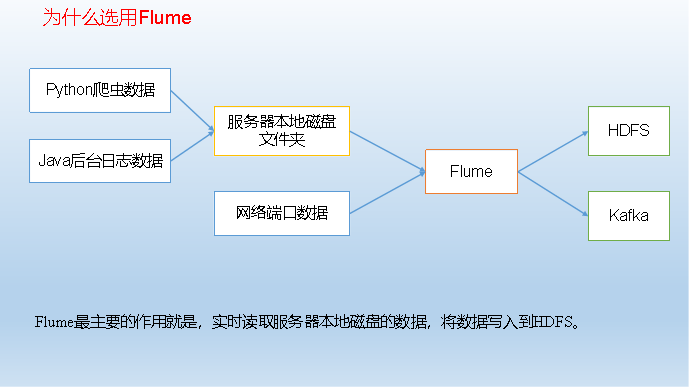
1. What is Flume: Flume is a highly available, highly reliable, distributed system for collecting, aggregating and transferring massive logs provided by Cloudera. Flume is based on streaming architecture, flexible and simple.
Flume Composition Architecture
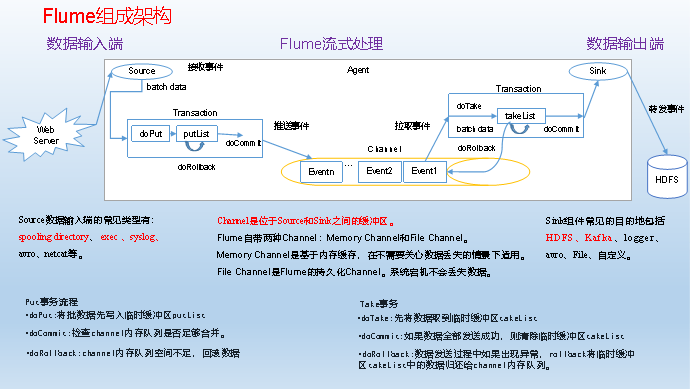
Now let's go into detail about the components in the Flume architecture.
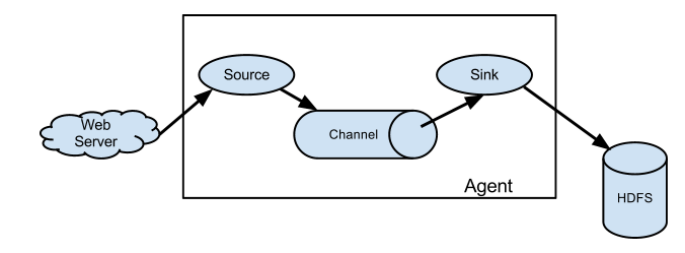
1) Agent:
Is a jvm program, which sends data from the source to the destination in the form of events. It is the basic unit of Flume data transmission.
Agent consists of three parts: Source, Channel and Sinl.
2) Source:
Source is the organization responsible for receiving data to Flume Agent. Source can process various types and formats of log data, including avro, thirft, exec, jms, spooling directory, netcat, sequence generator, syslog, http, legacy.
3) Channel:
Channel is a buffer between Source and Sun
Therefore, Channel allows SOurce and Link to operate at different rates. Channel is thread-safe and can handle several Source write operations and several Sink read operations at the same time.
Flume comes with two Channels: Memory Channel and FIle Channel.
Memory Channel: It's a queue in memory. Memory Channel is suitable without loss of relational data. If relational data needs to be lost, Memory Channel should not be used because program death and restart of machine outage value will result in data loss.
File Channel writes all events to disk. Therefore, the data will not be lost when the program relationship value machine goes down.
4) Sink:
Sink constantly polls Channel events and removes them in batches, and writes these events in batches to a storage or indexing system, or is sent to another Flume Agent.
Sink is completely transactional. Between mass deletion of data from Channel, each Sink starts a transaction with Channel. Once batch events are successfully written to the storage system or the next Flume Agent, Sink commits transactions using Channel. Once a transaction is committed, the Channel deletes events from its internal buffer.
Sink build destinations include: hdfs, logger, avro, thrift, ipc, file, null, Hbase, solr, custom.
Event Topology
The topology of Flume is shown in the figure.
