hive built-in function
In Hive, functions are mainly divided into two types: built-in functions and user-defined functions.
Function view
show functions; desc function functionName;
Date function
1) Current system time function: current_date(). current_timestamp(),unix_timestamp()
-- Function 1:current_date(); Current system date format:"yyyy-MM-dd" -- Function 2:current_timestomp(); Current system timestamp:format:"yyyy-MM-dd HH:mmm:ss.ms" -- Function 3: unix_timestamp(); Current system timestamp format:The number of seconds from 0:00 on January 1, 1970.
2) Date to timestamp function: unix_timestamp()
format: unix_timestamp([date[,pattern]])
case:
select unix_timestamp( '1970-01-01 0:0:0'); -- The date and time passed in is the time of Dongba District, and the return value is relative to the time of meridian
select unix_timestamp('1970-01-01 8:0:0') #0
-- Custom format
select unix_timestamp('0:0:0 1970-01-01' ,"HH:mm:ss yyyy-MM-dd");
select unix_timestamp(current_date());
3) Timestamp to date function: from_unixtime
grammar:from__unixtime(unix_time[,pattern]) case; select from_unixtime(1574092800); select from_unixtime(1574096401,'yyyy/MM/dd'); select from_unixtime(1574896401,'yyyy-MM-dd HH:mm:ss'); select from_unixtime(0,'yyyy-MM-dd HH:mm:ss'); select from_unixtime(-28800,"yyyy-MM-dd HH:mm:ss";
4) Calculate the time difference function: datediff().months_between0
format: datediff(date1,date2) - Returns the number of days between date1 and date2
select datediff("2019-11-20","2019-11-01"); #Return 19
select datediff("2019-11-01","2019-11-19"); #Return - 18
format: months_between(date1,date2) - returns number of months between dates date1 and date2
select months_between( '2019-11-20','2019-11-01'); #Return 0.6 (months)
select months_between( '2019-10-30','2019-11-30'); #Return 1 (month)
select months_betweenC '2019-10-31','2019-11-30');
select months_between( '2019-11-00','2019-11-30');
5) Date time component functions: year(), month0, day0, hour(), minute(), second()
-- case select year(current_date); select month(current_date); select day(current_date); select year(current_timestamp); select month(current_timestamp); select day(current_timestamp); select hour(current_timestamp); select minute(current_timestamp); select second(current_timestamp); select dayofmonth(current_date); #What day of the month is today select weekofyear(current_date); #What week is this year
6) Date locator function: last_day(),next_day()
