1, Hive table structure
Format for creating table:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
(
col1Name col1Type [COMMENT col_comment],
co21Name col2Type [COMMENT col_comment],
co31Name col3Type [COMMENT col_comment],
co41Name col4Type [COMMENT col_comment],
co51Name col5Type [COMMENT col_comment],
......
coN1Name colNType [COMMENT col_comment]
)
[PARTITIONED BY (col_name data_type ...)] --Partition table structure
[CLUSTERED BY (col_name...) [SORTED BY (col_name ...)] INTO N BUCKETS] --Bucket table structure
[ROW FORMAT row_format] -- Specifies the delimiter for the data file
row format delimited fields terminated by 'Column separator' -- Column separator, default to\001
lines terminated by 'Line separator' --Line separator, default\n
[STORED AS file_format] -- Specifies the storage format of the file
[LOCATION hdfs_path] -- Used to specify the location of the table directory. The default table directory is under the database directory
1. Common table structure
MapReduce processing rules:
Step 1: retrieve the metadata and find the HDFS directory corresponding to the table
Step 2: take the last level directory of the table as the input of MapReduce program
Structure:
Hive Data warehouse directory/Database directory/Table of contents/data file
characteristic:
The directory at the last level of the table is the directory of the table
Question: if it is an ordinary table structure, manually put the file into the table directory through the HDFS command. Can you read it in the table?
Yes, because the last level directory of the table is an ordinary directory, it can be read in the table
Application:
The tables created by default are of normal table structure
It is generally used to build the original data file into a table structure
2. Partition table structure
Common table structure problem?
A large number of meaningless filtering operations need to be done in the Map stage, resulting in a waste of resources
2.1 design of partition table structure
Design idea:
Divide the data into different directories according to certain rules and conditions for partition storage
When querying, you can filter at the directory level according to the query criteria, and MapReduce directly loads the directory of the data to be processed
Essence:
Divide the data into different directories for storage in advance
Reduce the amount of input data of the underlying MapReduce through query conditions, avoid useless filtering and improve performance
Structure:
Data warehouse directory/Database directory/Table of contents/Partition directory/Partition data file
characteristic:
The last level directory of the table is the partition directory
Application:
Most commonly used table: partitioned external table
Partition: it is generally divided according to time
2.2 implementation of partition table structure:
1. Static partition
The data file itself is planned according to the partition. Directly create the partition table and load the data of each partition
Step 1: create partition table directly