Flume Agent Connection
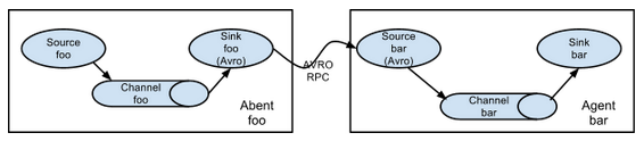
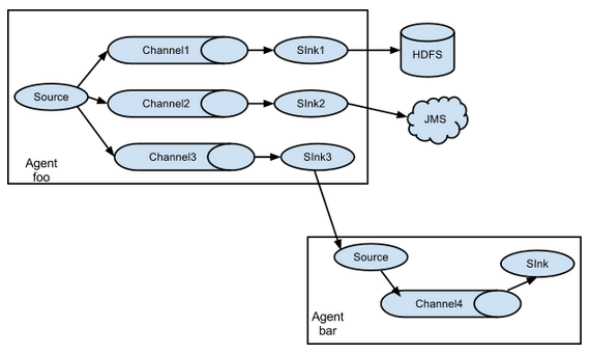
Single source, multiple channel, sink
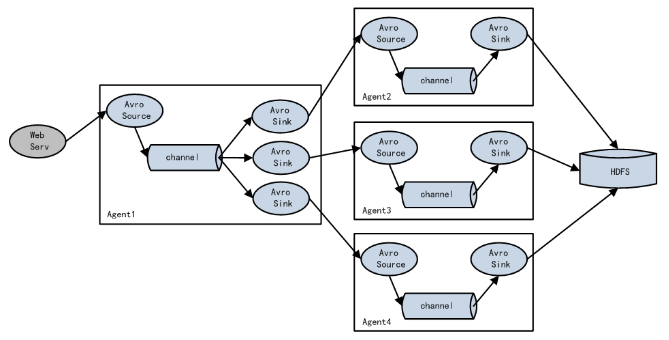
Flume Load Balancing
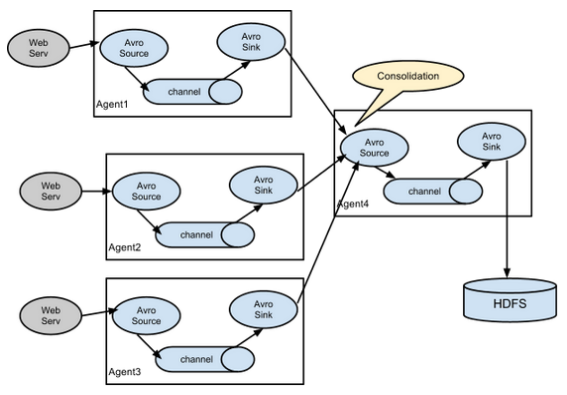
Flume Agent Aggregation
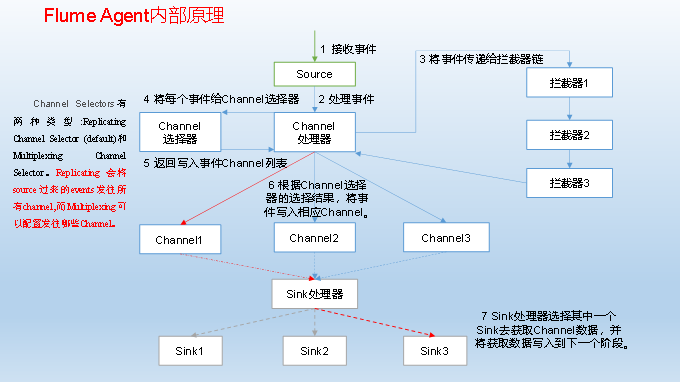
Internal Principles of Flume Agent
Flume Installation
1) Official website
2) Document View Address
3) Download address
Installation Deployment
1) Upload apache-flume-1.9.0-bin.tar.gz to the / usr/local/directory of linux
2) Unzip apache-flume-1.9.0-bin.tar.gz to/usr/local/directory
$ tar -zxf apache-flume-1.9.0-bin.tar.gz -C /usr/local/
3) Modify the name of apache-flume-1.9.0-bin to flume
$ mv apache-flume-1.9.0-bin flume
4) Modify the flume-env.sh.template file under flume/conf to flume-env.sh and configure the flume-env.sh file
$ mv flume-env.sh.template flume-env.sh $ vi flume-env.sh export JAVA_HOME=/home/hduser/software/jdk1.8.0_221
Case:
1)
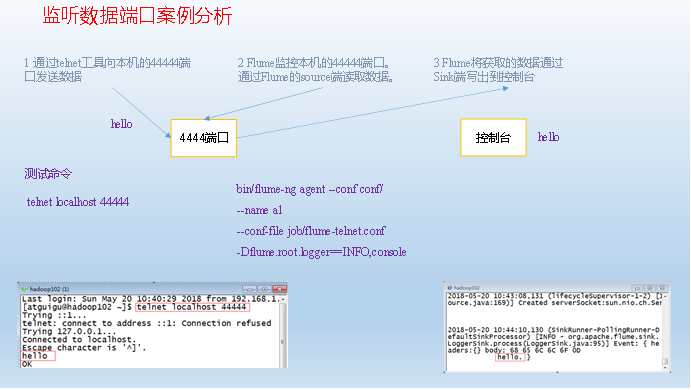
First, Flume monitors port 44444, then sends messages to port 44444 via telnet tool. Finally, Flume displays the monitored data in real time on the console.
