Abstract: This paper introduces the prototype construction of Flink + Hudi Lake Warehouse Integration Scheme in detail. The main contents are as follows:
-
Hudi
-
The new architecture is integrated with the lake warehouse
-
Best practices
-
Flink on Hudi
-
Flink CDC 2.0 on Hudi
Tips: FFA 2021 is heavily opened. Click "read the original text" to sign up ~

GitHub address
Welcome to Flink Like star~

1, Hudi
1. Introduction
Apache Hudi (pronounced "Hoodie") provides the following stream primitives on the DFS dataset:
-
Insert updates (how do I change the dataset?)
-
Incremental pull (how to get changed data?)
Hudi maintains a timeline of all operations performed on the dataset to provide an instant view of the dataset. Hudi organizes the dataset into a directory structure under a basic path very similar to the Hive table. The dataset is divided into multiple partitions, and the folder contains the files of the partition. Each partition is uniquely identified by the partition path relative to the basic path.
Partition records are assigned to multiple files. Each file has a unique file ID and the commit that generated the file. If there are updates, multiple files share the same file ID, but the commit when writing is different.
Storage type – Storage method of processing data
-
Copy on write
-
Pure determinant
-
Create a new version of the file
-
Read time merge
-
Near real time
view – Read mode of processing data
Read optimization view - The input format selects only compressed columnar files
-
parquet file query performance
-
The delay time of 500GB is about 30 minutes
-
Import an existing Hive table
Near real time view
-
Mix and format data
-
Delay of about 1-5 minutes
-
Provide near real time table
Incremental view
-
Changes to data sets
-
Enable incremental pull
The Hudi storage tier consists of three different parts:
-
metadata – It maintains the metadata of all operations performed on the dataset in the form of a timeline, which allows the immediate view of the dataset to be stored in the metadata directory of the basic path. The types of operations on the timeline include:
-
-
Commit: a commit represents the process of writing a batch of record atoms into the dataset. Monotonically increasing timestamp, commit represents the beginning of the write operation.
-
Clean, which cleans up older versions of files in the dataset that are no longer used in queries.
-
Compression: the action of converting a line file into a column file.
-
-
Indexes - Quickly map incoming record keys to files (if record keys already exist). The index implementation is pluggable, Bloom filter - since it does not rely on any external system, it is the default configuration, and the index and data are always consistent. Apache HBase - is more efficient for a small number of keys. It may save a few seconds during index marking.
-
data - Hudi stores data in two different storage formats. The format actually used is pluggable, but requires the following characteristics - read optimized column storage format (ROFormat), with the default value of Apache Parquet; write optimized row based storage format (WOFormat), with the default value of Apache Avro.