Step 2: load each file into the corresponding partition
Create partition table:
create table tb_emp_part1( empno string, ename string, job string, managerno string, hiredate string, salary double, jiangjin double, deptno string ) partitioned by (department int) row format delimited fields terminated by '\t';
Load the corresponding data file to the corresponding partition
load data local inpath '/export/data/emp10.txt' into table tb_emp_part1 partition (department=10); load data local inpath '/export/data/emp10.txt' into table tb_emp_part1 partition (department=20); load data local inpath '/export/data/emp10.txt' into table tb_emp_part1 partition (department=30);
Test SQL execution plan: explain
General table:
explain extended select count(*) as numb from tb_emp where deptno = 20;
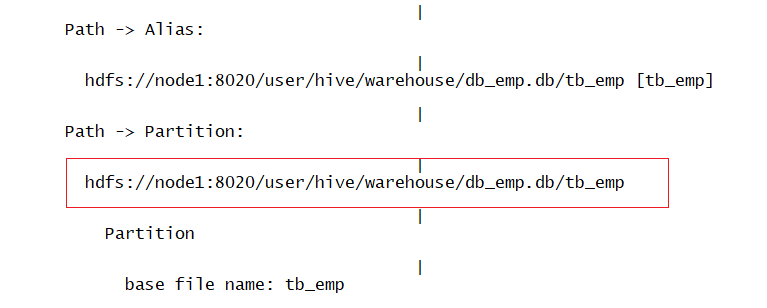
Partition table:
explain extended select count(*) as numb from tb_emp_part1 where department = 20;

View metadata:
PARTITIONS

SDS

2. Dynamic zoning
The data itself is not divided according to the partition rules, and it needs to be automatically and dynamically divided by program
Steps:
Step 1: first create a common table and load the overall data
tb_emp: common table. The employee information of all departments is in one directory file
#1. Create employee table create database db_emp; use db_emp; create table tb_emp( empno string, ename string, job string, managerid string, hiredate string, salary double, jiangjin double, deptno string ) row format delimited fields terminated by '\t'; #2. Load data load data local inpath '/export/data/emp.txt' into table tb_emp;
Step 2: create partition table
create table tb_emp_part2( empno string, ename string, job string, managerno string, hiredate string, salary double, jiangjin double ) partitioned by (dept string) row format delimited fields terminated by '\t';
Enable dynamic partition:
set hive.exec.dynamic.partition.mode=nonstrict;
step3: write the data of ordinary table into partition table to realize dynamic partition
insert into table tb_emp_part2 partition(dept) select ......,deptno from tb_emp ;
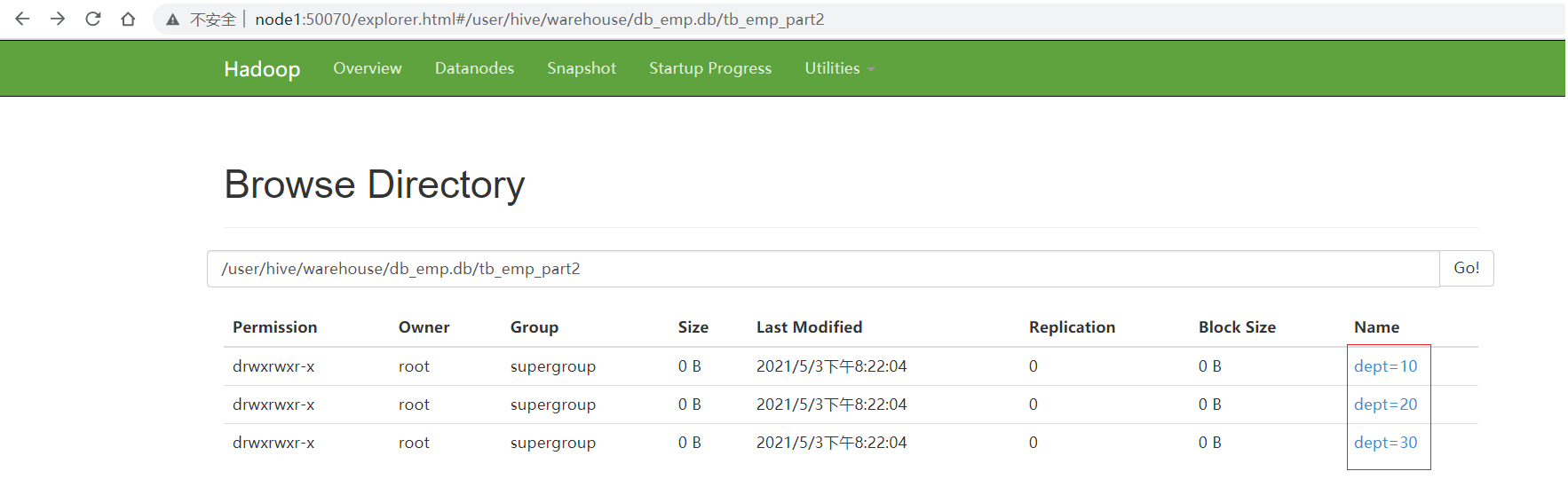

Requirement: generally, select * is not required for query statements, and the last field of query statements is required to be the partition field
3. Multi level zoning
Create multi-level partition table
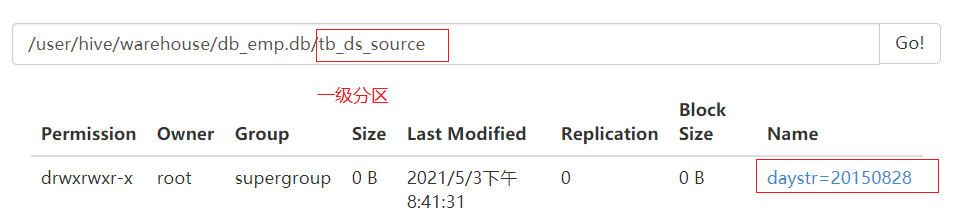
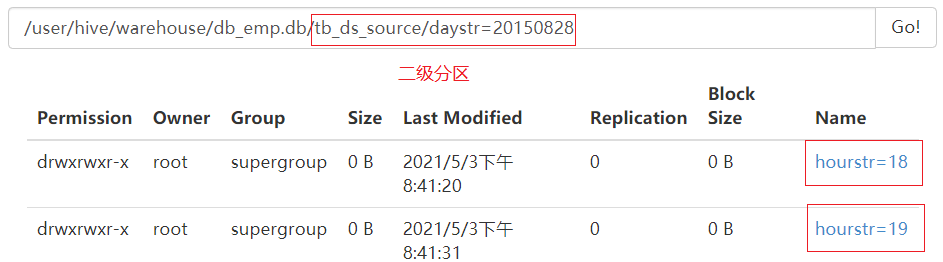
create table tb_ds_source( id string, url string, referer string, keyword string, type string, guid string, pageId string, moduleId string, linkId string, attachedInfo string, sessionId string, trackerU string, trackerType string, ip string, trackerSrc string, cookie string, orderCode string, trackTime string, endUserId string, firstLink string, sessionViewNo string, productId string, curMerchantId string, provinceId string, cityId string, fee string, edmActivity string, edmEmail string, edmJobId string, ieVersion string, platform string, internalKeyword string, resultSum string, currentPage string, linkPosition string, buttonPosition string ) partitioned by (daystr string,hourstr string) row format delimited fields terminated by '\t';