Demand analysis:
3) Implementation steps:
Install telnet tools
Check if telnet has been installed
rpm -qa | grep telnet
If there's nothing, just don't install it and go on to the next step.
Install telnet and telnet-server. Note that root permission is required to install. (Seems like you need to follow the server first)
yum install telnet-server -y yum install telnet -y
Because after installing the telnet service, the default is not to open the service. Next we need to modify the file to open the service.
Note: The telnet configuration file for centos7 is: / etc/xinetd.conf. Centos7 was before / etc/xinetd.d/telnet
vim /etc/xinetd.d/telnet
Modify disable = yes to disable = no
Need to activate xinetd service
systemctl start xinetd.service
Let xinetd boot
systemctl enable xinetd.service
Start telnet service
systemctl restart telnet.socket
Setting up telnet service to boot
systemctl enable telnet.socket
Test whether telnet is successfully opened
telnet localhost
Determine whether port 4444444 is occupied
sudo netstat -tunlp | grep 44444 Function Description: The netstat command is a very useful tool for monitoring TCP/IP networks. It can display routing tables, actual network connections and each network interface setting. Prepared status information. Basic grammar: netstat [option] Option parameters: - t or -- tcp: Shows the connection status of TCP transport protocol; - u or - udp: Shows the connection status of UDP transport protocol; - n or -- numeric: use the ip address directly, not through the domain name server; - l or -- listening: Show the Socket of the server under monitoring; - p or -- programs: Displays the program identifier and program name that is using Socket;
Create the Flume Agent configuration file flume-telnet-logger.conf
Create a job folder under the flume directory and enter the job folder
mkdir jobconf cd jobconf/
Create the Flume Agent configuration file flume-telnet-logger.conf under the job folder
touch flume-telnet-logger.conf
Add the following to the flume-telnet-logger.conf file.
vim flume-telnet-logger.conf
Add the following:
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1

Function
Open the flume listening port first
bin/flume-ng agent --conf conf/ --name a1 --conf-file jobconf/flume-telnet-logger.conf -Dflume.root.logger=INFO,console
Description of parameters:
Conf/: Represents that configuration files are stored in conf / directory
- name a1: denotes naming an agent A1
conf-file job/flume-telnet.conf: The configuration file read by flume at this boot is the flume-telnet.conf file under the job folder.
- D flume.root.logger== INFO, console:-D indicates that the flume runtime dynamically modifies the flume.root.logger parameter attribute values, and sets the console log printing level to INFO level. Log levels include log, info, warn, error.
Send Content to Port 44444 of Local Machine Using telnet Tool
telnet localhost 44444
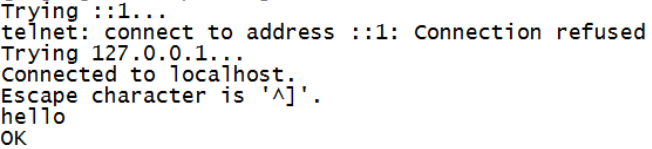
Watch the received data on the Flume monitor page
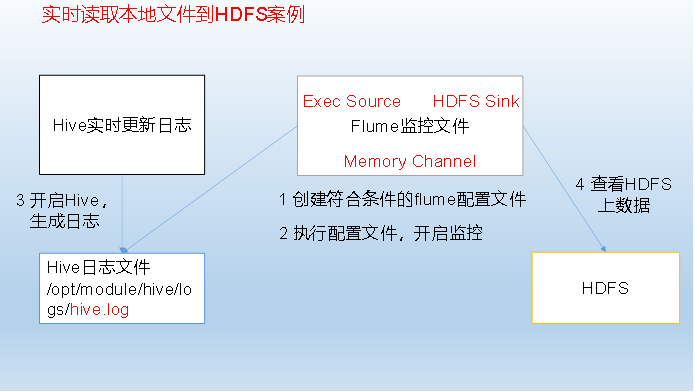
Case 2) Real-time reading of local files to HDFS cases
1. Flume must have Hadoop-related jar packages in order to export data to HDFS
take
commons-configuration-1.6.jar, hadoop-auth-2.7.2.jar, hadoop-common-2.7.2.jar, hadoop-hdfs-2.7.2.jar, commons-io-2.4.jar, htrace-core-3.1.0-incubating.jar
Copy to / opt/module/flume/lib folder.
