Elastasearch - Introduction and installation
Full text search belongs to the most common requirement, open source Elasticsearch (hereinafter referred to as ES) is the first choice of full-text search engine. It can quickly store, search and analyze massive data.
The bottom layer of ES is the open source library Lucene. ES is a Lucene based search server. It provides a distributed full-text search engine based on restful web interface. ES is an open source project developed in Java language and based on Apache protocol. It is the most popular enterprise search engine at present. ES is widely used in cloud computing, can achieve real-time search, and has the characteristics of stability, reliability and speed.
file
Chinese documents : Based on version 2.3, some contents are outdated
Official documents : the details shall be subject to the official documents
Related concepts
-
Index: an index is a collection of documents with similar characteristics, similar to the concept of database in MySql.
-
Type: type is a logical category partition of an index. Generally, it is a document type with a set of public fields, similar to the concept of tables in MySql. Note: in Elasticsearch 6.0.0 and later versions, type type is removed, and an index can only contain one type.
reason:
1. In relational databases, table s are independent (stored independently), but different types in the same index in es are stored in the same index (lucene's index file). Therefore, the mapping of fields with the same name in different types must be consistent.
2. Different types of "records" are stored in the same index, which will affect the compression performance of lucene.
ES 7: the type parameter in the URL is optional. For example, the document type is not required to index a document
ES 8: the Type parameter in the URL is no longer supported
Migration solution: migrate the index from multi type to single type, and each type of document has an independent index
-
Document: a document is a basic information unit that can be indexed. It is expressed in JSON, similar to the concept of row record in MySql.
-
Shards (shards): when an index stores a large amount of data, it may exceed the hardware limit of a single node. To solve this problem, Elasticsearch provides the concept of subdividing the index into Shards. The shard mechanism gives the index the ability to expand horizontally and allows cross shard distribution and parallelization operations, so as to improve performance and throughput.
-
Replicas: in the network environment where failures may occur, a failover mechanism is required. Elasticsearch provides the function of replicating index fragments into one or more replicas. Replicas provide high availability in case of failure of some nodes.
-
Cluster: a cluster is a collection of one or more nodes that together save the entire data and provide federated index and search functions across all nodes. Each cluster has its own unique cluster name, and nodes join the cluster through the name.
-
Node: a node refers to a single elasticsearch instance belonging to a cluster, which stores data and participates in the indexing and search functions of the cluster. Nodes can be configured to join a specific cluster by cluster name. By default, each node is set to join a cluster named elasticsearch.
Inverted index: Reference address
Docker installation Elasticsearch and Kibana
1. Download the image file
# Storing and retrieving data docker pull elasticsearch:7.4.2 # Visual retrieval data docker pull kibana:7.4.2
2. Configure the mounted data folder
# Create profile directory mkdir -p /mydata/elasticsearch/config # Create data directory mkdir -p /mydata/elasticsearch/data # Make the files in the / mydata/elasticsearch / folder readable and writable chmod -R 777 /mydata/elasticsearch/ # Configure any machine to access elasticsearch echo "http.host: 0.0.0.0" >/mydata/elasticsearch/config/elasticsearch.yml
3. Start Elasticsearch
The \ after the command is a newline character. Note that there is a space in front of it
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \ -e "discovery.type=single-node" \ -e ES_JAVA_OPTS="-Xms64m -Xmx512m" \ -v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \ -v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \ -v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \ -d elasticsearch:7.4.2
- p 9200:9200 -p 9300:9300: two ports are exposed. 9200 is used for HTTP REST API requests. 9300 is the communication port between ES in the distributed cluster state;
- E "discovery. Type = single node": es runs as a single node
- e ES_JAVA_OPTS="-Xms64m -Xmx512m": set startup to occupy memory. If it is not set, it may occupy all memory of the current system
- v: Mount the configuration file, data file and plug-in data in the container to the local folder;
- d elasticsearch:7.6.2: Specifies the mirror to start
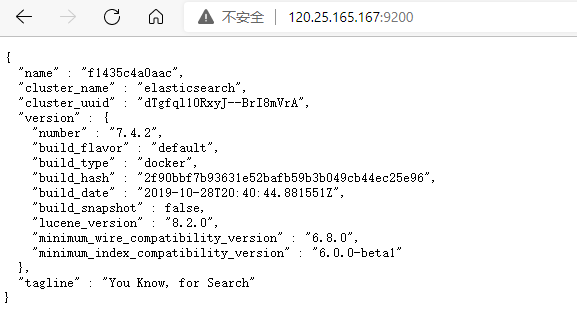
Visit IP:9200 and see the returned json data, indicating that the startup is successful.