Load multi-level partition data
load data local inpath '/export/data/2015082818' into table tb_ds_source partition (daystr='20150828',hourstr='18'); load data local inpath '/export/data/2015082819' into table tb_ds_source partition (daystr='20150828',hourstr='19');
View partition Directory:
show partitions tb_ds_source;

Partitions are directory level. A directory represents a partition
Name of directory: partition field = value of partition
The fields of the partition are logical
3. Bucket table structure
1.Join's questions
Map Join: good performance, suitable for small tables and large tables
Reduce Join: it is realized through the grouping of Shuffle. It is suitable for large tables to join large tables
2. Barrel separation design
Idea: divide large data into multiple small data according to rules, and each small data goes through Map Join to reduce the comparison times of each data and improve performance
Function: optimize the problem of large table join, and sample by bucket
Essence: divide the data into multiple files through the partition [partition rules of Reduce] at the bottom of MapReduce
Each file = each bucket = each Reduce
Division rule: Hash remainder
Bucket table fields are physical
Bucket table is a file level design
The data of bucket splitting table cannot be loaded with load
Structure:
Data warehouse directory/Database directory/Table of contents/File data by bucket
Divide the two large tables into buckets according to the same rules to realize bucket sharing Join. Map Join is directly performed between buckets to reduce the number of comparisons and improve performance
technological process:
step1: divide the two tables into buckets
Implementation: bucket 2
Hive will automatically judge whether the conditions for bucket splitting Join are met. If so, bucket splitting Join will be realized automatically
3. Realization of barrel separation
Syntax:
clustered by col [sorted by col] into N buckets clustered by : According to which column are barrels divided sorted by: In which column is the interior of each bucket sorted N: Divided into several buckets, there are several data written on behalf of the bottom layer reduce
Open configuration
set hive.optimize.bucketmapjoin = true; set hive.optimize.bucketmapjoin.sortedmerge = true;
Create bucket table
create table tb_emp_bucket( empno string, ename string, job string, managerno string, hiredate string, salary double, jiangjin double, deptno string ) clustered by (deptno) into 3 BUCKETS row format delimited fields terminated by '\t';
Write bucket table
insert overwrite table tb_emp_bucket select * from tb_emp cluster by (deptno);
2, Join in Hive
1.inner join: inner join
select a.empno, a.ename, b.deptno, b.dname from tb_emp a join tb_dept b on a.deptno = b.deptno;
Features: there are results on both sides
2.left outer join: left outer join
select a.empno, a.ename, b.deptno, b.dname from tb_emp a left join tb_dept b on a.deptno = b.deptno;
