Enterprise level tuning
Explain
Basic grammar
EXPLAIN [EXTENDED | DEPENDENCY | AUTHORIZATION] query
Case practice
(1) View the execution plan of the following statement
No MR task was generated
hive (default)> explain select * from emp;
OK
Explain
STAGE DEPENDENCIES:
Stage-0 is a root stage // A stage
STAGE PLANS:
Stage: Stage-0
Fetch Operator // Grab operation
limit: -1
Processor Tree:
TableScan
alias: emp // The alias of the table. If not, it is the table name
Statistics: Num rows: 1 Data size: 6570 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: empno (type: int), ename (type: string), job (type: string), mgr (type: int), hiredate (type: string), sal (type: double), comm (type: double), deptno (type: int) // Fields to query
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7
Statistics: Num rows: 1 Data size: 6570 Basic stats: COMPLETE Column stats: NONE
ListSink
Time taken: 1.192 seconds, Fetched: 17 row(s)
Have the ability to generate MR tasks
hive (default)> explain select deptno, avg(sal) avg_sal from emp group by deptno;
OK
Explain
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1 // Two phases, phase 0 depends on Phase 1
STAGE PLANS:
Stage: Stage-1 // Phase 1 is a MapReduce
Map Reduce
Map Operator Tree: // Map operation
TableScan
alias: emp // Alias of the table processed by the map phase
Statistics: Num rows: 1 Data size: 6570 Basic stats: COMPLETE Column stats: NONE
Select Operator // Query operation
expressions: sal (type: double), deptno (type: int)
outputColumnNames: sal, deptno
Statistics: Num rows: 1 Data size: 6570 Basic stats: COMPLETE Column stats: NONE
Group By Operator // groupBy operation
aggregations: sum(sal), count(sal) // Group content
keys: deptno (type: int) // Grouped key
mode: hash
outputColumnNames: _col0, _col1, _col2
Statistics: Num rows: 1 Data size: 6570 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 1 Data size: 6570 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: double), _col2 (type: bigint)
Execution mode: vectorized
Reduce Operator Tree: // Reduce operation
Group By Operator
aggregations: sum(VALUE._col0), count(VALUE._col1)
keys: KEY._col0 (type: int)
mode: mergepartial
outputColumnNames: _col0, _col1, _col2 // Output three fields
Statistics: Num rows: 1 Data size: 6570 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), (_col1 / _col2) (type: double) // Average
outputColumnNames: _col0, _col1
Statistics: Num rows: 1 Data size: 6570 Basic stats: COMPLETE Column stats: NONE
File Output Operator // Write operation
compressed: false
Statistics: Num rows: 1 Data size: 6570 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0 // Phase 0, grab operation
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 1.68 seconds, Fetched: 53 row(s)
(2) View detailed execution plan
hive (default)> explain extended select * from emp; hive (default)> explain extended select deptno, avg(sal) avg_sal from emp group by deptno;
Fetch grab
Fetch fetching means that some queries in Hive do not need to be calculated by MapReduce.
For example: SELECT * FROM employees; In this case, Hive can simply read the files in the storage directory corresponding to the employee, and then output the query results to the console.
In hive default xml. Hive. In template file fetch. task. Conversion defaults to more, and the old version of hive defaults to minimal,
After the attribute is changed to more, mapreduce will not be used in global search, field search, limit search, etc.
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
<description>
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have any aggregations or distincts (which incurs RS), lateral views and joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)
</description>
</property>
Local mode
Most Hadoop jobs need the complete scalability provided by Hadoop to handle large data sets. However, sometimes Hive's input data volume is very small. In this case, it may take much more time to trigger the execution task for the query than the execution time of the actual job. For most of these cases, Hive can handle all tasks on a single machine through local mode.
For small data sets, the execution time can be significantly reduced.
Users can set Hive exec. mode. local. The value of auto is true to let Hive automatically start the optimization when appropriate.
//Turn on local mr, and the default is false, which is the cluster mode set hive.exec.mode.local.auto=true; //Set the maximum input data amount of local mr. when the input data amount is less than this value, the mode of local mr is adopted. The default is 134217728, i.e. 128M set hive.exec.mode.local.auto.inputbytes.max=50000000; //Set the maximum number of input files of local mr. when the number of input files is less than this value, the local mr mode is adopted, and the default is 4 set hive.exec.mode.local.auto.input.files.max=10;
When the amount of data is small and there are few data files, the local mode can be used. After startup, it will directly use the local Hadoop node, which is equivalent to a single machine. In production mode, the local mode is generally not used.