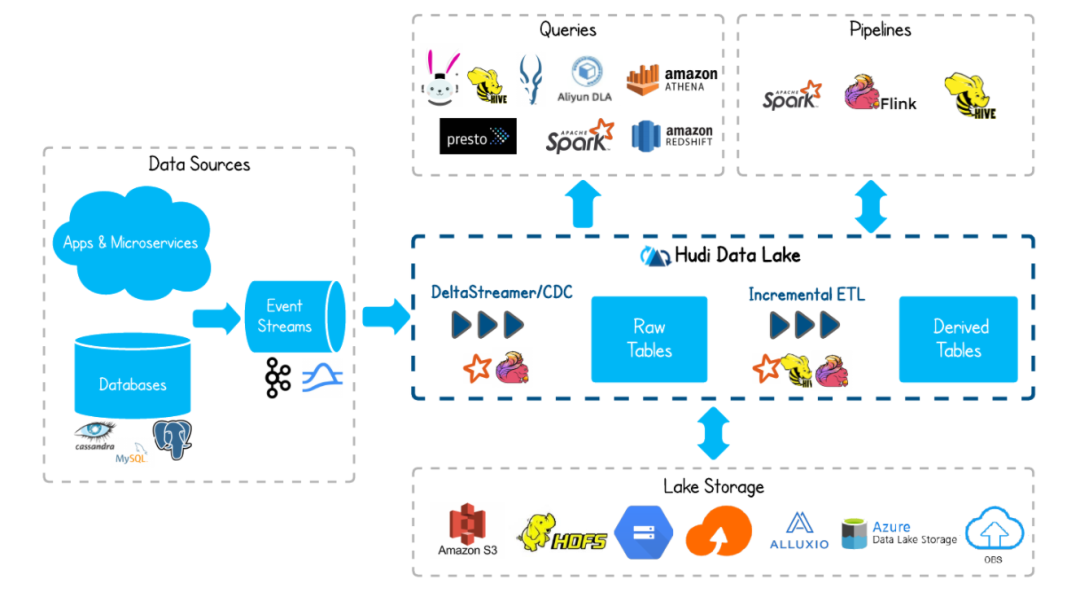
2. Why is Hudi important for large-scale and near real-time applications?
Hudi addresses the following limitations:
-
Scalability limitations of HDFS;
-
Need to render data faster in Hadoop;
-
There is no direct support for updating and deleting existing data;
-
Fast ETL and modeling;
-
To retrieve all updated records, whether they are new records added to the latest date partition or updates to old data, Hudi allows users to use the last checkpoint timestamp. This process does not need to perform a query that scans the entire source table.
3. Hudi's advantages
-
Scalability limitations in HDFS;
-
Fast presentation of data in Hadoop;
-
Support the update and deletion of existing data;
-
Fast ETL and modeling.
The above content is mainly quoted from Apache Hudi
2, The new architecture is integrated with the lake warehouse
Through the integration of Lake warehouse and flow batch, we can achieve the same source of data, the same computing engine, the same storage and the same computing caliber in the quasi real-time scenario. The timeliness of data can reach the minute level, which can well meet the needs of business quasi real-time data warehouse. The following is the architecture diagram:
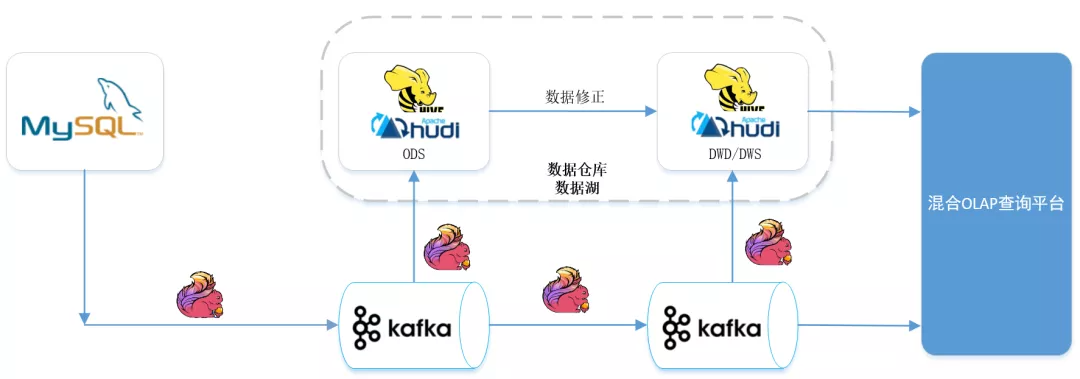
MySQL data enters Kafka through Flink CDC. The reason why the data enters Kafka first rather than directly into Hudi is to reuse the data from MySQL for multiple real-time tasks and avoid the impact on the performance of MySQL database caused by multiple tasks connecting MySQL tables and Binlog through Flink CDC.
In addition to the ODS layer of the offline data warehouse, the data entering Kafka through CDC will be sent from ODS - > DWD - > DWS - > OLAP database according to the link of the real-time data warehouse, and finally used for data services such as reports. The result data of each layer of the real-time data warehouse will be sent to the offline data warehouse in quasi real time. In this way, one-time program development and indicator caliber can be achieved Unified, unified data.
From the architecture diagram, we can see that there is a step of data correction (rerunning historical data). The reason for this step is that there may be rerunning historical data due to caliber adjustment or error in the calculation result of the real-time task of the previous day.
The data stored in Kafka has an expiration time and will not store historical data for a long time. The historical data that runs for a long time cannot obtain historical source data from Kafka. Moreover, if a large amount of historical data is pushed to Kafka again and the historical data is corrected through the real-time calculation link, it may affect the real-time operation of the day. Therefore, for the rerun historical data, the data will be used Fix this step to handle.
Generally speaking, this architecture is a hybrid architecture of Lambda and kappa. Each data link of the stream batch integrated data warehouse has a data quality verification process. The next day, the data of the previous day is reconciled. If the data calculated in real time the previous day is normal, there is no need to correct the data. Kappa architecture is enough.
This section is quoted from: 37 mobile Tour Based on Flink CDC + Hudi Lake Warehouse Integration Scheme
3, Best practices
1. Version matching
The problem of version selection may become the first stumbling block for everyone. The following is the version adaptation recommended by hudi Chinese community:
| Flink | Hudi |
|---|---|
| 1.12.2 | 0.9.0 |
| 1.13.1 | 0.10.0 |
It is recommended to use Hudi master + Flink 1.13, which can better adapt to CDC connector.
