[GiantPandaCV introduction] different from the previous BoTNet, although the title of CvT has the word convolution, it is still dominated by Transformer Block in general. Convolution is introduced in the processing of Token, which brings locality to the model. Finally, CvT won the highest Top1 accuracy of 87.7%.
introduction
The Motivation of the CvT architecture also introduces locality into the Vision Transformer architecture. It is expected to obtain a higher performance and efficiency trade-off by introducing locality. Therefore, we mainly focus on how CvT introduces locality. Specifically, two improvements are proposed:
- Convolutional token embedding
- Convolutional Projection
Through the above improvements, the model not only has the advantages of convolution (advantages brought by local receptive field, weight sharing, spatial down sampling and other characteristics), such as translation invariance, scale invariance, rotation invariance, but also maintains the advantages of Self Attention, such as dynamic attention, global semantic information, stronger generalization ability and so on.
To expand, the revolutionary vision transformer has two core points:
- In the first step, referring to the architecture of CNN, the Transformer is also designed as a multi-stage hierarchical architecture. Before each stage, the progressive token embedding is used. The dimension reduction function can be realized by using convolution + layer normalization (Note: while gradually reducing the sequence length, increasing the dimension of each token can be compared with the operation of halving the feature map and increasing the number of channels in convolution)
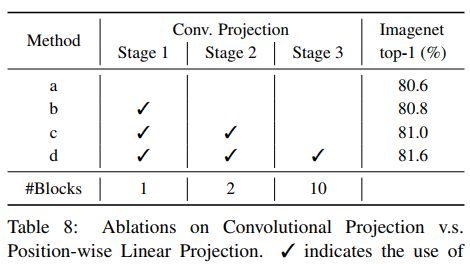
- In the second step, the original Linear Projection is replaced by the revolutionary projection. The module actually uses the deep separable convolution implementation, which can also effectively capture the local semantic information.
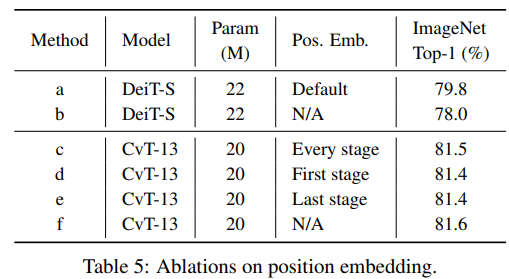
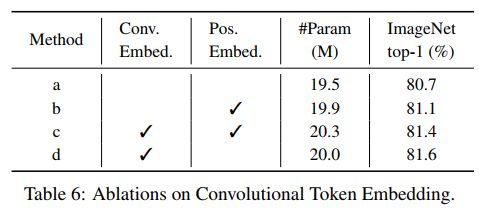
It should be noted that CvT removes the Positional Embedding module and finds that it has no impact on the performance of the model. It is considered that it can simplify the design of the architecture and adapt more easily when the resolution changes.