Table optimization
Small table large table Join(MapJOIN)
Put the tables with relatively scattered key s and small amount of data on the left of the join. You can use map join to make the small dimension tables advance into memory. Complete the join on the map side.
The actual test shows that the new version of hive has optimized the small table JOIN large table and large table JOIN small table. There is no difference between the small table on the left and the right.
mapJoin, that is, in the map phase, the small table is loaded into memory. When joining, the data is directly obtained from memory. The join can be completed on the map side without reducing.
Enable MapJoin parameter setting
(1)Set automatic selection Mapjoin,Default to true set hive.auto.convert.join = true; (2)Threshold setting for large and small tables(Default 25 M The following are considered small tables): set hive.mapjoin.smalltable.filesize = 25000000;
MapJoin working mechanism
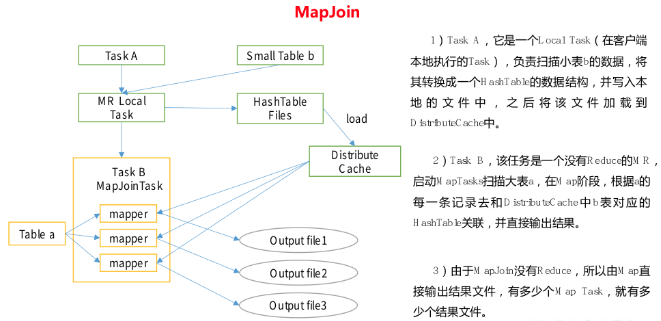
Large table Join large table
Empty KEY filtering
Sometimes the join timeout occurs because there are too many data corresponding to some keys, and the data corresponding to the same key will be sent to the same reducer, resulting in insufficient memory. At this time, we should carefully analyze these abnormal keys. In many cases, the data corresponding to these keys are abnormal data, and we need to filter them in SQL statements.
The test is not empty id hive (default)> insert overwrite table jointable select n.* from nullidtable n left join bigtable o on n.id = o.id; Test filter empty id hive (default)> insert overwrite table jointable select n.* from (select * from nullidtable where id is not null) n left join bigtable o on n.id = o.id;
During MapJoin, null value filtering will be performed automatically.
Inner join will also automatically filter null values.
Usage scenario of empty key filtering:
1. Non inner join
2. A null field is not required
It's best to filter first and then join
Empty key conversion
Sometimes, although a key is empty, there are many corresponding data, but the corresponding data is not abnormal data and must be included in the join result. At this time, we can assign a random value to the field with empty key in table a, so that the data can not be randomly and evenly distributed to different reducer s.
When null is in multiple partitions, the data with null key will be placed in the same partition, resulting in data skew. Therefore, null needs to be evenly divided into different reducer s through random values.
When a random number is given, the same value as the original key cannot be given.
SMB(Sort Merge Bucket join) bucket sharing table
When dividing buckets, buckets are divided according to the join field, and the number of buckets is the same, then those with the same join field will be placed in the same bucket; Therefore, the data in each bucket will only correspond to the data in the other bucket, and the join will have results.
The number of buckets should not exceed the number of available CPU cores, so that all tasks will be executed in parallel and the efficiency will be the highest.
Create tap Table 1,The number of barrels should not exceed the available CPU Kernel number of
create table bigtable_buck1(
id bigint,
t bigint,
uid string,
keyword string,
url_rank int,
click_num int,
click_url string
)
clustered by(id)
sorted by(id)
into 6 buckets
row format delimited fields terminated by '\t';
Create tap Table 2,The number of barrels should not exceed the available CPU Kernel number of
create table bigtable_buck2(
id bigint,
t bigint,
uid string,
keyword string,
url_rank int,
click_num int,
click_url string
)
clustered by(id)
sorted by(id)
into 6 buckets
row format delimited fields terminated by '\t';
Set parameters
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
test
insert overwrite table jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable_buck1 s
join bigtable_buck2 b
on b.id = s.id;
Bucket table is often used in big data join, and the efficiency is obviously improved.
Group By
By default, the same key data in the Map phase is distributed to a reduce. When a key data is too large, it will tilt.
