Reference article: https://www.cnblogs.com/qingyunzong/p/8746159.html
1, Composite data type
1,array: ARRAY<data_type>
2,map: MAP<primitive_type, data_type>
3,struct: STRUCT<col_name:data_type>
The available data are as follows:
1 huangbo guangzhou,xianggang,shenzhen a1:30,a2:20,a3:100 beijing,112233,13522334455,500 2 xuzheng xianggang b2:50,b3:40 tianjin,223344,13644556677,600 3 wangbaoqiang beijing,zhejinag c1:200 chongqinjg,334455,15622334455,20
Create table statement:
use class;
create table cdt(
id int,
name string,
work_location array<string>,
piaofang map<string,bigint>,
address struct<location:string,zipcode:int,phone:string,value:int>
)
row format delimited
fields terminated by "\t"
collection items terminated by ","
map keys terminated by ":"
lines terminated by "\n";Import data:
> load data local inpath "/home/hadoop/cdt.txt" into table cdt;
The query is displayed as follows:
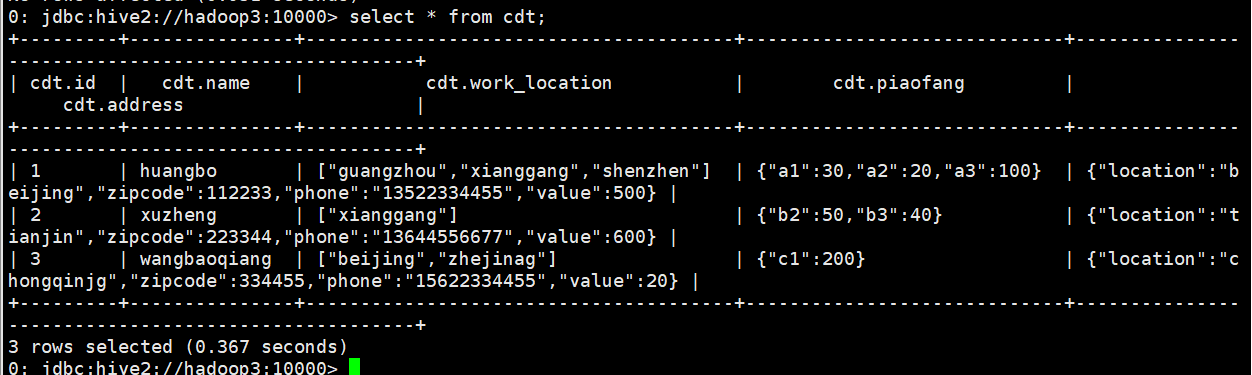
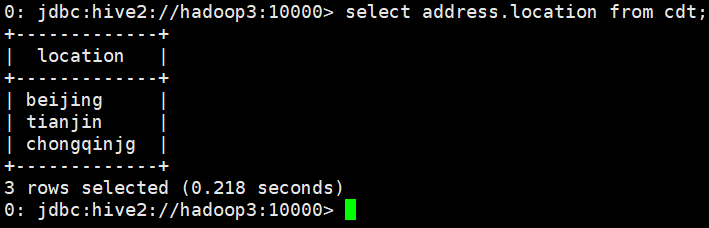
If you want to query a value under the address field, you can:
select address.location from cdt;
In this way, only one value under the field is displayed:
4,union: UNIONTYPE<data_type,data_type,...>
Union type can keep exactly one specified data type at the same time point. You can use create_ The UDF of union creates the type of an instance:
create table union_test(foo uniontype<int, double, array<string>, struct<a:int,b:string>>);
select foo from union_test;
{0:1}
{1:2.0}
{2:["three","four"]}
{3:{"a":5,"b":"five"}}
{2:["six","seven"]}
{3:{"a":8,"b":"eight"}}
{0:9}
{1:10.0} In the result of the query, the first part is a tag for the deserialization of the union to let it know which part of the union is used. The sequence number 0 indicates the 0th data type declared, that is, int. the same is true for others.
To create a union, it must be create_union provides tag:
select create_union(0, key),
create_union(if(key<100, 0, 1), 2.0, value),
create_union(1, "a", struct(2, "b")
)
from src limit 2;
{0:"238"} {1:"val_238"} {1:{"col1":2,"col2":"b"}}
{0:"86"} {0:2.0} {1:{"col1":2,"col2":"b"}} 2, View
1. The difference between Hive's view and relational database's view
Like relational databases, Hive also provides the function of view, but there are the following differences:
(1) Only logical view, no materialized view;
(2) Views can only be queried, not load, insert, update or delete data;
(3) When the view is created, only a metadata is saved. When the view is queried, the sub queries corresponding to the view are executed.