compare
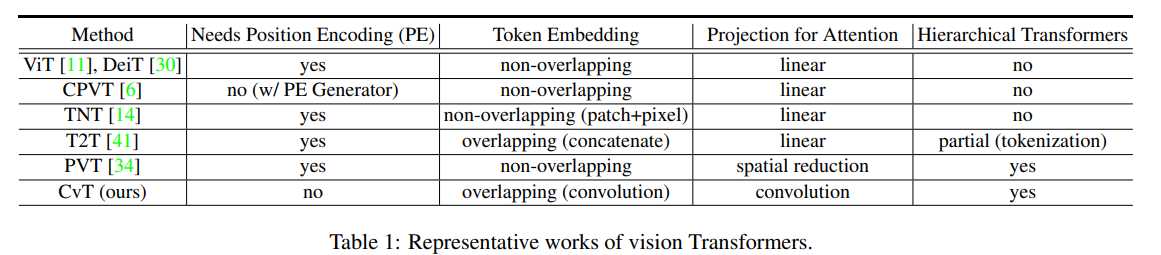
In relevant work, CvT summarizes a table for comparison:
method
It has been described in detail in the introduction. Let's repeat it with reference to the architecture diagram (describe it in as popular language as possible):
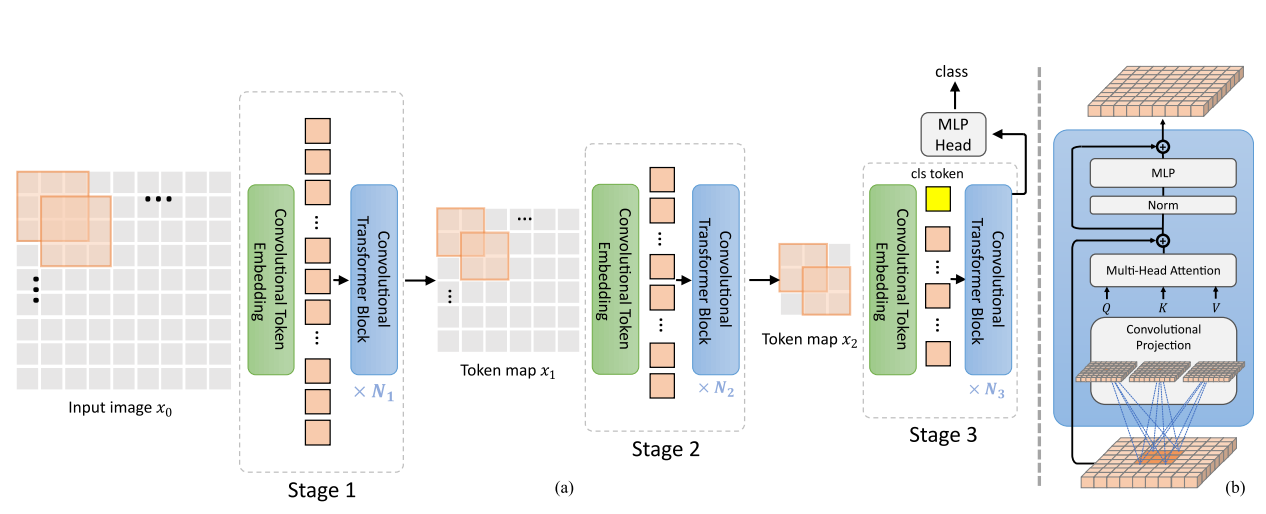
- The green box is the conv token embedding operation. Generally speaking, a super large convolution kernel is used to improve the problem of insufficient locality.
- The blue box on the right shows the improved self attention. Generally speaking, non local operation is used, and deep separable convolution is used to replace MLP for Projection, as shown in the following figure:
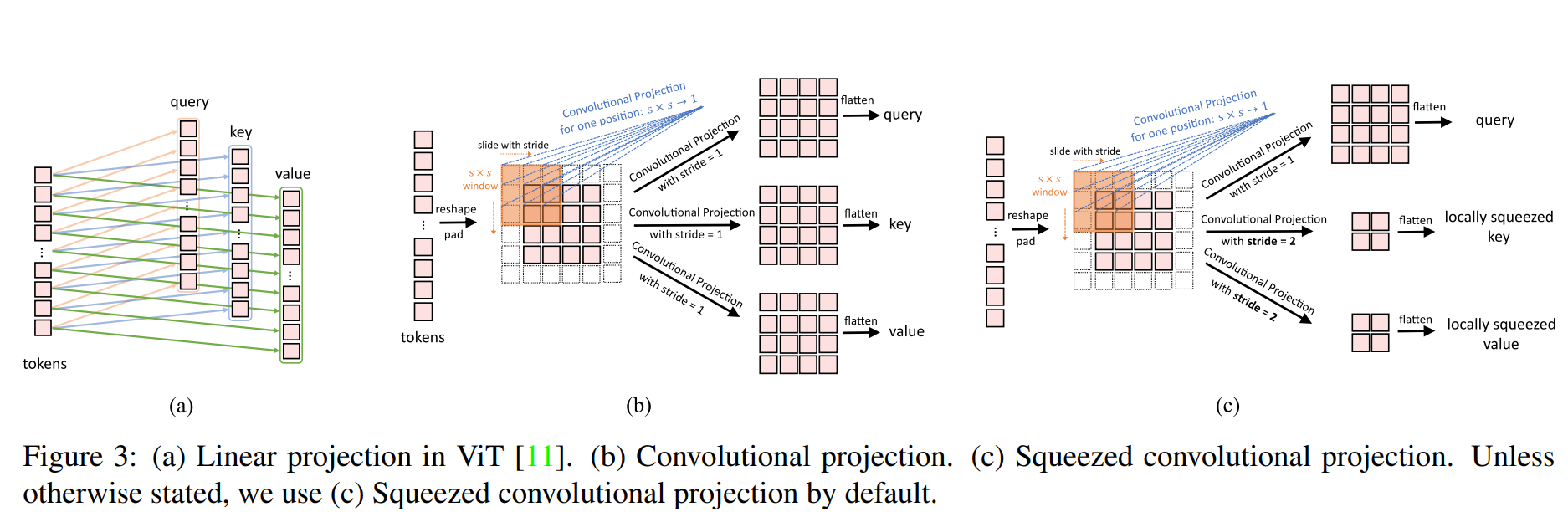
- As shown in figure (a), MLP is used for Linear Projection in Vision Transformer. Such information is global, but the amount of calculation is large.
- As shown in figure (b), convolution is used for mapping. This operation is similar to Non Local Network. Convolution is used for mapping.
- As shown in figure (c), convolution with stripe is used for compression. This is in consideration of efficiency. The number of token s can be reduced by four times, resulting in a certain performance loss.
