the decoding and encoding of ffmpeg follow its basic execution flow.
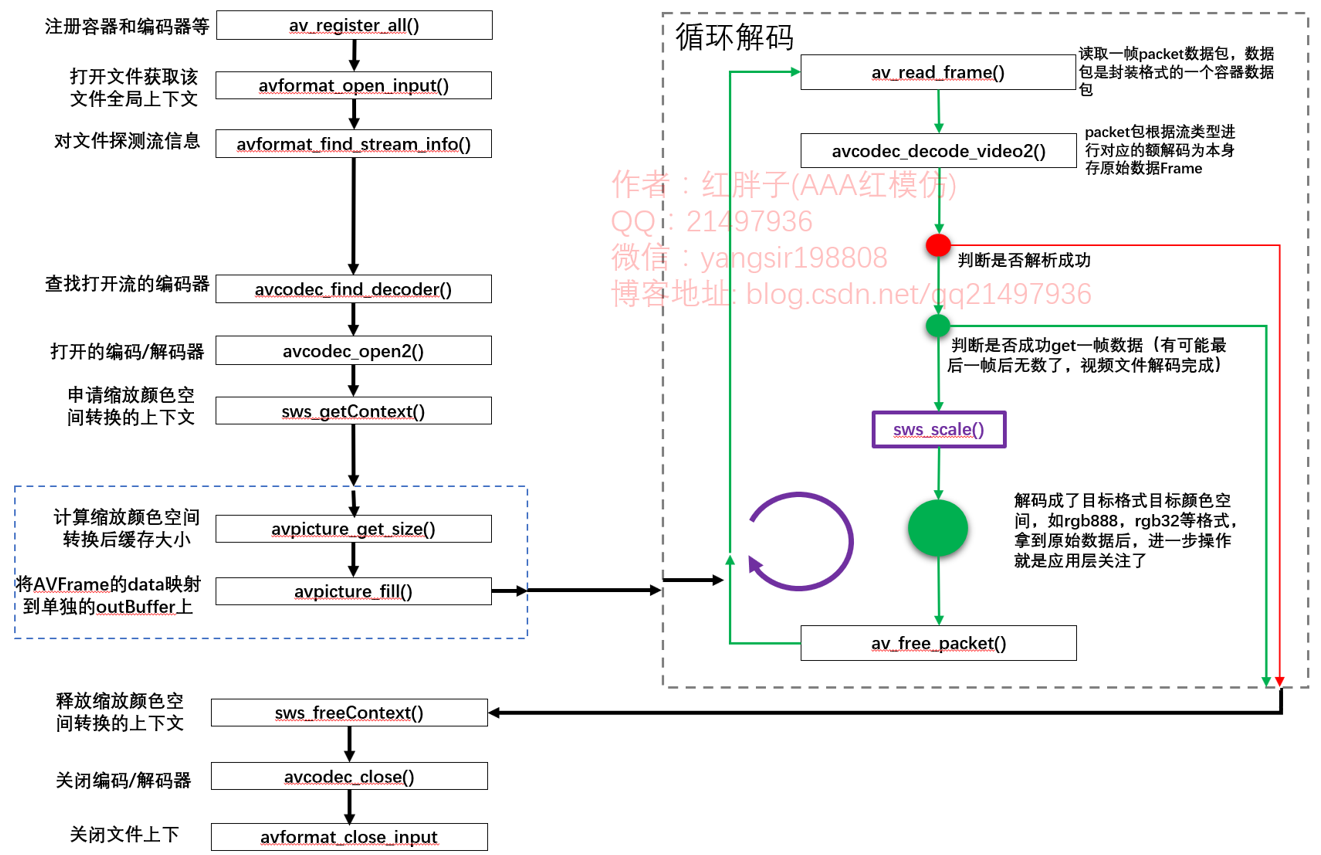
the basic decoding process of the new api is as follows:
Step 1: Register: (obsolete)
all libraries corresponding to ffmpeg need to be registered. You can register children or all.
Step 2: open the file: avformat_open_input
open the file and obtain the corresponding ffmpeg global context according to the file name information.
Step 3: probe stream information: avformat_find_stream_info
be sure to detect the stream information and get the encoding format of the stream code. If you do not detect the stream information, the encoding type obtained by the stream encoder may be empty, and the original format cannot be known during subsequent data conversion, resulting in errors.