-- end of the month: select last_day(current_date) -- next week select next_day(current_date,'thursday') ; #What date is the next thursday
7) Date addition and subtraction function: date_addo.date_subo,add_months()
select date_add(current_date,1);
select date_sub(current_date,90);
select add_months(current_date,12;
select date_add('2019-12-10',1); #Return to December 11, 2019
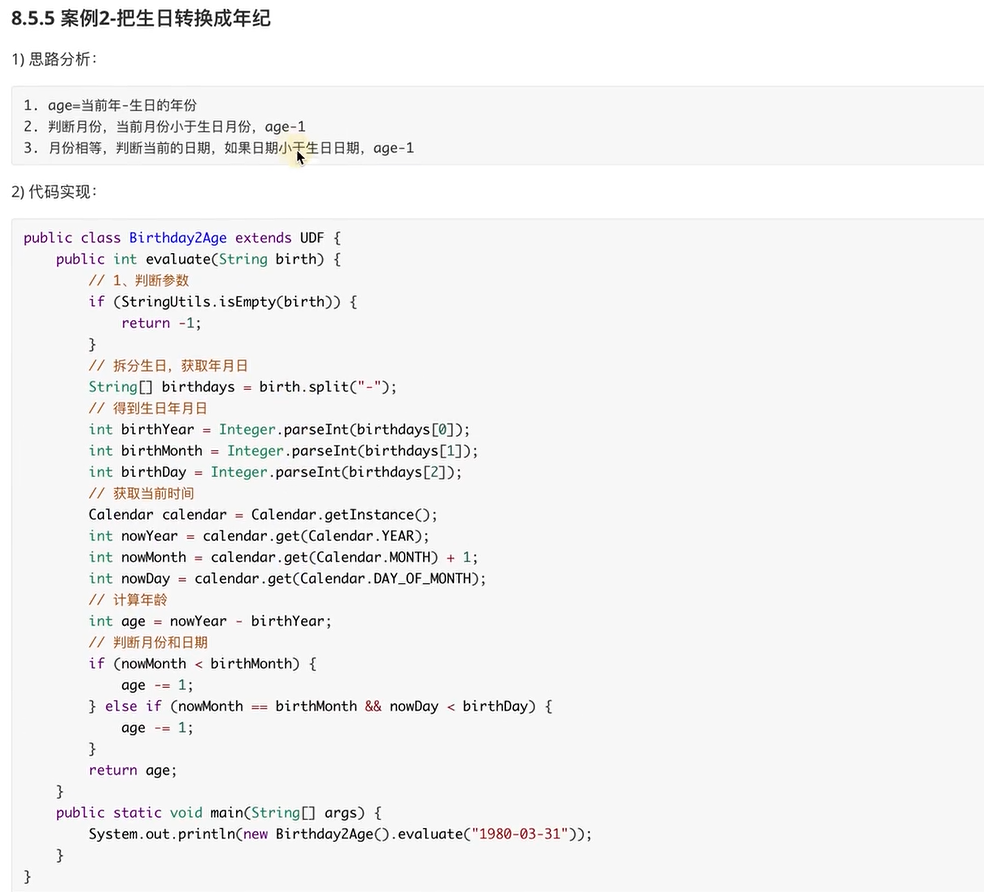
8) String to date: to_date(
(String must be: yyyy-MM-dd format)
select to_date('2017-01-01 12:12:12');
9) Date to string (format) function: date_format
select date_format(current_timestamp(),'yyyy-MM-dd HH:mm:ss'); select date_format(current_date(),'yyyyMMdd'); select date_format( '2017-21-01','yyyy-MM-dd HH:mm:ss');
String function
lower -- (Turn lowercase)
select lower('ABC');
upper -- (Capitalize)
select upper('abc');
length -- (String length, number of characters)
select length('abc');
concat -- (String splicing)
select concat('A','B','C'); # ABC
concat_ws -- (Specify separator)
select concat_ws('-','a','b','c'); # a-b-c
substr-- (substring )
select substr('abcde',3); # cde
select substr('abcde',2,3); # bc
split(str ,regex) -- Splits a string and returns an array.
select split("a-b-c-d-e-f","-");
Type conversion function
cast(value as type) -- Type conversion
select cast("123" as int)+1;
Mathematical function
round -- rounding((42.3 ->42)) select round(42.3); ceil -- Round up(42.3=>43) select ceil(42.3); floor -- Round down(42.3=>42) select floor(42.3);
Other common functions
nvl(value ,default value):If value by null,Then use default value,Otherwise, use itself value. select if(1>2 ,ture,false); # Return false select coalesce(1,2,3,4,5) # Return the first non empty question return 1 select coalesce(NULL,2,3,4,5) # Return to 2
Window function of hive (emphasis)
Introduction to window function over
Let's take a look at this demand first: find the employee information of each department and the average salary of the Department. How to implement it in mysql
SELECT emp.*,avg_sal
FROM emp
J0IN (
SELECT deptno
,round(AVG(ifnull(sal, 0))) AS avg_sal
FR0M emp
GROUP BY deptno
) t
ON emp.deptno = t.deptno
ORDER BY deptno;
select emp.*,(select avg(ifnull(sal,0)) from emp B where B.deptno = A.deptno) from emp A;
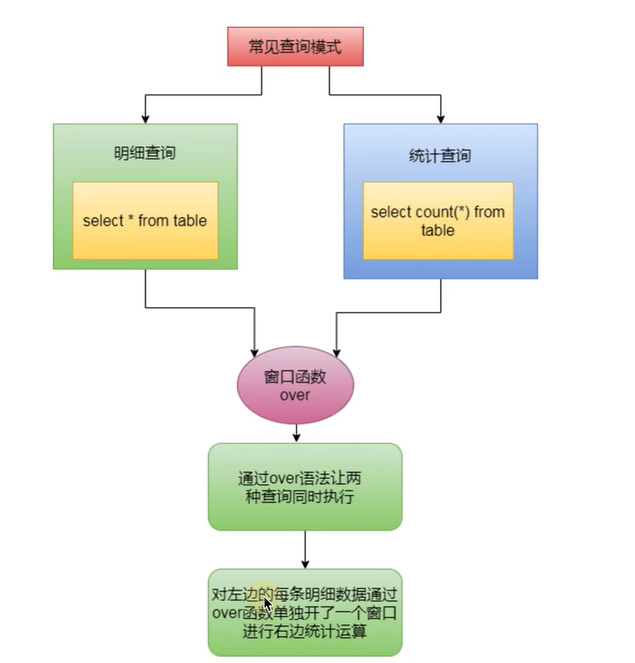
Through this requirement, we can see that if you want to query detailed records and aggregate data, you must query twice, which is more troublesome. At this time, it will be much more convenient for us to use the window function. So what is the window function?