4. Set Elasticsearch to start with Docker
# Currently, Docker starts automatically, so ES is also started automatically docker update elasticsearch --restart=always
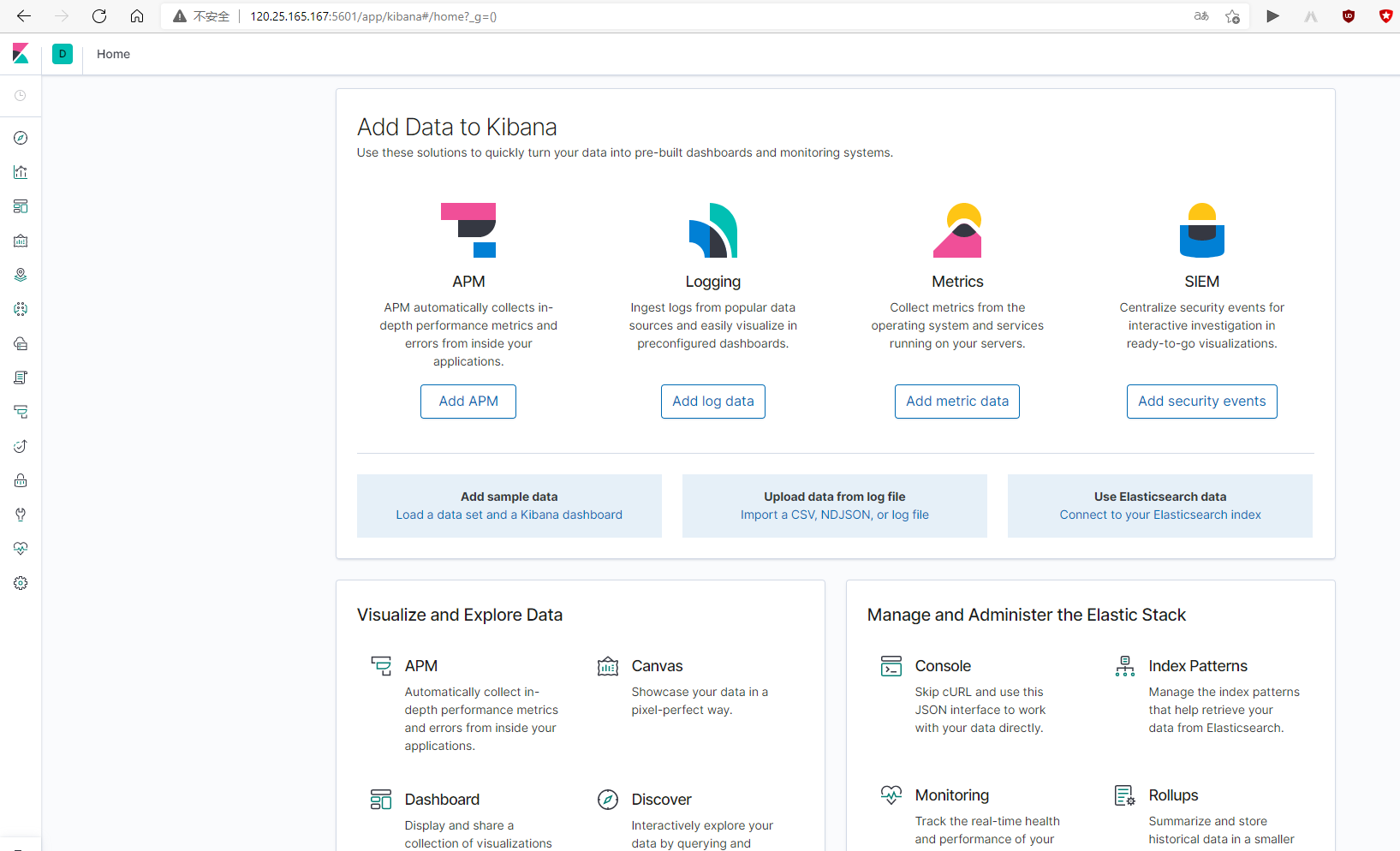
5. Start visualization Kibana
docker run --name kibana \ -e ELASTICSEARCH_HOSTS=http://120.25.165.166:9200 \ -p 5601:5601 \ -d kibana:7.4.2
- ELASTICSEARCH_HOSTS=http://120.25.165.166:9200: Set the IP address of your virtual machine here
Browser input 120.25 165.166:5601 test:
6. Set Kibana to start with Docker
# Currently, Docker starts automatically, so kibana also starts automatically docker update kibana --restart=always
Elasticsearch - getting started
Elasticsearch operates data through REST API interfaces. The following is a demonstration of its use through requests from several interfaces. (the current virtual machine IP is 120.25.165.167)
View cluster status_ cat
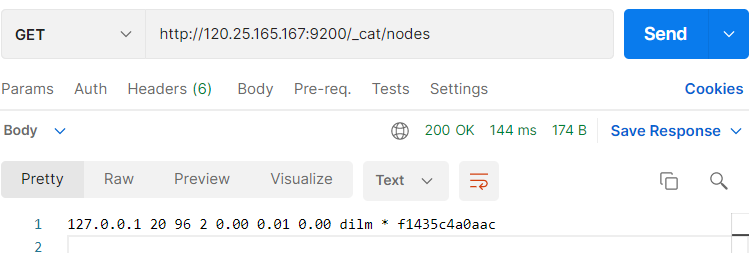
- /_ cat/nodes: view all nodes
Interface: GET http://120.25.165.167:9200/_cat/nodes
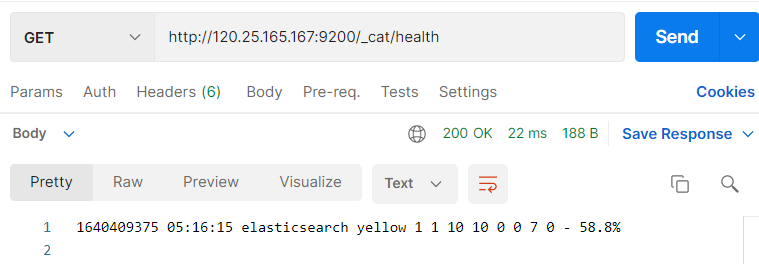
- /_ cat/health: View ES health
Interface: GET http://120.25.165.167:9200/_cat/health
- /_ cat/master: View master node information
Interface: GET http://120.25.165.167:9200/_cat/master
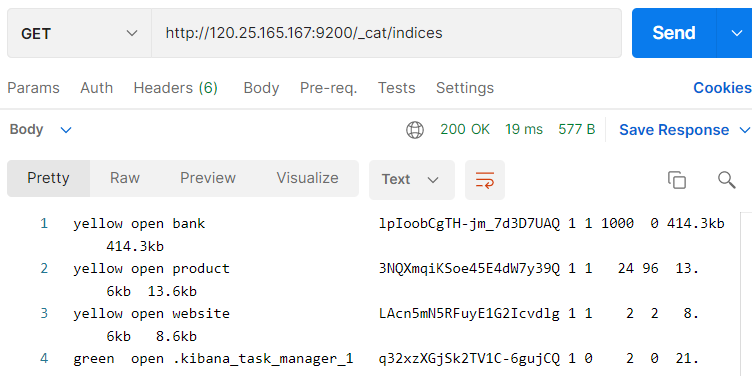
- /_ Cat / indexes: view all indexes
Interface: GET http://120.25.165.167:9200/_cat/indices
Index (add) a document
That is, save a piece of data in which index and type, and specify which unique identifier to use.
