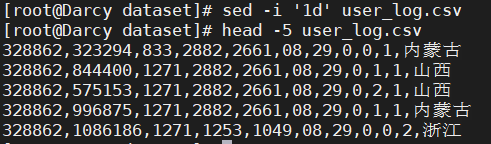
2) Remove user with command_ log. Check whether the first 5 records in CSV are as shown in the figure below. Check whether they are deleted successfully.
head -5 user_log.csv
3. Obtain the first 10000 data of double 11 in the data set
Because the transaction data in the data set is too large, only the first 10000 transaction data in the double 11 are intercepted here as a small data set small_user_log.csv.
1) Under the / root/dbtaobao/dataset directory, create a script file called predeal. XML through vim SH, please add the following code to this script file and save it:
vim predeal.sh
#!/bin/bash
#Next, set the input file to execute predeal The first parameter provided when the SH command is used as the input file name
infile=$1
#Next, set the output file to execute predeal The second parameter supplied with the SH command is the output file name
outfile=$2
#be careful!! The last $infile > $outfile must follow the two characters} '
awk -F "," 'BEGIN{
id=0;
}
{
if($6==11 && $7==11){
id=id+1;
print $1","$2","$3","$4","$5","$6","$7","$8","$9","$10","$11
if(id==10000){
exit
}
}
}' $infile > $outfile

2) Execute predeal SH script file to intercept the first 10000 transaction data in the double 11 as a small data set small_user_log.csv, the command is as follows:
chmod +x ./predeal.sh ./predeal.sh ./user_log.csv ./small_user_log.csv

After that, the following files should be in the dataset Directory:

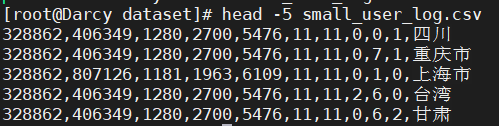
You can view small_ user_ log. The first five pieces of CSV data are as follows:
head -5 small_user_log.csv
4. Upload files to the distributed file system HDFS
1) Start Hadoop.
start-all.sh
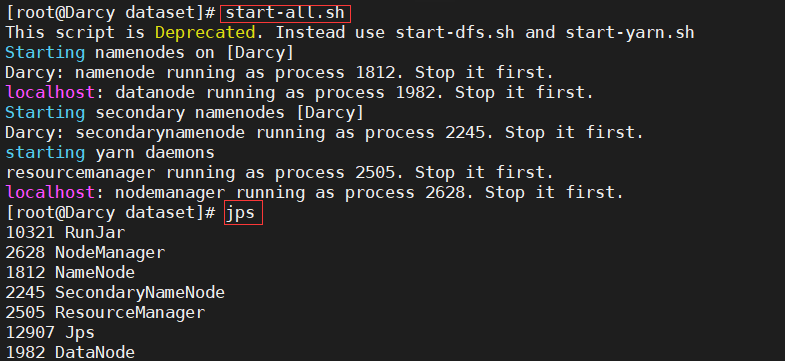
- Create a new directory dbtaobao under the root directory of HDFS, and create a subdirectory dataset / user under this directory_ Log, the command is as follows:
hadoop fs -mkdir -p /dbtaobao/dataset/user_log

3) Small in Linux local file system_ user_ log. CSV is uploaded to the "/ dbtaobao/dataset/user_log" directory of the distributed file system HDFS.
hadoop fs -put "/root/dbtaobao/dataset/small_user_log.csv" /dbtaobao/dataset/user_log

4) Take a look at small in HDFS_ user_ log. Whether the first 10 records of CSV are verified successfully. (prompt: hadoop fs -cat target file | head -n)
hadoop fs -cat /dbtaobao/dataset/user_log/small_user_log.csv | head -10
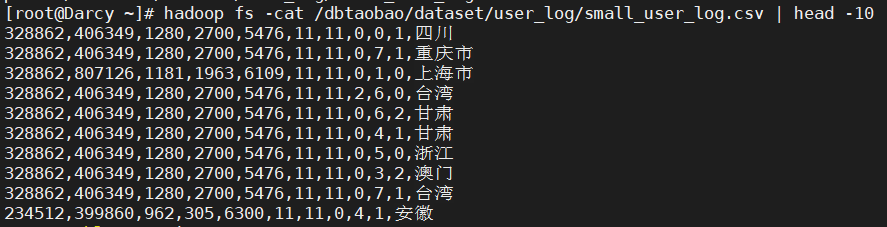
5. small_ user_ log. Importing data into data warehouse in CSV Hive
1) Start MySQL, start hive, enter hive interactive interface, and create a new database dbtaobao.
systemctl start mysqld hive

2) Create an external table user in the database dbtaobao_ Log, which contains the field user_id INT,item_id INT,cat_id INT,merchant_id INT,brand_id INT,month STRING,day STRING,action INT,age_range INT, gender INT, province STRING), each field is divided by ',' and saved as TEXTFILE. At the same time, the path (pointing path) for storing data in the external table is specified as' / dbtaobao/dataset/user_log '(Note: if the storage path is specified, it will not be stored in user/hive/warehouse/dbtaobao.db by default. Please think about the meaning of the specified storage path)
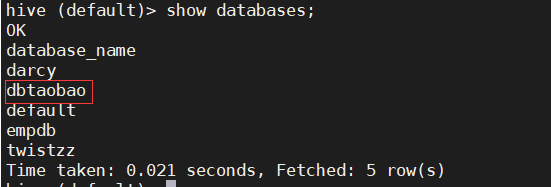
--Create database
create database dbtaobao;
--view the database
show databases;
use dbtaobao;
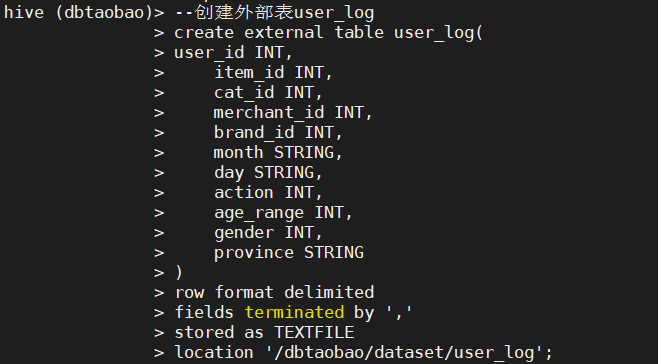
--Create external table user_log
create external table user_log(
user_id INT,
item_id INT,
cat_id INT,
merchant_id INT,
brand_id INT,
month STRING,
day STRING,
action INT,
age_range INT,
gender INT,
province STRING
)
row format delimited
fields terminated by ','
stored as TEXTFILE
location '/dbtaobao/dataset/user_log';

Step 2: Hive data analysis
Task list
-
Start Hadoop and Hive
-
Create databases and tables
-
Simple query analysis
-
Statistical analysis of the number of queries
-
Keyword condition query analysis
-
Association query, joint query analysis
-
Function query analysis
-
Analysis based on user behavior
-
User real-time query and analysis, etc
Next, do the following.
Note that this step needs to be started on the premise of MySQL, Hadoop and Hive.