Features: there are on the left, and there are results
3.right outer join: right outer join
select a.empno, a.ename, b.deptno, b.dname from tb_emp a right join tb_dept b on a.deptno = b.deptno;
Features: there are on the right, and there are results
4.full join: full join
select a.empno, a.ename, b.deptno, b.dname from tb_emp a full join tb_dept b on a.deptno = b.deptno;
5.map join
Features: put the data of the small table into the distributed cache and Join with each part of the large table. It occurs on the Map side without shuffling
Scenario: small table join small table, small table join large table
Requirement: one table must be a small table
Implementation rules:
By default, Hive will give priority to judging whether the conditions of Map Join are met
File size of judgment table: less than 25MB
If satisfied, go to Map Join automatically
If it does not meet the requirements, it will automatically go to Reduce Join
6.Reduce Join
Features: using Shuffle grouping to realize the Join process, which takes place at the Reduce end and needs to go through Shuffle
Scenario: join large table
Requirement: Hive defaults to Reduce Join automatically if Map Join is not satisfied
7.Bucket Join
Features: divide large data into multiple small data, each small data is a bucket, and realize bucket join
Scenario: join large tables. Optimize this process if you join multiple times
requirement:
Bucket Map Join: an ordinary bucket join
Both tables are bucket tables. The number of buckets is a multiple, and the Join field = bucket field
Bucket Sort Merge Map Join: Bucket Sort Merge Map Join based on sorting
Both tables are bucket tables
The number of barrels is multiple
Join field = bucket sorting field = sorting field
3, Select syntax: order by and sort by
1. Number of ReduceTask in hive
Number of reduce tasks not specified. Estimated from input data size: 1 In order to change the average load for a reducer (in bytes):\ #Amount of data processed by each Reduce set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: #The maximum number of reduce allowed to start set hive.exec.reducers.max=<number> In order to set a constant number of reducers: #Set the number of reduce set mapreduce.job.reduces=<number>
#Specify the number of reduce as 2 set mapreduce.job.reduces=2;
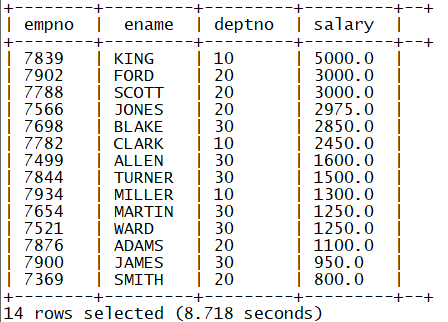
2.order by
Function: Global sorting
select empno,ename,deptno,salary from tb_emp order by salary desc;
Question: if there are more than one Reduce, can global sorting be realized?
There cannot be more than one reduce. If order by is used, only one reduce will be started
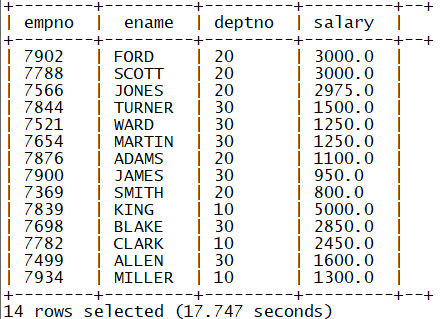
3.sort by
Function: local sorting
In multiple reduce scenarios, each reduce is orderly
select empno,ename,deptno,salary from tb_emp sort by salary desc;
Put the sql results into a file
insert overwrite local directory '/export/data/sort' row format delimited fields terminated by '\t' select empno,ename,deptno,salary from tb_emp sort by salary desc;

