01 introduction
In the previous blog, we learned Flink's File Sink. Interested students can refer to the following:
- Flink tutorial (01) - Flink knowledge map
- Flink tutorial (02) - getting started with Flink
- Flink tutorial (03) - Flink environment construction
- Flink tutorial (04) - getting started with Flink
- Flink tutorial (05) - simple analysis of Flink principle
- Flink tutorial (06) - Flink batch streaming API (Source example)
- Flink tutorial (07) - Flink batch streaming API (Transformation example)
- Flink tutorial (08) - Flink batch streaming API (Sink example)
- Flink tutorial (09) - Flink batch streaming API (Connectors example)
- Flink tutorial (10) - Flink batch streaming API (others)
- Flink tutorial (11) - Flink advanced API (Window)
- Flink tutorial (12) - Flink advanced API (Time and Watermaker)
- Flink tutorial (13) - Flink advanced API (state management)
- Flink tutorial (14) - Flink advanced API (fault tolerance mechanism)
- Flink tutorial (15) - Flink advanced API (parallelism)
- Flink tutorial (16) - Flink Table and SQL
- Flink tutorial (17) - Flink Table and SQL (cases and SQL operators)
- Flink tutorial (18) - Flink phase summary
- Flink tutorial (19) - Flink advanced features (BroadcastState)
- Flink tutorial (20) - Flink advanced features (dual stream Join)
- Flink tutorial (21) - end to end exactly once
- Flink tutorial (22) - Flink advanced features (asynchronous IO)
- Flink tutorial (23) - Streaming File Sink
- Flink tutorial (24) - Flink advanced features (File Sink)
This article mainly explains how Flink SQL integrates Hive.
02 FlinkSQL integration Hive
2.1 introduction
reference resources:
- https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/hive/
- https://zhuanlan.zhihu.com/p/338506408
Using Hive to build data warehouse has become a common solution. At present, some common big data processing engines are compatible with Hive without exception. Flink supports integrated Hive from 1.9, but version 1.9 is beta and is not recommended for use in production environments. At flink1 In version 10, it marks the completion of the integration of Blink, and the integration of Hive also meets the requirements of production level. It is worth noting that different versions of Flink have different integration for Hive. Next, we will use the latest flink1 Take version 12 as an example to realize Flink integration Hive.
2.2 basic ways to integrate Hive
The integration of Flink and Hive is mainly reflected in the following two aspects:
- Persistent metadata: Flink uses Hive's MetaStore as a persistent Catalog. We can store Flink metadata in different sessions in Hive Metastore through HiveCatalog. For example, we can use HiveCatalog to store its Kafka data source table in Hive Metastore, so that the metadata information of the table will be persisted to the metadata database corresponding to Hive Metastore, and we can reuse them in subsequent SQL queries.
- Use Flink to read and write Hive tables: Flink opens up the integration with Hive. Just like using SparkSQL or Impala to operate the data in Hive, we can use Flink to read and write Hive tables directly.
The design of HiveCatalog provides good compatibility with Hive. Users can access their existing Hive tables "out of the box". There is no need to modify the existing history Metastore, or change the data location or partition of the table.
