02 introduction to deep learning
What is the field of perception: the stage at which people can quickly perceive and process (English to Chinese).
Deep learning, computer vision and natural language processing are the three largest contents in the field of AI.

Application of deep learning
- Image classification (IMAGENET), at present, the error of image classification can be comparable to the accuracy of human beings
- Object detection and segmentation (Mask_RCNN)
- Style transfer (mxnet style transfer)
- Face synthesis (2018)
- Text generated picture (openai)
- Text generation (gpt3)
- Driverless
- Advertising recommendation (the following is a small case)
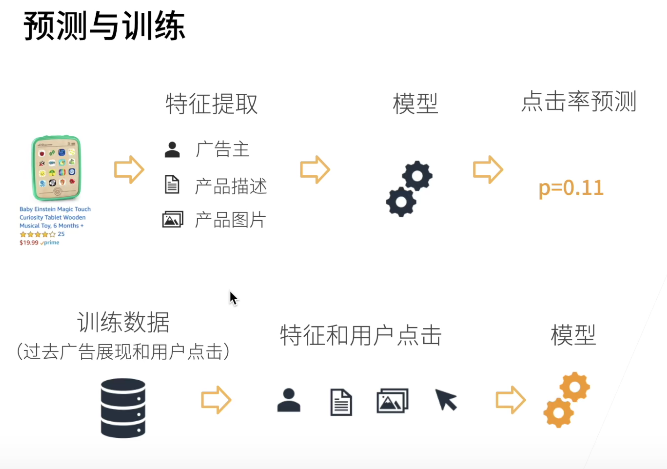
There are three types of people in machine learning: business domain experts, data scientists and AI experts
03 hands on learning - Installation
- windows installation reference: (thank you for stepping on the pit)
https://blog.csdn.net/qq_38311396/article/details/120768038
It should be noted that pandas software does not need to pay special attention to their version (the new setup.py does not say the version. In fact, most computers will automatically find the version that depends on ok. If the version is wrong, they will also help you remove and reinstall the correct version). Then, after each installation, import it to see if it is successful. I installed torch myself.
04 data operation
Data dimension: scalar (0-D), vector (1-D) and matrix (2-D), picture (3-D), batch picture (4-D), batch video (5-D, and video)

The colon in the picture represents an area.
Tensors represent an array of values that may have multiple dimensions. n-dimensional arrays are generally expressed as ndarray or tensor
# Creation and use of tensors import torch x = torch.arrage(12) #Create row vector x.shape #shape x.numel #Total elements X = x.reshape(3,4) #Change the shape without changing the number and value of elements torch.zeros((2,3,4)) #Create all 0, create all 1 is ones, which is a three-dimensional array torch.randn(3, 4) #Create random number array
Operation between tensors:
torch.tensor([[1,2,3,4],[1,2,4,3]]) #Tell the list of each row and change the dimension through [] x = torch.tensor([1.0,2,4,8]) #The common standard arithmetic symbol operation (+ - * /) can be upgraded to operation by element, and * * is power operation y = torch.tensor([2,2,2,2]) x + y, x -y, x* y torch.exp(x) # Exponentiation operation X = torch.arange(12, dtype=torch.float32).reshape((3,4)) Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]]) torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1) # Combine multiple tensors. The former is 0-dimensional addition, that is, x rows are stacked together, and the latter is 1-dimensional addition, that is, y columns are stacked together. Because there are only two dimensions here, an error will be reported if dim = 2 X == Y # Determine whether the elements at each position in the tensor are equal X.sum() # Sum all elements in the tensor to produce a single element tensor
Broadcasting mechanism
Even if the shapes are different, we can still perform the operation by element by calling the broadcasting mechanism
a = torch.arange(3).reshape((3, 1)) b = torch.arange(2).reshape((1, 2)) a, b a + b # At this time, although the shapes are different, the heap shape will be assigned and converted automatically
Indexing and slicing
X[-1], X[1:2] # The former selects the last element and the latter selects the second element. Note that the second and third elements are selected because there is a difference of 2 between [1:3] X[1, 2] = 9 # Elements in the second row and third column X[0:2, :] = 12 # All elements of the first and second lines
Save memory
Running some operations may cause memory allocation for new results, which can be solved by using slicing
before = id(Y)
Y = Y + X
id(Y) == before # At this time, Y is a new Y
Z = torch.zeros_like(Y) # Using zeros_like to allocate a block of all zeros
print('id(Z):', id(Z))
Z[:] = X + Y #Slicing operation, you can assign the result of the operation to the previously allocated array
print('id(Z):', id(Z))
Convert to python object
This refers in particular to the conversion to ndarray in NumPy
A = X.numpy() # The format of A becomes ndarray a = torch.tensor([3.5]) a.item() # The tensor of size 1 is transformed into python scalar and can be used for subsequent use
04-2 data preprocessing
The panda package is usually used to preprocess raw data, which is compatible with tensors
Read dataset
# Create a manual dataset and store it in a csv file
import os
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f: #Write data
f.write('NumRooms,Alley,Price\n') # Listing
f.write('NA,Pave,127500\n') # Each row represents a data sample
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
Then use pandas's read_csv function to load the dataset:
import pandas as pd data = pd.read_csv(data_file) print(data)
Processing missing data
Typical methods include interpolation and deletion
# Interpolation method: inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2] #The data is divided into input (the first two columns) and output (the last column). idex_location is the location index inputs = inputs.fillna(inputs.mean()) # For all inputs that are NaN, replace na (fillna) with the mean of this column # For category values or discrete values in inputs, we regard "NaN" as a category, except that category "Pave" is category "Nah", so the final result can be replaced with 0 or 1 inputs = pd.get_dummies(inputs, dummy_na=True) # Two classes, if it is pave, it is 1, otherwise it is 0 print(inputs)
Convert to tensor format
Now all entries in inputs and outputs are numeric types, which can be converted to tensor format and then manipulated using tensor functions.
import torch X, y = torch.tensor(inputs.values), torch.tensor(outputs.values) #The default is 64 bit floating point number X, y