4. What are the functions and differences between order by and sort by?
order by: Global sort. There can only be one reduce
sort by: local sort, multiple reduce, local sort for each reduce
4, Select syntax: distribute by and cluster by
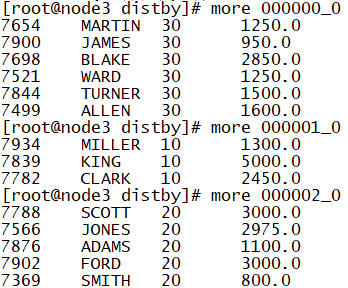
1.distribute by
Function: specify a field as k2 due to the intervention of the underlying MapReduce
#Specify the number of reduce as 3 set mapreduce.job.reduces=3;
insert overwrite local directory '/export/data/distby' row format delimited fields terminated by '\t' select empno,ename,deptno,salary from tb_emp distribute by deptno;
2. Use distribution by and sort by together
insert overwrite local directory '/export/data/distby' row format delimited fields terminated by '\t' select empno,ename,deptno,salary from tb_emp distribute by deptno sort by salary desc;
Application:
distribute by 1 => Used to put all data into one Reduce in distribute by rand() => Realize random partition to avoid data skew
3.cluster by
Function: if distribute by And sort by Is the same field and can be used cluster by replace
5, Data type: Array
1. Generate data
#1. Create an array txt vim /export/data/array.txt #2. Add data zhangsan beijing,shanghai,tianjin wangwu shanghai,chengdu,wuhan,haerbin
2. Create table
#1. Create db_complex database create database db_complex; use db_complex; #2. Create a complex_array table create table if not exists complex_array( name string, work_locations array<string> ) row format delimited fields terminated by '\t' COLLECTION ITEMS TERMINATED BY ',';
COLLECTION ITEMS TERMINATED BY ‘,’ ; Used to specify the separator for each element in the array
3. Load data
load data local inpath '/export/data/array.txt' into table complex_array;
4. Take out the required data
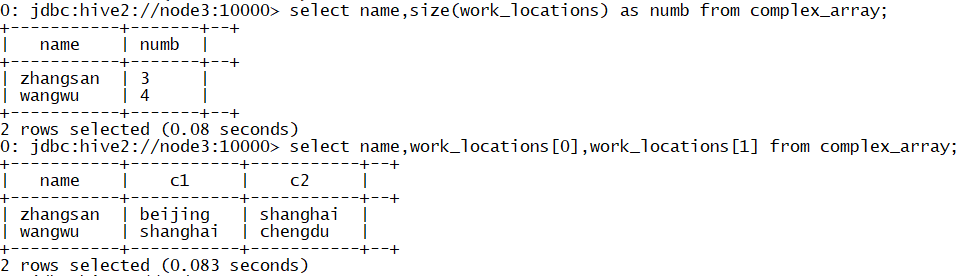
#1. Count the number of cities each user has worked in select name,size(work_locations) as numb from complex_array; #2. Take out the individual elements in the array select name,work_locations[0],work_locations[1] from complex_array;
6, Data type: Map
1. Generate data
#1. Create an amp txt vim /export/data/map.txt #2. Add data 1,zhangsan,sing:like it very much-dance:like-Swimming:So-so 2,lisi,Play games:like it very much-Basketball:dislike
2. Create table
create table if not exists complex_map( id int, name string, hobby map<string,string> ) row format delimited fields terminated by ',' COLLECTION ITEMS TERMINATED BY '-' MAP KEYS TERMINATED BY ':';
COLLECTION ITEMS TERMINATED BY '-'
Used to divide each KV pair
MAP KEYS TERMINATED BY ':';
User divided K and V
3. Load data
load data local inpath '/export/data/map.txt' into table complex_map;
4. Take out the required data
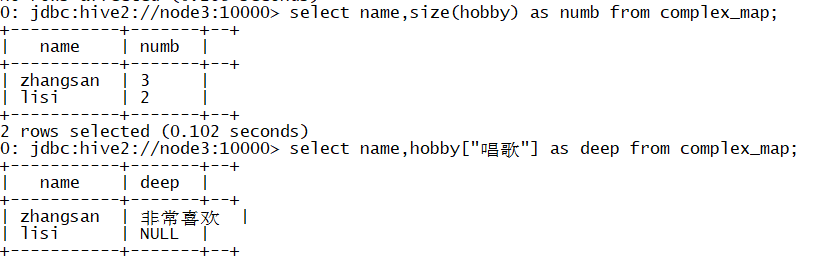
#1. Count how many hobbies everyone has select name,size(hobby) as numb from complex_map; #2. Take out everyone's preference for singing select name,hobby["sing"] as deep from complex_map;
7, Regular loading
Hive does not support multi byte delimiters
1. Separator problem
Separator for columns in data||
The delimiters of each column in the data are inconsistent
The data field contains delimiters
2. Treatment scheme
Scheme 1: first do ETL, first develop a program to realize data processing, and then load the processing results into Hive table
Replace separator by program
Scheme 2: Hive officially provides a regular loading method
Regular expressions are used to match each column in each piece of data
3. Regular loading
Generate data
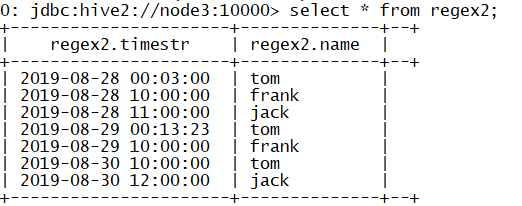
#1. Create a regex txt vim /export/data/regex.txt #2. Add data 2019-08-28 00:03:00 tom 2019-08-28 10:00:00 frank 2019-08-28 11:00:00 jack 2019-08-29 00:13:23 tom 2019-08-29 10:00:00 frank 2019-08-30 10:00:00 tom 2019-08-30 12:00:00 jack
Create table
Normal creation
#1. Create table regex1 create table regex1( timestr string, name string ) row format delimited fields terminated by ' '; #2. Load data load data local inpath '/export/data/regex.txt' into table regex1;