Step 4: find the corresponding decoder avcodec_find_decoder
find the decoder according to the format of the stream. Soft decoding or hard decoding is determined here. However, pay special attention to whether it supports hardware. You need to find the corresponding identification of the local hardware decoder and query whether it supports it. The common operation is to enumerate all decoders that support file suffix decoding and find them. If they find them, they can be hard decoded (there is no too much discussion here, and there will be articles on hard decoding for further research).
(Note: look for the decoder when decoding and the encoder when encoding. The two functions are different. Don't make a mistake, otherwise it can be opened later, but the data is wrong)
Step 5: open the decoder avcodec_open2
open the obtained decoder.
Step 6: apply for scaling data format conversion structure sws_getContext
pay special attention here. Basically, the decoded data are in yuv series format, but the data we display is the data of rgb and other related color spaces. Therefore, the conversion structure here is the description from before to after conversion, which provides the basis for transcoding for subsequent conversion functions. It is a very key and very common structure.
Step 7: apply for cache {avpicture_get_size+avpicture_fill
apply for a buffer area outBuffer and fill it into the data of our target frame data, such as rgb data. The data of QAVFrame is stored in the specified format and stored with rules, while fill to outBuffer (the buffer area of one frame of the target format applied by ourselves) is the storage order of the data format we need.
for example, the decoded and converted data is rgb888. In fact, it is wrong to directly use data data, but it is right to use outBuffer, so it should be that the fill function of ffmpeg has made some conversion here.
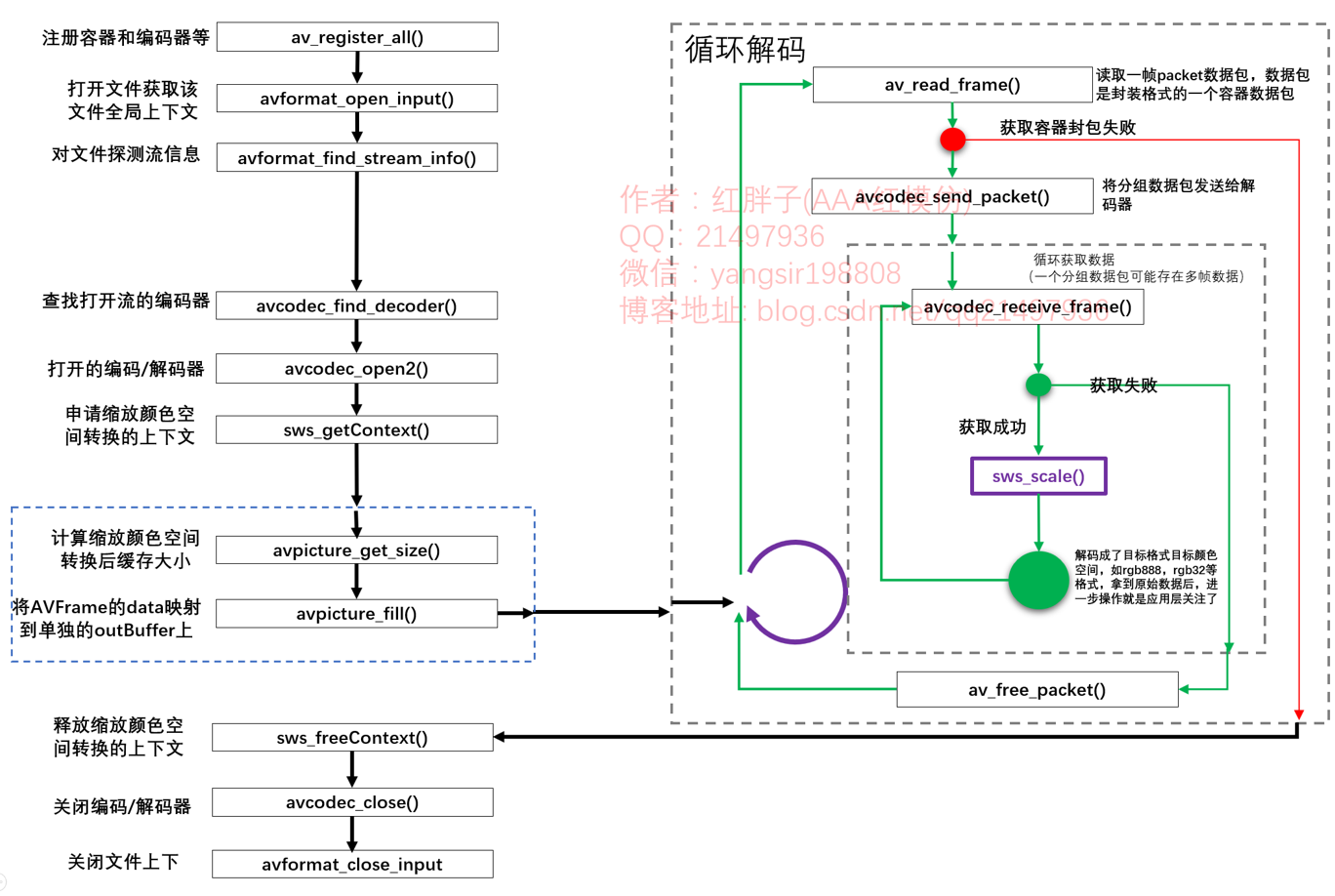
Enter loop decoding:
Step 8: send the packet to the decoder (from one step here to step 8 and step 9) avcodec_send_packet
take a packet encapsulated, judge the type of packet data and send it to the decoder for decoding.