1. Simple query analysis in hive
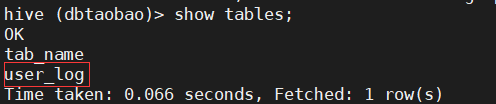
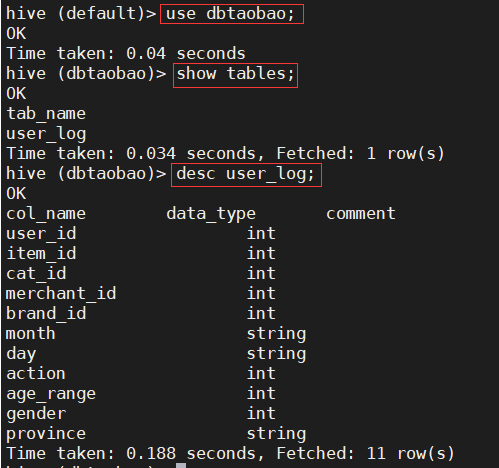
1) Use the dbtaobao database to display all tables in the database and view the user_ Simple structure of log table
use dbtaobao; show tables; desc user_log;
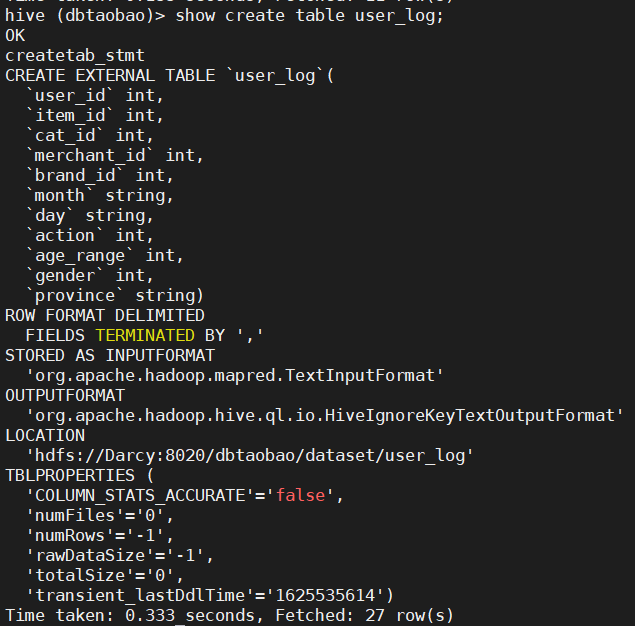
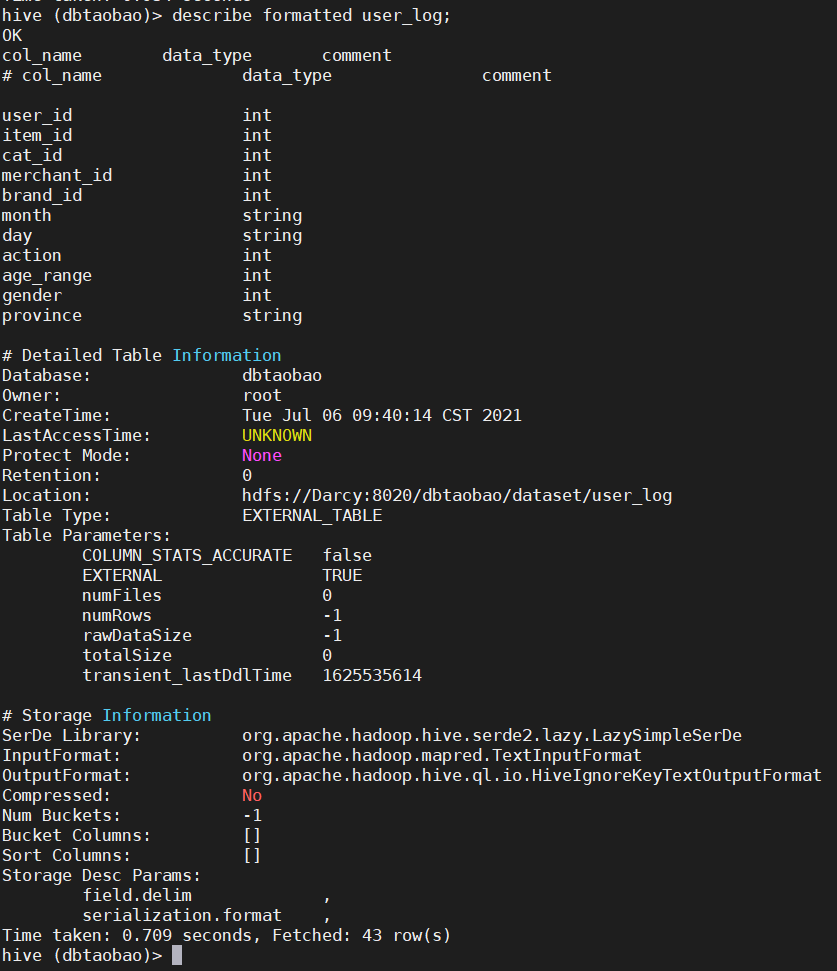
2) View user_ Various attributes of the log table (see the detailed table creation statement of the table).
show create table user_log; --perhaps describe formatted user_log;
3) View user_ The product brands of the top 10 transaction logs in the log table.
select brand_id from user_log limit 10;
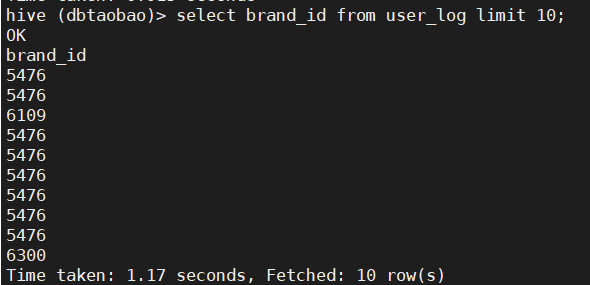
4) Query user_ The time and type of goods purchased in the first 20 transaction logs of the log table.
select month, day, cat_id form user_log limit 20;
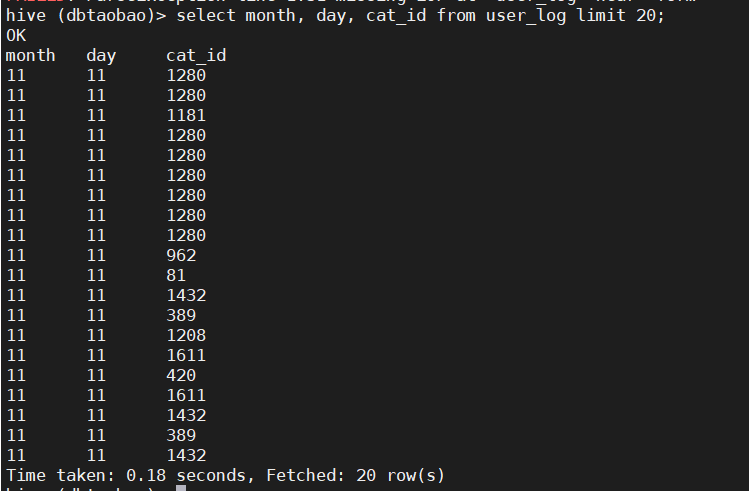
2. Statistical analysis in hive
1) Count user_ How many rows of data are there in the log table. (10000)
select count(*) from user_log;
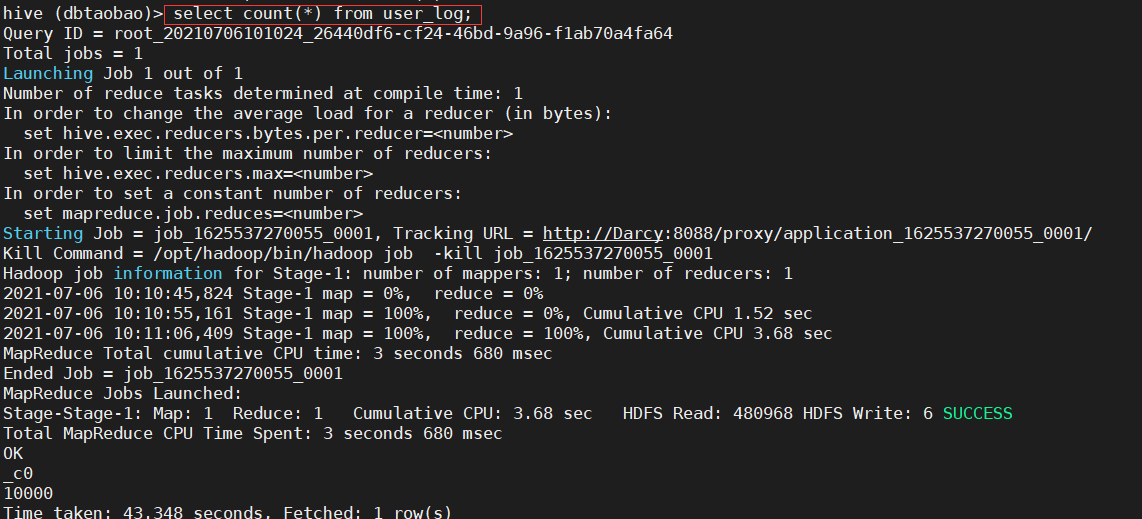
2) Count user_ How many customers are there in the log table (non duplicate user_id s are counted). (358)
select count(distinct user_id) from user_log;
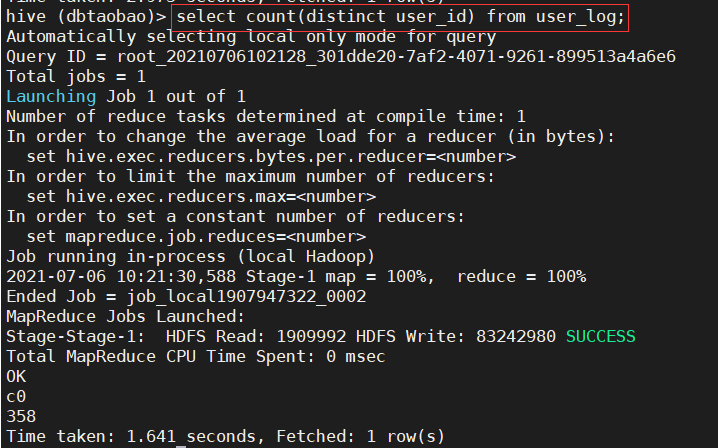
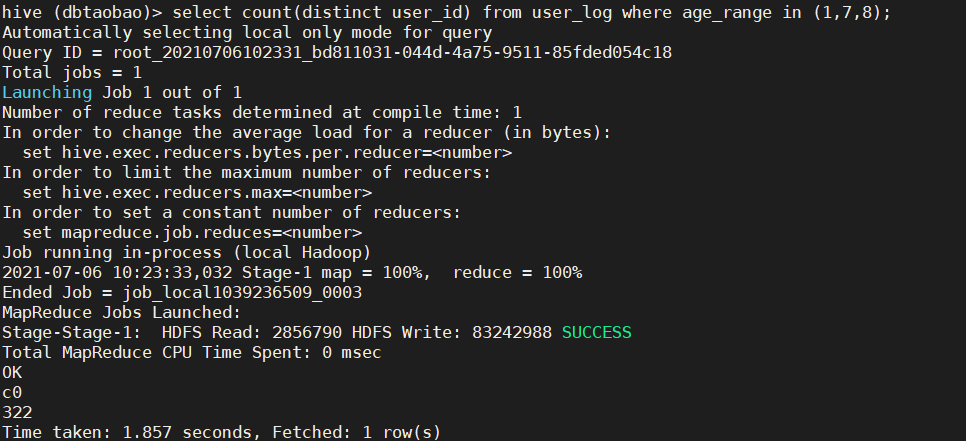
3) Count user_ In the log table, how many buyers are younger than 18 years old and older than or equal to 50 years old. (pay attention to weight removal) (322)
select count(distinct user_id) from user_log where age_range in (1,7,8);
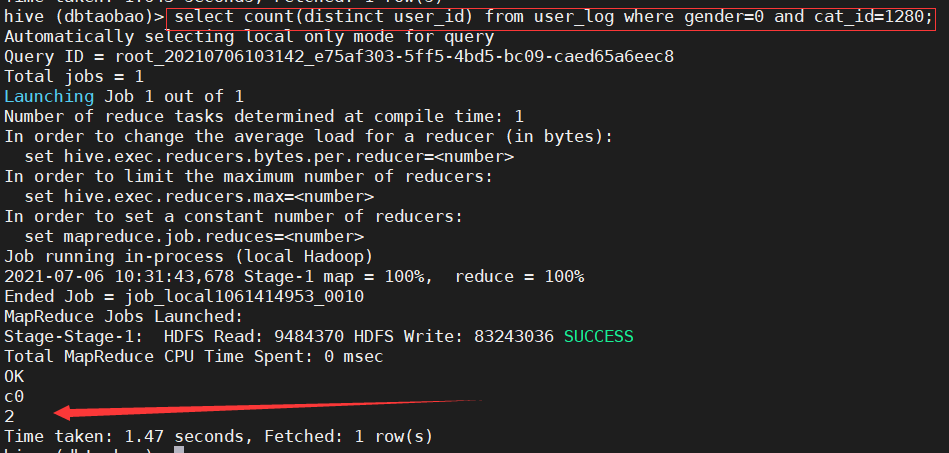
4) Statistics on the number of women who purchased the commodity category No. 1280. (2)
select count(distinct user_id) from user_log where gender=0 and cat_id=1280;
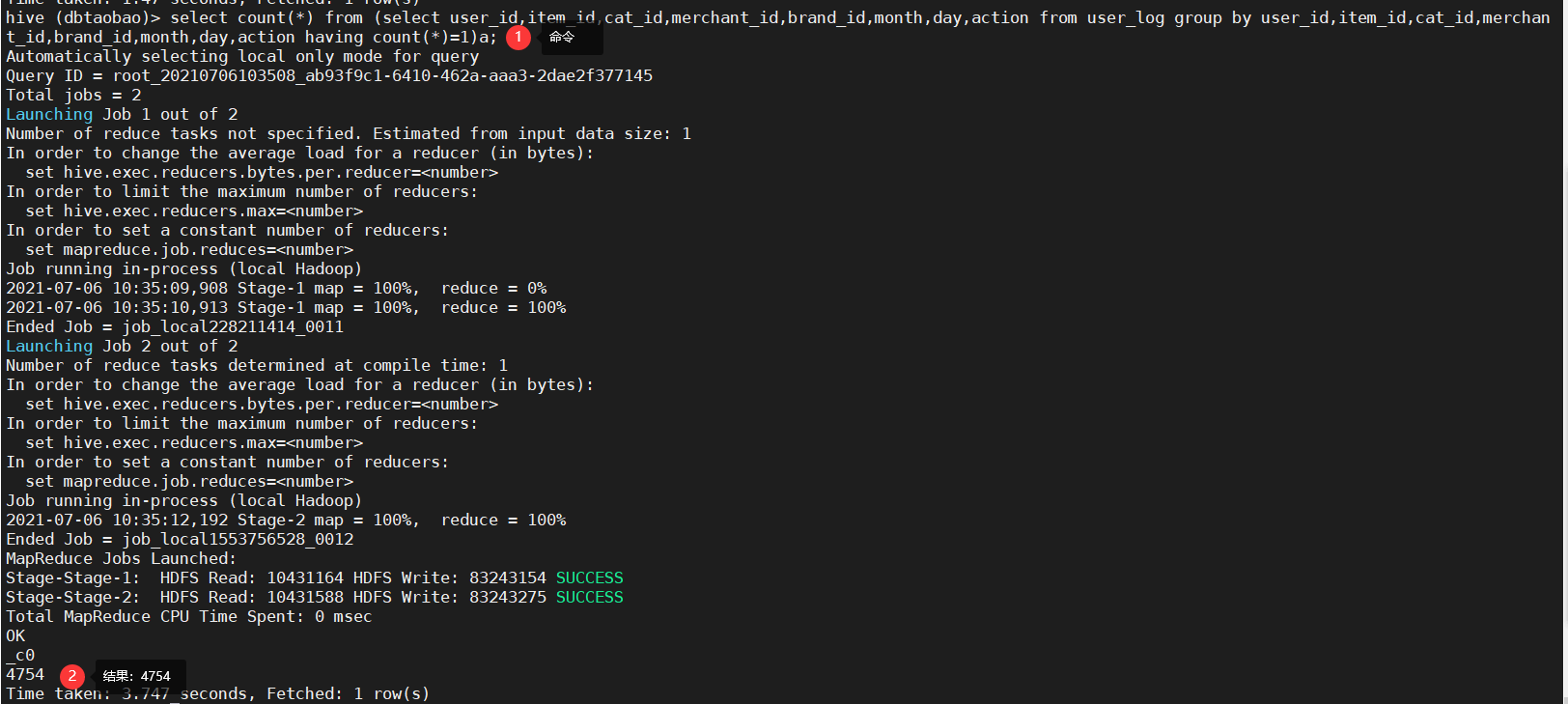
5) Count user_ How many pieces of data are not duplicated in the log table (in order to exclude customer billing) (duplicate data means that the data of all fields are consistent). (Note: nested statements are best aliased) (4754)
select count(*) from (select user_id,item_id,cat_id,merchant_id,brand_id,month,day,action from user_log group by user_id,item_id,cat_id,merchant_id,brand_id,month,day,action having count(*)=1)a;