-1)Window function, also known as window function. It belongs to a kind of analysis function. -2)It is a function used to solve the statistical requirements of complex reports. -3)Window function is often used to calculate some value based on group, which is different from aggregate function:Multiple rows are returned for each group, while the aggregate function returns only one row for each group. Simply put, a window function is used to open a face for each detailed record,Query aggregation -4)The windowing function specifies the data window size of the analysis function. The data window size may change with the change of rows. -5)Window functions are not used only -6)You can also group and sort within the window function
Case preparation
Data preparation order.txt
Name purchase date purchase quantity
saml,2018-01-01,10
tomy,2018-01-02,15
saml,2018-02-03,23
...
-- 1.establish order Table:
create table if not exists t_order(
name string,
orderdata string,
cost int
)row format delimited fields terminated by ',';
-- 2.Load data
load data local inpath "./root/order.txt" into table t_order;
Demand: query the information of each order and the total number of orders
– 1. Do not use window functions
-- Query all details select* from t_order; #Total query select count(*) from t_order;
– 2. Use window function: usually the format is available function + over() function
select *, count(*) over() from t_order; -- Results returned by query saml,2018-01-01,10 3 tomy,2018-01-02,15 3 saml,2018-02-03,23 3
be careful:
The window function is for each row of data
If no parameter is specified in over, the default window size is all result sets
Demand: query the purchase details and total number of customers who purchased in January 2018
select * ,count(*) over() from t_order where substring(orderdate,1,7) = '2018-01'; -- Results returned by query saml,2018-01-01,10 2 tomy,2018-01-02,15 2
distribute by clause
Group in the over window, and make grouping statistics for a field. The window size is all records of the same group
Demand: view the customer's purchase details and monthly total purchase amount
select name,orderdate,cost,sum(cost) over (distribute by month(orderdate)) from t_order; saml,2018-01-01,10 33 tomy,2018-01-02,15 15 saml,2018-02-03,23 33
Demand: view the customer's purchase details and the monthly total purchase amount of each customer
select name,orderdate,cost,sum(cost) over (distribute by name, month(orderdate)) from t_order; saml,2018-01-01,10 33 tomy,2018-01-02,15 15 saml,2018-02-03,23 33
sort by clause
The sort by clause will force the input data to be sorted (emphasis: when sorting is used, the window will grow row by row in the group)
Demand: view the purchase details of customers and the monthly total purchase amount of each customer, and sort them in descending order by date
select name,orderdate,cost, sum(cost) over (distribute by name, month(orderdate) sort by orderdata desc) from t_order; saml,2018-01-01,10 10 saml,2018-02-03,23 33 saml,2018-02-03,53 86 tomy,2018-01-02,15 15
window clause of hive
If you want to make more fine-grained division of the results of the window, you can use the window clause. The following are common
PRECEDING:Go ahead FOLLOWING:Back CURRENT ROW:Current row UNBOUNDED:starting point, UNBOUNDED PRECEDING:Represents the starting point from the front, UNBOUNDED FOLLOWING:Indicates to the next end point
Demand: view the customer's total purchase so far
select name, t_order.orderdata, cost, sum(cost) over(partition by name order by orderdata rows between UNBOUNDED PRECEDING and current row) as allCount from t_order;
Demand: find the total consumption of each customer in the last three times
select name,orderdate,cost, sum(cost) over(partition by name order by orderdata rows between 2 PRECEDING and current row) from t_order;
Hive's sequence function
NTILE
ntile is a powerful analysis function of Hive. It can be regarded as: it evenly distributes the ordered data set to the specified number (num) of beds, and assigns the bucket number to each row. If it cannot be evenly distributed, the barrels with smaller numbers shall be allocated first, and the number of rows that can be placed in each barrel shall differ by 1 at most.