2. Download Hudi
https://mvnrepository.com/artifact/org.apache.Hudi/Hudi-Flink-bundle
At present, the latest version of maven central warehouse is 0.9.0. If you need to download version 0.10.0, you can join the community group, download it in the shared file, or download the source code and compile it yourself.
3. Implementation
If you put Hudi Flink bundle_2.11-0.10.0.jar under Flink/lib, you only need to execute the following steps, otherwise various exceptions will occur that cannot find the class
bin/SQL-client.sh embedded
4, Flink on Hudi
Newly build maven project and modify pom as follows:
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId> <artifactId>Flink_Hudi_test</artifactId> <version>1.0-SNAPSHOT</version>
<properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <Flink.version>1.13.1</Flink.version> <Hudi.version>0.10.0</Hudi.version> <hadoop.version>2.10.1</hadoop.version> </properties>
<dependencies>
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>${hadoop.version}</version> </dependency>
<dependency> <groupId>org.apache.Flink</groupId> <artifactId>Flink-core</artifactId> <version>${Flink.version}</version> </dependency> <dependency> <groupId>org.apache.Flink</groupId> <artifactId>Flink-streaming-java_2.11</artifactId> <version>${Flink.version}</version> </dependency>
<dependency> <groupId>org.apache.Flink</groupId> <artifactId>Flink-connector-jdbc_2.11</artifactId> <version>${Flink.version}</version> </dependency>
<dependency> <groupId>org.apache.Flink</groupId> <artifactId>Flink-java</artifactId> <version>${Flink.version}</version> </dependency> <dependency> <groupId>org.apache.Flink</groupId> <artifactId>Flink-clients_2.11</artifactId> <version>${Flink.version}</version> </dependency> <dependency> <groupId>org.apache.Flink</groupId> <artifactId>Flink-table-api-java-bridge_2.11</artifactId> <version>${Flink.version}</version> </dependency> <dependency> <groupId>org.apache.Flink</groupId> <artifactId>Flink-table-common</artifactId> <version>${Flink.version}</version> </dependency>
<dependency> <groupId>org.apache.Flink</groupId> <artifactId>Flink-table-planner_2.11</artifactId> <version>${Flink.version}</version> </dependency>
<dependency> <groupId>org.apache.Flink</groupId> <artifactId>Flink-table-planner-blink_2.11</artifactId> <version>${Flink.version}</version> </dependency> <dependency> <groupId>org.apache.Flink</groupId> <artifactId>Flink-table-planner-blink_2.11</artifactId> <version>${Flink.version}</version> <type>test-jar</type> </dependency>
<dependency> <groupId>com.ververica</groupId> <artifactId>Flink-connector-mySQL-CDC</artifactId> <version>2.0.0</version> </dependency>
<dependency> <groupId>org.apache.Hudi</groupId> <artifactId>Hudi-Flink-bundle_2.11</artifactId> <version>${Hudi.version}</version> <scope>system</scope> <systemPath>${project.basedir}/libs/Hudi-Flink-bundle_2.11-0.10.0-SNAPSHOT.jar</systemPath> </dependency>
<dependency> <groupId>mySQL</groupId> <artifactId>mySQL-connector-java</artifactId> <version>5.1.49</version> </dependency>
</dependencies></project>We build the query insert into t2 select replace(uuid(),'-',''),id,name,description,now() from mySQL_binlog inserts the created MySQL table into Hudi.