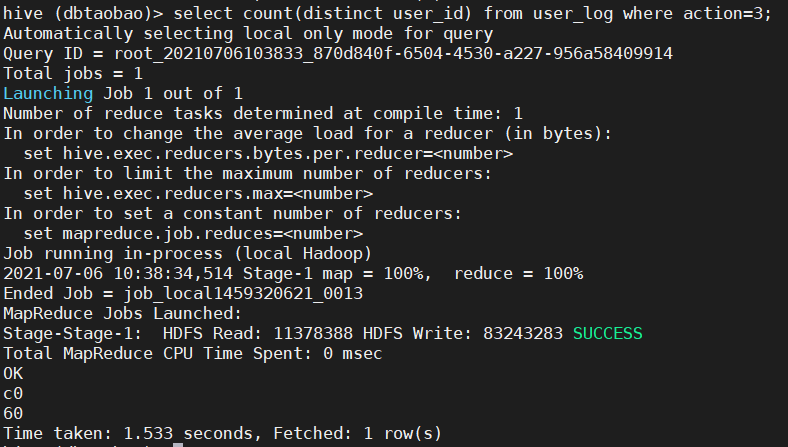
3. Query and analysis of keyword conditions in hive
1) According to user_log table to query how many people paid attention to the goods on the day of double 11 (pay attention to the weight of people). (60)
select count(distinct user_id) from user_log where action=3;
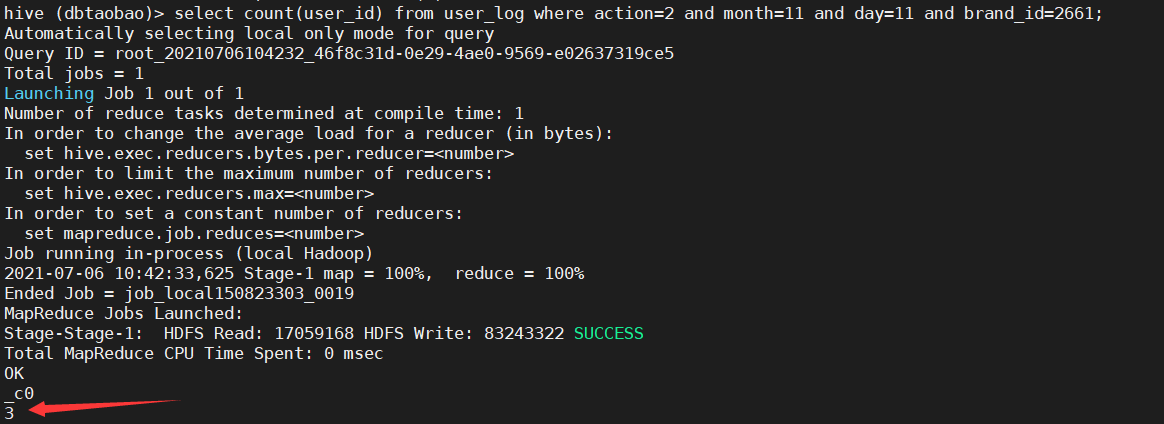
2) Ask for several times to buy 2661 brand goods on the same day. (3)
select count(user_id) from user_log where action=2 and month=11 and day=11 and brand_id=2661;
4. Analysis based on user behavior in hive
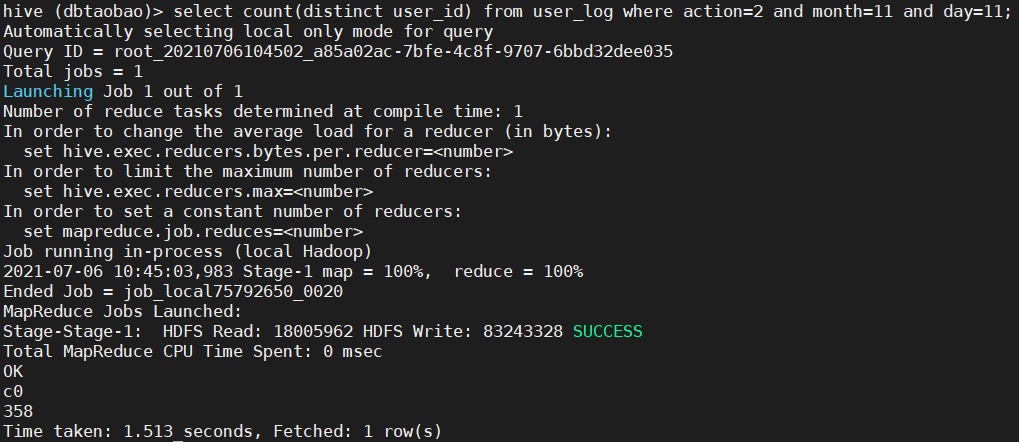
1) Query how many users have purchased goods in double 11. (pay attention to weight removal) (358)
select count(distinct user_id) from user_log where action=2 and month=11 and day=11;
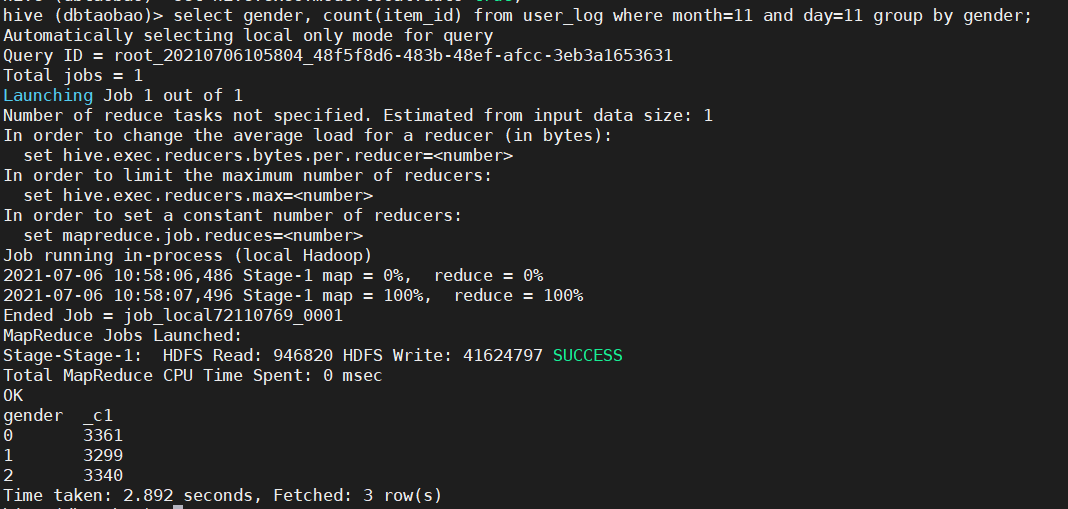
2) Inquire about the number of goods purchased on the day of double 11, classified by men and women and buyers of unknown gender.
select gender, count(item_id) from user_log where month=11 and day=11 group by gender;
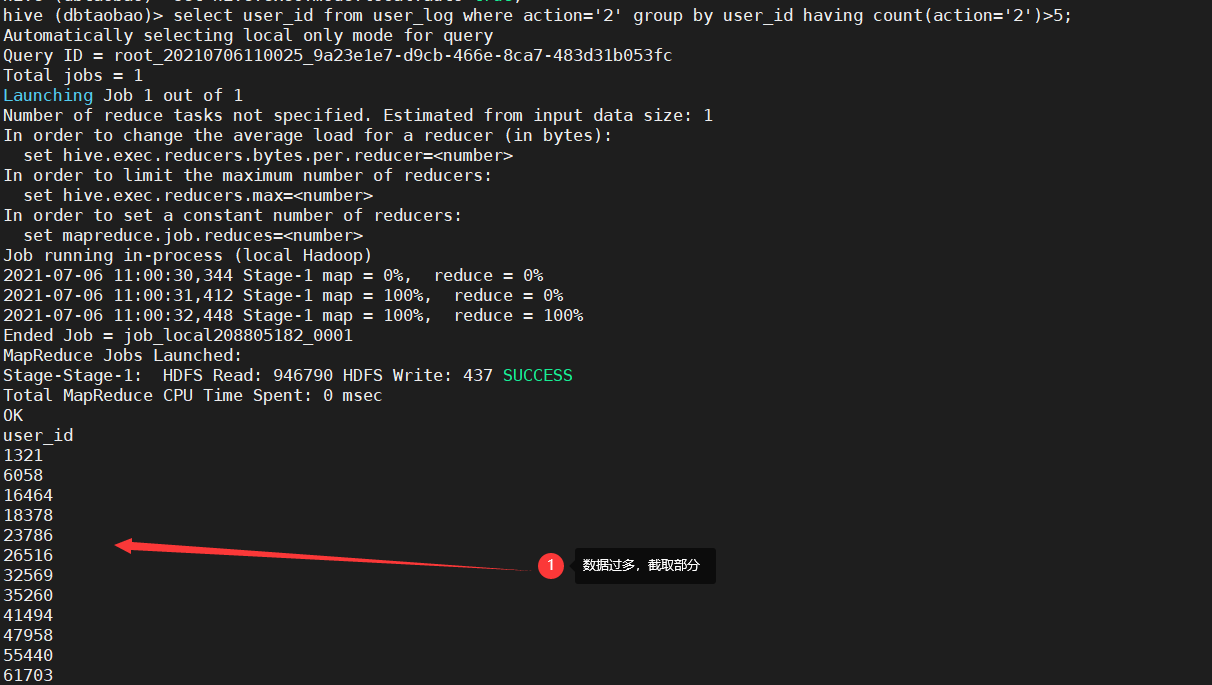
3) Query the user id of purchasing goods on this website for more than 5 times
select user_id from user_log where action='2' group by user_id having count(action='2')>5;
5. Real time query and analysis of users in hive
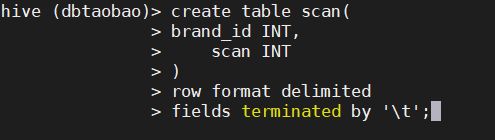
1) Create a new data table scan with field brand_id INT (brand), scan INT (number of times the brand has been purchased), and each field is divided by '\ t'
create table scan(
brand_id INT,
scan INT
)
row format delimited
fields terminated by '\t';
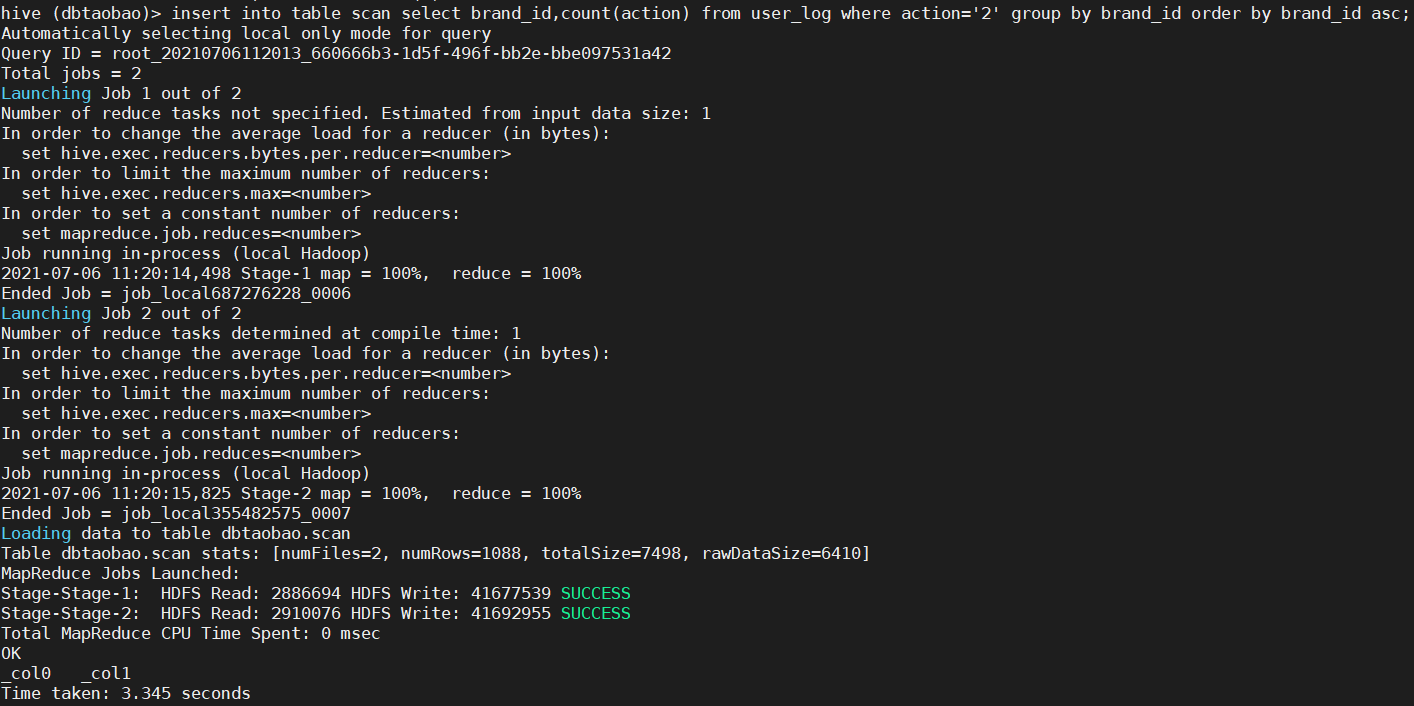
2) User_ The data of the brand counted in the log and the corresponding number of times of purchasing the brand are transferred to the table scan and processed according to the brand_id is sorted in ascending order, as shown in the following figure:
insert into table scan select brand_id,count(action) from user_log where action='2' group by brand_id order by brand_id asc; --View data rows select count(*) from scan;
6. Pretreatment test CSV dataset
Test. Is listed here CSV and train Description of the field in CSV. The field definition is as follows:
-
user_id | buyer id
-