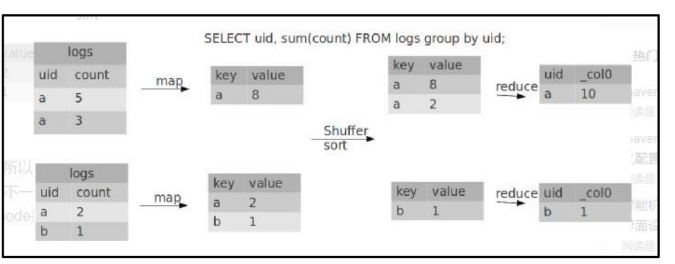
Not all aggregation operations need to be completed on the Reduce side. Many aggregation operations can be partially aggregated on the Map side first, and finally the final result can be obtained on the Reduce side.
1) Enable aggregation parameter setting at Map end
(1)Is it Map End polymerization,Default to True set hive.map.aggr = true (2)stay Map Number of entries for aggregation at the end set hive.groupby.mapaggr.checkinterval = 100000 (3)Load balancing when there is data skew(The default is false) set hive.groupby.skewindata = true
When the option is set to true, the generated query plan will have two Mr Jobs.
In the first MR Job, the output results of the Map will be randomly distributed to Reduce. Each Reduce performs some aggregation operations and outputs the results. The result of this processing is that the same Group By Key may be distributed to different Reduce, so as to achieve the purpose of load balancing;
The second MR Job is distributed to Reduce according to the Group By Key according to the preprocessed data results (this process can ensure that the same Group By Key is distributed to the same Reduce), and finally complete the final aggregation operation.
hive (default)> set hive.groupby.skewindata = true; hive (default)> select deptno from emp group by deptno;
Count(Distinct) de duplication statistics
It doesn't matter when the amount of data is small. When the amount of data is large, because the COUNT DISTINCT operation needs to be completed with a Reduce Task, the amount of data that needs to be processed by this Reduce is too large, which will make the whole Job difficult to complete,
Generally, COUNT DISTINCT is replaced by group by and then COUNT, but attention should be paid to the data skew caused by group by
Perform de duplication id query hive (default)> select count(distinct id) from bigtable; Set 5 reduce number hive (default)> set mapreduce.job.reduces = 5; use GROUP by duplicate removal id hive (default)> select count(id) from (select id from bigtable group by id) a;
Although it will be completed with one more Job, it is definitely worth it in the case of a large amount of data.
This is not necessary when the amount of data is small, because the cost of starting the task will be greater; Optimization can only be seen when there is a large amount of data.
Cartesian product
Try to avoid Cartesian product. join without on condition or invalid on condition. Hive can only use one reducer to complete Cartesian product.
Row column filtering
Column processing: in SELECT, only the required columns are taken. If there are partitions, try to use partition filtering instead of SELECT *.
Row processing: in partition clipping, when external association is used, if the filter condition of the sub table is written after Where, the whole table will be associated first and then filtered
1)The test first associates two tables,Reuse where Conditional filtering
hive (default)> select o.id from bigtable b
join bigtable o on o.id = b.id
where o.id <= 10;
2)After sub query,Re association table
hive (default)> select b.id from bigtable b
join (select id from bigtable where id <= 10) o on b.id = o.id;
The execution results of the above two methods are similar, because sql will be optimized automatically,
In the first method, the O and B tables will be processed with < = 10. The o.id will be filtered because the predicates in sql are pushed down, filtered first, and then joined. The b.id will also be filtered because the field of join is ID; If you do not use the join field for filtering, advance filtering will not be performed.
The second method will also process the o and b tables < = 10 first.
Therefore, in order to prevent predicate pushdown failure, you'd better write your own filter conditions to filter.
partition
Separate barrel
Reasonably set the number of maps and Reduce
1) Typically, the job will generate one or more map tasks through the input directory.
The main determinants are: the total number of input files, the file size of input, and the file block size set by the cluster.
2) Is the more map s the better?
The answer is No. If a task has many small files (much smaller than the block size of 128m), each small file will also be treated as a block and completed by a map task. The start and initialization time of a map task is much longer than that of logical processing, which will cause a great waste of resources. Moreover, the number of maps that can be executed at the same time is limited.
3) Is it safe to ensure that each map handles nearly 128m file blocks?
The answer is not necessarily. For example, a 127m file is normally completed with a map, but the file has only one or two small fields, but there are tens of millions of records. If the logic of map processing is complex, it must be time-consuming to do it with a map task.