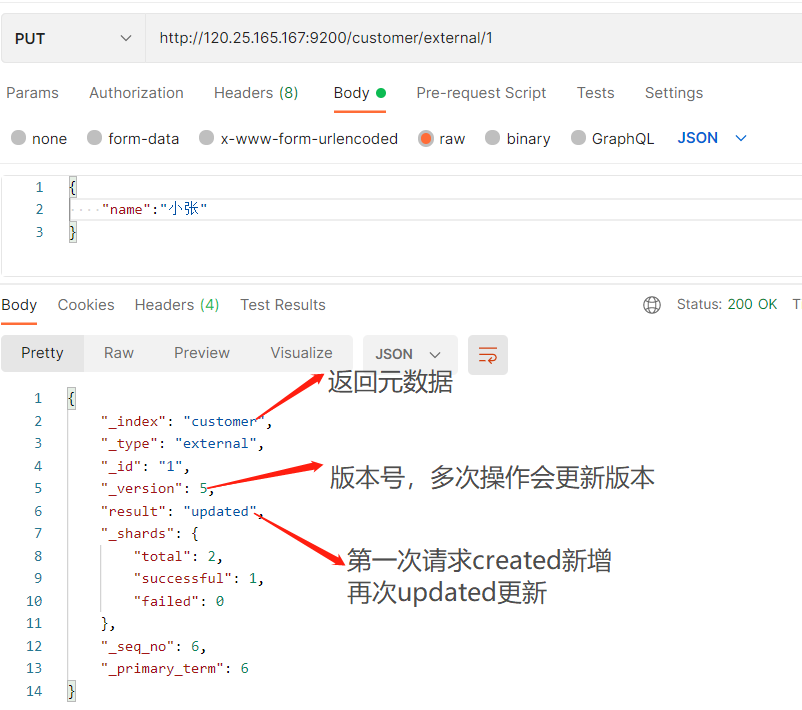
PUT request
Interface: PUT http://120.25.165.167:9200/customer/external/1
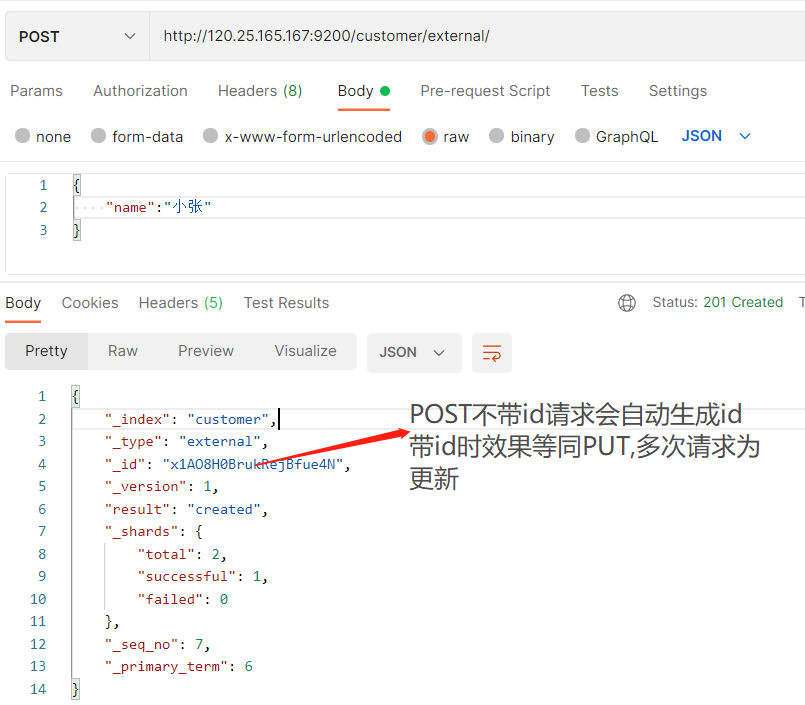
POST request
Interface: POST http://120.25.165.167:9200/customer/external/
Both PUT and POST are OK
- If you do not specify an id for POST addition, the id will be automatically generated. Specifying the id will modify the data and add a version number;
- PUT can be added or modified. PUT must specify id; Because PUT needs to specify an id, it is generally used for modification. If the id is not specified, an error will be reported.
View document
/index/type/id
Interface: GET http://120.25.165.167:9200/customer/external/1
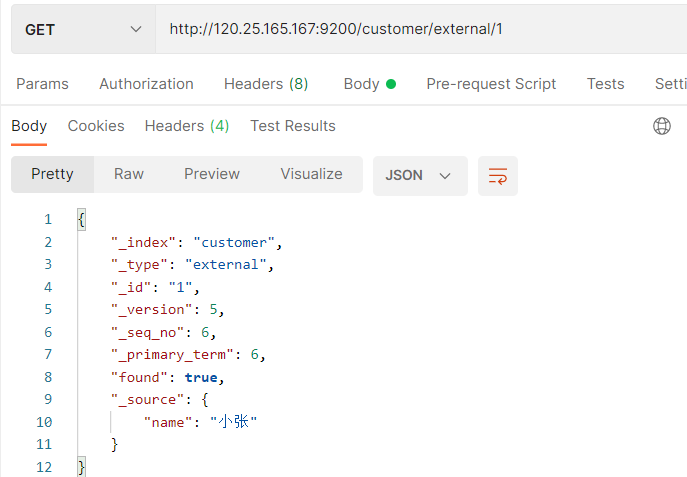
**Field interpretation:**
{
"_index": "customer", # At which index (Library)
"_type": "external", # In which type (table)
"_id": "1", # Document ID (record)
"_version": 5, # Version number
"_seq_no": 4, # The concurrency control field will be + 1 every time it is updated, which is used as an optimistic lock
"_primary_term": 1, # As above, the main partition will be reassigned. If it is restarted, it will change
"found": true,
"_source": { # data
"name": "zhangsan"
}
}
# Carry optimistic lock when updating_ seq_ no=0&_ primary_ Term = 1 update fails when the carried data does not match the actual value
Update document
/index/type/id/_update
Interface: POST http://120.25.165.167:9200/customer/external/1/_update
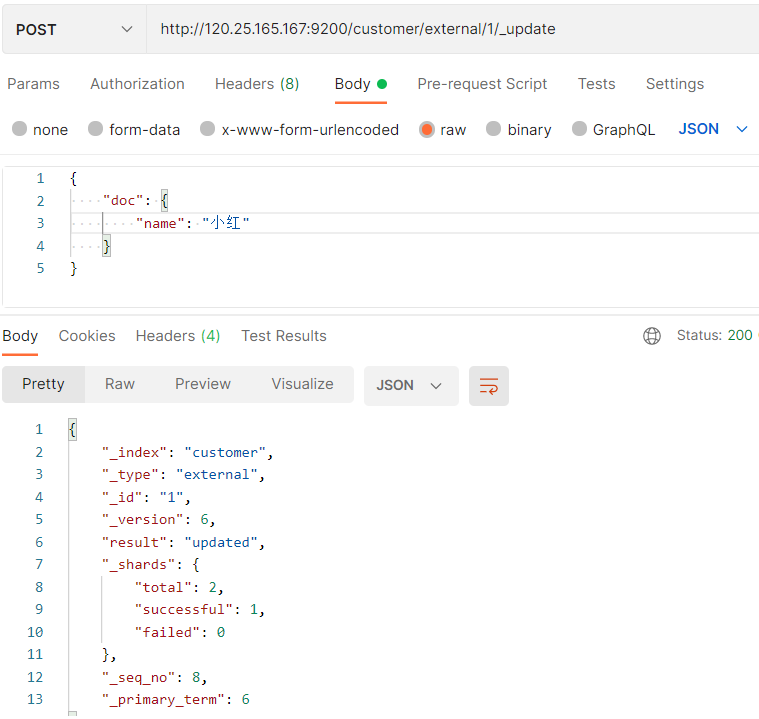
Differences between several updated documents