age_range | buyer's age segmentation: 1 indicates age < 18,2 indicates age at [18,24], 3 indicates age at [25,29], 4 indicates age at [30,34], 5 indicates age at [35,39], 6 indicates age at [40,49], 7 and 8 indicate age > = 50,0 and NULL indicates unknown
-
Gender | gender: 0 for female, 1 for male, 2 and NULL for unknown
-
merchant_id | merchant id
-
labe - | whether it is a repeat customer. A value of 0 indicates that it is not a repeat customer, a value of 1 indicates a repeat customer, and a value of - 1 indicates that the user has exceeded the prediction range we need to consider. NULL value only exists in the test set, which represents the value to be predicted.
Please do the following:
1) You need to preprocess test CSV dataset, put this test The label field in the CSV dataset indicates that the - 1 value is eliminated and the data to be analyzed is retained It is assumed that the label field in the data to be analyzed is 1. Create a new predeal with vim editor in / root/dbtaobao/dataset directory_ test. SH script file, please add the following code to this script file.
#!/bin/bash
#Next, set the input file to execute predeal_ test. The first parameter provided when the SH command is used as the input file name
infile=$1
#Next, set the output file to execute predeal_ test. The second parameter supplied with the SH command is the output file name
outfile=$2
#be careful!! The last $infile > $outfile must follow the two characters} '
awk -F "," 'BEGIN{
id=0;
}
{
if($1 && $2 && $3 && $4 && !$5){
id=id+1;
print $1","$2","$3","$4","1
if(id==10000){
exit
}
}
}' $infile > $outfile
Now you can execute predeal_test.sh script file to intercept the predicted data of the test data set to test_after.csv, the command is as follows:
chmod +x ./predeal_test.sh ./predeal_test.sh ./test.csv ./test_after.csv

Then check the script and processed data in the / root/dbtaobao/dataset directory_ after. Whether the CSV is all there.
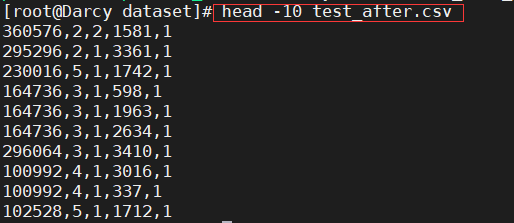
Take the first ten lines.
head -10 test_after.csv
7. Pretreatment train CSV dataset
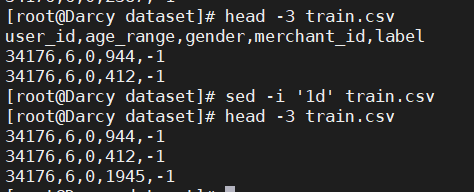
1) Dataset train The first line of CSV is the field name. The field name in the first line is not required. Please select train CSV data preprocessing, delete the first row.