package name.lijiaqi;
import org.apache.Flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.Flink.table.api.EnvironmentSettings;import org.apache.Flink.table.api.SQLDialect;import org.apache.Flink.table.api.TableResult;import org.apache.Flink.table.api.bridge.java.StreamTableEnvironment;
public class MySQLToHudiExample { public static void main(String[] args) throws Exception { EnvironmentSettings fsSettings = EnvironmentSettings.newInstance() .useBlinkPlanner() .inStreamingMode() .build(); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, fsSettings);
tableEnv.getConfig().setSQLDialect(SQLDialect.DEFAULT);
// Data source table string sourceddl = "create table mysql_binlog (\ n" + "id int not null, \ n" + "name string, \ n" + "description string \ n" + ") with (\ n" + "'connector '='jdbc', \ n"+ " 'url' = 'jdbc:mySQL://127.0.0.1:3306/test', \n"+ " 'driver' = 'com.mySQL.jdbc.Driver', \n"+ " 'username' = 'root',\n" + " 'password' = 'dafei1288', \n" + " 'table-name' = 'test_CDC'\n" + ")";
// Output target table string sinkddl = "create table t2 (\ n" + "\ tuuid varchar (20), \ n" + "\ TID int not null, \ n" + "\ tname varchar (40), \ n" + "\ tdescription varchar (40), \ n" + "\ TTS timestamp (3) \ n "+// "\t`partition` VARCHAR(20)\n" + ")\n" +// "PARTITIONED BY (`partition`)\n" + "WITH (\n" + "\t'connector' = 'Hudi',\n" + "\t'path' = ' hdfs://172.19.28.4:9000/Hudi_t4/ ',\n" + "\ t 'table. Type' ='merge_on_read '\ n" + ")"; / / simple aggregation processing string transformsql = "insert into T2 select replace (uuid(),' - ',' '), ID, name, description, now() from MySQL"_ binlog";
tableEnv.executeSQL(sourceDDL); tableEnv.executeSQL(sinkDDL); TableResult result = tableEnv.executeSQL(transformSQL); result.print();
env.execute("mySQL-to-Hudi"); }}Query Hudi
package name.lijiaqi;
import org.apache.Flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.Flink.table.api.EnvironmentSettings;import org.apache.Flink.table.api.SQLDialect;import org.apache.Flink.table.api.TableResult;import org.apache.Flink.table.api.bridge.java.StreamTableEnvironment;
public class ReadHudi { public static void main(String[] args) throws Exception { EnvironmentSettings fsSettings = EnvironmentSettings.newInstance() .useBlinkPlanner() .inStreamingMode() .build(); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, fsSettings);
tableEnv.getConfig().setSQLDialect(SQLDialect.DEFAULT);
String sourceDDL = "CREATE TABLE t2(\n" + "\tuuid VARCHAR(20),\n"+ "\tid INT NOT NULL,\n" + "\tname VARCHAR(40),\n" + "\tdescription VARCHAR(40),\n" + "\tts TIMESTAMP(3)\n"+// "\t`partition` VARCHAR(20)\n" + ")\n" +// "PARTITIONED BY (`partition`)\n" + "WITH (\n" + "\t'connector' = 'Hudi',\n" + "\t'path' = 'hdfs://172.19.28.4:9000/Hudi_t4/',\n" + "\t'table.type' = 'MERGE_ON_READ'\n" + ")" ; tableEnv.executeSQL(sourceDDL); TableResult result2 = tableEnv.executeSQL("select * from t2"); result2.print();