When indexing documents, i.e. saving documents, there are also two ways to update documents:
- When the PUT request has an id and the id data exists, the document will be updated;
- When the POST request has an id, which is the same as PUT, and the id data already exists, the document will be updated;
The two requests are similar, that is, if the data exists with id, the update operation will be performed.
Analogy:
- The message format of the request body is different_ The data to be modified in the update mode should be wrapped under the doc key
- _ The update method will not update repeatedly, the existing data will not be updated, and the version number will not change. The other two methods will update repeatedly (overwrite the original data), and the version number will change
- These methods can add attributes when updating. PUT requests with id and POST requests with id will directly overwrite the original data and will not add attributes to the original attributes
Delete document & Index
remove document
Interface: DELETE http://120.25.165.167:9200/customer/external/1
Delete index
Interface: DELETE http://120.25.165.167:9200/customer
Batch operation data - bulk
Syntax format:
{action:{metadata}}\n // For example, index saves records and update updates
{request body }\n
{action:{metadata}}\n
{request body }\n
Batch operation specifying index and type
Interface: POST /customer/external/_bulk
Parameters:
{"index":{"_id":"1"}}
{"name":"John Doe"}
{"index":{"_id":"2"}}
{"name":"John Doe"}
Test batches using dev tools in Kibana:
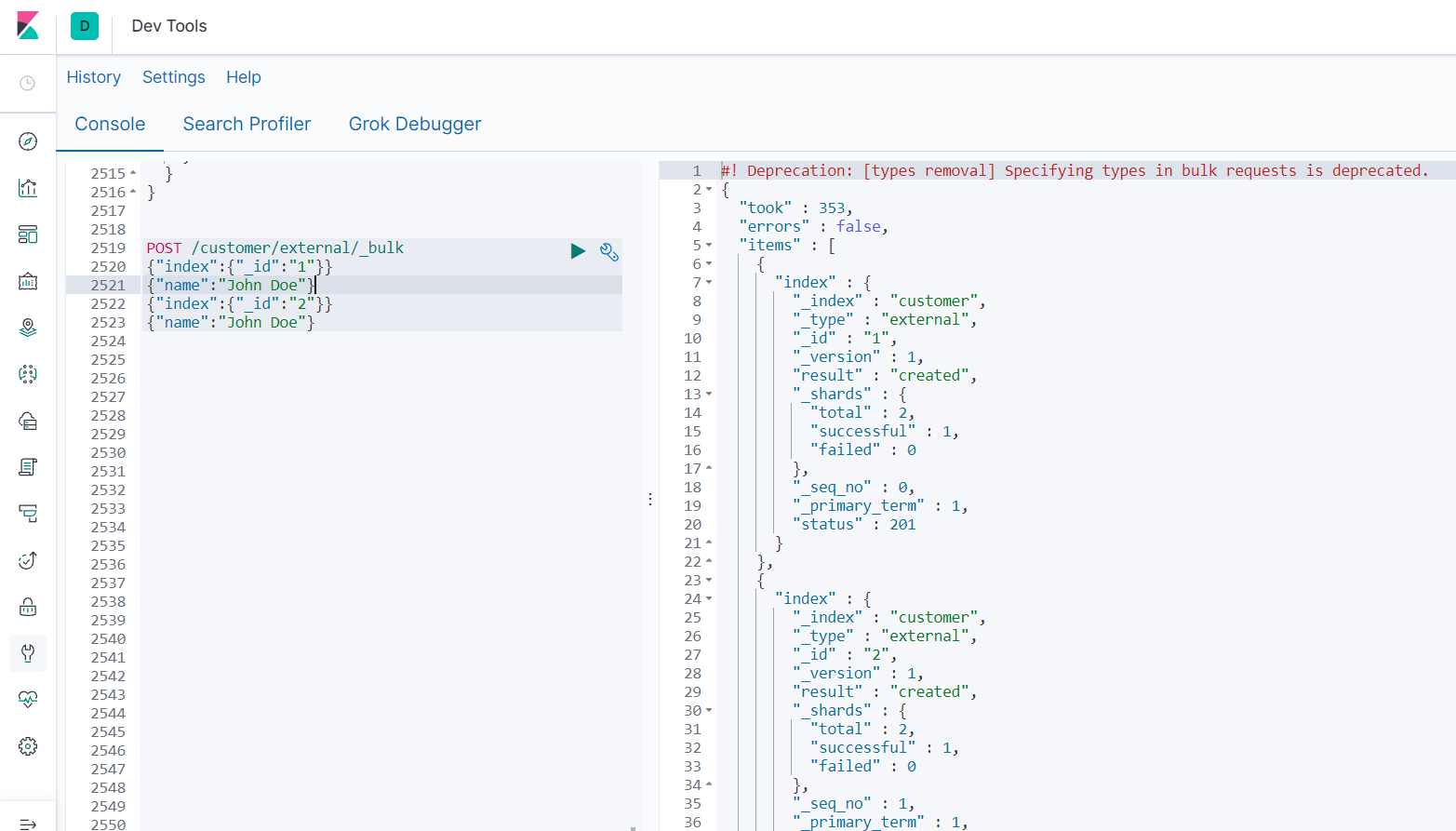
Perform batch operations on all indexes
Interface: Post/_ bulk
Parameters:
{"delete":{"_index":"website","_type":"blog","_id":"123"}}
{"create":{"_index":"website","_type":"blog","_id":"123"}}
{"title":"my first blog post"}
{"index":{"_index":"website","_type":"blog"}}
{"title":"my second blog post"}
{"update":{"_index":"website","_type":"blog","_id":"123"}}
{"doc":{"title":"my updated blog post"}}
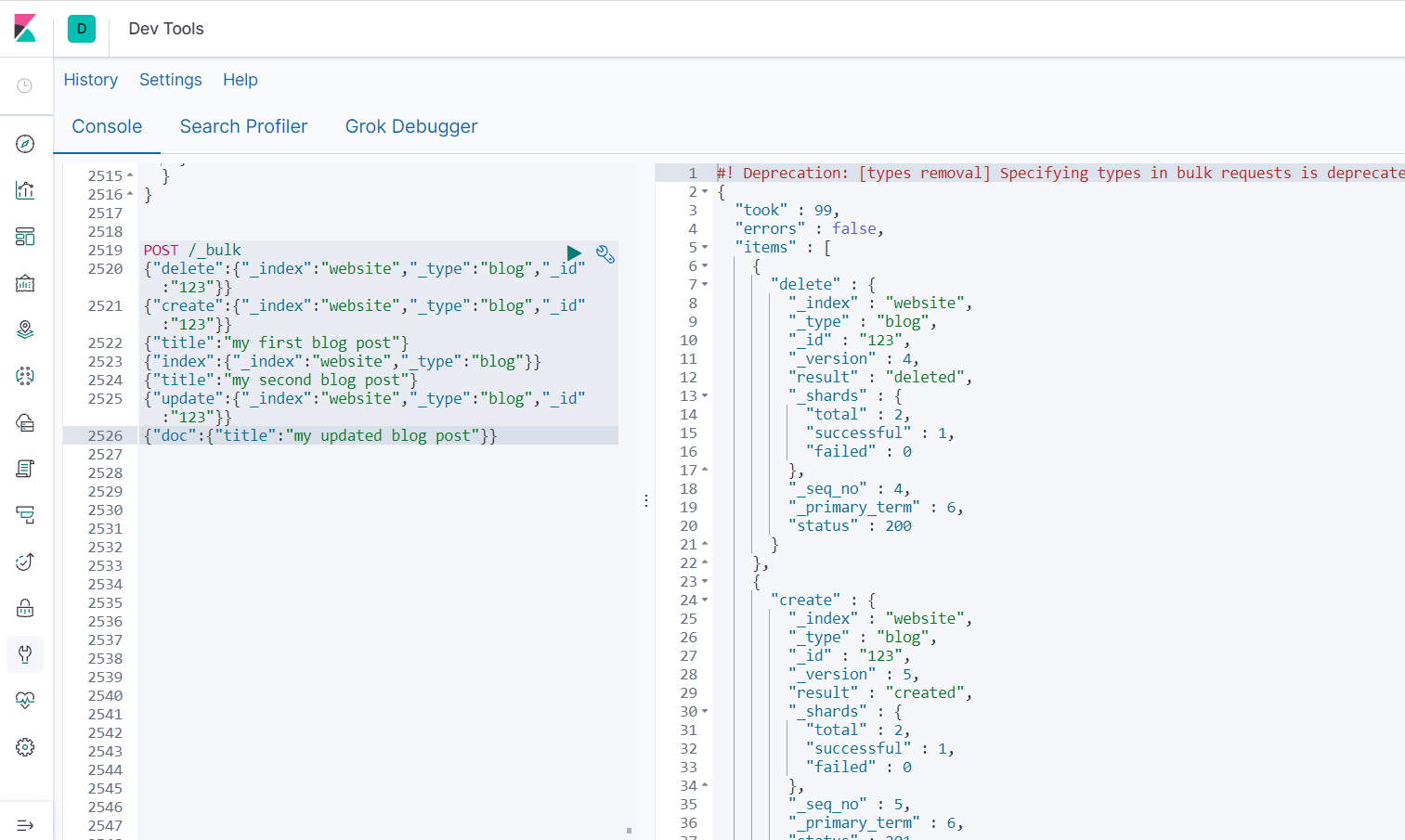
- For batch operations here, when an execution fails, other data can still be executed, that is, they are independent of each other.
- The bulk api executes all actions in this order. If a single action fails for any reason, it will continue to process the remaining actions after it.
- When the bulk api returns, it will provide the status of each action (in the same order as sending), so you can check whether a specified action has failed.
Elasticsearch - Advanced Search
Import sample test data
Prepare a fictional JSON document sample of customer bank account information. Each document has the following schema.
{
"account_number": 1,
"balance": 39225,
"firstname": "Amber",
"lastname": "Duke",
"age": 32,
"gender": "M",
"address": "880 Holmes Lane",
"employer": "Pyrami",
"email": "amberduke@pyrami.com",
"city": "Brogan",
"state": "IL"
}
https://raw.githubusercontent.com/elastic/elasticsearch/master/docs/src/test/resources/accounts.json
Access failed to request: Mirror Address . Import test data.