sed -i '1d' train.csv
2) Next, remove the train Data whose field value is empty in the field value part of CSV. A new predeal is created using the vim editor_ train. SH script file, please add the following code to this script file:
#!/bin/bash
#Next, set the input file to execute predeal_ train. The first parameter provided when the SH command is used as the input file name
infile=$1
#Next, set the output file to execute predeal_ train. The second parameter supplied with the SH command is the output file name
outfile=$2
#be careful!! The last $infile > $outfile must follow the two characters} '
awk -F "," 'BEGIN{
id=0;
}
{
if($1 && $2 && $3 && $4 && ($5!=-1)){
id=id+1;
print $1","$2","$3","$4","$5
if(id==10000){
exit
}
}
}' $infile > $outfile

Execute predeal_train.sh script file to intercept the predicted data of the test data set to the train_after.csv, the command is as follows:
chmod +x ./predeal_train.sh ./predeal_train.sh ./train.csv ./train_after.csv
Then check the script and processed data in the usr/local/dbtaobao/dataset directory_ after. Whether the CSV is all there.

Take the first ten lines.
8. Data set processing
1) Start Hadoop and create a subdirectory under the root directory dbtaobao/dataset of HDFS. The command is as follows:
hadoop fs -mkdir -p /dbtaobao/dataset/test_log hadoop fs -mkdir -p /dbtaobao/dataset/train_log

Test in Linux local file system_ after. csv,train_after.csv is uploaded to the "/ dbtaobao/dataset/ test_log" and "/ dbtaobao/dataset/ train_log" directories of the distributed file system HDFS.
hadoop fs -put "/root/dbtaobao/dataset/test_after.csv" /dbtaobao/dataset/test_log hadoop fs -put "/root/dbtaobao/dataset/train_after.csv" /dbtaobao/dataset/ train_log

Take a look at test in HDFS_ after. csv,train_ after. The first 10 records of CSV.
hadoop fs -cat /dbtaobao/dataset/test_log/test_after.csv | head -10 hadoop fs -cat /dbtaobao/dataset/train_log/train_after.csv | head -10
2) Create a new external table test in the hive dbtaobao database_ Log and train_log and point to test_after.csv and train_after.csv, the path is specified as:
‘/dbtaobao/dataset/test_log 'and' / dbtaobao/dataset/train_log’.