Positional embedding discussion:
Because the revolutionary projection is used in each Transformer Block, combined with the revolutionary token embedding operation, it can give the model enough ability to model local spatial relationships. Therefore, the Positional Embedding operation in the Transformer can be removed. It is found from the table below that pe has little effect on the performance of the model.
Comparison with other work:
- Concurrent work 1: tokens to tokens vit: use Progressive Tokenization to integrate adjacent tokens. The transformer based backbone network can not only be localized, but also reduce the length of token sequence.
- Difference: CvT uses a multi-stage process. While the token length decreases, its dimension increases, so as to ensure the capacity of the model. At the same time, the amount of calculation is improved compared with T2T.
- Concurrent work 2: Pyramid Vision Transformer(PVT): the pyramid architecture is introduced so that PVT can be used as a Backbone in the sense prediction task.
- Difference: CvT also uses pyramid architecture. The difference is that CvT proposes to use stripe convolution to realize spatial downsampling and further integrate local information.
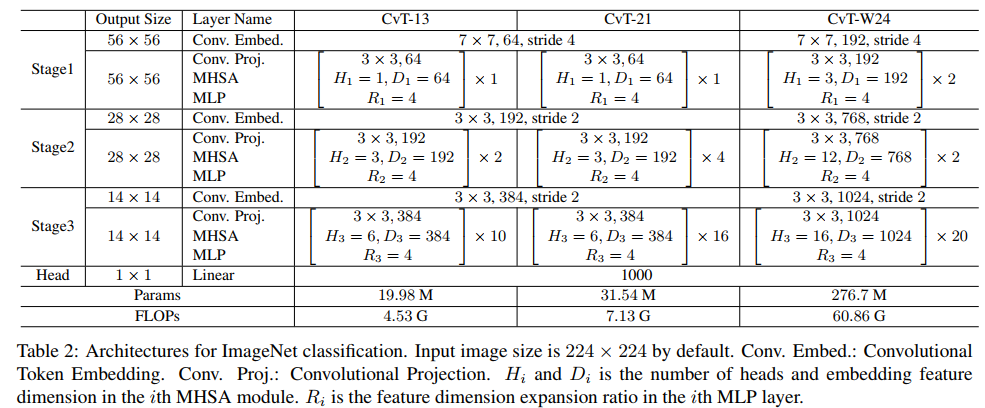
The final model architecture is as follows:
experiment
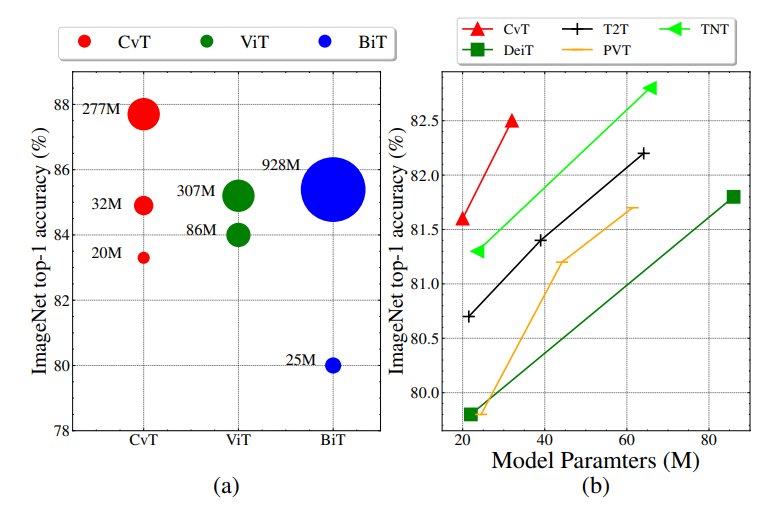
What is interesting in the left figure is BiT. This is Google's article big transfer, which explores the effect of CNN architecture on large-scale data and training. It can be seen that even the pure CNN architecture can have a very large number of model parameters, while the number of model parameters of Vision Transformer and CvT are much smaller than BiT under the same accuracy, To a certain extent, this shows that the performance of Transformer combined with CNN can be very considerable when the amount of data is sufficient, which is better than the model performance of simple CNN architecture.
The right figure shows the performance comparison between CvT and several vision transformer architectures. It can be seen that CvT does a very good job in trade-offs.
Compared with SOTA:
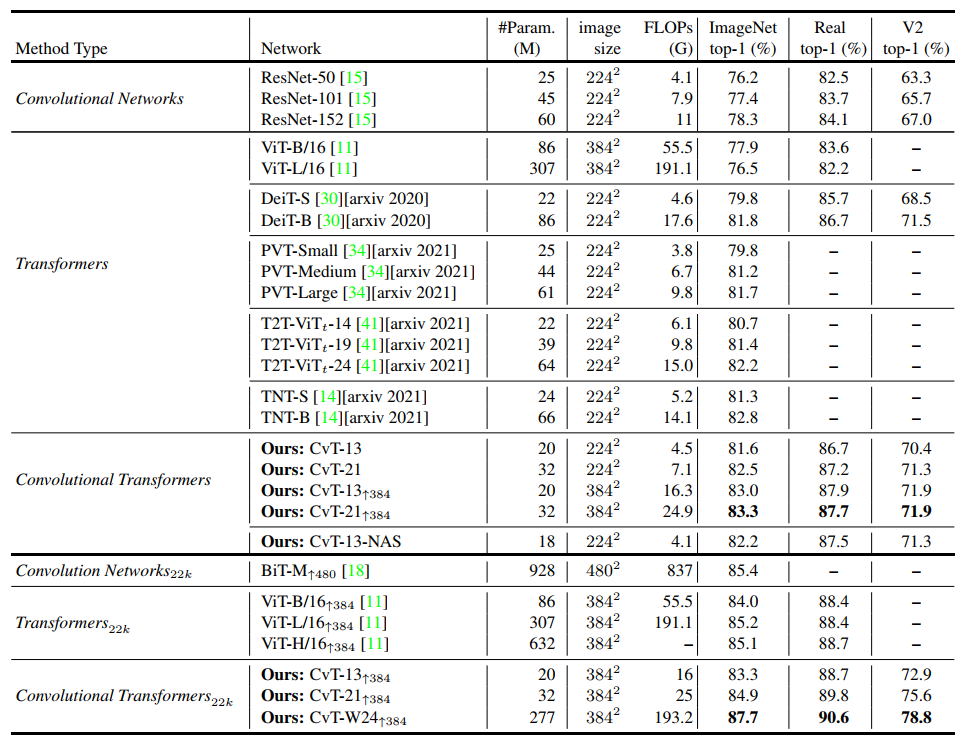
Interestingly, CvT-13-NAS also adopts the search method DA-NAS. The main search objects are key and value strings and MLP Expansion Ratio. The final search result is slightly better than Baseline.