POST bank/account/_bulk
POST /bank/account/_bulk
{
"index": {
"_id": "1"
}
}
{
"account_number": 1,
"balance": 39225,
"firstname": "Amber",
"lastname": "Duke",
"age": 32,
"gender": "M",
"address": "880 Holmes Lane",
"employer": "Pyrami",
"email": "amberduke@pyrami.com",
"city": "Brogan",
"state": "IL"
}
......Omit several pieces of data
Introduction to retrieval examples
The following requests are operated in kibana dev tools
The simplest search, using match_all, for example, search all, request interface:
GET /bank/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"account_number": "asc"
}
]
}
# Query query criteria
# Sort sort criteria
result
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "0",
"_score" : null,
"_source" : {
"account_number" : 0,
"balance" : 16623,
"firstname" : "Bradshaw",
"lastname" : "Mckenzie",
"age" : 29,
"gender" : "F",
"address" : "244 Columbus Place",
"employer" : "Euron",
"email" : "bradshawmckenzie@euron.com",
"city" : "Hobucken",
"state" : "CO"
},
"sort" : [
0
]
},
...
]
}
}
Response field interpretation
- took – how long it takes Elasticsearch to run the query, in milliseconds
- timed_out – whether the search request timed out
- _ shards – how many tiles were searched, and how many tiles were successful, failed, or skipped.
- max_score – find the relevant file with the highest score
- hits.total.value - how many matching documents were found
- hits.sort - sort position of the document (when not sorted by relevant score)
- hits._score - the relevant score of the document (not applicable when using match_all)
Response result description
Elasticsearch will return 10 pieces of data by default, and will not return all data at once.
Description of request mode
ES supports two basic retrieval methods;
- Send search parameters (uri + search parameters) through REST request uri;
- Send them through REST request body (uri + request body);
That is, in addition to the request interface in the above example, retrieval is performed according to the request body;
It can also be retrieved in the form of GET request parameters:
GET bank/_search?q=*&sort=account_number:asc # q = * query all # sort=account_number:asc by account_number in ascending order
Query DSL
This section refers to official documents: Query DSL
Elasticsearch provides a JSON style DSL that can execute queries. This is called Query DSL, and the query language is very comprehensive. Elasticsearch can use it to realize rich search functions with a simple JSON interface. It will be used for the following search operations:
1. Basic grammar format
Typical structure of a query statement:
QUERY_NAME:{
ARGUMENT:VALUE,
ARGUMENT:VALUE,...
}
For a field, its structure is as follows:
{
QUERY_NAME:{
FIELD_NAME:{
ARGUMENT:VALUE,
ARGUMENT:VALUE,...
}
}
}
Request example:
GET bank/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 5,
"sort": [
{
"account_number": {
"order": "desc"
},
"balance": {
"order": "asc"
}
}
]
}
# match_all query type: represents all query types. In es, you can combine many query types in query to complete complex queries;
# from+size limit to complete paging function; Starting from the first data, how much data is there on each page
# Sort sort, multi field sort, will sort the subsequent fields when the previous fields are equal, otherwise the previous order will prevail;
2. Return some fields
Request example:
GET bank/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 5,
"sort": [
{
"account_number": {
"order": "desc"
}
}
],
"_source": ["balance","firstname"]
}
# _ source specifies the field name contained in the returned result
Examples of results:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "999",
"_score" : null,
"_source" : {
"firstname" : "Dorothy",
"balance" : 6087
},
"sort" : [
999
]
},
...
]
}
}
3. match query
Exact query - basic data type (non text)
GET bank/_search
{
"query": {
"match": {
"account_number": 20
}
}
}
# Find matching account_ term is recommended for non text data with number 20
Fuzzy query - text string
GET bank/_search
{
"query": {
"match": {
"address": "mill lane"
}
}
}
# Find the data with the matching address containing mill or lane
match is full-text search. Word segmentation matching is performed on the search fields, and the score will be given according to the response_ The principle of score sorting is inverted index.
Exact match - text string
GET bank/_search
{
"query": {
"match": {
"address.keyword": "288 Mill Street"
}
}
}
# Find data with address 288 Mill Street.
# The search here is an accurate search. Only when there is an exact match can the existing records be found,
# If you want to blur the query, you should use match_phrase matching
4. match_phrase phrase matching
The value to be matched is retrieved as an entire word (no word segmentation)
GET bank/_search
{
"query": {
"match_phrase": {
"address": "mill lane"
}
}
}
# Here, the data with address matching the phrase mill lane will be retrieved
5. multi_math multi field matching
GET bank/_search
{
"query": {
"multi_match": {
"query": "mill",
"fields": [
"city",
"address"
]
}
}
}
# Retrieving city or address matches the data containing mill, and word segmentation will be performed on the query criteria
6. bool composite query
Compound statements can be combined with any other query statements, including matching statements. This means that between compound statements
It can be nested with each other and can express very complex logic.
- Must: all conditions listed in must must be met
- must_not, must not match must_ All conditions listed in not.
- Should, one of the conditions listed in should can be satisfied (similar to or in MYSQL).
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"gender": "M"
}
},
{
"match": {
"address": "mill"
}
}
]
}
}
}
# Query the data whose gender is M and address contains mill
7. filter result filtering
Not all queries need to generate scores, especially those documents that are only used for filtering filtering. In order not to calculate the score, elastic search automatically checks the scenario and optimizes the execution of the query.
The filter filters the results and does not calculate the correlation score.
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "mill"
}
}
],
"filter": {
"range": {
"balance": {
"gte": "10000",
"lte": "20000"
}
}
}
}
}
}
# First, query all documents with matching address including mil,
# Then filter the query results according to 10000 < = balance < = 20000
In the boolean query, must, should and must_not elements are called query clauses. Whether the document meets the criteria in each "must" or "should" clause determines the "relevance score" of the document. The higher the score, the better the document matches your search criteria. By default, Elasticsearch returns documents sorted by these correlation scores.