Step 9: obtain the decoded data avcodec from the decoder cache_ receive_ frame
there may be multiple groups of data in a package. The old api obtains the first one. After the new api is separated, it can be obtained circularly until it cannot be obtained. Jump to "step 12".
Step 11: handle it by yourself. This example is sws_scale image scaling and format conversion
get the original data and process it by yourself.
keep cycling until the pakcet function is obtained successfully, but cannot get a frame of data, it means that the file decoding has been completed.
the frame rate needs to control the cycle by itself. Here, it is only a cycle to take, and delay can be added.
Step 12: release QAVPacket av_free_packet
we need to list it separately here because in fact, many online and developer Codes:
AV is performed before entering cyclic decoding_ new_ Packet, not AV in loop_ free_ Packet, causing memory overflow;
AV is performed before entering cyclic decoding_ new_ Packet, AV in the loop_ free_ Pakcet, then a new corresponds to countless free times, which does not comply with the one-to-one correspondence specification on the encoder.
viewing the source code, you can actually find av_read_frame, AV is automatically performed_ new_ Packet (), then in fact, for packet, you only need to perform AV once_ packet_ Alloc(), AV after decoding_ free_ packet.
after execution, return to "step 8: get a packet", and one cycle ends.
Step 13: release the conversion structure sws_freeContext
after all decoding is completed, install the application sequence and release the corresponding resources.
Step 14: turn off decoding / coder avcodec_close
turn off the decoding / encoder that was turned on before.
Step 15: close context avformat_close_input
after closing the file context, release the previously applied variables in order.
example:
void FFmpegManager::testDecodeNewApi()
{
QString fileName = "test/1.mp4";
// Pre definition and allocation of ffmpeg related variables
AVFormatContext *pAVFormatContext = 0; // The global context of ffmpeg, which is required for all ffmpeg operations
// AVInputFormat *pAVInputFormat = 0; // Input format structure of ffmpeg
AVDictionary *pAVDictionary = 0; // ffmpeg dictionary option, various parameters to format codec configuration parameters
AVCodecContext *pAVCodecContext = 0; // ffmpeg encoding context
AVCodec *pAVCodec = 0; // ffmpeg encoder
AVPacket *pAVPacket = 0; // ffmpag single frame packet
AVFrame *pAVFrame = 0; // ffmpeg single frame cache
AVFrame *pAVFrameRGB32 = 0; // The cache after ffmpeg single frame cache is converted into color space
struct SwsContext *pSwsContext = 0; // Format conversion of ffmpag encoded data
pAVFormatContext = avformat_alloc_context(); // distribution
pAVPacket = av_packet_alloc(); // distribution
pAVFrame = av_frame_alloc(); // distribution
pAVFrameRGB32 = av_frame_alloc(); // distribution
......
// Step 2: open the file (0 if ffmpeg is successful)
ret = avformat_open_input(&pAVFormatContext, fileName.toUtf8().data(), 0, 0);
// Step 3: detect streaming media information
// Assertion desc failed at libswscale/swscale_internal.h:668
// Pit entry: because of pix_fmt is null. Further detection of encoder context is required
ret = avformat_find_stream_info(pAVFormatContext, 0);
// Step 3: extract stream information and video information
for(int index = 0; index < pAVFormatContext->nb_streams; index++)
{
pAVCodecContext = pAVFormatContext->streams[index]->codec;
switch (pAVCodecContext->codec_type)
{
case AVMEDIA_TYPE_UNKNOWN:
LOG << "Stream sequence number:" << index << "Type is:" << "AVMEDIA_TYPE_UNKNOWN";
break;
case AVMEDIA_TYPE_VIDEO:
LOG << "Stream sequence number:" << index << "Type is:" << "AVMEDIA_TYPE_VIDEO";
videoIndex = index;
break;
case AVMEDIA_TYPE_AUDIO:
LOG << "Stream sequence number:" << index << "Type is:" << "AVMEDIA_TYPE_AUDIO";
break;
case AVMEDIA_TYPE_DATA:
LOG << "Stream sequence number:" << index << "Type is:" << "AVMEDIA_TYPE_DATA";
break;
.......