--New external table test_log
create external table test_log(
user_id int,
age_range int,
gender int,
merchant_id int,
label int
)
row format delimited
fields terminated by ','
location '/dbtaobao/dataset/test_log';
--New external table train_log
create external table train_log(
user_id int,
age_range int,
gender int,
merchant_id int,
label int
)
row format delimited
fields terminated by ','
location '/dbtaobao/dataset/train_log';
Query the first ten rows of the two tables to see if there is data.
select * from test_log limit 10; select * from train_log limit 10;
9. Data set analysis
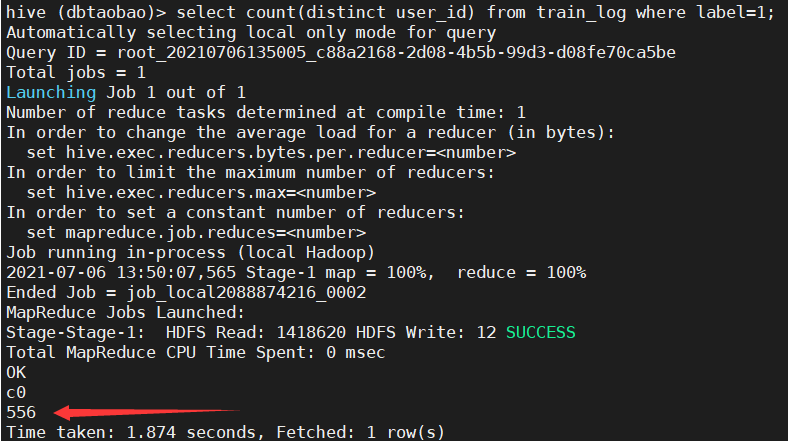
1) Query train_ How many repeat customers are there in the log (the buyer does not double calculate). (556)
select count(distinct user_id) from train_log where label=1;
2) In train_ In the log table, according to the classification of business ID, query the number of times each different business is selected by repeat customers, sort in ascending order according to the number of times, and find out the business ID that repeat customers like to buy most.
select merchant_id,count(distinct user_id) a from train_log where label=1 group by merchant_id order by a asc;
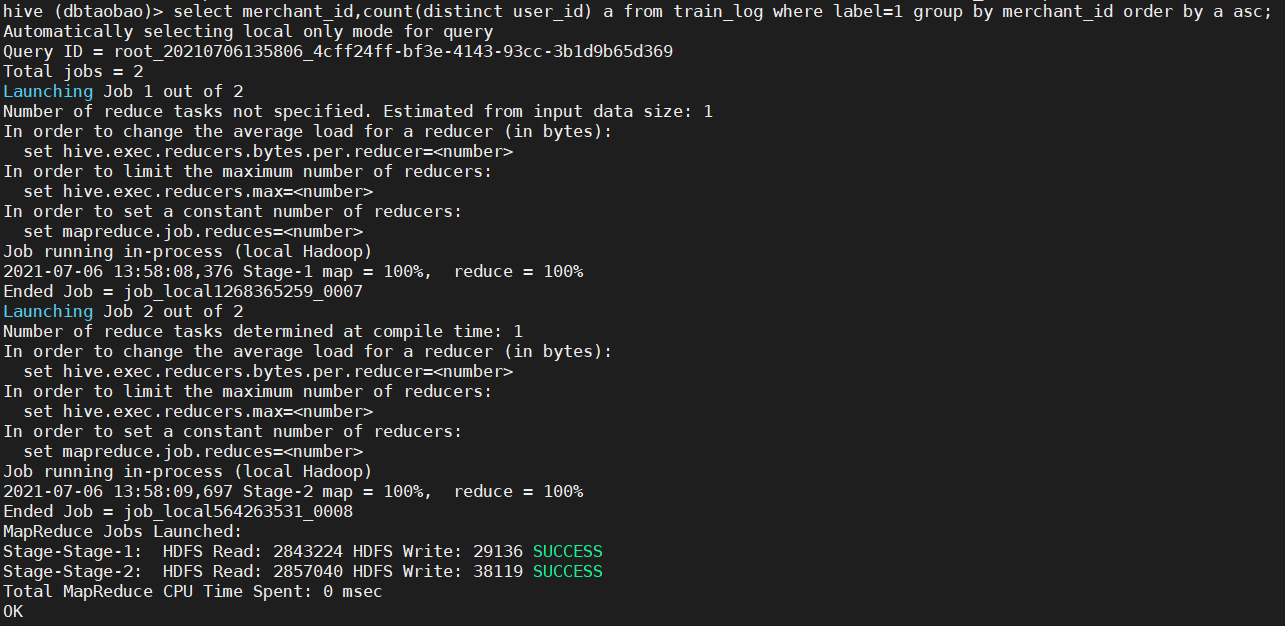
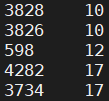
(intercepted part), 598
3) Analyze train_ In the log table, the number of repeat customers in each age group is classified by age group.
select age_range,count(distinct user_id) from train_log where label=1 group by age_range order by age_range asc;
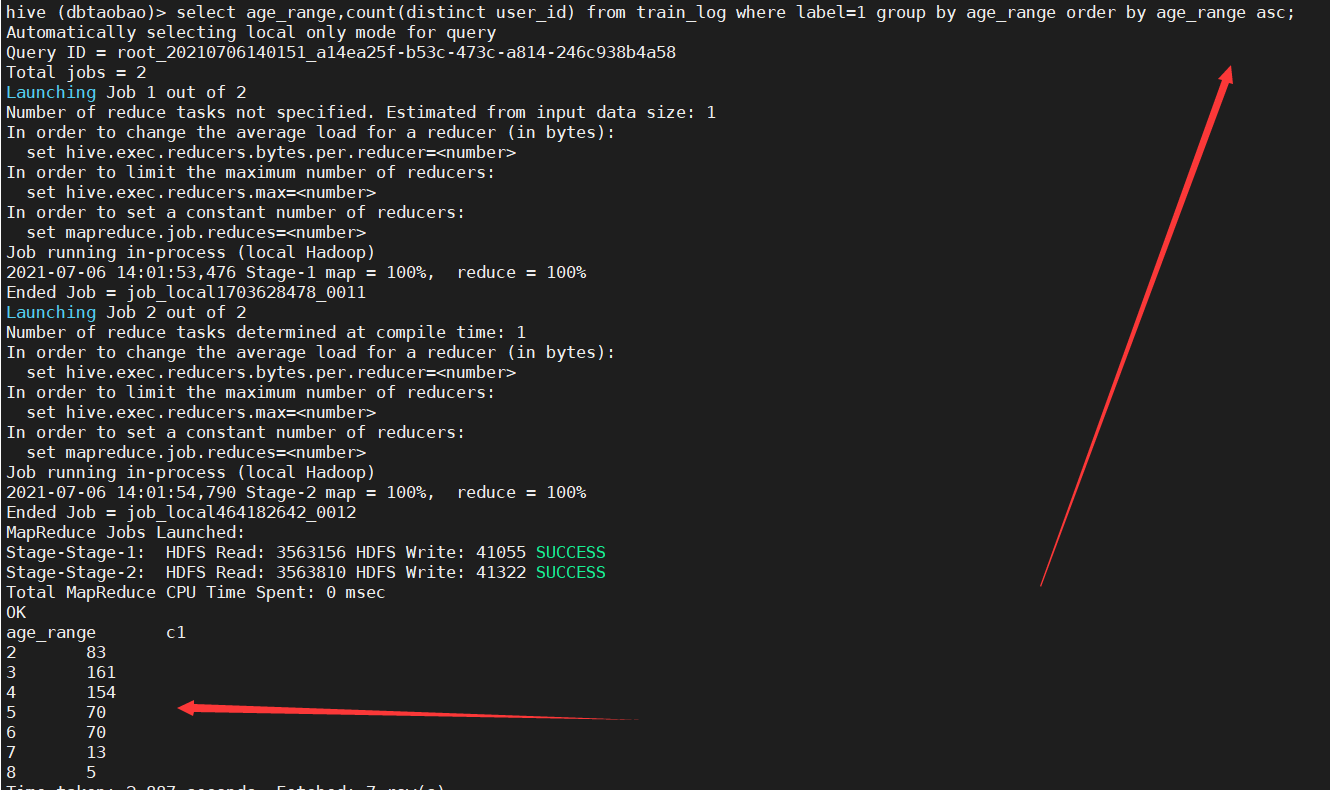
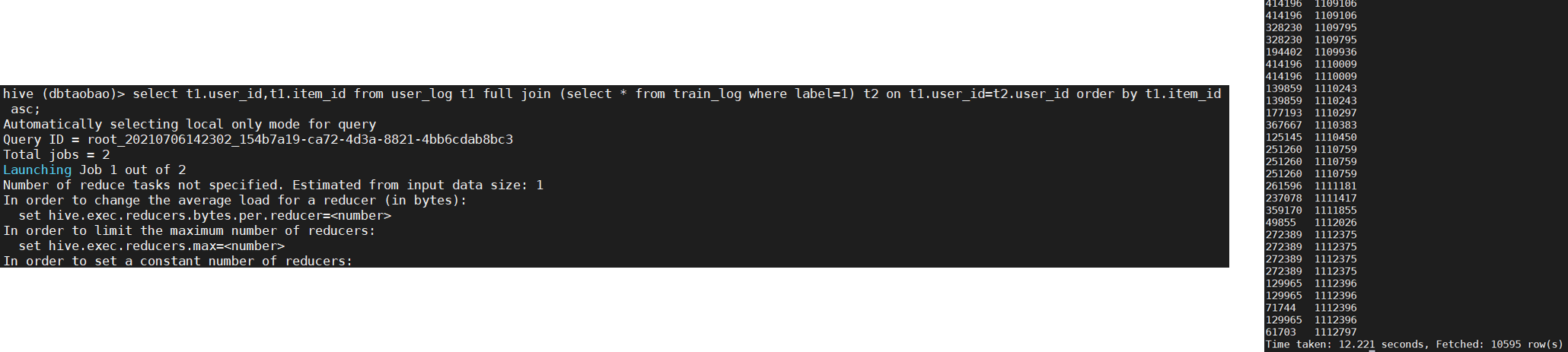
4) Please follow the table_ Log and train_log to query what goods repeat customers have bought? The commodity numbers are displayed in ascending order.