Conditions in the 'must_not' clause are treated as' filters'. It affects whether the document is included in the results, but it does not affect the scoring method of the document. You can also explicitly specify any filter to include or exclude documents based on structured data.
8. term exact search
Avoid using term to query text fields
By default, Elasticsearch passes analysis Word segmentation splits the value of a text field into parts, which makes it difficult to accurately match the value of a text field.
If you want to query text field values, use match query instead.
https://www.elastic.co/guide/en/elasticsearch/reference/7.11/query-dsl-term-query.html
Above 3 Match matching query describes the exact query for non text fields. Elasticsearch officially recommends using term to accurately retrieve such non text fields.
GET bank/_search
{
"query": {
"term": {
"age": "28"
}
}
}
# Find data with age 28
9. Aggregation - perform aggregation
https://www.elastic.co/guide/en/elasticsearch/reference/7.11/search-aggregations.html
Aggregate syntax
GET /my-index-000001/_search
{
"aggs":{
"aggs_name":{ # The name of this aggregation is easy to display in the result set
"AGG_TYPE":{ # Type of aggregation (avg,term,terms)
}
}
}
}
Example 1 - search for the age distribution and average age of all people with mill in address
GET bank/_search
{
"query": {
"match": {
"address": "Mill"
}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 10
}
},
"ageAvg": {
"avg": {
"field": "age"
}
},
"balanceAvg": {
"avg": {
"field": "balance"
}
}
},
"size": 0
}
# "ageAgg": { --- The aggregate name is ageagg
# "terms": { --- Aggregate type is term
# "field": "age", --- the aggregation field is age
# "size": 10 --- Get the first ten data after aggregation
# }
# },
# ------------------------
# "ageAvg": { --- The aggregate name is ageavg
# "avg": { --- The aggregation type is AVG for average
# "field": "age" --- The aggregation field is age
# }
# },
# ------------------------
# "balanceAvg": { --- The aggregate name is balanceavg
# "avg": { --- The aggregation type is AVG for average
# "field": "balance" -- the aggregate field is balance
# }
# }
# ------------------------
# "size": 0 --- the hit result is not displayed, and only the aggregate information is viewed
result:
{
"took" : 10,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"ageAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 38,
"doc_count" : 2
},
{
"key" : 28,
"doc_count" : 1
},
{
"key" : 32,
"doc_count" : 1
}
]
},
"ageAvg" : {
"value" : 34.0
},
"balanceAvg" : {
"value" : 25208.0
}
}
}
Example 2 - aggregate by age and find the average salary of these people in these age groups
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"ageAvg": {
"avg": {
"field": "balance"
}
}
}
}
},
"size": 0
}
result:
{
"took" : 12,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"ageAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 31,
"doc_count" : 61,
"ageAvg" : {
"value" : 28312.918032786885
}
},
{
"key" : 39,
"doc_count" : 60,
"ageAvg" : {
"value" : 25269.583333333332
}
},
{
"key" : 26,
"doc_count" : 59,
"ageAvg" : {
"value" : 23194.813559322032
}
},
{
"key" : 32,
"doc_count" : 52,
"ageAvg" : {
"value" : 23951.346153846152
}
},
{
"key" : 35,
"doc_count" : 52,
"ageAvg" : {
"value" : 22136.69230769231
}
},
{
"key" : 36,
"doc_count" : 52,
"ageAvg" : {
"value" : 22174.71153846154
}
},
{
"key" : 22,
"doc_count" : 51,
"ageAvg" : {
"value" : 24731.07843137255
}
},
{
"key" : 28,
"doc_count" : 51,
"ageAvg" : {
"value" : 28273.882352941175
}
},
{
"key" : 33,
"doc_count" : 50,
"ageAvg" : {
"value" : 25093.94
}
},
{
"key" : 34,
"doc_count" : 49,
"ageAvg" : {
"value" : 26809.95918367347
}
},
{
"key" : 30,
"doc_count" : 47,
"ageAvg" : {
"value" : 22841.106382978724
}
},
{
"key" : 21,
"doc_count" : 46,
"ageAvg" : {
"value" : 26981.434782608696
}
},
{
"key" : 40,
"doc_count" : 45,
"ageAvg" : {
"value" : 27183.17777777778
}
},
{
"key" : 20,
"doc_count" : 44,
"ageAvg" : {
"value" : 27741.227272727272
}
},
{
"key" : 23,
"doc_count" : 42,
"ageAvg" : {
"value" : 27314.214285714286
}
},
{
"key" : 24,
"doc_count" : 42,
"ageAvg" : {
"value" : 28519.04761904762
}
},
{
"key" : 25,
"doc_count" : 42,
"ageAvg" : {
"value" : 27445.214285714286
}
},
{
"key" : 37,
"doc_count" : 42,
"ageAvg" : {
"value" : 27022.261904761905
}
},
{
"key" : 27,
"doc_count" : 39,
"ageAvg" : {
"value" : 21471.871794871793
}
},
{
"key" : 38,
"doc_count" : 39,
"ageAvg" : {
"value" : 26187.17948717949
}
},
{
"key" : 29,
"doc_count" : 35,
"ageAvg" : {
"value" : 29483.14285714286
}
}
]
}
}
}
Example 3 - find out all age distributions, and the average salary of M and F in these age groups, as well as the overall average salary of this age group
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"genderAgg": {
"terms": {
"field": "gender.keyword"
},
"aggs": {
"balanceAvg": {
"avg": {
"field": "balance"
}
}
}
},
"ageBalanceAvg": {
"avg": {
"field": "balance"
}
}
}
}
},
"size": 0
}
# "field": "gender.keyword" gender is txt, which cannot be aggregated and must be added keyword exact substitution
result:
{
"took" : 17,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"ageAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 31,
"doc_count" : 61,
"genderAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "M",
"doc_count" : 35,
"balanceAvg" : {
"value" : 29565.628571428573
}
},
{
"key" : "F",
"doc_count" : 26,
"balanceAvg" : {
"value" : 26626.576923076922
}
}
]
},
"ageBalanceAvg" : {
"value" : 28312.918032786885
}
},
{
"key" : 39,
"doc_count" : 60,
"genderAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "F",
"doc_count" : 38,
"balanceAvg" : {
"value" : 26348.684210526317
}
},
{
"key" : "M",
"doc_count" : 22,
"balanceAvg" : {
"value" : 23405.68181818182
}
}
]
},
"ageBalanceAvg" : {
"value" : 25269.583333333332
}
},
...