default:
break;
}
}
// Step 4: find a decoder for the found video stream
pAVCodec = avcodec_find_decoder(pAVCodecContext->codec_id);
// Step 5: open the decoder
ret = avcodec_open2(pAVCodecContext, pAVCodec, NULL);
// Step 6: scale and convert the original data format to the specified format height width size
// Assertion desc failed at libswscale/swscale_internal.h:668
// Pit entry: because of pix_fmt is null. Further detection of encoder context is required
pSwsContext = sws_getContext(pAVCodecContext->width,
pAVCodecContext->height,
pAVCodecContext->pix_fmt,
pAVCodecContext->width,
pAVCodecContext->height,
AV_PIX_FMT_RGBA,
SWS_FAST_BILINEAR,
0,
0,
0);
numBytes = avpicture_get_size(AV_PIX_FMT_RGBA,
pAVCodecContext->width,
pAVCodecContext->height);
outBuffer = (uchar *)av_malloc(numBytes);
// The data pointer of parvframe32 points to outBuffer
avpicture_fill((AVPicture *)pAVFrameRGB32,
outBuffer,
AV_PIX_FMT_RGBA,
pAVCodecContext->width,
pAVCodecContext->height);
// No assignment required here
// av_read_frame, he will assign, av_new_packet is superfluous. It just explains the problem of one new and many free
// av_new_packet(pAVPacket, pAVCodecContext->width * pAVCodecContext->height);
// Step 7: read the packet of one frame of data
while(av_read_frame(pAVFormatContext, pAVPacket) >= 0)
{
if(pAVPacket->stream_index == videoIndex)
{
// Step 8: send data to encoder
ret = avcodec_send_packet(pAVCodecContext, pAVPacket);
// Step 9: the cyclic encoder obtains the decoded data
while(!avcodec_receive_frame(pAVCodecContext, pAVFrame))
{
sws_scale(pSwsContext,
(const uint8_t * const *)pAVFrame->data,
pAVFrame->linesize,
0,
pAVCodecContext->height,
pAVFrameRGB32->data,
pAVFrameRGB32->linesize);
QImage imageTemp((uchar *)outBuffer,
pAVCodecContext->width,
pAVCodecContext->height,
QImage::Format_RGBA8888);
QImage image = imageTemp.copy();
LOG << image.save(QString("%1.jpg").arg(frameIndex++));
}
av_free_packet(pAVPacket);
QThread::msleep(1);
}
END:
LOG << "Release recycled resources";
......General idea of code:
1) sws_getContext sets the color conversion mode
2) avpicture_fill , bind the memory pavframergb32 and outbuffer
3) av_read_frame,avcodec_send_packet,avcodec_receive_frame reads and decodes frames
4) sws_scale performs color conversion Put the newly output frame into parvframergb32 (parvframe - > parvframergb32)
5) Data parvframergb32 = > outbuffer = > qimage imagetemp = > qimage image
sws_getContext function parsing:
sws_getContext(w, h, YV12, w, h, NV12, 0, NULL, NULL, NULL); / / yv12 - > nv12 color space conversion
sws_getContext(w, h, YV12, w/2, h/2, YV12, 0, NULL, NULL, NULL); / / yv12 image reduced to 1 / 4 of the original image
sws_getContext(w, h, YV12, 2w, 2h, YN12, 0, NULL, NULL, NULL); / / enlarge the yv12 image to 4 times the original image and convert it to NV12 structure
This example sws_getContext will set parvcodeccontext - > pix_ FMT to AV_PIX_FMT_RGBA.