2. Create flume-file-hdfs.conf file
create a file
touch flume-file-hdfs.conf
Note: To read files in Linux system, you must execute commands according to the rules of Linux commands. Because Hive logs are in Linux system, the type of file to read is chosen: exec is the meaning of execute execution. Represents executing Linux commands to read files.
vim flume-file-hdfs.conf
Add the following
# Name the components on this agent a2.sources = r2 a2.sinks = k2 a2.channels = c2 # Describe/configure the source a2.sources.r2.type = exec a2.sources.r2.command = tail -F /udr/local/hive/logs/hive.log a2.sources.r2.shell = /bin/bash -c # Describe the sink a2.sinks.k2.type = hdfs a2.sinks.k2.hdfs.path = hdfs://chun1:9000/flume/%Y%m%d/%H #Prefix for uploading files a2.sinks.k2.hdfs.filePrefix = logs- #Whether to scroll folders according to time a2.sinks.k2.hdfs.round = true #How much time to create a new folder a2.sinks.k2.hdfs.roundValue = 1 #Redefining unit of time a2.sinks.k2.hdfs.roundUnit = hour #Whether to use local timestamp a2.sinks.k2.hdfs.useLocalTimeStamp = true #How many Event s are saved to flush to HDFS once a2.sinks.k2.hdfs.batchSize = 1000 #Set file type to support compression a2.sinks.k2.hdfs.fileType = DataStream #How often to generate a new file a2.sinks.k2.hdfs.rollInterval = 600 #Set the scroll size for each file a2.sinks.k2.hdfs.rollSize = 134217700 #File scrolling is independent of the number of Event s a2.sinks.k2.hdfs.rollCount = 0 #Minimum Redundancy Number a2.sinks.k2.hdfs.minBlockReplicas = 1 # Use a channel which buffers events in memory a2.channels.c2.type = memory a2.channels.c2.capacity = 1000 a2.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r2.channels = c2 a2.sinks.k2.channel = c2

