In the previous chapter, we built the ES cluster. Interested friends can refer to it Introduction to the core concept of elasticSearch (XIII): docker building ES cluster
Here we introduce the partition management of ES cluster index
ES cluster index fragmentation management
introduce
- Shard: because ES is a distributed search engine, the index is usually divided into different parts, and the data distributed in different nodes is shard. ES automatically manages and organizes shards, and rebalances the shard data when necessary, so users basically don't have to worry about the processing details of Shards.
- replica: ES creates a primary partition for an index by default, and creates a secondary partition for each index, that is, each index is cost by a primary partition, and each primary partition has a corresponding copy.
- ES7. After X, if the index partition is not specified, a primary partition and a secondary partition will be created by default, while 7 Comparison before version x, such as 6 X version, 5 main partitions by default
Let's take a look at how to use slicing?
Create index (no number of slices specified)
curl -X PUT "172.25.45.150:9200/nba" -H 'Content-Type:aplication/json' -d '
{
"mappings": {
"properties": {
"birthDay": {
"type": "date"
},
"birthDayStr": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"code": {
"type": "text"
},
"country": {
"type": "text"
},
"countryEn": {
"type": "text"
},
"displayAffiliation": {
"type": "text"
},
"displayName": {
"type": "text"
},
"displayNameEn": {
"type": "text"
},
"draft": {
"type": "long"
},
"heightValue": {
"type": "float"
},
"jerseyNo": {
"type": "text"
},
"playYear": {
"type": "long"
},
"playerId": {
"type": "keyword"
},
"position": {
"type": "text"
},
"schoolType": {
"type": "text"
},
"teamCity": {
"type": "text"
},
"teamCityEn": {
"type": "text"
},
"teamConference": {
"type": "keyword"
},
"teamConferenceEn": {
"type": "keyword"
},
"teamName": {
"type": "keyword"
},
"teamNameEn": {
"type": "keyword"
},
"weight": {
"type": "text"
}
}
}
}
'
After creation, we get the index to see the number of slices
curl -X GET "172.25.45.150:9200/nba"
The returned results are as follows:
"settings": {
"index": {
"creation_date": "1646360464892",
"number_of_shards": "1",
"number_of_replicas": "1",
"uuid": "oUWzENVEQVW_hXZlCdfQhg",
"version": {
"created": "7040299"
},
"provided_name": "nba"
}
}
You can see number_ of_ Shards and number_ of_ The number of shards is 1.
Delete the above index. Let's see how to get and create the specified number of slices
curl -X DELETE "172.25.45.150:9200/nba"
Create index (specify number of tiles)
- settings
"settings":{
"number_of_shards":3,
"number_of_replicas":1
},
- Create index
curl -X PUT "172.25.45.150:9200/nba" -H 'Content-Type:aplication/json' -d '
{
"settings":{
"number_of_shards":3,
"number_of_replicas":1
},
"mappings": {
"properties": {
"birthDay": {
"type": "date"
},
"birthDayStr": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"code": {
"type": "text"
},
"country": {
"type": "text"
},
"countryEn": {
"type": "text"
},
"displayAffiliation": {
"type": "text"
},
"displayName": {
"type": "text"
},
"displayNameEn": {
"type": "text"
},
"draft": {
"type": "long"
},
"heightValue": {
"type": "float"
},
"jerseyNo": {
"type": "text"
},
"playYear": {
"type": "long"
},
"playerId": {
"type": "keyword"
},
"position": {
"type": "text"
},
"schoolType": {
"type": "text"
},
"teamCity": {
"type": "text"
},
"teamCityEn": {
"type": "text"
},
"teamConference": {
"type": "keyword"
},
"teamConferenceEn": {
"type": "keyword"
},
"teamName": {
"type": "keyword"
},
"teamNameEn": {
"type": "keyword"
},
"weight": {
"type": "text"
}
}
}
}
'
Let's continue to look at the fragmentation of the index
curl -X GET "172.25.45.150:9200/nba"
"settings": {
"index": {
"creation_date": "1646361232608",
"number_of_shards": "3",
"number_of_replicas": "1",
"uuid": "m_z801WySBCVX-ujrGSv8g",
"version": {
"created": "7040299"
},
"provided_name": "nba"
}
}
You can see that the number of index fragments we have created has been set for us
Index partition allocation
- The ES automatically manages which node the partition is allocated to. If a node hangs, the allocation will be reassigned to other nodes.
- In a single machine, the node has no secondary partition, because there is only one node, so it is unnecessary to generate partition. If a node hangs, the secondary partition will also hang up. It is a single fault and has no significance.
- In a cluster, the main partition and sub partition of the same partition will not be on the same node, because the main partition and sub partition are on the same node. When the node is hung, the sub partition and the main partition are hung. Don't put all your eggs in the same basket.
- You can manually move a partition, such as moving a partition from node 1 to node 2
- The number of primary partitions specified during index creation cannot be modified later, so the number of primary partitions should be determined according to the project. If you really want to increase the primary partition, you can only rebuild the index. The number of sub segments can be modified later.
According to the partition we created above, there are three main partitions, and then each main partition has one sub partition, so we have six partitions.
If kibana is installed, you can check the partition distribution through Monitoring.
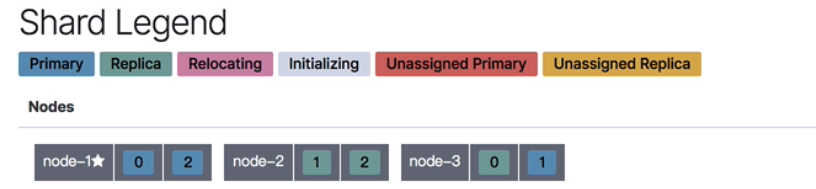
- Primary: primary partition
- Replica: secondary Shard
- Relocating: allocating
- Initializing: initializing
- Unassigned Primary: Unassigned Primary partition
- Unassigned Replica: Unassigned Replica
Manually move the slice
Move slice 2 from node 1 to node 3
curl -X PUT "172.25.45.150:9200/_cluster/reroute" -H 'Content-Type:aplication/json' -d '
{
"commands": [
{
"move": {
"index": "nba",
"shard": 2,
"from_node": "node-1",
"to_node": "node-3"
}
}
]
}
'
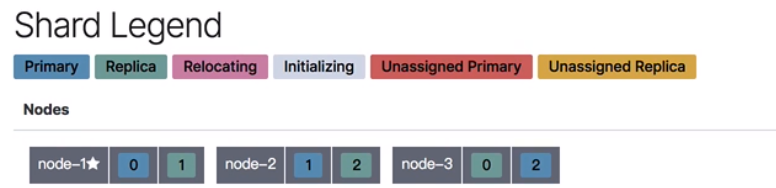
Modify the number of sub segments
As mentioned above, the number of primary partitions cannot be modified after the index is created. If you want to modify it, you have to recreate the index, then we can modify the number of secondary partitions.
curl -X PUT "http://172.25.45.150:9200/nba/_settings" -H 'Content-Type:application/json' -d '
{
"number_of_replicas":2
}
'
Query all
curl -X GET "http://172.25.45.150:9200/nba"
"settings": {
"index": {
"creation_date": "1646361232608",
"number_of_shards": "3",
"number_of_replicas": "2",
"uuid": "m_z801WySBCVX-ujrGSv8g",
"version": {
"created": "7040299"
},
"provided_name": "nba"
}
}
We can see that the number of sub segments has become 2. Now there are 2 sub segments in each main segment, so now we have 9 segments. Let's take a look at the distribution of segments
