Station B tutorial address
https://www.bilibili.com/video/BV18b4y1J7a6/
introduce
Mobilenet is a network series created by Google. It has been released to V3. Each version update is an optimization modification on the previous network. Mobilenet focuses on lightweight networks, which means less network parameters, faster execution speed and easier deployment to terminal devices. There are also many applications in mobile terminals and embedded devices.
MobilenetV3 has made a series of small modifications to MobilenetV2, which has achieved another breakthrough in accuracy and improved the speed.
Main structure
Deep separable convolution

Deep separable convolution is widely used in the main part of MobilenetV3. We introduced it in detail in the previous lecture. Again, it is pointed out that this convolution structure greatly reduces the amount of parameters and is very beneficial to lightweight networks.
SE attention mechanism
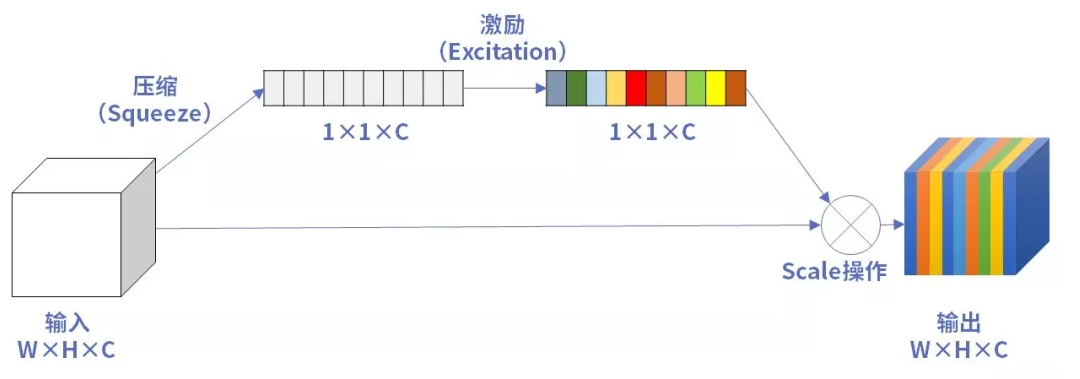
In the infrastructure of MobilenetV3, SE attention mechanism is used, which we also introduced in the previous lecture. Because SE attention mechanism will add a small number of parameters, but the accuracy is improved. SE attention mechanism is added to some layers in all MobilenetV3 to pursue the balance between accuracy and parameter quantity. Moreover, some modifications have been made to the initial attention mechanism, mainly reflected in the convolution layer and activation function.
New activation function
The hardwise activation function is used in MobilenetV3 instead of Swish activation.
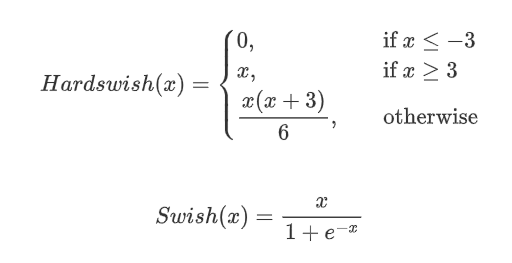
In terms of formula, hardwise replaces the exponential function, which reduces the calculation cost and lightens the model.

Making the function image and gradient image, we can see that the original function is very close. There is a mutation in hardwise on the gradient map, which is unfavorable for training, while the swish gradient changes smoothly. In other words, hardwise speeds up the operation speed, but it is not conducive to improving the accuracy. After many experiments, MobilenetV3 found that hardwise had less accuracy loss in deeper networks. Finally, Relu activation was used in the first half of the network and hardwise activation was used in deep networks.
Modified tail structure
MobilenetV3 modifies the tail structure of MobilenetV2 as follows:

The last tail of MobilenetV2 uses four convolution layers and an average pooling layer. MobilenetV3 directly connects the average pooling layer after modifying the number of channels through only one convolution layer. This also greatly reduces the amount of network parameters. In the experiment, it is found that the accuracy is not reduced.
Overall network
After the above minor modifications, the overall network form of MobilenetV3 is very clear. Its general structural units are as follows:

The whole network is composed of multiple such units stacked. MobilenetV3 has two versions: large and small. We take large as an example.
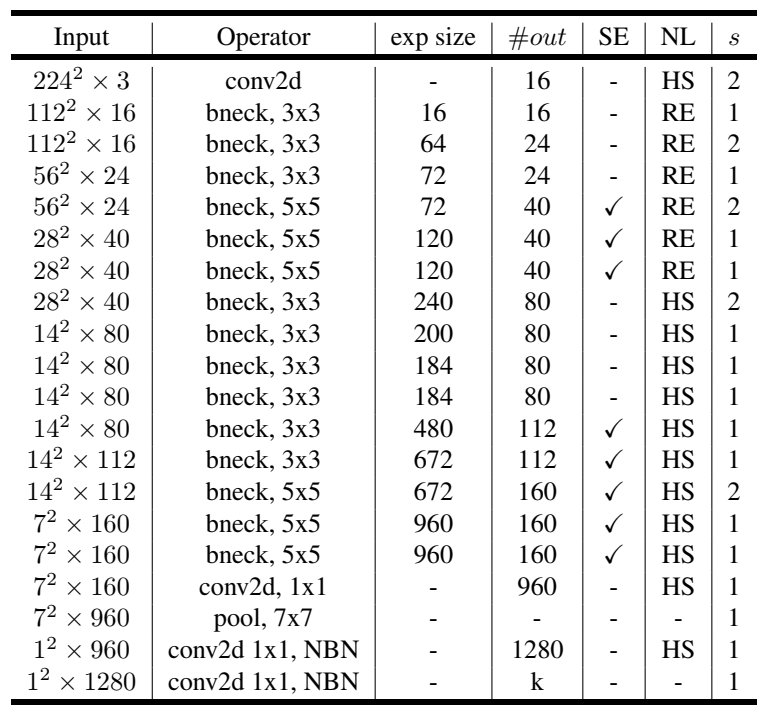
In the table, input represents the output shape, exp size represents the number of expanded channels, out represents the number of output channels, SE represents whether to use SE attention mechanism, NL represents the activation function used, and S represents the step size of convolution.
bneck is the format shown in the first figure. You can see that the middle is reused many times. First use a convolution layer to expand the number of channels to 16, then fully extract the features through multiple bnecks, then use a tail structure, and finally output a matrix of the number of categories. At present, the imagenet data set is usually used in writing papers, which is a huge classification data set of 1000 categories, so the dimension of the final output of the official network is generally 1000.
Training MobilenetV3 with PaddleClas
PaddleClas is a visual classification suite that relies on PaddleClas, which integrates many typical networks of classification. We use MobilenetV3 in PaddleClas to train garbage classification tasks.
The overall code implementation of MobileNetV3 in PaddleClas is as follows:
class MobileNetV3(TheseusLayer):
"""
MobileNetV3
Args:
config: list. MobileNetV3 depthwise blocks config.
scale: float=1.0. The coefficient that controls the size of network parameters.
class_num: int=1000. The number of classes.
inplanes: int=16. The output channel number of first convolution layer.
class_squeeze: int=960. The output channel number of penultimate convolution layer.
class_expand: int=1280. The output channel number of last convolution layer.
dropout_prob: float=0.2. Probability of setting units to zero.
Returns:
model: nn.Layer. Specific MobileNetV3 model depends on args.
"""
def __init__(self,
config,
scale=1.0,
class_num=1000,
inplanes=STEM_CONV_NUMBER,
class_squeeze=LAST_SECOND_CONV_LARGE,
class_expand=LAST_CONV,
dropout_prob=0.2,
return_patterns=None):
super().__init__()
self.cfg = config
self.scale = scale
self.inplanes = inplanes
self.class_squeeze = class_squeeze
self.class_expand = class_expand
self.class_num = class_num
self.conv = ConvBNLayer(
in_c=3,
out_c=_make_divisible(self.inplanes * self.scale),
filter_size=3,
stride=2,
padding=1,
num_groups=1,
if_act=True,
act="hardswish")
self.blocks = nn.Sequential(* [
ResidualUnit(
in_c=_make_divisible(self.inplanes * self.scale if i == 0 else
self.cfg[i - 1][2] * self.scale),
mid_c=_make_divisible(self.scale * exp),
out_c=_make_divisible(self.scale * c),
filter_size=k,
stride=s,
use_se=se,
act=act) for i, (k, exp, c, se, act, s) in enumerate(self.cfg)
])
self.last_second_conv = ConvBNLayer(
in_c=_make_divisible(self.cfg[-1][2] * self.scale),
out_c=_make_divisible(self.scale * self.class_squeeze),
filter_size=1,
stride=1,
padding=0,
num_groups=1,
if_act=True,
act="hardswish")
self.avg_pool = AdaptiveAvgPool2D(1)
self.last_conv = Conv2D(
in_channels=_make_divisible(self.scale * self.class_squeeze),
out_channels=self.class_expand,
kernel_size=1,
stride=1,
padding=0,
bias_attr=False)
self.hardswish = nn.Hardswish()
self.dropout = Dropout(p=dropout_prob, mode="downscale_in_infer")
self.flatten = nn.Flatten(start_axis=1, stop_axis=-1)
self.fc = Linear(self.class_expand, class_num)
if return_patterns is not None:
self.update_res(return_patterns)
self.register_forward_post_hook(self._return_dict_hook)
def forward(self, x):
x = self.conv(x)
x = self.blocks(x)
x = self.last_second_conv(x)
x = self.avg_pool(x)
x = self.last_conv(x)
x = self.hardswish(x)
x = self.dropout(x)
x = self.flatten(x)
x = self.fc(x)
return x
The specific training is also very simple. We only need to modify the corresponding configuration file and store it in the ppcls/config directory. For training your own dataset, focus on the need to modify the relevant parameters of the dataset, batch_size and the size of the output image. Others can be modified according to their own needs.
The method of training is to use command line commands.
Training Command:
python tools/train.py -c ./ppcls/configs/quick_start/MobileNetV3_large_x1_0.yaml -o Arch.pretrained=True -o Global.device=gpu
Breakpoint Training Command:
python tools/train.py -c ./ppcls/configs/quick_start/MobileNetV3_large_x1_0.yaml -o Global.checkpoints="./output/MobileNetV3_large_x1_0/epoch_5" -o Global.device=gpu
Forecast command:
python tools/infer.py -c ./ppcls/configs/quick_start/MobileNetV3_large_x1_0.yaml -o Infer.infer_imgs=./188.jpg -o Global.pretrained_model=./output/MobileNetV3_large_x1_0/best_model
reference material
https://arxiv.org/abs/1905.02244