env.execute("read_Hudi"); }}Show results
5, Flink CDC 2.0 on Hudi
In the previous chapter, we built the experiment in the form of code. In this chapter, we directly used the Flink package downloaded from the official website to build the experimental environment.
1. Add dependency
Add the following dependencies to $Flink_HOME/lib:
-
Hudi Flink bundle_2.11-0.10.0-snapshot.jar (modify the Hudi Flink version of the Master branch to 1.13.2 and build it)
-
hadoop-mapreduce-client-core-2.7.3.jar (solve Hudi ClassNotFoundException)
-
Flink-SQL-connector-mySQL-CDC-2.0.0.jar
-
Flink-format-changelog-json-2.0.0.jar
-
Flink-SQL-connector-Kafka_2.11-1.13.2.jar
Note that when looking for jar s, CDC 2.0 updated the group id and changed it to com.verica instead of com.alibaba.verica
2. Flink SQL CDC on Hudi
Create MySQL CDC table
CREATE TABLE mySQL_users ( id BIGINT PRIMARY KEY NOT ENFORCED , name STRING, birthday TIMESTAMP(3), ts TIMESTAMP(3)) WITH ( 'connector' = 'mySQL-CDC', 'hostname' = 'localhost', 'port' = '3306', 'username' = 'root', 'password' = 'dafei1288', 'server-time-zone' = 'Asia/Shanghai', 'database-name' = 'test', 'table-name' = 'users' );
Create Hudi table
CREATE TABLE Hudi_users5( id BIGINT PRIMARY KEY NOT ENFORCED, name STRING, birthday TIMESTAMP(3), ts TIMESTAMP(3), `partition` VARCHAR(20)) PARTITIONED BY (`partition`) WITH ( 'connector' = 'Hudi', 'table.type' = 'MERGE_ON_READ', 'path' = 'hdfs://localhost:9009/Hudi/Hudi_users5');
Modify the configuration, output the query mode as a table, and set the checkpoint
set execution.result-mode=tableau;set execution.checkpointing.interval=10sec;
Import input
INSERT INTO Hudi_users5(id,name,birthday,ts, `partition`) SELECT id,name,birthday,ts,DATE_FORMAT(birthday, 'yyyyMMdd') FROM mySQL_users;
Query data
select * from Hudi_users5;
results of enforcement
3. Card execution plan
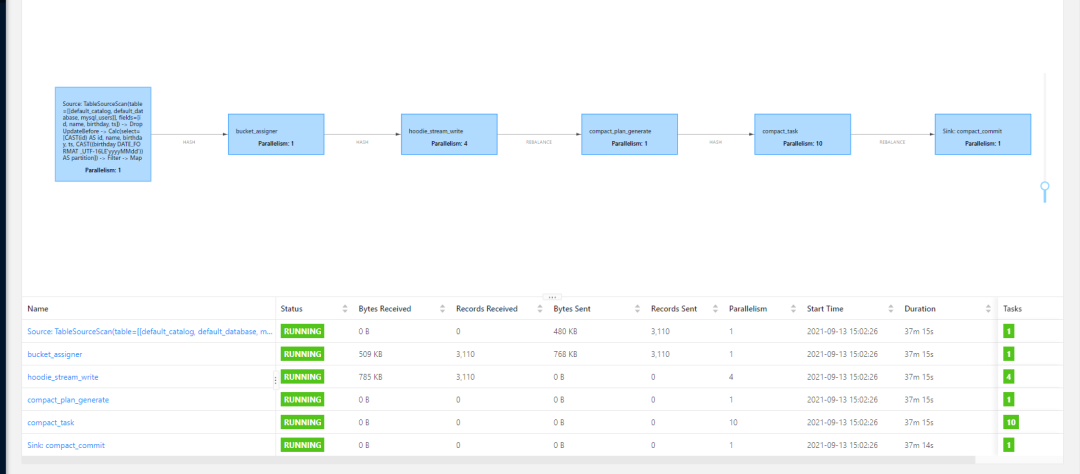
This problem has been studied for a long time. On the surface, it is normal, and there are no errors reported in the log. It can also be seen that the CDC works. There is data writing, but it is stuck in the hoodie_stream_write and there is no data distribution. Thanks to Danny Chan, the community leader, for his advice, it may be a checkpoint problem, so he made the following settings:
set execution.checkpointing.interval=10sec;
Finally normal:
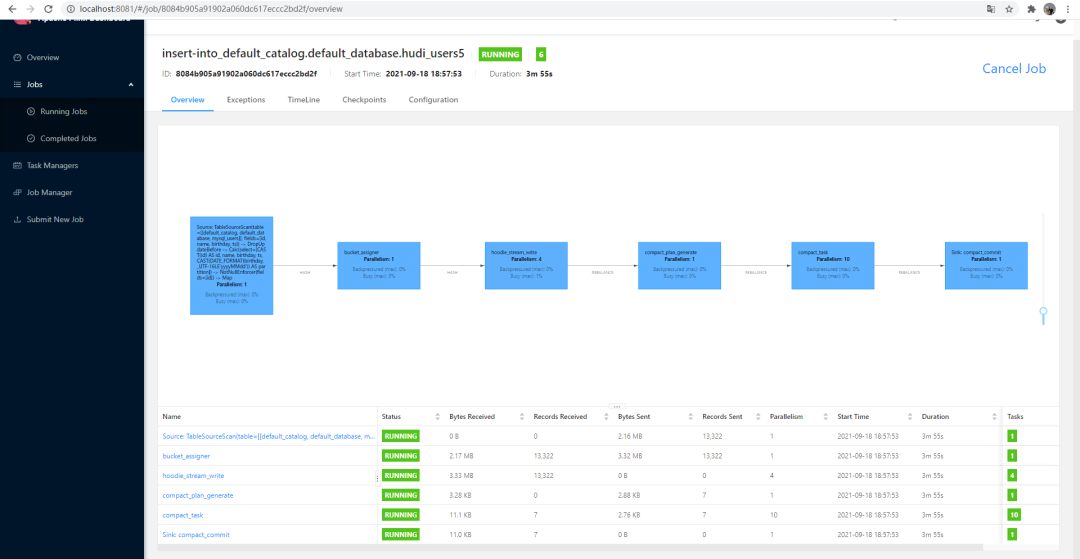
So far, the prototype of Flink + Hudi Lake warehouse integration scheme has been completed.
Reference link
[1] https://blog.csdn.net/qq_37095882/article/details/103714548
[2] https://blog.csdn.net/weixin_49218925/article/details/115511022