To solve the above problems 2 and 3, we need to take two ways: reducing the number of maps and increasing the number of maps;
Increase the number of maps for complex files
When the input files are large, the task logic is complex, and the map execution is very slow, you can consider increasing the number of maps to reduce the amount of data processed by each map, so as to improve the execution efficiency of the task.
The method of adding map is to adjust the maximum value of maxSize according to the formula of computeslatesize (math.max (minsize, math. Min (maxSize, blocksize)) = blocksize = 128M. If the maximum maxSize is lower than the block size, the number of maps can be increased.
set mapreduce.input.fileinputformat.split.maxsize=100;
Merge small files
1) Merge small files before map execution to reduce the number of maps: CombineHiveInputFormat has the function of merging small files (the system default format). HiveInputFormat does not have the ability to merge small files.
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
2) Merge small file settings at the end of map reduce:
stay map-only Merge small files at the end of the task,default true SET hive.merge.mapfiles = true; stay map-reduce Merge small files at the end of the task,default false SET hive.merge.mapredfiles = true; Size of merged files,Default 256 M SET hive.merge.size.per.task = 268435456; When the average size of the output file is less than this value,Start a separate map-reduce Task progress file merge SET hive.merge.smallfiles.avgsize = 16777216;
Reasonably set the number of Reduce
1) Method 1 for adjusting the number of reduce
(1)each Reduce The amount of data processed is 256 by default MB hive.exec.reducers.bytes.per.reducer=256000000 (2)Maximum per task reduce number,The default is 1009 hive.exec.reducers.max=1009 (3)calculation reducer Formula of number N=min(Parameter 2,Total input data/Parameter 1)
2) Method 2 for adjusting the number of reduce
stay hadoop of mapred-default.xml Modify in file Or set each job of Reduce number set mapreduce.job.reduces = 15;
3) The number of reduce is not the more the better
(1) Too much startup and initialization of reduce will also consume time and resources;
(2) In addition, there will be many output files according to the number of reduce files. If many small files are generated, there will be too many small files if these small files are used as the input of the next task;
These two principles should also be considered when setting the number of reduce:
Handle a large amount of data and use the appropriate number of reduce;
Make the amount of data processed by a single reduce task appropriate.
Parallel execution
Hive transforms a query into one or more stages. Such stages can be MapReduce stage, sampling stage, merging stage and limit stage. Or other stages that hive may need during execution. By default, hive executes only one phase at a time. However, a specific job may contain many phases, which may not be completely interdependent. That is, some phases can be executed in parallel, which may shorten the execution time of the whole job. However, if there are more phases that can be executed in parallel, the faster the job may complete.
By setting the parameter hive exec. If the parallel value is true, concurrent execution can be enabled. However, in a shared cluster, it should be noted that if there are more parallel phases in a job, the cluster utilization will increase.
//Open task parallel execution set hive.exec.parallel=true; //The maximum parallelism allowed for the same sql is 8 by default. set hive.exec.parallel.thread.number=16;
Of course, you have to have an advantage when the system resources are relatively idle. Otherwise, parallelism can't work without resources.
Strict mode
Hive can prevent some dangerous operations by setting strict mode:
1) Partitioned tables do not use partition filtering
Set hive strict. checks. no.partition. When filter is set to true, partition tables are not allowed to execute unless the where statement contains partition field filter conditions to limit the scope. In other words, users are not allowed to scan all partitions. The reason for this limitation is that usually partitioned tables have very large data sets and the data increases rapidly. Queries without partitioning restrictions can consume unacceptably large resources to process this table.
It is possible that global scanning will also be performed when there are partitions.
2) Use order by without limit filtering
Set hive strict. checks. orderby. When no.limit is set to true, the query using the order by statement must use the limit statement. In order to perform the sorting process, order by will distribute all the result data to the same Reducer for processing. Forcing the user to add this limit statement can prevent the Reducer from executing for a long time.
3) Cartesian product
Set Hive strict. checks. cartesian. When product is set to true * *, the query of Cartesian product will be restricted * *. Users who know a lot about relational databases may expect to use the where statement instead of the ON statement when executing JOIN queries, so that the execution optimizer of relational databases can efficiently convert the where statement into that ON statement. Unfortunately, Hive does not perform this optimization, so if the table is large enough, the query will become uncontrollable.
JVM reuse
When dealing with small files, you can use JVM reuse.