select t1.user_id,t1.item_id from user_log t1 full join (select * from train_log where label=1) t2 on t1.user_id=t2.user_id order by t1.item_id asc;
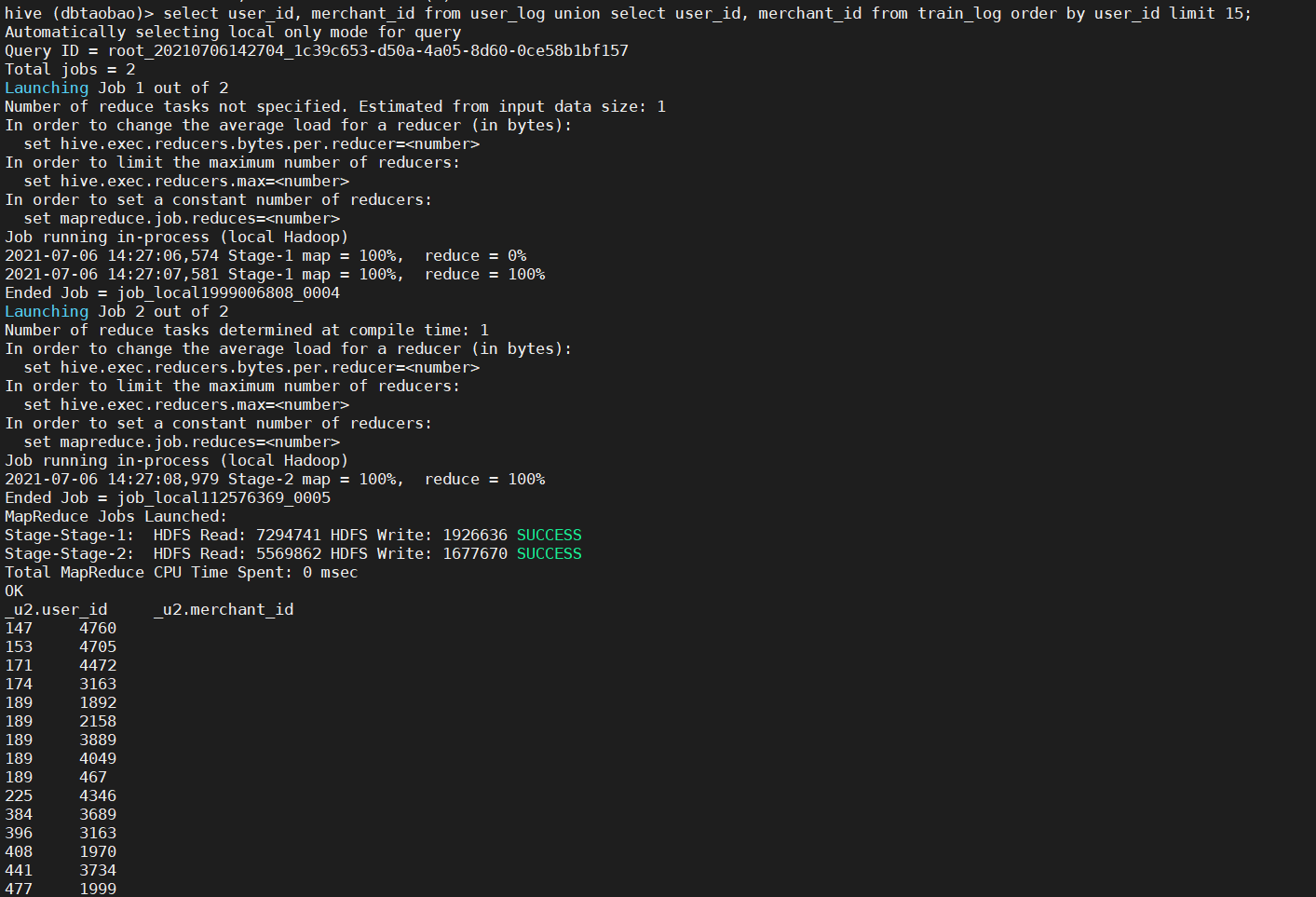
5) Please query the usage of union, the union query table user_log and train_ The user id and merchant id in the log are sorted by user id, and the first 15 lines are taken.
select user_id, merchant_id from user_log union select user_id, merchant_id from train_log order by user_id limit 15;
10. Function application of data set analysis
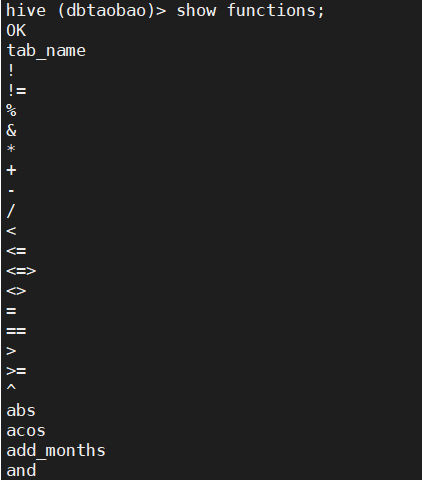
1) Check the functions of the system in hive (prompt: functions).
show functions;
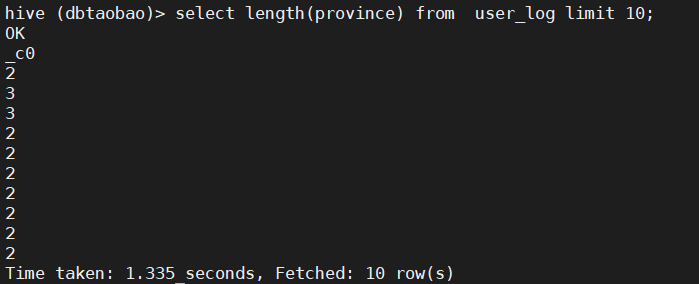
2) Statistical user_ The first 10 rows in the log table harvest the string length of the address (prompt length (province)).
select length(province) from user_log limit 10;
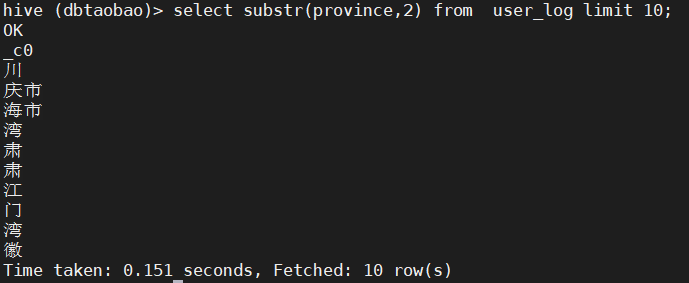
3) Intercept user_ The harvest address of the first 10 rows in the log table, showing the harvest address from the second character to the last character. (prompt: substr(province,2))
select substr(province,2) from user_log limit 10;
4) Create a new table map_train, train_ User in log_ ID and merchant_id is integrated into map table through map function_ A map type field u in the train_ m. And pass in data. Check map_ The structure of the train and the first ten rows of data.