2.3 preparation
1. Add hadoop_classpath
vim /etc/profile
Add the following configuration
export HADOOP_CLASSPATH=`hadoop classpath`
Refresh configuration
source /etc/profile
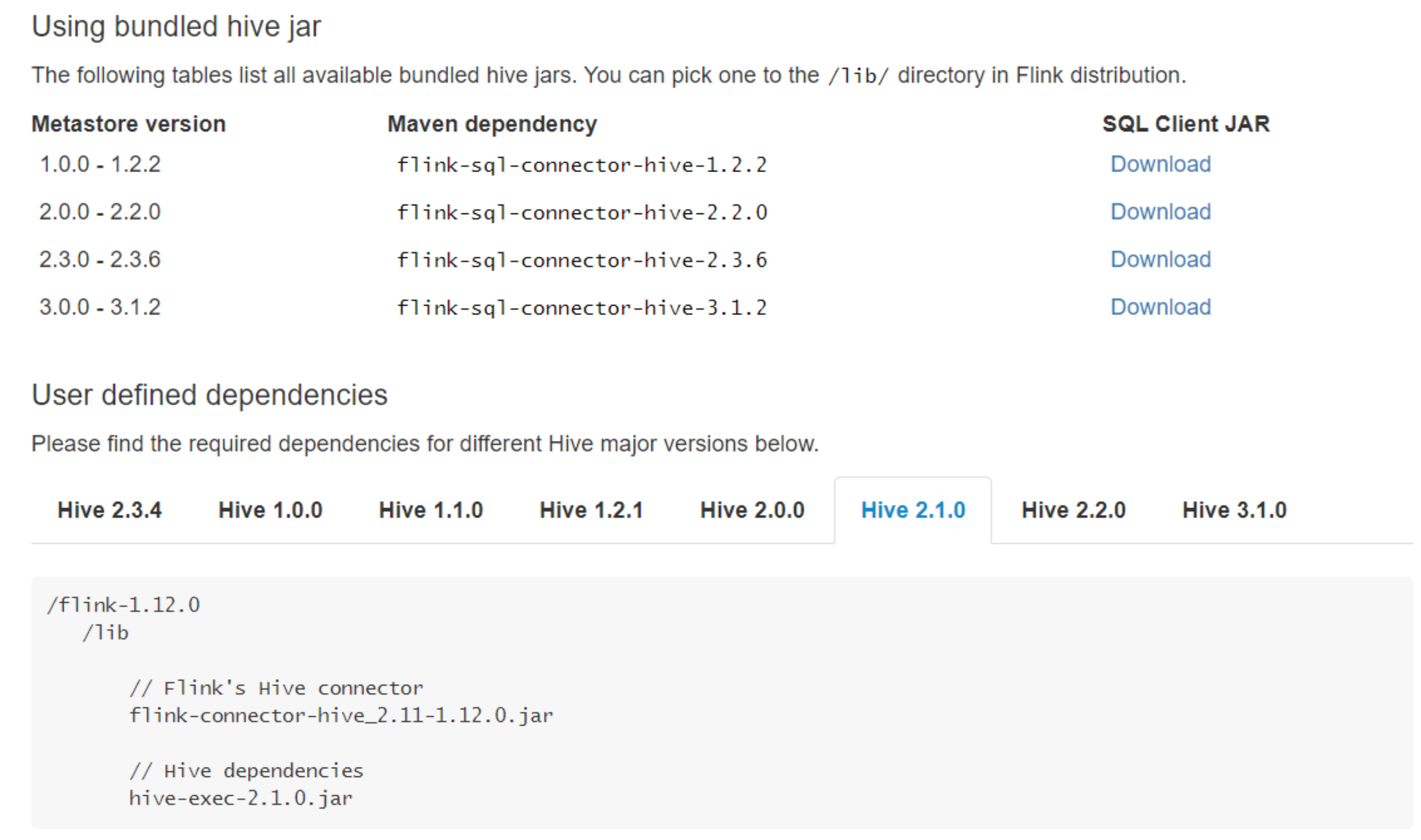
2. Download the jar and upload it to the flink/lib directory
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/hive/
3. Modify hive configuration
vim /export/server/hive/conf/hive-site.xml
<property>
<name>hive.metastore.uris</name>
<value>thrift://node3:9083</value>
</property>
4. Start hive metadata service
nohup /export/server/hive/bin/hive --service metastore &
2.4 SQL CLI
1. Modify the flinksql configuration
vim /export/server/flink/conf/sql-client-defaults.yaml
Add the following configuration
catalogs:
- name: myhive
type: hive
hive-conf-dir: /export/server/hive/conf
default-database: default
2. Start the flink cluster
/export/server/flink/bin/start-cluster.sh
3. Start the Flink SQL client
/export/server/flink/bin/sql-client.sh embedded
4. Execute sql:
show catalogs; use catalog myhive; show tables; select * from person;
2.5 code demonstration
/**
* Flink SQL Integrate hive
*
* @author : YangLinWei
* @createTime: 2022/3/9 9:22 morning
*/
public class HiveDemo {
public static void main(String[] args) {
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
String name = "myhive";
String defaultDatabase = "default";
String hiveConfDir = "./conf";
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir);
//Register catalog
tableEnv.registerCatalog("myhive", hive);
//Use registered catalog
tableEnv.useCatalog("myhive");
//Write data to Hive table
String insertSQL = "insert into person select * from person";
TableResult result = tableEnv.executeSql(insertSQL);
System.out.println(result.getJobClient().get().getJobStatus());
}
}
03 end
This article mainly explains the integration of FlinkSQL and Hive. Thank you for reading. The end of this article!