3. Implementation of monitoring configuration
bin/flume-ng agent --conf conf/ --name a2 --conf-file job/flume-file-hdfs.conf
4. Open Hadoop and Hive and operate Hive to generate logs
sbin/start-dfs.sh sbin/start-yarn.sh bin/hive hive >
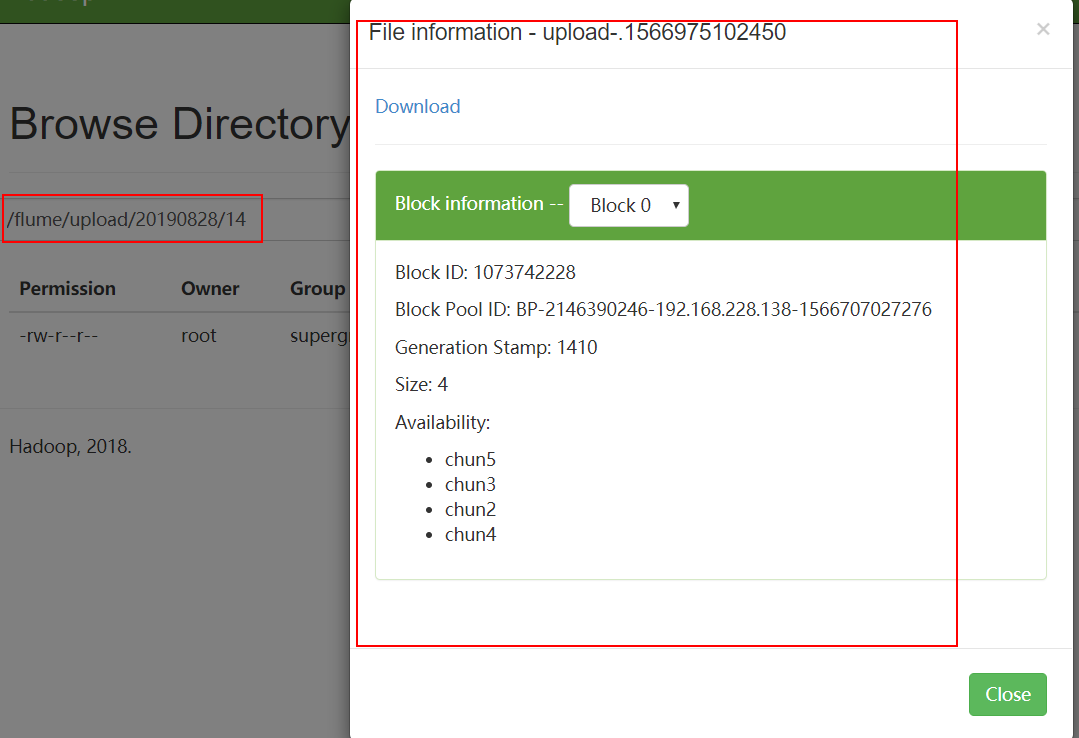
5. View files on HDFS.

Case 3) Real-time reading directory files to HDFS cases
Use Flume to listen for files in the entire directory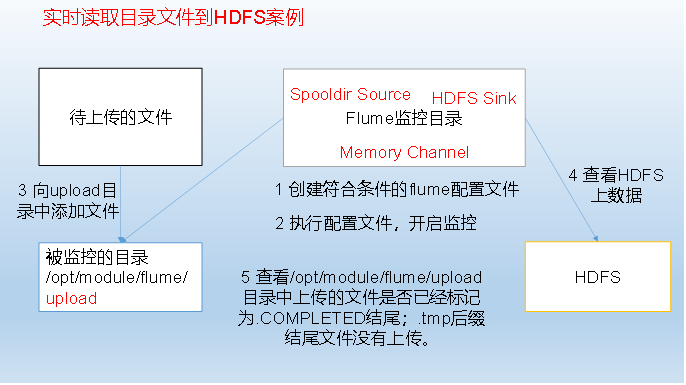
3) Implementation steps:
1. Create configuration file flume-dir-hdfs.conf
Create a file
touch flume-dir-hdfs.conf
Open the file
vim flume-dir-hdfs.conf
Add the following
a3.sources = r3 a3.sinks = k3 a3.channels = c3 # Describe/configure the source a3.sources.r3.type = spooldir a3.sources.r3.spoolDir = /usr/local/flume-1.9.0/jobconf/upload a3.sources.r3.fileSuffix = .COMPLETED a3.sources.r3.fileHeader = true #Ignore all files ending with. tmp and do not upload a3.sources.r3.ignorePattern = ([^ ]*\.tmp) # Describe the sink a3.sinks.k3.type = hdfs a3.sinks.k3.hdfs.path = hdfs://hadoop102:9000/flume/upload/%Y%m%d/%H #Prefix for uploading files a3.sinks.k3.hdfs.filePrefix = upload- #Whether to scroll folders according to time a3.sinks.k3.hdfs.round = true #How much time to create a new folder a3.sinks.k3.hdfs.roundValue = 1 #Redefining unit of time a3.sinks.k3.hdfs.roundUnit = minute #Whether to use local timestamp a3.sinks.k3.hdfs.useLocalTimeStamp = true #How many Event s are saved to flush to HDFS once a3.sinks.k3.hdfs.batchSize = 100 #Set file type to support compression a3.sinks.k3.hdfs.fileType = DataStream #How often to generate a new file a3.sinks.k3.hdfs.rollInterval = 600 #Setting the scroll size for each file is about 128M a3.sinks.k3.hdfs.rollSize = 134217700 #File scrolling is independent of the number of Event s a3.sinks.k3.hdfs.rollCount = 0 #Minimum Redundancy Number a3.sinks.k3.hdfs.minBlockReplicas = 1 # Use a channel which buffers events in memory a3.channels.c3.type = memory a3.channels.c3.capacity = 1000 a3.channels.c3.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r3.channels = c3 a3.sinks.k3.channel = c3

2. Start the Monitor Folder Command
bin/flume-ng agent --conf conf/ --name a3 --conf-file job/flume-dir-hdfs.conf
Note: When using Spooling Directory Source
1) Do not create and continuously modify files in the monitoring directory
2) Uploaded files end with. COMPLETED
3) File changes of monitored folders are scanned every 500 milliseconds
3. Add files to upload folder
Create upload folder under / opt/module/flume directory
mkdir upload
Add files to upload folder
touch atguigu.txt touch atguigu.tmp touch atguigu.log
4. View data on HDFS