example:
select name,orderdate,cost, ntile(3) over(partition by name), #Group by name, and cut the data into 3 copies in the group from t_order;
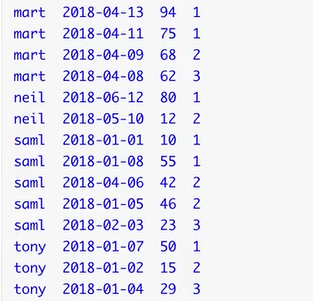

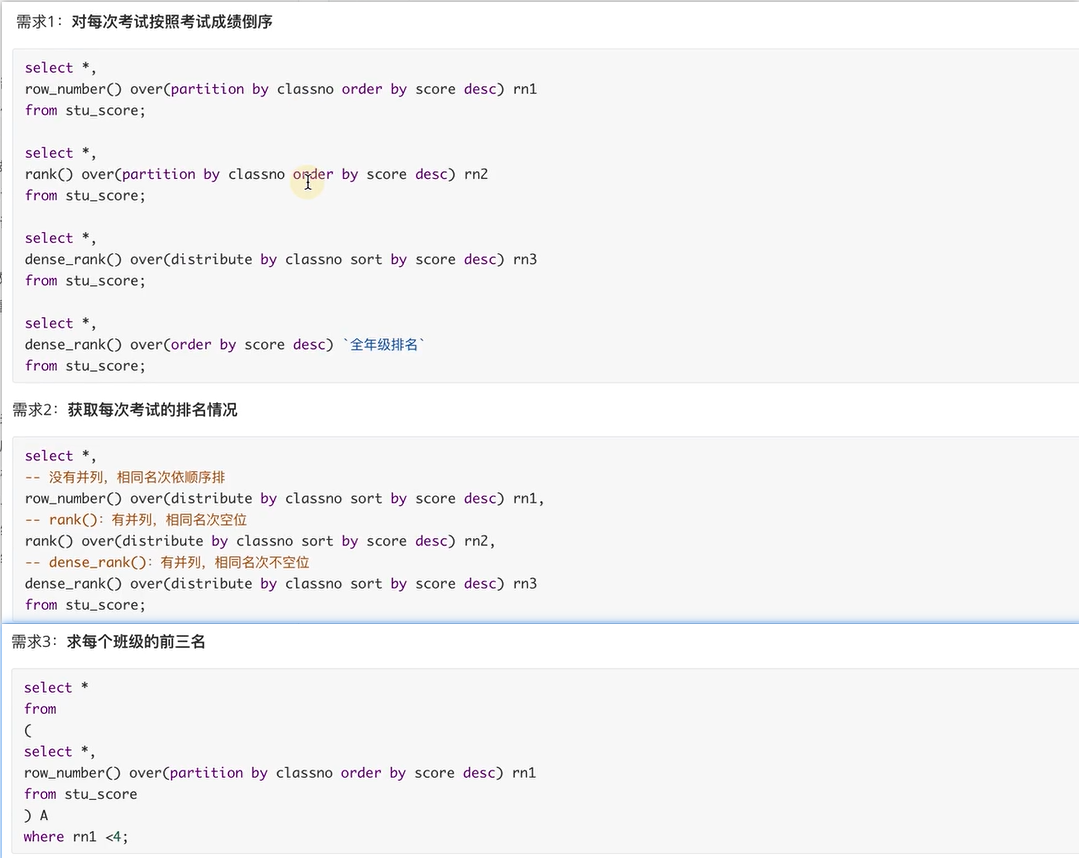
Ranking function of hive

Prepare data stu_score.txt

create table if not exists stu_score(
userid int,
classno string,
score int
)
row format delimited
fields terminated by ' ';
local data inpath './root/stu_score.txt' overwrite into table stu_score;
Custom UDF functions for hive
introduce

case
idea maven project HiveFunction adds the following maven dependency packages in pom.xml
<property>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.1.1</version>
</property>
Write a class ConcatString
public class ConcatString extends UDF{
public String evaluate(String str){
return str+"!";
}
}
be careful
1.inherit org.apache.hadoop.hive.al.exec.UDF 2.to write evaluate(),This method is not defined by the interface,Because of the number of parameters it can accept,Data types are uncertain. Hive Will check UDF ,See if you can find a match for the function call evaluate()method
First: Command loading (only valid for the current session)
Package double click package
HiveFunction-1.0.jar
Upload it
[root@tianqinglong01 ~]# mv HiveFunction-1.0.jar function.jar
# Package and upload the prepared UDF to the server, and add the jar package to hive's classpath
hive> add jar /root/function.jar
hive> create temporary function my_concot_str as 'com.qf.ConcatString'; #Create a custom snack function name
hive > show functions; # View the custom functions we created
hive > select my_concot_str("hello") # Use the function to return hello!
# Delete custom function
hive> drop temporary function if exists my_concot_str;
The second method: loading the configuration file (functions will be loaded whenever you start with the hive command line)
1,Upload the prepared self-defined function to the server 2,stay hive Under the installation directory of bin Create a file in the directory named.hiverc [root@tianqinglong01 hive]#vi ./bin/.hiverc 3,Write the statement to add the function to this file vi $HIVE_HOME/bin/.hiverc add jar /root/function.jar create temporary function my_concot_str as 'com.qf.ConcatString'; 4,Direct start hive jar Generally placed in lib Directory