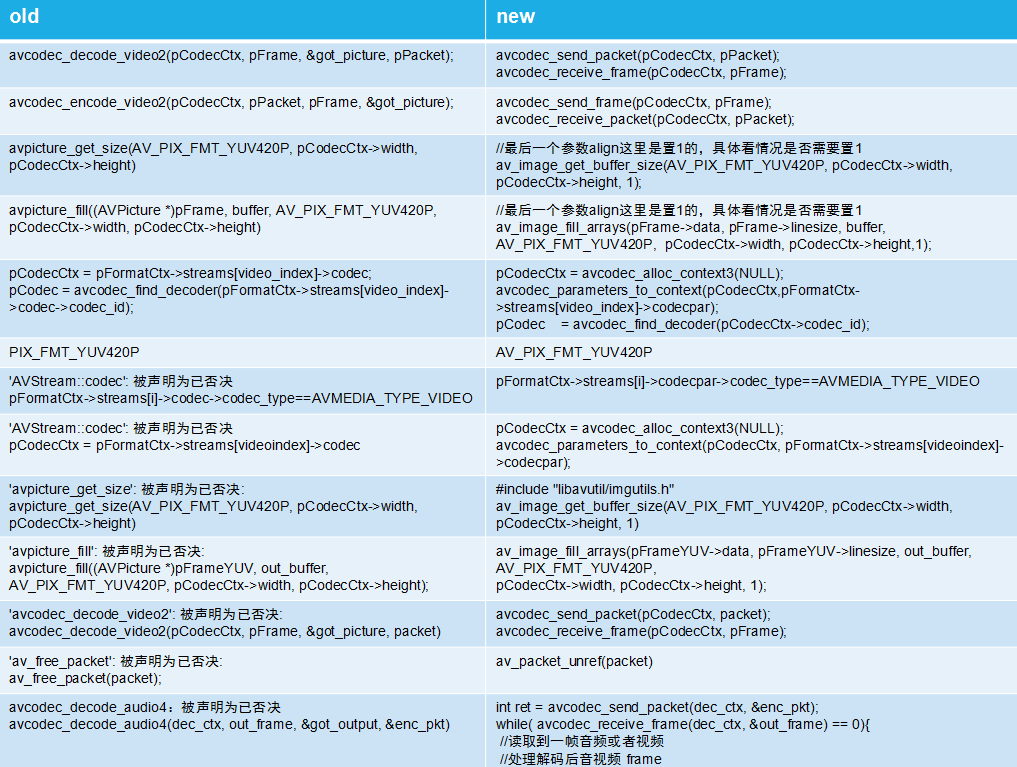
avpicture_ fill attribute_ Changed deprecated to av_image_fill_arrays
pAVFrameRGB32 and out_buffer is a section of memory that has been applied for, but pAVFrameRGB32 only applies for a section of structure memory, and the value in the structure is empty
We need to use avpicture_fill() function to make parvframergb32 and out_buffer is associated, and out is used in pAVFrameRGB32_ The memory space pointed to by buffer
sws_scale function
int sws_scale(struct SwsContext *c, const uint8_t *const srcSlice[],
const int srcStride[], int srcSliceY, int srcSliceH,
uint8_t *const dst[], const int dstStride[]);The function parameters are described in detail below:
1. Parameter SwsContext *c, context of conversion format. SWS_ The result returned by the getcontext function.
2. Parameter const uint8_t *const srcSlice [], input the data pointer of each color channel of the image. In fact, it is the data [] array in the decoded AVFrame Because the storage formats of different pixels are different, the srcSlice [] dimension may also be different
Take YUV420P as an example. It is in planar format. Its memory layout is as follows:
YYYYYYYY UUUU VVVV
When FFmpeg decoding is used and stored in the data [] array of AVFrame:
data[0] - Y component, Y1, Y2, Y3, Y4, Y5, Y6, Y7, Y8
data[1] - U component, U1, U2, U3, U4
data[2] - V component, V1, V2, V3, V4
linesize [] the data width of the corresponding channel is saved in the array,
linesize[0] - width of - Y component
linesize[1] - width of - U component
linesize[2] - width of - V component
RGB24, which is in packed format, has only one dimension in the data [] array. Its storage method is as follows:
data[0]: R1, G1, B1, R2, G2, B2, R3, G3, B3, R4, G4, B4......
Others: FFMpeg 4.0 new api
" warning: 'AVStream::codec' is deprecated (declared at /usr/local/ffmpeg/include/libavformat/avformat.h:880) [-Wdeprecated-declarations]
1.1.1 av_register_all() -- deprecated
• the function to register the multiplexer is av_register_output_format().
• the function to register the demultiplexer is av_register_input_format().
• the function to register the protocol processor is ffurl_register_protocol().
Note: ffmpeg4 0 and above, these functions have been discarded.
The above function is no longer needed, but the specific function is used directly
For example, the following is the api decoding process of the old version:
Compared with figure 1: avcodec_ decode_ Change video2 to avcodec_send_packet and avcodec_receive_frame