Regular loading
#1. Create table regex2 create table regex2( timestr string, name string ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ( "input.regex" = "([^}]*) ([^ ]*)" ) STORED AS TEXTFILE; #2. Load data load data local inpath '/export/data/regex.txt' into table regex2;
8, Functions in Hive: built in functions
#1. View functions show functions; #2. Check function usage desc function [extended] funName; #3. Common functions #3.1 aggregate function count,sum,avg,max,min #3.2 conditional function if,case when #3.3 string function intercept: substring,substr Splicing: concat,concat_ws division: split Find: instr Replace: regex_replace Length: length #3.4 date function transformation: unix_timestamp,from_unixtime Date: current_date,date_sub,date_add obtain: year,month,day,hour #4. Special functions JSON: json_tuple,get_json_object URL: parse_url,parse_url_tuple Window function: Aggregation window: sum,count...... Location window: lag,lead,first_value,last_value Analysis function: row_number,rank,dense_rank
9, Functions in Hive: custom functions
1. Function classification
UDF: one-to-one function, similar to substr
UDAF: many to one function, similar to aggregate function: count
UDTF: one to many function, expand turns each element in a row into a row
2. User defined UDF function
Demand: 24 / DEC / 2019:15:55:01 - > 2019-12-24 15:55:01
step1: customize a class and inherit UDF class
Step 2: implement at least one evaluate method in the class to define the logic for processing data
step3: make a jar package and add it to hive's environment variable
add jar /export/data/udf.jar;
step4: register the class as a function
create temporary function transFDate as 'com.miao.hive.udf.UserUDF';
Step 5: call function
select transFDate("24/Dec/2019:15:55:01");
3. Customize UDAF and UDTF
UDAF
Step 1: register the class as a function
create temporary function userMax as 'com.miao.hive.udaf.UserUDAF';
Step 2: call function
select userMax(cast(deptno as int)) from db_emp.tb_dept;
Cast: cast function
cast(column as type)
UDTF
Step 1: register the class as a function
create temporary function transMap as 'com.miao.hive.udtf.UserUDTF';
Step 2: call function
select transMap("uuid=root&url=www.taobao.com") as (userCol1,userCol2);
10, Functions in Hive: parse_url_tuple
#1. Create lateral Txt file vim /export/data/lateral.txt #2. Add data 1 http://facebook.com/path/p1.php?query=1 2 http://www.baidu.com/news/index.jsp?uuid=frank 3 http://www.jd.com/index?source=baidu #3. Create table create table tb_url( id int, url string ) row format delimited fields terminated by '\t'; #4. Load data load data local inpath '/export/data/lateral.txt' into table tb_url;
1.parse_url: used to parse URLs. Only one element can be parsed at a time
2.parse_url_tuple: used to parse URLs. It is a UDTF function that parses multiple elements at a time
3. Syntax:
select parse_url(url,'HOST') from tb_url; select parse_url(url,'PATH') from tb_url; select parse_url(url,'QUERY') from tb_url; select parse_url_tuple(url,'HOST','PATH','QUERY') from tb_url;
11, Function in Hive: lateral view
1.UDTF function problem
udtf can only be used directly in select, can not be used by adding other fields, can not be nested calls, and can not be used together with group by/cluster by/distribute by/sort by
2.lateral view
When used in combination with UDTF function, the result of UDTF function is transformed into a table similar to the view, which is convenient to operate with the original table
Syntax:
select ...... from tabelA lateral view UDTF(xxx) alias as col1,col2,col3......
12, Functions in Hive: explode
1. Expand function
Turns each element of a collection in a collection type into a row
Syntax:
explode( Map | Array)
2. Usage
Use alone
select explode(work_locations) as loc from complex_array; select explode(hobby) from complex_map;
Use with side view
select a.id, a.name, b.* from complex_map a lateral view explode(hobby) b as hobby,deep;