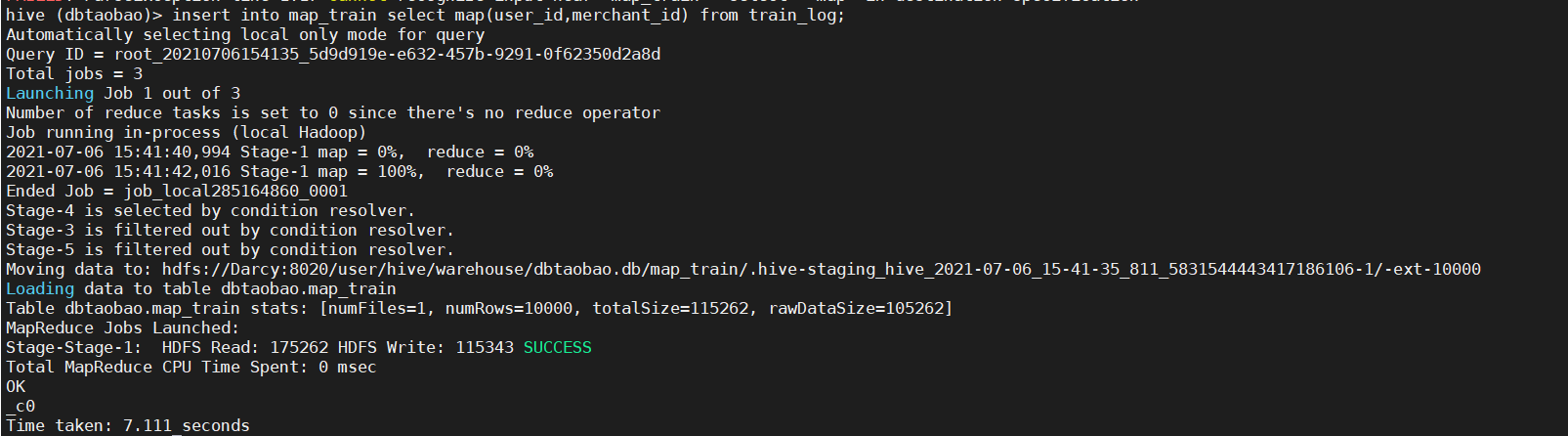
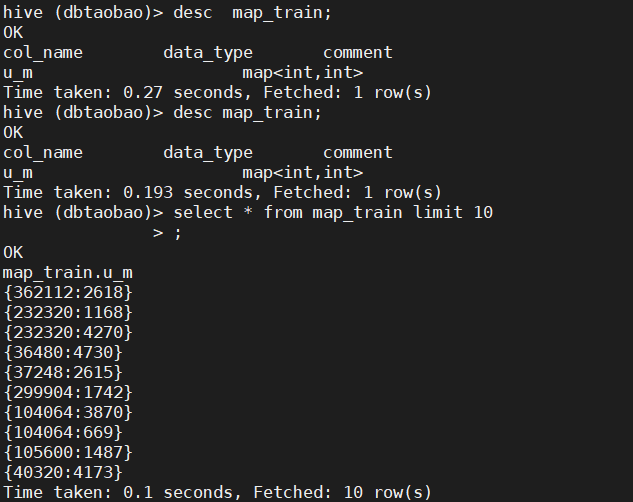
--Create a new table map_train create table map_train(u_m map<int,int>) row format delimited map keys terminated by ':'; --incoming data insert into map_train select map(user_id,merchant_id) from train_log; --inspect map_train Structure and first ten rows of data desc map_train; select * from map_train limit 10;

11. Data set partition processing
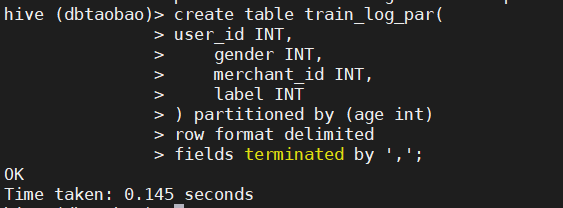
1) Create internal partition table train_ log_ par, user_ id INT,gender INT,merchant_ Id int and label int are partitioned by age int, and each field is divided by ','.
create table train_log_par(
user_id INT,
gender INT,
merchant_id INT,
label INT
) partitioned by (age int)
row format delimited
fields terminated by ',';
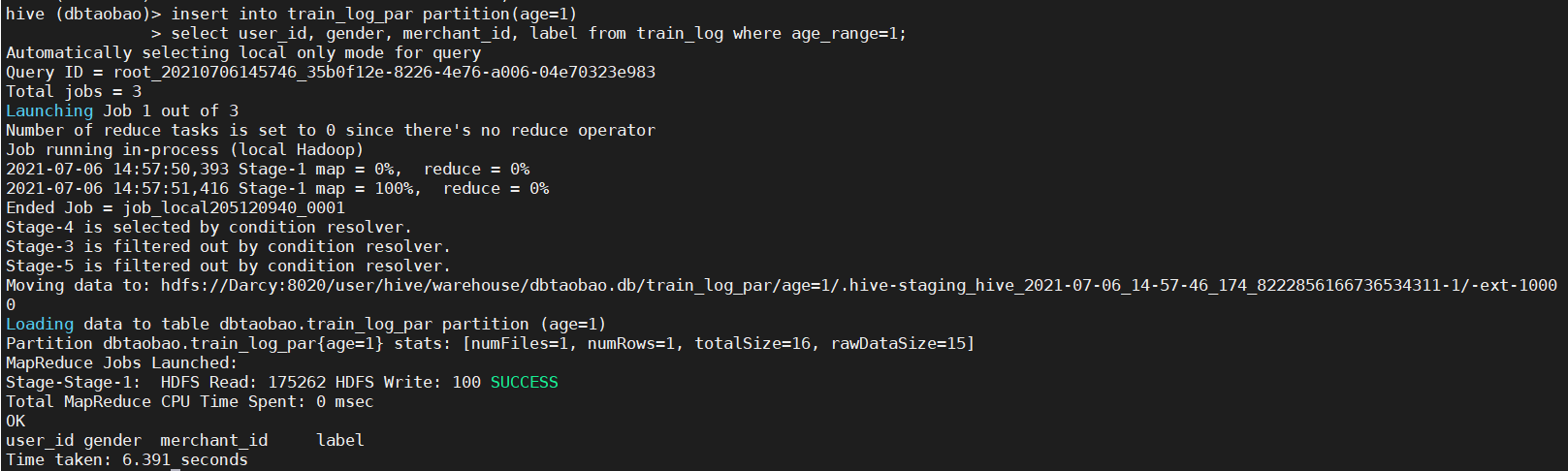
2) From train_ The buyer id, gender, merchant id, whether it is a repeat customer and age in the log table_ Insert the data with range = 1 into the train_log partition is in table age=1.
insert into train_log_par partition(age=1) select user_id, gender, merchant_id, label from train_log where age_range=1;

3) Is train_ log_ Add partition to par: age=2, age=3, age=4, age=5, age=6, age=7, age = 8 (prompt: alter... add)
alter table train_log_par add partition(age=2); alter table train_log_par add partition(age=3); alter table train_log_par add partition(age=4); alter table train_log_par add partition(age=5); alter table train_log_par add partition(age=6); alter table train_log_par add partition(age=7); alter table train_log_par add partition(age=8);
4) From train_ The buyer id, gender, merchant id, whether it is a repeat customer and age in the log table_ range=2,age_range=3,age_range=4,age_range=5,age_range=6,age_range=7,age_ Insert the data with range = 8 into the train_log partition is in table age=1.
insert into train_log_par partition(age=2) select user_id, gender, merchant_id, label from train_log where age_range=2; insert into train_log_par partition(age=3) select user_id, gender, merchant_id, label from train_log where age_range=3; insert into train_log_par partition(age=4) select user_id, gender, merchant_id, label from train_log where age_range=4; insert into train_log_par partition(age=5) select user_id, gender, merchant_id, label from train_log where age_range=5; insert into train_log_par partition(age=6) select user_id, gender, merchant_id, label from train_log where age_range=6; insert into train_log_par partition(age=7) select user_id, gender, merchant_id, label from train_log where age_range=7; insert into train_log_par partition(age=8) select user_id, gender, merchant_id, label from train_log where age_range=8;