Learn about data preprocessing
d2l.DATA_HUB['fra-eng'] = (d2l.DATA_URL + 'fra-eng.zip',
'94646ad1522d915e7b0f9296181140edcf86a4f5')
#@save
def read_data_nmt():
"""Load English-French dataset."""
data_dir = d2l.download_extract('fra-eng')
with open(os.path.join(data_dir, 'fra.txt'), 'r',
encoding='utf-8') as f:
return f.read()
raw_text = read_data_nmt()
print(raw_text[:75])
In fact, this function is redundant, which means downloading a data set.
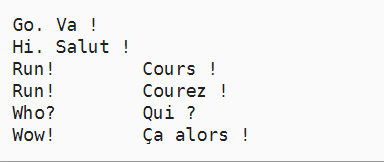
This is a character data set, that is, each element is a character
def preprocess_nmt(text):
"""Preprocessing "English"-French dataset."""
def no_space(char, prev_char):
return char in set(',.!?') and prev_char != ' '
# Replace uninterrupted spaces with spaces
# Replace uppercase letters with lowercase letters
text = text.replace('\u202f', ' ').replace('\xa0', ' ').lower()
# Insert spaces between words and punctuation
out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else char
for i, char in enumerate(text)]
return ''.join(out)
text = preprocess_nmt(raw_text)
print(text[:80])
This function is more like a standardized function. After formatting each word, there is a punctuation mark and a tab between words
def tokenize_nmt(text, num_examples=None):
"""Morpheme "English"-French dataset."""
source, target = [], []
for i, line in enumerate(text.split('\n')):
if num_examples and i > num_examples:
break
parts = line.split('\t')
if len(parts) == 2:
source.append(parts[0].split(' '))
target.append(parts[1].split(' '))
return source, target
source, target = tokenize_nmt(text)
source[:6], target[:6]
Morpheme, here it outputs two of this table. One is that source can be understood as an English dictionary, and the other is that target can be understood as a French dictionary. We think our input can return target after RNN
Each element of a dictionary has two lengths, one is a word, and the other is a punctuation mark that identifies a character
src_vocab = d2l.Vocab(source, min_freq=2,
reserved_tokens=['<pad>', '<bos>', '<eos>'])
len(src_vocab)
Here, when we created the dictionary, we also added three special symbols, respectively identifying the start symbol, bos, the end symbol eos and the interval symbol pad, and we removed the characters whose frequency is less than 2.
def truncate_pad(line, num_steps, padding_token):
"""Truncates or fills the text sequence."""
if len(line) > num_steps:
return line[:num_steps] # truncation
return line + [padding_token] * (num_steps - len(line)) # fill
truncate_pad(src_vocab[source[0]], 10, src_vocab['<pad>'])
For data, we hope that the length of statements in a batch can be quite num_step effect, so if the length is insufficient, we need to supplement it. If the length is too long, we need to intercept it.
def build_array_nmt(lines, vocab, num_steps):
"""Convert machine translated text sequences into small batches."""
lines = [vocab[l] for l in lines]
lines = [l + [vocab['<eos>']] for l in lines]
array = torch.tensor([truncate_pad(
l, num_steps, vocab['<pad>']) for l in lines])
valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1)
return array, valid_len
You need to understand this function
First, let's change lines
Originally, lines = [[go,.], [Hello,?]...]
Now turn the characters inside into the corresponding index (our vocab is classified according to characters)
The second step is to add the eos symbol behind each word,
The third step is to complete each Minibatch and complete each word in the batch into num_ The length of steps,
Step 4, calculate the effective length of each sentence.
def load_data_nmt(batch_size, num_steps, num_examples=600):
"""Returns the iterator and vocabulary of the translation dataset."""
text = preprocess_nmt(read_data_nmt())
source, target = tokenize_nmt(text, num_examples)
src_vocab = d2l.Vocab(source, min_freq=2,
reserved_tokens=['<pad>', '<bos>', '<eos>'])
tgt_vocab = d2l.Vocab(target, min_freq=2,
reserved_tokens=['<pad>', '<bos>', '<eos>'])
src_array, src_valid_len = build_array_nmt(source, src_vocab, num_steps)
tgt_array, tgt_valid_len = build_array_nmt(target, tgt_vocab, num_steps)
data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)
data_iter = d2l.load_array(data_arrays, batch_size)
return data_iter, src_vocab, tgt_vocab
This function is to implement a package
num_steps indicates how many time steps you want to process in an RNN cycle
batch_size: indicates that you want to read several pieces of data at one time
For the return value data_iter is actually a quad. The first two elements represent batch English sentences and corresponding lengths, and the last two elements represent batch French sentences and corresponding effective lengths