]
}
}
}
Elasticsearch-Mapping
Mapping - Introduction to mapping official website:
https://www.elastic.co/guide/en/elasticsearch/reference/7.11/mapping.html
1. Introduction to mapping
Mapping is used to define a document and how its contained field s are stored and indexed.
For example, use maping to define:
- Which string attributes should be regarded as full text fields;
- Which attributes contain numbers, dates, or geographic locations;
- Whether all attributes in the document are indexed (all configured);
- Format of date;
- Custom mapping rules to dynamically add attributes;
Viewing mapping information
GET bank/_mapping
{
"bank" : {
"mappings" : {
"properties" : {
"account_number" : {
"type" : "long"
},
"address" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"age" : {
"type" : "long"
},
"balance" : {
"type" : "long"
},
"city" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"email" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"employer" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"firstname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"gender" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"lastname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"state" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
2. New version type removal
ElasticSearch7 - remove the type concept
- Two data representations in relational databases are independent. Even if they have columns with the same name, it will not affect their use, but this is not the case in ES. Elastic search is a search engine developed based on Lucene, and the final processing method of files with the same name under different type s in ES is the same in Lucene.
- Two users under two different types_ Name, under the same index of ES, is actually considered to be the same filed. You must define the same filed mapping in two different types. Otherwise, the same field names in different types will conflict in processing, resulting in the decrease of Lucene processing efficiency.
- Removing type is to improve the efficiency of ES data processing.
- Elasticsearch 7. The type parameter in the X URL is optional. For example, indexing a document no longer requires a document type.
- Elasticsearch 8.x no longer supports the type parameter in URL s.
- Solution: migrate the index from multi type to single type. Each type of document has an independent index. Migrate all the type data under the existing index to the specified location. See data migration for details
3. Attribute type
Reference: Official Attribute type
Mapping operation
References: Creating Mapping operation
1. Create index mapping
Create an index and specify the mapping rules for attributes (equivalent to creating a new table and specifying fields and field types)
PUT /my_index
{
"mappings": {
"properties": {
"age": {
"type": "integer"
},
"email": {
"type": "keyword"
},
"name": {
"type": "text"
}
}
}
}
result:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "my_index"
}
2. Add fields to existing mappings
reference resources: Official documents
PUT /my_index/_mapping
{
"properties": {
"employee-id": {
"type": "keyword",
"index": false
}
}
}
# "Index" here: false, indicating that the newly added field cannot be retrieved. The default is true
# https://www.elastic.co/guide/en/elasticsearch/reference/7.x/mapping-index.html
result:
{
"acknowledged" : true
}
3. View mapping
reference resources: Official documents
GET /my_index/_mapping # View the mapping of a field GET /my_index/_mapping/field/employee-id
result:
{
"my_index" : {
"mappings" : {
"properties" : {
"age" : {
"type" : "integer"
},
"email" : {
"type" : "keyword"
},
"employee-id" : {
"type" : "keyword",
"index" : false
},
"name" : {
"type" : "text"
}
}
}
}
}
# index false indicates that it cannot be found by the index
4. Update mapping
reference resources: Official documents
We cannot update an existing field mapping. Update must create a new index for data migration.
5. Data migration
There are two migration methods: one is to remove type after 7 and 7, and the other is to include type migration.
No type data migration
POST reindex [Fixed writing]
{
"source":{
"index":"twitter"
},
"dest":{
"index":"new_twitters"
}
}
With data migration
POST reindex [Fixed writing]
{
"source":{
"index":"twitter",
"twitter":"twitter"
},
"dest":{
"index":"new_twitters"
}
}
6. Data migration instance
For our test data, it is the index bank containing type.
Now let's create a new index newbank and modify the types of some fields to demonstrate the data migration operation when the mapping needs to be updated.
① View the current field mapping type of index bank
GET /bank/_mapping
# result
{
"bank" : {
"mappings" : {
"properties" : {
"account_number" : {
"type" : "long"
},
"address" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"age" : {
"type" : "long"
},
"balance" : {
"type" : "long"
},
"city" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"email" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"employer" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"firstname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"gender" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"lastname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"state" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
② Create a new index newbank and modify the field type
PUT /newbank
{
"mappings": {
"properties": {
"account_number": {
"type": "long"
},
"address": {
"type": "text"
},
"age": {
"type": "integer"
},
"balance": {
"type": "long"
},
"city": {
"type": "keyword"
},
"email": {
"type": "keyword"
},
"employer": {
"type": "keyword"
},
"firstname": {
"type": "text"
},
"gender": {
"type": "keyword"
},
"lastname": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"state": {
"type": "keyword"
}
}
}
}
③ Data migration
POST _reindex
{
"source": {
"index": "bank",
"type": "account"
},
"dest": {
"index": "newbank"
}
}
result:
#! Deprecation: [types removal] Specifying types in reindex requests is deprecated.
{
"took" : 269,
"timed_out" : false,
"total" : 1000,
"updated" : 0,
"created" : 1000,
"deleted" : 0,
"batches" : 1,
"version_conflicts" : 0,
"noops" : 0,
"retries" : {
"bulk" : 0,
"search" : 0
},
"throttled_millis" : 0,
"requests_per_second" : -1.0,
"throttled_until_millis" : 0,
"failures" : [ ]
}
④ View migrated data
GET /newbank/_search
# Results: after migration, the type was unified as_ doc remove type
{
"took" : 367,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "newbank",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"account_number" : 1,
"balance" : 39225,
"firstname" : "Amber",
"lastname" : "Duke",
"age" : 32,
"gender" : "M",
"address" : "880 Holmes Lane",
"employer" : "Pyrami",
"email" : "amberduke@pyrami.com",
"city" : "Brogan",
"state" : "IL"
}
},
...