2. Hive view creation
create view view_cdt as select * from cdt;
3. View Hive view information
show views; desc view_cdt;
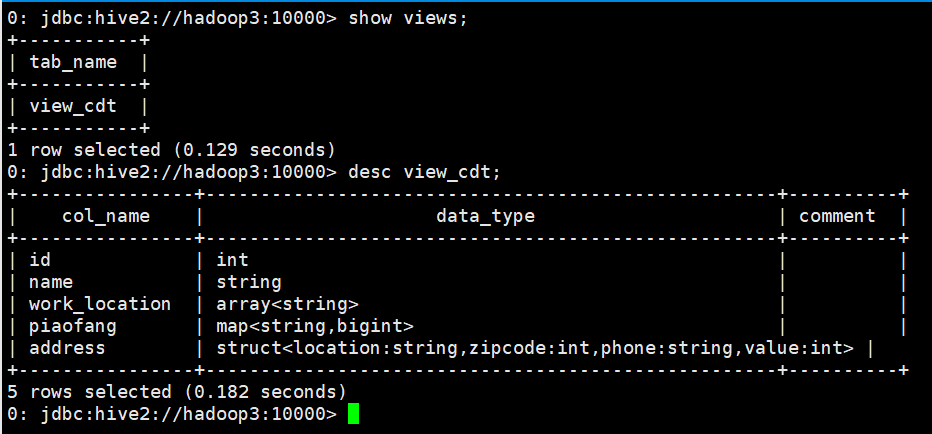
4. Use of Hive view
select * from view_cdt;
5. Delete Hive view
drop view view_cdt;
3, Functions
1. Built in function
(1) View built-in functions
show functions;
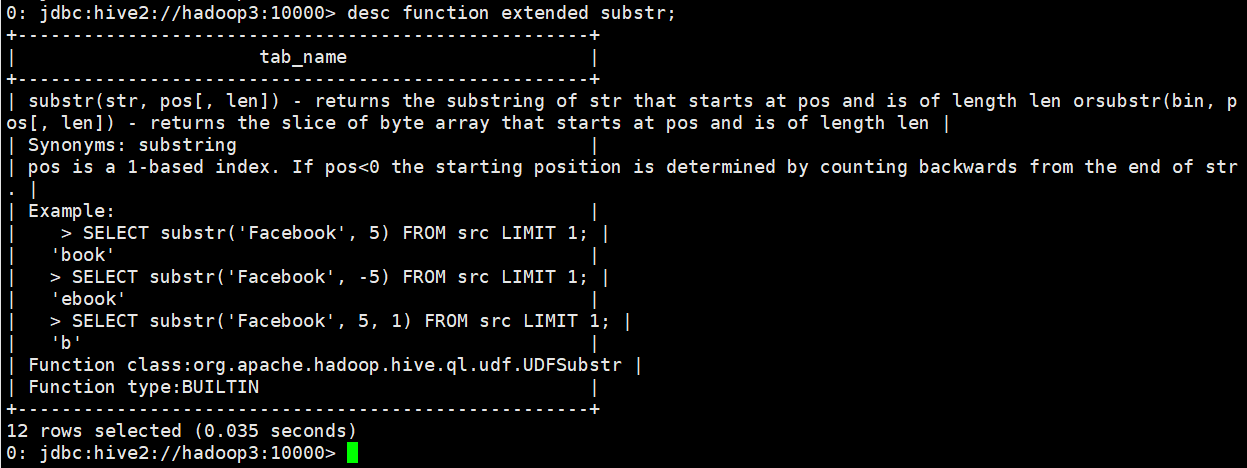
(2) display function details
desc function substr;

(3) Displays extended information for the function
desc function extended substr;
2. User defined function UDF
See: https://www.cnblogs.com/qingyunzong/p/8746159.html
When the built-in functions provided by Hive cannot meet the needs of business processing, you can consider using user-defined functions.
UDF (user defined function) acts on a single data row to produce a data row as output. (mathematical function, string function)
UDAF (user defined aggregation function): receives multiple input data rows and generates one output data row. (count, max)
UDTF (user defined table functions): receive one line of input and output multiple lines. (expand)
(1) Simple DUF example
a. Import the jar package required by hive, customize a java class, inherit UDF, and overload the evaluate method;
b. Print the jar package and upload it to the server;
c. Add the jar package to hive's classpath;
d. Create a temporary function to associate with the developed class;
e. At this point, you can use custom functions in hql
(2) JSON data parsing UDF development
......
(3) Transform implementation
......
4, Special separator handling
Firstly, the mechanism of Hive reading data is supplemented:
1. First, use inputformat < the default is: org apache. hadoop. mapred. A concrete implementation class of textinputformat > reads file data and returns records one by one (which can be lines or "lines" in your logic).
2. Then use serde < default: org apache. hadoop. hive. serde2. lazy. Lazysimpleserde > is a specific implementation class of lazysimpleserde >, which cuts the fields of one record returned above.
Hive only supports single byte separators for fields in the file by default. If the separators in the data file are multi character, it is as follows:
01||huangbo
02||xuzheng
03||wangbaoqiang
1. Parsing using RegexSerDe regular expressions
Create table:
create table t_bi_reg(id string,name string)
row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties('input.regex'='(.*)\\|\\|(.*)','output.format.string'='%1$s %2$s')
stored as textfile;Import data and query:
load data local inpath '/home/hadoop/data.txt' into table t_bi_reg; select a.* from t_bi_reg a;