Without JFT data set, the highest adjustment of CvT can reach the top1 accuracy of 87.7%.
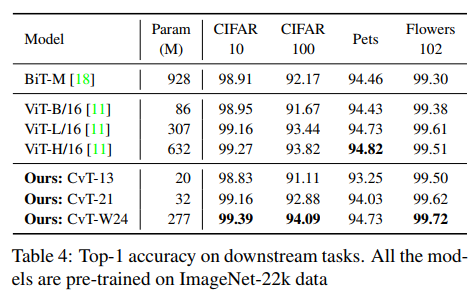
Other dataset results:
Ablation Experiment
code
Implementation of Convolutional Token Embedding Code: it can be seen that it is actually the locality introduced by the sliding of large convolution core + large Stride.
class ConvEmbed(nn.Module):
""" Image to Conv Embedding
"""
def __init__(self,
patch_size=7,
in_chans=3,
embed_dim=64,
stride=4,
padding=2,
norm_layer=None):
super().__init__()
patch_size = to_2tuple(patch_size)
self.patch_size = patch_size
self.proj = nn.Conv2d(
in_chans, embed_dim,
kernel_size=patch_size,
stride=stride,
padding=padding
)
self.norm = norm_layer(embed_dim) if norm_layer else None
def forward(self, x):
x = self.proj(x)
B, C, H, W = x.shape
x = rearrange(x, 'b c h w -> b (h w) c')
if self.norm:
x = self.norm(x)
x = rearrange(x, 'b (h w) c -> b c h w', h=H, w=W)
return x
The code implementation of the revolutionary project is as follows:_ build_projection function:
class Attention(nn.Module):
def __init__(self,
dim_in,
dim_out,
num_heads,
qkv_bias=False,
attn_drop=0.,
proj_drop=0.,
method='dw_bn',
kernel_size=3,
stride_kv=1,
stride_q=1,
padding_kv=1,
padding_q=1,
with_cls_token=True,
**kwargs
):
super().__init__()
self.stride_kv = stride_kv
self.stride_q = stride_q
self.dim = dim_out
self.num_heads = num_heads
# head_dim = self.qkv_dim // num_heads
self.scale = dim_out ** -0.5
self.with_cls_token = with_cls_token
self.conv_proj_q = self._build_projection(
dim_in, dim_out, kernel_size, padding_q,
stride_q, 'linear' if method == 'avg' else method
)
self.conv_proj_k = self._build_projection(
dim_in, dim_out, kernel_size, padding_kv,
stride_kv, method
)
self.conv_proj_v = self._build_projection(
dim_in, dim_out, kernel_size, padding_kv,
stride_kv, method
)
self.proj_q = nn.Linear(dim_in, dim_out, bias=qkv_bias)
self.proj_k = nn.Linear(dim_in, dim_out, bias=qkv_bias)
self.proj_v = nn.Linear(dim_in, dim_out, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim_out, dim_out)
self.proj_drop = nn.Dropout(proj_drop)
def _build_projection(self,
dim_in,
dim_out,
kernel_size,
padding,
stride,
method):
if method == 'dw_bn':
proj = nn.Sequential(OrderedDict([
('conv', nn.Conv2d(
dim_in,
dim_in,
kernel_size=kernel_size,
padding=padding,
stride=stride,
bias=False,
groups=dim_in
)),
('bn', nn.BatchNorm2d(dim_in)),
('rearrage', Rearrange('b c h w -> b (h w) c')),
]))
elif method == 'avg':
proj = nn.Sequential(OrderedDict([
('avg', nn.AvgPool2d(
kernel_size=kernel_size,
padding=padding,
stride=stride,
ceil_mode=True
)),
('rearrage', Rearrange('b c h w -> b (h w) c')),
]))
elif method == 'linear':
proj = None
else:
raise ValueError('Unknown method ({})'.format(method))
return proj
def forward_conv(self, x, h, w):
if self.with_cls_token:
cls_token, x = torch.split(x, [1, h*w], 1)
x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w)
if self.conv_proj_q is not None:
q = self.conv_proj_q(x)
else:
q = rearrange(x, 'b c h w -> b (h w) c')
if self.conv_proj_k is not None:
k = self.conv_proj_k(x)
else:
k = rearrange(x, 'b c h w -> b (h w) c')
if self.conv_proj_v is not None:
v = self.conv_proj_v(x)
else:
v = rearrange(x, 'b c h w -> b (h w) c')
if self.with_cls_token:
q = torch.cat((cls_token, q), dim=1)
k = torch.cat((cls_token, k), dim=1)
v = torch.cat((cls_token, v), dim=1)
return q, k, v
def forward(self, x, h, w):
if (
self.conv_proj_q is not None
or self.conv_proj_k is not None
or self.conv_proj_v is not None
):
q, k, v = self.forward_conv(x, h, w)
q = rearrange(self.proj_q(q), 'b t (h d) -> b h t d', h=self.num_heads)
k = rearrange(self.proj_k(k), 'b t (h d) -> b h t d', h=self.num_heads)
v = rearrange(self.proj_v(v), 'b t (h d) -> b h t d', h=self.num_heads)
attn_score = torch.einsum('bhlk,bhtk->bhlt', [q, k]) * self.scale
attn = F.softmax(attn_score, dim=-1)
attn = self.attn_drop(attn)
x = torch.einsum('bhlt,bhtv->bhlv', [attn, v])
x = rearrange(x, 'b h t d -> b t (h d)')
x = self.proj(x)
x = self.proj_drop(x)
return x
reference resources
https://github.com/microsoft/CvT/blob/main/lib/models/cls_cvt.py
https://arxiv.org/pdf/2103.15808.pdf
https://zhuanlan.zhihu.com/p/142864566
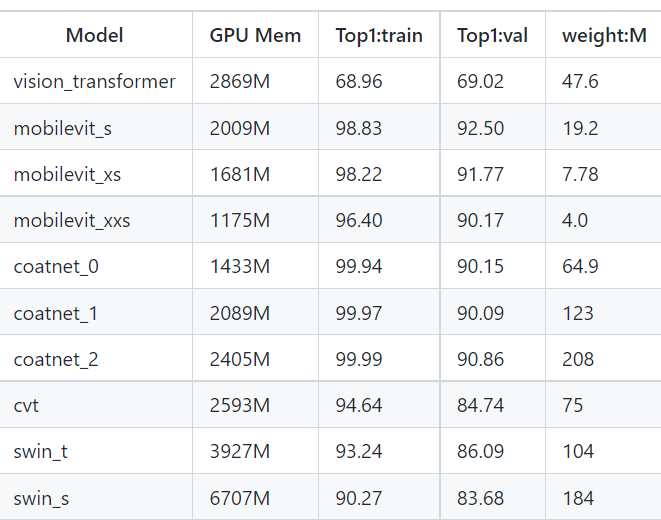
The author modified the Stride and other parameters in the CvT on the cifar10 dataset, and obtained the following results without any data enhancement and Trick. The Top1 is 84.74. Although it seems that the performance is poor, it has not been adjusted and combined with the data enhancement method, and only 200 epoch s have been trained.
python train.py --model 'cvt' --name "cvt" --sched 'cosine' --epochs 200 --lr 0.01
Interested parties can click the following link to adjust parameters:
https://github.com/pprp/pytorch-cifar-model-zoo